1. 简介
首先我们要知道RNN是干什么的,解决了什么问题。RNN(Recurrent Neural Network)神经网络是一种能够处理序列数据的神经网络模型,它能够记忆之前的信息并将其应用于当前的计算中。RNN能够解决很多与序列相关的问题,如语言模型、机器翻译、语音识别、图像描述生成等。
RNN的特点是它们具有循环连接,这使得它们能够处理不定长的序列输入,并且能够根据之前的信息来预测下一个输出。这种记忆能力使得RNN在处理时序信息时非常有效。在传统的神经网络中,每个输入和输出之间都是相互独立的,而在RNN中,每个输入都与之前的输入相关联,这种序列信息的处理能力使得RNN能够更好地感知时间上的相关性。
因此,RNN能够有效地解决序列数据相关的问题,比如在语音识别中,RNN可以将之前的声音信息作为上下文来更好地识别当前的声音。在机器翻译中,RNN可以将整个句子作为序列输入,并输出对应语言的翻译结果。在图像描述生成中,RNN可以将图像特征作为序列输入,并输出对图像的描述。
总之,RNN能够解决很多与序列相关的问题,其优点在于具有循环连接,能够记忆之前的信息并将其应用于当前的计算中,从而更好地处理序列数据。
2. RNN网络结构
2.1 基本网络结构
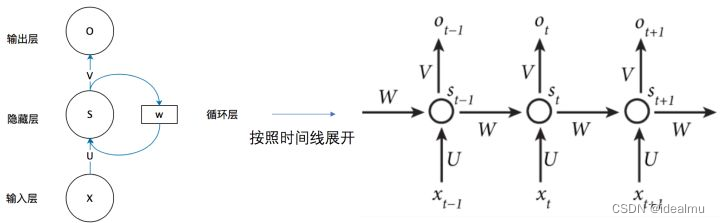
x x x是输入矩阵, x t , . . . x_{t},... xt,...对应的都是一个个词向量有向量维度;
s s s是隐藏层矩阵;
o o o是输出矩阵;
U 、 V 、 W U、V、W U、V、W如上图箭头方向的传递的全连接层的权重矩阵。
从图上我们可以得到两个非常重要的信息:
(1)、在时间 t t t方向上,也就是从左到右方向上,权重是共享的,即 U 、 V 、 W U、V、W U、V、W在 t t t方向上是一样的。
(2)、 t t t时刻的 s t s_t st值由前一时刻 s t − 1 s_{t-1} st−1 和 x t x_t xt共同决定的,这也是为什么能够处理序列的原因。
两个重要公式:
(1)、 s t = f ( x t ∗ U T + s t − 1 ∗ W T ) s_t = f( x_t * U^T + s_{t-1} * W^T) st=f(xt∗UT+st−1∗WT) ; // f f f是输入到隐藏层的激活函数,每个箭头方向代表一个全连接层 x t x_t xt、 s t s_t st都是向量,有维度。
(2)、 o t = g ( s t ∗ V T ) o_t = g( s_t * V^T ) ot=g(st∗VT); // g g g是隐藏层到输出层的激活函数。
例子:
输入 x t x_t xt维度为(1,100),隐藏层 s t s_t st维度想要为(1,128),
则 U 、 W U、W U、W的维度分别为(128,100),(128,128)
输出层维度想要为(1,10)假设想要实现10分类,
则 V V V的维度为(10,128)。
2.2 单向单层RNN
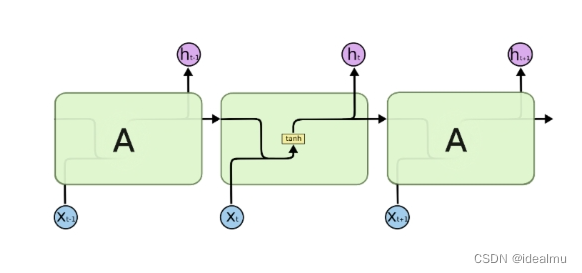
如上图所示,假设隐藏层的激活函数是tanh,结合2.1,则 h t h_t ht如下:
h t = t a n h ( x t ∗ W i h T + h t − 1 ∗ W h h T ) h_t = tanh(x_t * W_{ih}^T + h_{t-1} * W_{hh}^T ) ht=tanh(xt∗WihT+ht−1∗WhhT)
看一下pytorch 2.0文档这部分的介绍https://pytorch.org/docs/stable/generated/torch.nn.RNN.html
关于参数文档里已经解释的很清楚了,而且很明白。



接下来,我们就用代码来验证这些参数和权重相关信息。
先让我们简化一下结构图:
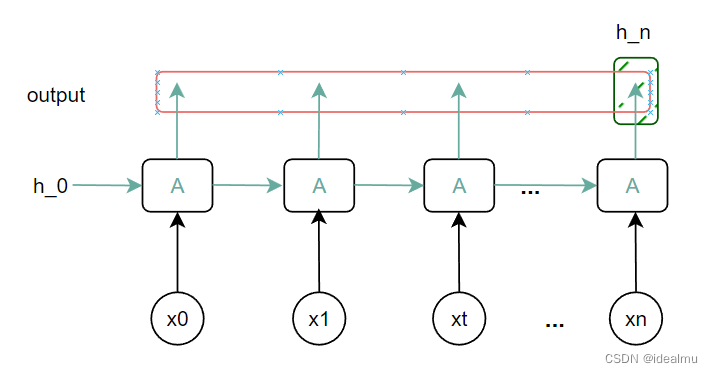
在看一下代码
from torch import nn
import torch
# # 单向单层 # #
'''
输入参数定义
batchsize: 批处理大小
seq_len : 序列长度 X=[x1, x2, ..., xt, ...] 维度为seq_len
xt_size : 输入每一个xt特征的向量维度, xt = [v1, v2, ...] 维度为xt_size,在自然语言处理中每一个xt其实代表一个词或者一个字对应的词向量
'''
batchsize = 3
seq_len = 4
xt_size = 10
input_x = torch.randn(batchsize, seq_len, xt_size)
'''
rnn 重要参数说明
inputsize : 要和input_x 中每一个输入xt 的维度一致,这里
hidden_size : 隐藏层神经元个数
num_layers : rnn 的层数
nonlinearity : 激活函数 'relu' , 'tanh'
batch_first : 按照一般思维,batchsize一般第一维度,这里用True
bidirectional: 单向就False
'''
hidden_size = 5
num_layers = 1
rnn = nn.RNN(input_size=xt_size, hidden_size=5, num_layers=1, nonlinearity='relu',
bias=True, batch_first=True, dropout=0, bidirectional=False)
# 单层单向h_0维度为(1, batchsize, hidden_size)
h_0 = torch.randn(1, batchsize, hidden_size)
# 输出 output.shape = (batchsize, seq_len, hiddzen)
# h_n.shape = (1, batchsize, hiddzen)
output, h_n = rnn(input_x, h_0)
print("output.shape, h_n.shape: ", '\n', output.shape, h_n.shape, '\n')
# 这两个应该相等
print("output[1, -1, :], h_n[:, 1, :] : ", '\n', output[1, -1, :], '\n', h_n[:, 1, :], '\n')
for name, p in rnn.named_parameters():
print(name, p.shape)
输出结果:
可以看到输出结果和文档以及我们理论上说明完全一致
output.shape, h_n.shape:
torch.Size([3, 4, 5])
torch.Size([1, 3, 5])
output[1, -1, :], h_n[:, 1, :] :
tensor([0.0401, 0.0000, 1.1217, 0.0000, 0.3944], grad_fn=<SliceBackward0>)
tensor([0.0401, 0.0000, 1.1217, 0.0000, 0.3944], grad_fn=<SliceBackward0>)
weight_ih_l0 torch.Size([5, 10])
weight_hh_l0 torch.Size([5, 5])
bias_ih_l0 torch.Size([5])
bias_hh_l0 torch.Size([5])
2.3 双向单层RNN
先画一个简单的示意图
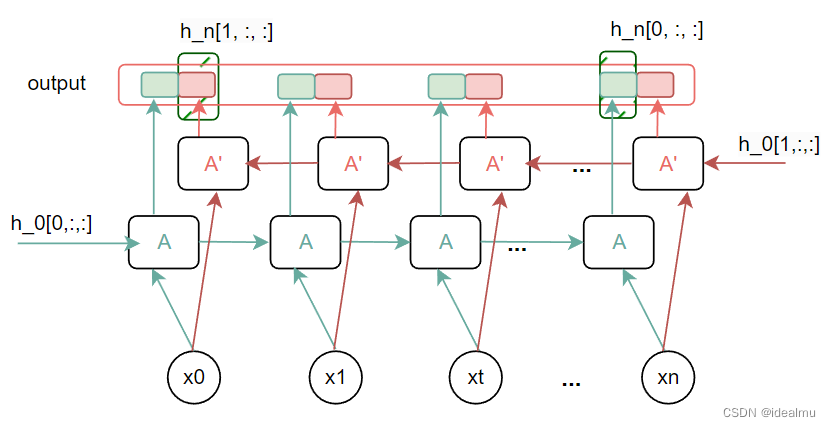
在看代码:
from torch import nn
import torch
# # 双向单层 # #
'''
输入参数定义
batchsize: 批处理大小
seq_len : 序列长度 X=[x1, x2, ..., xt, ...] 维度为seq_len
xt_size : 输入每一个xt特征的向量维度, xt = [v1, v2, ...] 维度为xt_size,在自然语言处理中每一个xt其实代表一个词或者一个字对应的词向量
'''
batchsize = 3
seq_len = 4
xt_size = 10
input_x = torch.randn(batchsize, seq_len, xt_size)
'''
rnn 重要参数说明
inputsize : 要和input_x 中每一个输入xt 的维度一致,这里
hidden_size : 隐藏层神经元个数
num_layers : rnn 的层数
nonlinearity : 激活函数 'relu' , 'tanh'
batch_first : 按照一般思维,batchsize一般第一维度,这里用True
bidirectional: 双向就True
'''
hidden_size = 5
num_layers = 1
rnn = nn.RNN(input_size=xt_size, hidden_size=5, num_layers=1, nonlinearity='relu',
bias=True, batch_first=True, dropout=0, bidirectional=True)
# 双向单层h_0维度为(2 * 1, batchsize, hidden_size)
h_0 = torch.randn(2 * num_layers, batchsize, hidden_size)
# 输出 output.shape = (batchsize, seq_len, 2 * hiddzen)
# h_n.shape = (2* num_layers, batchsize, hiddzen)
output, h_n = rnn(input_x, h_0)
print("output.shape, h_n.shape: ", '\n', output.shape, '\n', h_n.shape, '\n')
# 这两个应该相等
print("output[1, -1, :hidden_size], output[1, 0, hidden_size:], h_n[:, 1, :] : ", '\n',
output[1, -1, :hidden_size], '\n',
output[1, 0, hidden_size:], '\n',
h_n[:, 1, :], '\n')
for name, p in rnn.named_parameters():
print(name, p.shape)
看一下结果:
这里需要注意的是,正向权重和反向权重是分开的, 维度是一样的,h_0 和h_n的值一定要对着我的示意图和pytorch文档好好揣摩其中意思。

2.4 双向多层RNN
前面的看懂之后,更复杂的双向多层也就很容易明白。
先看简单的示意图
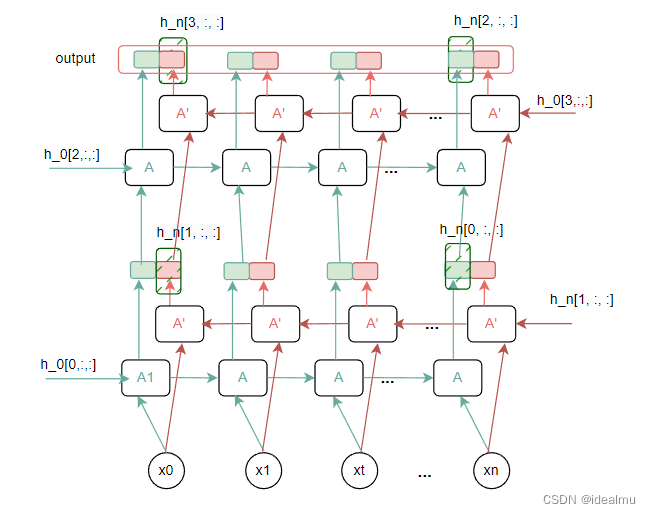
在看代码:
from torch import nn
import torch
# # 双向双层 # #
'''
输入参数定义
batchsize: 批处理大小
seq_len : 序列长度 X=[x1, x2, ..., xt, ...] 维度为seq_len
xt_size : 输入每一个xt特征的向量维度, xt = [v1, v2, ...] 维度为xt_size,在自然语言处理中每一个xt其实代表一个词或者一个字对应的词向量
'''
batchsize = 3
seq_len = 4
xt_size = 10
input_x = torch.randn(batchsize, seq_len, xt_size)
'''
rnn 重要参数说明
inputsize : 要和input_x 中每一个输入xt 的维度一致,这里
hidden_size : 隐藏层神经元个数
num_layers : rnn 的层数
nonlinearity : 激活函数 'relu' , 'tanh'
batch_first : 按照一般思维,batchsize一般第一维度,这里用True
bidirectional: 双向就True
'''
hidden_size = 5
num_layers = 2
rnn = nn.RNN(input_size=xt_size, hidden_size=5, num_layers=2, nonlinearity='relu',
bias=True, batch_first=True, dropout=0, bidirectional=True)
# 双向单层h_0维度为(2 * 1, batchsize, hidden_size)
h_0 = torch.randn(2 * num_layers, batchsize, hidden_size)
# 输出 output.shape = (batchsize, seq_len, 2 * hiddzen)
# h_n.shape = (2* num_layers, batchsize, hiddzen)
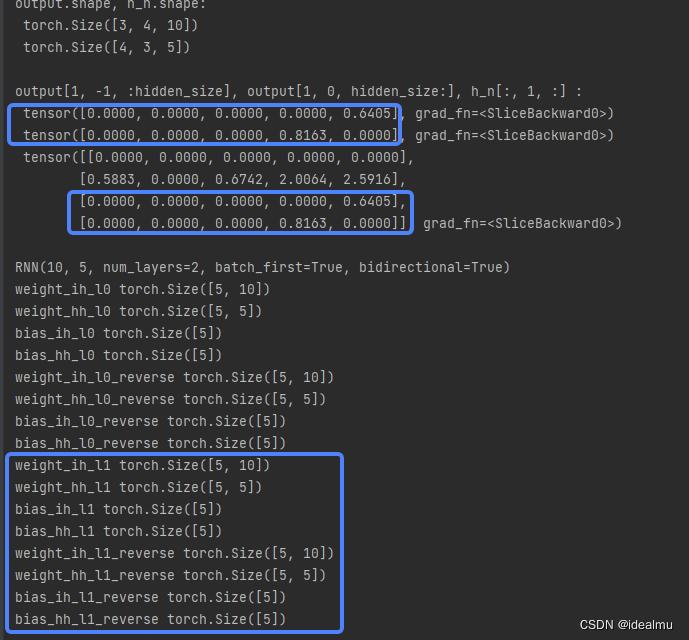
output, h_n = rnn(input_x, h_0)
print("output.shape, h_n.shape: ", '\n', output.shape, '\n', h_n.shape, '\n')
# 这两个应该相等
print("output[1, -1, :hidden_size], output[1, 0, hidden_size:], h_n[:, 1, :] : ", '\n',
output[1, -1, :hidden_size], '\n',
output[1, 0, hidden_size:], '\n',
h_n[:, 1, :], '\n')
print(rnn)
for name, p in rnn.named_parameters():
print(name, p.shape)
结果:多层结构权重会增加一层的权重,h_n的第一个维度会变为2*num_layers ;排列方式如简图那样。
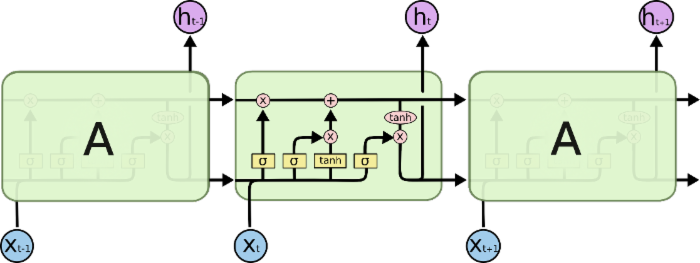
3 LSTM
LSTM增加了一些门单元,为了解决RNN长序列问题
RNN看明白之后,其实LSTM跟RNN是一样的,不同就是RNN中的单元结构增加了一些门单元以及多了一条传递的记忆线c,输入输出结构完全和RNN一样,而我们最关心的其实是输入、输出以及权重。
详细介绍可以看以下介绍
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
这里我们直接看pytorch 2.0给出的公式

参数介绍:
这里基本和rnn完全一致,只是多了一个proj_size参数,这个参数相当于在lstm输出后面再额外加一个全连接层,使输出的隐藏层单元hidden_size个数变成proj_size,后面我们会举例代码

其他输入输出以及权重就不在介绍,因为跟rnn基本完全一致,也可以看以上2.0文档中介绍。
我们直接拿一个双向双层代码例子看一下:
from torch import nn
import torch
# # 双向双层 # #
'''
输入参数定义
batchsize: 批处理大小
seq_len : 序列长度 X=[x1, x2, ..., xt, ...] 维度为seq_len
xt_size : 输入每一个xt特征的向量维度, xt = [v1, v2, ...] 维度为xt_size,在自然语言处理中每一个xt其实代表一个词或者一个字对应的词向量
'''
batchsize = 3
seq_len = 4
xt_size = 10
input_x = torch.randn(batchsize, seq_len, xt_size)
'''
rnn 重要参数说明
inputsize : 要和input_x 中每一个输入xt 的维度一致,这里
hidden_size : 隐藏层神经元个数
num_layers : rnn 的层数
nonlinearity : 激活函数 'relu' , 'tanh', lstm, gru没有这一项, 因为激活函数是固定的
batch_first : 按照一般思维,batchsize一般第一维度,这里用True
bidirectional: 双向就True
'''
hidden_size = 5
num_layers = 2
# 比rnn多了一个proj_size
lstm = nn.LSTM(input_size=xt_size, hidden_size=5, num_layers=2,
bias=True, batch_first=True, dropout=0, bidirectional=True, proj_size=0)
# 双向单层h_0维度为(2 * 1, batchsize, hidden_size), c_0跟h_0维度一致
h_0 = torch.randn(2 * num_layers, batchsize, hidden_size)
c_0 = torch.randn(2 * num_layers, batchsize, hidden_size)
# 输出 output.shape = (batchsize, seq_len, 2 * hiddzen)
# h_n.shape = (2* num_layers, batchsize, hiddzen)
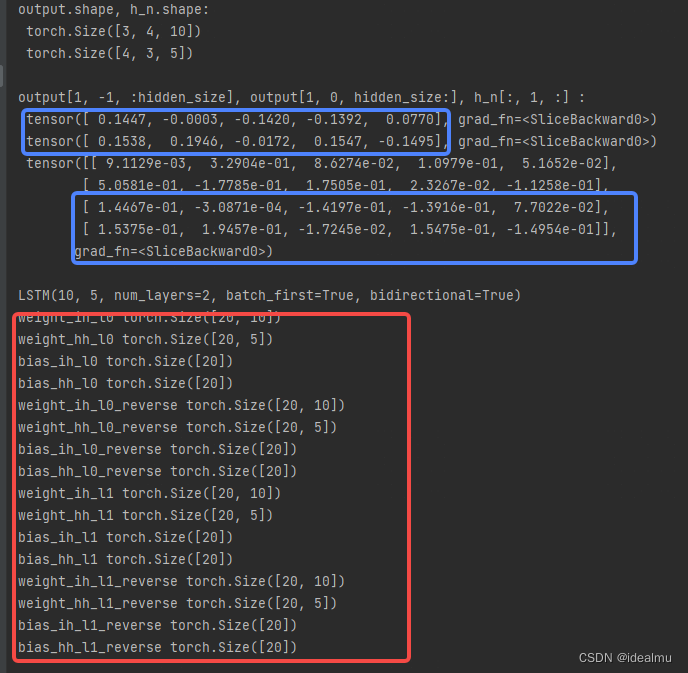
output, (h_n, c_n) = lstm(input_x, (h_0, c_0))
print("output.shape, h_n.shape: ", '\n', output.shape, '\n', h_n.shape, '\n')
# 这两个应该相等
print("output[1, -1, :hidden_size], output[1, 0, hidden_size:], h_n[:, 1, :] : ", '\n',
output[1, -1, :hidden_size], '\n',
output[1, 0, hidden_size:], '\n',
h_n[:, 1, :], '\n')
print(lstm)
for name, p in lstm.named_parameters():
print(name, p.shape)
结果:这个结果其实跟rnn是没差别的只是多个一些门单元的权重参数
我们再把代码中的proj_size改成6试一试,
h_0也要改,因为ht最后的单元变成了proj_size而不是hidden_size了
输出打印也要改一下,因为输出维度也是变了
proj_size = 6
lstm = nn.LSTM(input_size=xt_size, hidden_size=5, num_layers=2,
bias=True, batch_first=True, dropout=0, bidirectional=True, proj_size=6)
h_0 = torch.randn(2 * num_layers, batchsize, proj_size)
... ...
print("output[1, -1, :proj_size], output[1, 0, proj_size:], h_n[:, 1, :] : ", '\n',
output[1, -1, :proj_size], '\n',
output[1, 0, proj_size:], '\n',
h_n[:, 1, :], '\n')
报错:
ValueError: proj_size has to be smaller than hidden_size
看来维度只能往小的变,不能往大的变。
那我们改成3试一试:
proj_size = 3
lstm = nn.LSTM(input_size=xt_size, hidden_size=5, num_layers=2,
bias=True, batch_first=True, dropout=0, bidirectional=True, proj_size=6)
h_0 = torch.randn(2 * num_layers, batchsize, proj_size)
... ...
print("output[1, -1, :proj_size], output[1, 0, proj_size:], h_n[:, 1, :] : ", '\n',
output[1, -1, :proj_size], '\n',
output[1, 0, proj_size:], '\n',
h_n[:, 1, :], '\n')
结果:跟rnn还是基本完全一致,这里会多一个权重 W h r W_{hr} Whr,就不在多说了,前面已经解释过了。
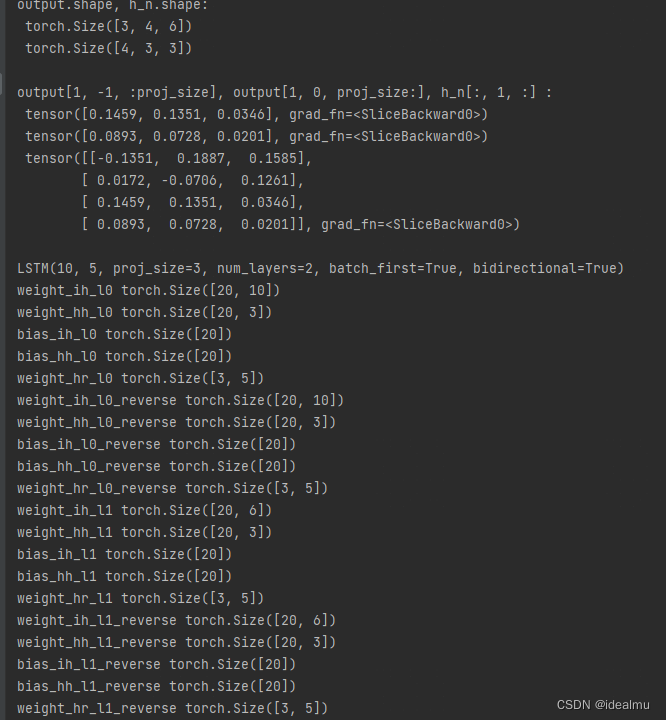
4 GRU
GRU就是LSTM的变形,省去了c这条记忆链,减少了权重参数
还是在https://colah.github.io/posts/2015-08-Understanding-LSTMs/
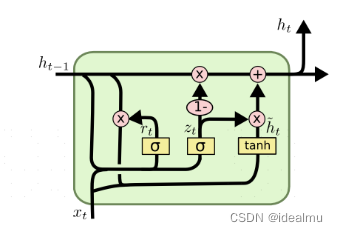
pytorch 文档,基本上和lstm, rnn没什么区别,奇怪的是又把proj_size给干掉了,可能作者都发现这是一个没什么用的参数。
https://pytorch.org/docs/stable/generated/torch.nn.GRU.html
这里就不在介绍了,直接看一下代码吧,把rnn代码拿来都不需要怎么改。
from torch import nn
import torch
# # 双向双层 # #
'''
输入参数定义
batchsize: 批处理大小
seq_len : 序列长度 X=[x1, x2, ..., xt, ...] 维度为seq_len
xt_size : 输入每一个xt特征的向量维度, xt = [v1, v2, ...] 维度为xt_size,在自然语言处理中每一个xt其实代表一个词或者一个字对应的词向量
'''
batchsize = 3
seq_len = 4
xt_size = 10
input_x = torch.randn(batchsize, seq_len, xt_size)
'''
rnn 重要参数说明
inputsize : 要和input_x 中每一个输入xt 的维度一致,这里
hidden_size : 隐藏层神经元个数
num_layers : rnn 的层数
nonlinearity : 激活函数 'relu' , 'tanh', lstm,gru为固定的激活函数,不需要
batch_first : 按照一般思维,batchsize一般第一维度,这里用True
bidirectional: 双向就True
'''
hidden_size = 5
num_layers = 2
gru = nn.GRU(input_size=xt_size, hidden_size=5, num_layers=2,
bias=True, batch_first=True, dropout=0, bidirectional=True)
# 双向单层h_0维度为(2 * 1, batchsize, hidden_size)
h_0 = torch.randn(2 * num_layers, batchsize, hidden_size)
# 输出 output.shape = (batchsize, seq_len, 2 * hiddzen)
# h_n.shape = (2* num_layers, batchsize, hiddzen)
output, h_n = gru(input_x, h_0)
print("output.shape, h_n.shape: ", '\n', output.shape, '\n', h_n.shape, '\n')
# 这两个应该相等
print("output[1, -1, :hidden_size], output[1, 0, hidden_size:], h_n[:, 1, :] : ", '\n',
output[1, -1, :hidden_size], '\n',
output[1, 0, hidden_size:], '\n',
h_n[:, 1, :], '\n')
print(gru)
for name, p in gru.named_parameters():
print(name, p.shape)
结果:
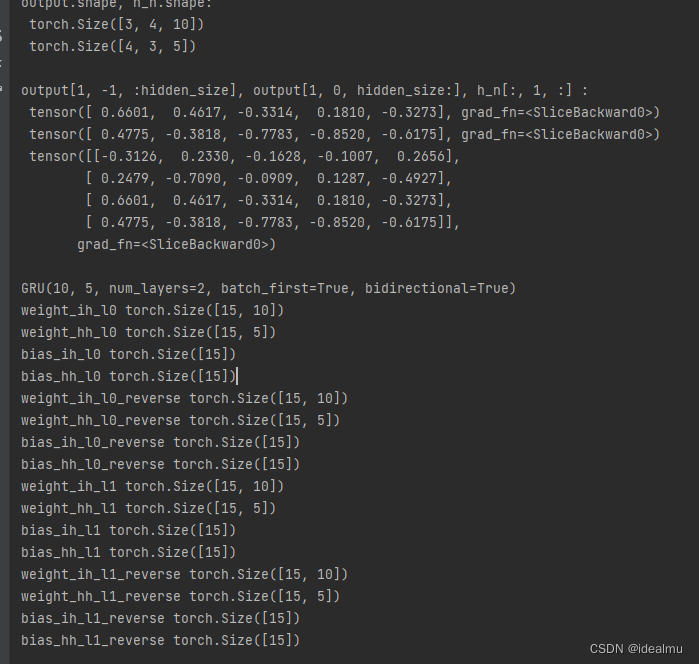
5 最后说一说优缺点吧
拿chatgpt给的答案,这就是这次的全部了,重要一点rnn都是历史的产物了,但是是基础,后面有机会在看transform如何克服rnn这些缺点,一度逆袭的。
RNN:
优点:
- 可以处理时间序列数据,具有记忆功能,能够传递信息;
- 网络结构简单,易于实现;
- 可以接受任意长度的输入。
缺点:
- 长期依赖关系不佳,容易出现梯度消失或爆炸问题;
- 训练过程中参数更新困难,容易过拟合;
- 难以处理变长的输入数据。
LSTM:
优点:
- 具有很好的长期依赖性,能够处理长序列数据;
- 通过门控机制(遗忘门、输入门、输出门)可以过滤掉不必要的信息,提高模型性能;
- 可以避免梯度消失或爆炸问题。
缺点:
- 训练过程复杂,计算量大,需要更多的时间和计算资源;
- 模型参数较多,容易过拟合;
- 不同的超参数设置对模型性能影响较大。
GRU:
优点:
- 简单有效,计算速度快,训练过程相对简单;
- 不同于LSTM,只有两个门(更新门、重置门),参数较少,容易优化;
- 具有很好的短期依赖性能力。
缺点:
- 不能很好的处理长期依赖关系;
- 效果相对于LSTM略差;
- 对于一些复杂的序列数据,可能需要更复杂的模型结构来提高性能。