pandas 常用函数总结
1.读取文件及查看数据表信息
读取文件及存储
1.pd.read_csv()/pd.read_excel()
读取csv文件/excel文件
参数为文件路径,可加sheet_name,默认sheet1名字为0
2.pd.to_csv(‘file_path’)/pd.to_excel()
存为csv文件/excel文件
参数为文件路径
常用函数
1.A=df.shape()
查看数据维数:
返回值为元组类型,可以如下调用:df.shape[0],行数
df=pd.DataFrame({'id':[1,np.nan,3,4],'name':['asx',np.nan,'wes','asd'],'score':[78,90,np.nan,88]},index=list('abcd'))
print(df.shape[0])
df
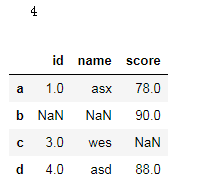
2.df.info()
数据表基本信息(维度、列名称、数据格式、所占空间等):
df=pd.DataFrame({'id':[1,np.nan,3,4],'name':['asx',np.nan,'wes','asd'],'score':[78,90,np.nan,88]},index=list('abcd'))
df.info()

3.df.dtypes()
每一列数据的格式:
4.df.head(n)/df.tail(n)
前n行数据/后n行数据,可以不填,默认5行
5.df.describe()
获取总的统计信息,包括和,平均值,方差,中位数等。
6.df.dtypes()
每一列数据的格式。
7.df.idxmax()/df.max()
求最大值索引/最大值 第一个函数只对数值型Series()起作用。
8.df.isnull()
返回每个单元格是否为空值,及是否为NAN,是返回True,否返回False.
2.数据处理
0.df[‘col_name’].value_counts()
对该列进行数据出现次数的统计
1.df.sum()
对列进行求和,当axis=1时,对每一行求和。
2.df.dropna()
删除含空值的行,返回不含空值的所有行的结果,如果how=’all’,删除全为空值的行,返回剩下的结果。
3.df.fillna(value=0)
缺失值填充,这里使用数字0填充空值。
使用方法,df.fillna(0) 空值全部填充为0
可差异化填充,使用字典dict={‘col1’:0,’col2’:’Unknow’,…}
Df.fillna(dict)/df.fillna(value=dict)均可
可以使用参数method,method=‘backfill’,以空值后面出现的值进行空值填充/’ffill’空值前面的值进行空值填充。
4.DataFrame.drop_duplicates(subset=None, keep=‘first’, inplace=False)
去重复值,各参数含义
subset : column label or sequence of labels, optional,传入列名,可以是单列或多列,多列用[],默认保留第一个重复值,传入多列时,多列值一起重复才会删除行。
用来指定特定的列,默认所有列
keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项
inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本
传入单列,会删除该列重复值得行,可传入多列,几列同时重复才会删除该行,多列用[‘a’,‘b’]传入,一般可以默认为所有列
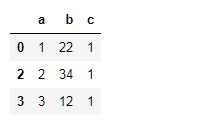
df3=pd.DataFrame({'a':[1,1,2,3],'b':[22,22,34,12],'c':[1,1,1,1]})
df3.drop_duplicates('a')
5.df.drop(labels=[‘col_name’], axis=1,inplace = True)
删除某一列或多列
6.df.pop(‘col_name’)
弹出某一列
7.Df.insert(0,’col-name’,df[‘col’])
插入一列,其中第一个参数为位置,第二个为新列名,第三个为插入的Series,注意插入时的索引必须一致。
8.df.set_index(‘col’)/df.reset_index()
设为索引,缺失值会被处理为nan字符串索引。
重设索引,一般不写参数,可以将原来索引变为普通列,使用默认索引。重设索引可以不给参数
9.pd.to_datetime()
将某一列设为时间序列,但是必须本身就为一定时间格式,不然结果会以1970年1月1日毫秒开始排列
df=pd.DataFrame({'a':[1,1,2,3],'b':[22,22,34,12],'c':[1,1,1,1]})
df3['a']=pd.to_datetime(df3['a'])
df=df3.set_index('c')
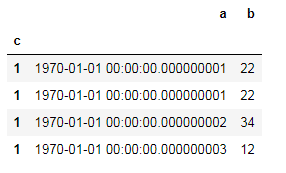
10.df.[‘col’].apply(lambda x: x.sum()/3, axis=1)
apply函数,将函数对所选列数据进行处理,处理方法为括号内函数。这里Axis=1表示对行进行处理,默认为列处理。
11.df[‘col’].replace(‘text1’,’text2’)
用text2代替text1
12.df[‘col’].str.contains(text_list,regex=True,na=False)
查询单元格是否包含某一内容。text_list为文本或者正则表达式。regex=True表示text_list为正则表达式查询。是否包含正则表达式或文本中的内容,是则返回True,否则返回False.
13.df3[].round(decimals=2)
设置单元格保留小数位数,这里保留两位小数。
14 df.map(str.strip)
去空格,这里查找数据表中所有单元格,去除前后空格及其他符号
详细解释,str.strip默认去掉字符中空格,及其他换行换位符,删除方法从头和尾部开始,但一旦没有符合删除要求的对象,就会停止删除
更多用法,str=str=‘hiahia ohoh haha ihih’
Str.strip(‘hai’) 就会为 ’ ohoh haha '.
字符串str还有另外两种类似的方法lstrip()和rstrip()。第一个是只删头,第二个是只删尾巴。用法类似。
3. 文本拆分及拼接
1.df.str.split(’-’)
列字符分隔
例如:df[‘柜台名称’].str.split(’-’)
以某一符号分割,此例子中以“-”分隔,并形成新的dateframe,使用expand实现。
Str.split()有三个参数,第一个为分列的依据,第二个为是否返回为dateframe数据格式,第三个为分列为多少行,如果想从右到左查找分列依据,使用rsplit().
rsplit(),rsplit和split()的用法类似,一个从右边开始,一个从左边开始。
返回的dateframe使用和原数据相同的索引,可以直接合并。
2.df.str.cat()
字符拼接
Df[‘col_name’].str.cat(df[‘col_name2’],sep=’-’) 将name和id 用-连接起来。
多列的拼接:Df[‘col_name’].str.cat([df[‘col_name2’],df[‘col_name3’]],sep=’-’)
4.数据表合并及拼接
1.pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=(’_x’, ‘_y’), copy=True, indicator=False,
validate=None)
Dataframe的合并,各参数含义
left: 拼接的左侧DataFrame对象
right: 拼接的右侧DataFrame对象
How:how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
Left,以左侧的数据框作为索引,右侧没有该索引的列会设为空值。
Right同理。
Inner:取交集
Outer:取并集
sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。
suffixes: 用于重叠列的字符串后缀元组。 默认为(‘x’,’ y’)
copy: 始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。
indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。 _merge是分类类型,并且对于其合并键仅出现在“左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在“右”DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。
right_index: 与left_index功能相似。
2.pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
第二种合并方式 .pd.concat()
要合并数据:objs=[df[],df[]…]
Axis=0,合并列 横向合并,axis=1.合并行,竖向合并。如果ignore_index=True,则索引会重设为默认索引。