
本文是《WebAssembly 权威指南》系列文章第 5 篇,系列文章列表:
这篇文章是《WebAssembly 权威指南》一书的第五章,介绍了如何使用 C/C++ 和 WebAssembly 开发应用程序。文章首先讲解了 C/C++ 语言和 WebAssembly 的兼容性和互操作性,以及一些常见的问题和解决方案。文章然后介绍了几种将 C/C++ 代码编译为 WebAssembly 模块的工具和方法,如 Emscripten、Clang 和 LLVM。文章还展示了如何使用 C/C++ 编写 WebAssembly 的函数、变量、内存、表和导入导出等特性。文章最后讲解了如何在浏览器中加载和运行 WebAssembly 模块,并使用 JavaScript 与之交互。
本书的转折点来了。到目前为止,我们一直专注于 WebAssembly 相关工具和技术栈。这是探索平台的方法有用,但是作为开发工具效率低下。高级编程语言早已使我们的专业超越了低级指令集的工作细节。用句法简洁、语义丰富的语言来表达逻辑,更容易、更有效率。
要真正体会到 WebAssembly 所提供的东西,我们需要考虑可编译为 WebAssembly 的源语言。问题是,并不是每个问题都能用 JavaScript 来表达,所以可以选择使用另一种语言,因为它的性能、表达的清晰性,或者仅仅是重复使用现有的代码,都是很有吸引力的。
C 语言是世界上最重要和最广泛使用的编程语言之一。我在高中时就开始在 Atari ST 电脑上使用它。我在《计算机语言》杂志上读到过它,一个朋友给了我一本开创性的、同名的书籍 《C 编程语言 [1]》作者是 Brian Kernighan 和已故伟大的 Dennis Ritchie。
有大量的 C 语言软件可以使用,其中大部分可以简单地重新编译成 WebAssembly。我们将在第 6 章 [2] 讨论现有库的移植问题。但现在我们将学习一点 C 语言,和使用它来改进我们迄今为止所尝试的一些工作。
使用 C 语言函数
C 语言函数在很多方面与 JavaScript 函数相似。它有自己的词法结构,并不附属于像类或结构那样的大单元。它可以接受也可以不接受参数。然而,它只能返回一个单一的值,并且不支持异常,所以错误处理往往比 C++、Java 或 JavaScript 更原始一些。
在例 5-1 中,有一个 C 语言实现了我们的年龄计算函数。这个程序很简单。这个例子甚至有一些基本的错误处理方法来处理参数错误的情况,即出生年份大于当前年份的情况。除非有来自未来的穿越者出现,否则这种情况不应该发生,我们应该处理它。更高级别的语言只是更容易来表达业务逻辑。
例 5-1. 一个简单的 C 语言程序
#include <stdio.h>
int howOld( int currentYear, int yearBorn )
{
int retValue = -1;
if ( yearBorn <= currentYear )
{
retValue = currentYear - yearBorn;
}
return(retValue);
}
int main()
{
int age = howOld( 2021, 2000 );
if ( age >= 0 )
{
printf( "You are % d!\n", age );
} else { printf( "You haven't been born yet." ); }
}不幸的是,计算机并不理解这些高级语言,所以我们需要将它们转换为二进制机器表示,以便执行。如果你只进行过 JavaScript 编程,这个过程可能略显陌生。作为一种解释性语言,你编写 JavaScript 并简单地运行它。就像所有的事情一样,都是有取舍的。对开发者来说很方便的东西,在运行时往往会明显变慢,而 C 和 C++ 在性能上长期以来一直占据着领先地位。
鉴于 C 语言的成熟度和对我们行业的重要性,有许多优秀的商业和开源的编译器。其中包括 GNU/Linux C 编译器(GCC)和 LLVM 的 Clang 编译器。我们将专注于后者,原因很快就会清楚。参考附录 [3] 来运行安装程序。即使在默认使用 Clang 的 macOS 上,如果没有安装 LLVM 的 WebAssembly 支持,也不是所有的命令都能开箱即用。
我们可以将 C 语言程序转换为可执行文件,如下所示:
brian@tweezer ~/g/w/s/ch05> clang howold.c
brian@tweezer ~/g/w/s/ch05> ls -laF
total 112
drwxr-xr-x 4 brian staff 128 Feb 14 14:35 ./
drwxr-xr-x 6 brian staff 192 Feb 14 14:32 ../
-rwxr-xr-x 1 brian staff 49456 Feb 14 14:35 a.out*
-rw-r--r-- 1 brian staff 343 Feb 14 14:36 howold.c由于历史原因,生成的可执行文件被称为 a.out。你将在后面看到如何改变它。现在,我们可以执行该程序。
brian@tweezer ~/g/w/s/ch05> ./a.out
You are 21!这是因为生成的可执行文件已经变成了 macOS 知道如何运行的合适格式。它是一个针对 64 位平台上的英特尔 x86 指令集的 Mach-O 可执行文件。
brian@tweezer ~/g/w/s/ch05> file a.out
a.out: Mach-O 64-bit executable x86_64这个程序不能在 Windows 或 Linux 机器上运行。如果没有新的仿真层,它甚至不能在苹果新的基于 ARM 的机器上运行。这是因为 CPU 有一个指令集,涉及到将数值加载到寄存器中,在 CPU 上调用功能,并将结果存储在内存中。重新运行 clang 以支持 duce 汇编语言输出,而不是二进制可执行文件:
brian@tweezer ~/g/w/s/ch05> clang -S howold.c产生的文件如例 5-2 所示。
例 5-2. 为我们的简单应用程序生成的汇编语言
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 13, 0 sdk_version 13, 1
.globl _howOld ## -- Begin function howOld
.p2align 4, 0x90
_howOld: ## @howOld
.cfi_startproc
## % bb.0:
pushq % rbp
.cfi_def_cfa_offset 16
.cfi_offset % rbp, -16
movq % rsp, % rbp
.cfi_def_cfa_register % rbp
movl % edi, -4 (% rbp)
movl % esi, -8 (% rbp)
movl $-1, -12 (% rbp)
movl -8 (% rbp), % eax
cmpl -4 (% rbp), % eax
jg LBB0_2
## % bb.1:
movl -4 (% rbp), % eax
subl -8 (% rbp), % eax
movl % eax, -12 (% rbp)
LBB0_2:
movl -12 (% rbp), % eax
popq % rbp
retq
.cfi_endproc
## -- End function
.globl _main ## -- Begin function main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## % bb.0:
pushq % rbp
.cfi_def_cfa_offset 16
.cfi_offset % rbp, -16
movq % rsp, % rbp
.cfi_def_cfa_register % rbp
subq $16, % rsp
movl $0, -4 (% rbp)
movl $2021, % edi ## imm = 0x7E5
movl $2000, % esi ## imm = 0x7D0
callq _howOld
movl % eax, -8 (% rbp)
cmpl $0, -8 (% rbp)
jl LBB1_2
## % bb.1:
movl -8 (% rbp), % esi
leaq L_.str (% rip), % rdi
movb $0, % al
callq _printf
jmp LBB1_3
LBB1_2:
leaq L_.str.1 (% rip), % rdi
movb $0, % al
callq _printf
LBB1_3:
movl -4 (% rbp), % eax
addq $16, % rsp
popq % rbp
retq
.cfi_endproc
## -- End function
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "You are % d!\n"
L_.str.1: ## @.str.1
.asciz "You haven't been born yet."
.subsections_via_symbols正如你所看到的,它比我们的 C 程序要啰嗦得多。像函数调用、循环和条件检查这样的高级结构需要许多低级别的指令来表达。我们将需要一个实际的英特尔 x86 芯片来运行,或者至少是一个仿真的芯片。然而,在某种程度上,这与我们在前几章看到的 Wat 文件在概念上是相似的。
我们将 Clang 作为 C 编译器例子的主要原因是,它有一个基于 LLVM 项目的现代、可插拔的架构。在现代世界中,越来越多的竞争性指令集(如 x86、ARM、RISC-V)、新的编程语言(如 Rust、Julia、Swift),以及无论何种源语言都希望重复使用通用的优化,这一点是非常重要的。
在图 5-1 中,你可以看到这一过程包括三个环节。源代码被一个前端处理步骤解析。这将是特定于语言的。此步骤的输出是一个中间表示(IR),一个假设的但不是真实的机器的指令集。它以一种可以被优化层操作的格式捕获了所表达的逻辑。这个过程涉及到应用一个或多个转换 ,这些转换可以使代码更快、更有效。循环可以被展开。不使用的代码可能被删除,涉及常量的表达式可能被编译器评估,因此它们不需要在运行时评估,等等。最后一步是释放出一套本地的针对一个特定的运行时的指令。对于我们的目的,这显然是 Mach-O x86 64 位架构。

这些层中的任何一个都可以被替换成其他东西。正如我所提到的,Rust、Julia 和 Swift 等语言 ,都使用 LLVM 基础设施。这使语言作者不必每次都从头开始。他们需要编写新的前端解析器,但可以利用大部分现有的优化和后端工作。编译器研究人员可以开发新的优化,并在使其可用于任意输入语言的 IR 之前对其进行隔离测试。对于我们的目的,后端是最重要的可交换层。在 Linux 或 Windows 上,可以使用相同的前两层的本地版本,但也会有一个特定机器的后端。
你通常可以通过一个被称为交叉编译的过程,生成一个与你的计算机的本地运行时不同的后端。这对于针对可能没有安装开发者工具链的嵌入式系统很有用。这在持续集成和交付系统中也很有用,你可以从同一个构建环境中针对多个平台构建。否则,你可能需要为每个目标平台建立一个单独的构建环境。
Emscripten 工具链是为 asm.js 工作而开发的,它基于 LLVM 和 Clang,所以它只需要生成可优化的 JavaScript 子集,以允许 C 程序在浏览器上运行。当 WebAssembly 指令集和平台最终被定义时,从本质上讲,只需要添加一个 WebAssembly 后端来代替它。我们将在下一章介绍这个工具链,但希望你能充分了解高级语言是如何被编译成一种通用的形式,然后再进一步转化成一种有效的本地表示。
我们的 LLVM 安装原生支持 WebAssembly 后端。你可以使用下面的方式来检查:
brian@tweezer ~/g/w/s/ch05> llc --version LLVM (http://llvm.org/):
LLVM version 11.0.1
Optimized build.
Default target: x86_64-apple-darwin20.2.0
Host CPU: skylake
Registered Targets:
aarch64 - AArch64 (little endian)
aarch64_32 - AArch64 (little endian ILP32)
aarch64_be - AArch64 (big endian)
arm - ARM
arm64 - ARM64 (little endian)
arm64_32 - ARM64 (little endian ILP32)
nvptx - NVIDIA PTX 32-bit
nvptx64 - NVIDIA PTX 64-bit
ppc32 - PowerPC 32
ppc64 - PowerPC 64
ppc64le - PowerPC 64 LE
r600 - AMD GPUs HD2XXX-HD6XXX
riscv32 - 32-bit RISC-V
riscv64 - 64-bit RISC-V
wasm32 - WebAssembly 32-bit
wasm64 - WebAssembly 64-bit
x86 - 32-bit X86: Pentium-Pro and above
x86-64 - 64-bit X86: EM64T and AMD64
xcore - XCore我截断了支持的目标列表(它要长得多!),只要是为了表明大多数主要平台支持。为了简化,我打算用年龄计算函数取代程序中独立的 main () 功能,如例 5-3 所示。
例 5-3. 只是 howOld 函数
int howOld (int currentYear, int yearBorn) {
int retValue = -1;
if (yearBorn <= currentYear) {retValue = currentYear - yearBorn;}
return retValue;
}为了将其编译成 WebAssembly,我们可以使用以下方法:
> clang --target=wasm32 -nostdlib -Wl,--no-entry -Wl,--export-all howold2.c -o howold.wasm--target=wasm32 指令针对 32 位 WebAssembly 平台。--nostdlib 指令告诉它不要与标准库链接,因为我们并不打算在一个可以直接使用该函数的地方(例如,浏览器)运行该函数。--not-entry 和 --export-all 指令告诉链接器不要期望有 main () 函数,并保留所有的函数用于导出目的。如果没有后者的提示,优化过程可能会消除未使用的函数,因为在技术上没有任何东西在调用它们。-o howold.wasm 命名了输出文件。
这将产生一个可用的 Wasm 模块,通过学习前面的章节你应该知道如何使用它。文件中有很多噪音,但基本原理仍然是一样的。我们有类型、函数和内存,以及各种内存管理细节,现在我们将忽略这些细节:
brian@tweezer ~/g/w/s/ch05> wasm-objdump -x howold.wasm
howold.wasm: file format wasm 0x1
Section Details:
Type [2]:
- type [0] () -> nil
- type [1] (i32, i32) -> i32
Function [2]:
- func [0] sig=0 <__wasm_call_ctors>
- func [1] sig=1 <howOld>
Table [1]:
- table [0] type=funcref initial=1 max=1
Memory [1]:
- memory [0] pages: initial=2
Global [7]:
- global [0] i32 mutable=1 - init i32=66560
- global [1] i32 mutable=0 <__dso_handle> - init i32=1024
- global [2] i32 mutable=0 <__data_end> - init i32=1024
- global [3] i32 mutable=0 <__global_base> - init i32=1024
- global [4] i32 mutable=0 <__heap_base> - init i32=66560
- global [5] i32 mutable=0 <__memory_base> - init i32=0
- global [6] i32 mutable=0 <__table_base> - init i32=1
Export [9]:
- memory [0] -> "memory"
- func [0] <__wasm_call_ctors> -> "__wasm_call_ctors"
- func [1] <howOld> -> "howOld"
- global [1] -> "__dso_handle"
- global [2] -> "__data_end"
- global [3] -> "__global_base"
- global [4] -> "__heap_base"
- global [5] -> "__memory_base"
- global [6] -> "__table_base"
Code [2]:
- func [0] size=2 <__wasm_call_ctors>
- func [1] size=134 <howOld>
Custom:
- name: "name"
- func [0] <__wasm_call_ctors>
- func [1] <howOld>
Custom:
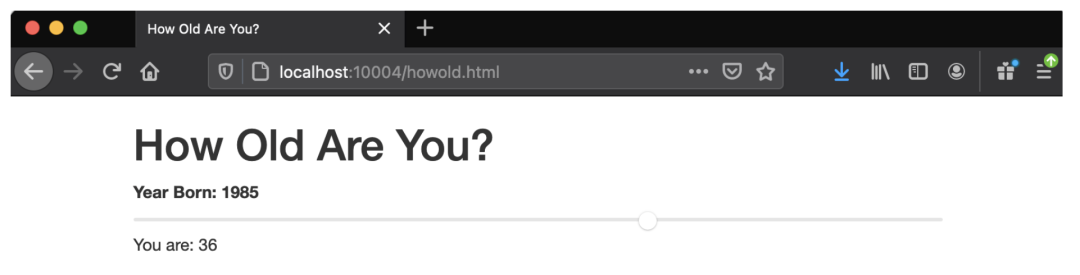
- name: "producers"在例 5-4 中,我们使用新模块来计算基于 HTML 输入范围设置的年龄。这显然不是一个我们必须用 C 语言编写的函数,但我们暂时让它保持简单。我们有一个范围 <input> 元素,一旦 WebAssembly 模块被加载,它的最大值就被设置为当前年份。我们任意地将最小值设置为过去的 100 年。我们有一个函数叫 updateLabels,当值发生变化时设置元素的值,另一个函数是当滑块值发生变化时重新计算某人的年龄。监听器函数调用我们模块,用 currentYear 和滑块的当前值来计算差异。
例 5-4. 在 HTML 中使用 howOld 函数
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<link rel="stylesheet" href="bootstrap.min.css">
<title>How Old Are You?</title>
<script src="utils.js"></script>
</head>
<body>
<div id="container" class="container" style="width: 80%">
<h1>How Old Are You?</h1>
<label for="year" id="yearborn" class="form-label">Year Born</label>
<input type="range" class="form-range" id="year" name="year" value="0"/>
<div class="form-label">You are: <span id="age"/></div>
</div>
<script>
var d = new Date ();
var currentYear = d.getFullYear ();
var slider = document.getElementById ("year");
var yearBorn = document.getElementById ("yearborn");
var ageSpan = document.getElementById ("age");
fetchAndInstantiate ('howold.wasm').then (function (instance) {slider.setAttribute ("min", currentYear - 100);
slider.setAttribute ("max", currentYear);
var updateLabels = function (val, age) {
yearBorn.innerText = "Year Born:" + val;
ageSpan.innerText = age;
};
var listener = function () {var age = instance.exports.howOld (currentYear, slider.value);
updateLabels (slider.value, age);
};
slider.onchange = listener;
slider.oninput = listener;
slider.value = "1972";
updateLabels (1972, 49);
});
</script>
</body>
</html>渲染后的 HTML 如图 5-2 所示。
开始变得复杂
现在你已经看到了用 WebAssembly 使用 C 语言的基本情况,实际上我们并没有写多少代码。我给你看了一个简单的例子,把几个数字传给一个只返回一个数字的函数。这与我们到目前为止所做的事情没有什么区别。
更复杂的 C 语言程序将很难很简单地映射到你接触的所有平台上。比如我们的 "Hello, World!" 程序,有一个问题:在浏览器中,程序没有 printf () 函数可用。还有一个问题,就是 C 语言程序的结构以及内存的分配和清理方式。在我们探索的领域,将各种编译后的程序链接在一起的过程也是根本不同的。
好消息是,这些问题中的大多数可以通过工具和运行时平台来处理。坏消息是,这些细节很快就变得相当复杂。如果你从未写过 C 语言程序,可能会有很多疑问。这本书不能教你所有的东西,但我将努力强调这种语言和 WebAssembly 之间的具体互动。
想象一下一个简单的函数,它不需要任何参数,只需要返回一个数组的总和。例 5-5 就有这样一个例子。忍耐一下吧,我暂时保持它的简单性。在这段代码中,我们没有参数,编译器可以知道数组需要多大,因为我们用前 10 位数字初始化了它。
例 5-5. 一个简单的 C 函数
int addArray () {
int retValue = 0;
int array [] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
for (int i = 0; i < 10; i++) {retValue += array [i];
}
return retValue;
}如果我们试图编译这个程序,我们可能会遇到一个警告,因为 Clang 希望有一个 main () 程序。这样操作系统才知道从哪里开始,正如我们在第 3 章中讨论的那样。因为它找不到这个名字的方法,所以它不能把所有的东西连接成一个独立的运行时。
brian@tweezer ~/g/w/s/ch05> clang simple.c -o simple.o
Undefined symbols for architecture x86_64:
"_main", referenced from:
implicit entry/start for main executable
ld: symbol (s) not found for architecture x86_64
clang-11: error: linker command failed with exit code 1 (use -v to see invocation)没问题。这是问题很容易解决。我们可以简单地告诉 Clang 编译代码,并使用 -c 选项告诉它不要链接。
brian@tweezer ~/g/w/s/ch05> clang -c simple.c -o simple.o brian@tweezer ~/g/w/s/ch05> ls -laF simple.*
-rw-r--r-- 1 brian staff 170 Feb 19 15:27 simple.c
-rw-r--r-- 1 brian staff 1060 Feb 19 15:43 simple.o这产生了一个对象文件,其中有函数定义。nm 命令向我们显示了编译后的文件中的内容。
brian@tweezer ~/g/w/s/ch05> nm -a simple.o
U ___stack_chk_fail
U ___stack_chk_guard
0000000000000000 T _addArray
U _memcpy
00000000000000a0 s l___const.addArray.array一开始你可能会让人困惑,但是通过我的解释,你的思路应该会清晰。我们的函数 addArray () 在对象文件中被定义为文本段符号。三个带有 U 符号类型的项目表示它们是未定义的。这些特殊的符号指的是一些出于安全考虑而自动链接的缓冲区溢出保护方法,以及一个将内存从一个位置复制到另一个位置的函数。这些函数的定义将被要求使代码可执行,但这是链接阶段和像 libc 这样的可重用库所提供的。
我们最终得到的是一个不完整的可执行文件,但却是一个正确形成的对我们函数的二进制表达。如果我们提供一个 main () 方法并链接可执行文件,我们就可以演示它是如何工作的。在例 5-6 中,驱动程序调用我们的函数。
例 5-6. 一个 main () 方法来调用我们的函数
#include <stdio.h>
extern int addArray ();
int main () {
int sum = addArray ();
printf ("The array sum is: % d\n", sum);
}注意,我们必须告诉编译器关于 addArray () 函数的定义,因为它没有在这个文件中定义。extern 关键字提供了一个承诺,即会有一个以这个名字命名的函数,不需要参数,并返回一个可用的整数。因此,把这个函数的结果分配给一个叫做 sum 的整数变量是可以的。然后将其传递给 printf () 函数,在那里它被格式化为对人友好的输出信息,表明累加的值。
为了构建可执行文件,我们编译了 simplemain.c 和 simple.c 文件,并将结果存储在一个名为 simplemain 的可执行文件中。因为我们没有包括 -c 选项,所以它确实参与了链接器。因为我们提供了 main () 方法的定义,所以它不再报错了。
brian@tweezer ~/g/w/s/ch05> clang simplemain.c simple.c -o simplemain
brian@tweezer ~/g/w/s/ch05> ls -laF simplemain
-rwxr-xr-x 1 brian staff 49640 Feb 19 16:01 simplemain* brian@tweezer ~/g/w/s/ch05> ./simplemain
The array sum is: 45如果我们在最终的可执行文件上使用 nm 程序,你会注意到这次已经提供了我们需要的一切。当程序运行时,未定义的符号将由一个动态库提供。它们被排除在二进制文件之外,以保持较小的体积。
brian@tweezer ~/g/w/s/ch05> nm -a simplemain
U ___stack_chk_fail
U ___stack_chk_guard
0000000100008018 d __dyld_private
0000000100000000 T __mh_execute_header
0000000100003ea0 T _addArray
0000000100003e70 T _main
U _memcpy
U _printf
U dyld_stub_binder现在我们有了一个可用的程序,回到我们的函数,如例 5-5。这是因为我们使用了一个字面语法来初始化数组。我们没有指定数组需要多大,因为编译器可以计算出来。在内存中,它已经分配了足够的空间来容纳这么多的整数。这个分配是在堆栈中完成的,所以当我们从函数中返回时,没有必要进行额外的清理。我们最终在内存中得到了一个足够大的位置来存储我们的数字,以进行求和,如图 5-3。

如果我们告诉编译器它需要多大,但又给它比这更多的数字,会发生什么?在例 5-7 中,我们告诉编译器我们只希望数组中有 5 个整数,但是又给它 10 个整数。这在某些领域里被称为 blivet。通过下面的讨论,我想说的是,当你编辑代码时,编译器如何提供问题反馈来帮助我们制定解决方案。这发生在我们尝试运行代码之前,这通常是我们在解释型语言中发现问题的地方。
例 5-7. 我们的函数的一个破损版本
int addArray () {
int retValue = 0;
intarray [5]={0,1,2,3,4,5,6,7,8,9};
for (int i=0;i<10;i++){retValue += array [i];
}
return retValue;
}幸运的是,编译器很容易发现这个问题。它将指出我们正在犯傻,并给出警告:
brian@tweezer ~/g/w/s/ch05> clang -c simple.c -o simple.o
int array [5] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
^
1 warning generated.如果我们想从函数中返回一个数组,会发生什么?在例 5-8 中,我们试图这样做,但很快就发现会失败。
例 5-8. 尝试从一个函数中返回一个数组,但不成功
int [] generateArray () {
int array []={0,1,2,3,4,5,6,7,8,9};
return array;
}尽管我们所做的似乎很合理,但编译器再次通知我们做得不对:
brian@tweezer ~/g/w/s/ch05> clang -c simple2.c -o simple2.o
simple2.c:1:22: error: brackets are not allowed here; to declare an array, place the brackets after the identifier
int [] generateArray () {~~ ^ []
simple2.c:1:20: error: function cannot return array type 'int []'
int [] generateArray () {
^
simple2.c:3:10: warning: incompatible pointer to integer conversion returning
'int [10]' from a function with result type 'int' [-Wint-conversion]
return array;
^~~~~
simple2.c:3:10: warning: address of stack memory associated with local variable
'array' returned [-Wreturn-stack-address]
return array;
^~~~~
2 warnings and 2 errors generated.数组名称是 C 语言中的特殊变量,它们是内存中存储这些数值的连续块的地址的占位符。我们可以引入一个指针,一个整数,并把它分配到数组的起始位置。为了访问该位置的值,我们必须使用解除引用操作符 *。
在例 5-9 中,你可以看到我们定义了一个指向整数的指针并将数组地址分配给它。当我们打印出 a 时,我们使用一个特殊的格式化结构 % p 来表示这是一个内存引用。
例 5-9. 使用指针指向数组
#include <stdio.h>
void generateArray () {
int array [] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int * a = array;
printf ("a is % p\n", a);
printf ("The first value is: % d\n", *a);
printf ("The second value is: % d\n", *(a + 1));
printf ("The third value is: % d\n", *(a + 2));
}
int main () {
generateArray ();
}数组中的第一个值位于数组的开头,所以我们可以用 * a 来访问它。第二个整数位于一个内存地址之上,所以我们在取消引用之前在数组的基数上加一。第三个值加二。
编译运行它,可以看到我们所期望的输出。a 的地址不太可能是相同的,但它看起来应该是类似的。
brian@tweezer ~/g/w/s/ch05> clang simple3.c -o simple3 brian@tweezer ~/g/w/s/ch05> ./simple3
a is 0x7ffeef3a9720
The first value is: 0
The second value is: 1
The third value is: 2编译器之所以报错,是因为在例 5-8 你不能像我们尝试的那样返回一个数组。相反,你必须返回一个指针。我们再一次尝试在例 5-10 来返回我们的数组。
例 5-10. 又一次尝试从一个函数中返回一个数组,但未获成功
#include <stdio.h>
int * generateArray () {
int array [] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
return array;
}
int main () {
int * a = generateArray ();
printf ("a is % p\n", a);
printf ("The first value is: % d\n", *a);
printf ("The second value is: % d\n", *(a + 1));
printf ("The third value is: % d\n", *(a + 2));
}而我们又一次失败了。
brian@tweezer ~/g/w/s/ch05> clang simple4.c -o simple4
simple4.c:5:10: warning: address of stack memory associated with local variable 'array' returned [-Wreturn-stack-address]
return array;
^~~~~
1 warning generated.这一次,编译器告诉我们,我们正在返回栈上的内存引用。如果你还记得我之前说过的,当我们从函数中返回时会发生什么,我们的指针指向的内存,在我们甚至有机会使用它之前就会被扔掉。
这就是为什么我们需要在堆上分配内存的能力。它将一直有效,直到我们告诉 C 语言运行时我们不再需要它了。在堆上分配内存的最简单方法是使用 malloc () 函数。
我们终于有了一个有效的代码样本,在例 5-11 中的 malloc () 函数是由标准库提供的,所以我们在它的定义中加入了另一个头文件。我们需要告诉这个函数要分配多少内存,所以我们使用一个整数的某个倍数。好消息是,我们现在也可以创建任意大的数组。你可以看到在这里我们把大小翻倍到 20,然后遍历 0 到 19 之间的数字来填充数组。最后返回结果,并将其在 main () 捕捉为一个 int * 。这就像我们在例子 5-9 中的 int * 一样。尽管我们现在指向的是堆而不是栈。
例 5-11. 一个成功的(但仍有缺陷的)尝试从一个函数中返回一个数组的例子
#include <stdio.h>
#include <stdlib.h>
int * generateArray () {
int * array = (int *) malloc (sizeof (int) * 20);
for (int i = 0; i < 20; i++) {
array [i] = i;
}
return array;
}
int main () {
int * a = generateArray ();
printf ("a is % p\n", a);
printf ("The first value is: % d\n", *a);
printf ("The second value is: % d\n", *(a + 1));
printf ("The third value is: % d\n", *(a + 2));
}编译和运行新程序终于给我们带来了一些快乐:
brian@tweezer ~/g/w/s/ch05> clang simple5.c -o simple5 brian@tweezer ~/g/w/s/ch05> ./simple5
a is 0x7fae22c059e0
The first value is: 0
The second value is: 1
The third value is: 2然而,我们的程序中仍然有一个缺陷。尽管我们打印出结果并退出,这不是一个大问题,但它是那种让 C 程序员(和他们的用户)发疯的问题。我们忘了释放我们所分配的内存!如果这是一个服务器或一个长期运行的程序,并且多次调用我们的函数,最终可能会耗尽内存。
为了解决这个问题,我们只需要调用 free () 函数来告诉运行时我们已经用完了这些内存。这样做之后,我们就不能再碰它了。这突出了 C 语言编程时需要考虑的许多问题:
• 在你分配内存之前,不要使用。
• 不要用你所分配的内存创建 Blivets。确保它们足够大。
• 完成后不要忘记释放内存。
• 在你释放了内存之后,不要再使用它。
忘记这些规则中的任何一条,都可能导致你的程序崩溃或内存耗尽。如果这看起来是个大麻烦,你会欣赏诸如 Java、Python 和 JavaScript 这样的语言,它们为你减轻了一些问题。缺点是,通常会有性能上的折衷,这就是为什么 Rust 如此引人注目。它为你提供了像 C 语言一样的速度,而没有像 C 语言一样的危险。我们会在第 10 章介绍 Rust。
在那之前,我们需要弄清楚这一切对 WebAssembly 意味着什么。
C/C++ 和 WebAssembly
在下一节中,我将使用一个更复杂的基础设施,基于 Petter Strandmark 提供的样例项目 [4] 的复杂基础架构来使用 Clang 和 WebAssembly。在下一章中,我们将介绍 Emscripten 工具链,使其更容易将现有的代码移植到 WebAssembly。最终,我们将引入 WebAssembly 系统接口(WASI)来处理这些细节,但在那之前,我们需要基础设施来帮助我们克服目前看到的障碍。
这个基础设施有几个部分,但基本上是自成一体的,而且我认为最终是相当清晰的。由于一些原因,不值得在此讨论。现在,我们将使用 C++ 版本的 Clang 编译器。在这一章中,我们没有时间教你 C++,所以我不打算关注太多具体细节。在有些情况下,我们需要让 C++ 代码表现得像 C 语言一样,所以在这个问题上,请跟着我。
我们将从一些 C/C++ 代码开始。这两种语言的关系相当密切,但 C++ 提供了面向对象的编程功能,使其更容易使用自然概念(如订单、账户、用户等)对一个领域进行建模。然而,我们并不打算关注这些区别,这就是为什么我一直把这两种语言放在一起提及。在例 5-12 中,你可以看到我们将要使用的一些功能。为了便于管理,我不会在此时向你展示所有的功能。
例 5-12 一些供我们调用的 C/C++ 函数
#include "nanolibc/libc.h"
#include "nanolibc/libc_extra.h"
#define WASM_EXPORT __attribute__((visibility ( "default") ) ) extern "C"
WASM_EXPORT int* get_memory_for_int_array (int size)
{return (new int [size]);
}
WASM_EXPORT void free_memory_for_int_array (int* arr)
{delete [] arr;
}
WASM_EXPORT void mergeSort (char *p, int length)
{
int c, d, swap;
for (c = 0; c < length - 1; c++)
{for ( d = 0; d < length - c - 1; d++)
{if ( p [d] > p [d + 1] )
{swap = p [d]; p [d] = p [d + 1]; p [d + 1] = swap;
}
}
}
}
WASM_EXPORT void reverse (unsigned char* p, int len)
{for ( inti = 0; i < len / 2; i++)
{unsigned char temp = p [i]; p [i] = p [len - i - 1]; p [len - i - 1] = temp;
}
}第一件让你眼前一亮的是 #include 语句。这段代码使用了 libc 库的一个非常小的实现,它为我们提供了 malloc ()、free ()、甚至 printf () (但先别急着想这个问题)。C/C++ 中的头文件允许我们公布函数的签名,这样编译器就知道应该期待什么。
如例 5-13,我们有一系列可用的函数来链接。为了确保它们作为 C 语言函数可见,我们使用 extern "C" 关键字 ,以防止 C++ 编译器混淆它们的名字。
例 5-13. libc 的一个小型实现的头文件
#ifndef _NANOLIB_C_H
#define _NANOLIB_C_H
#include <stdarg.h>
#include <stddef.h>
extern "C" {
void* memcpy(void* dest, const void* src, size_t count);
void* memset (void * dest, int value, size_t count);
int puts ( const char * str );
int printf(const char* format, ...);
int sprintf(char* buffer, const char* format, ...);
int snprintf(char* buffer, size_t count, const char* format, ...);
int vsnprintf(char* buffer, size_t count, const char* format, va_list va);
void* malloc(size_t amount);
void* realloc(void *ptr, size_t size);
void* calloc(size_t num, size_t size);
void free(void* mem);
}
#endif回顾一下例 5-12,我们有一个名为 get_memory_for_int_array () 的方法,它需要一个 size 参数来告诉我们需要分配多少内存。如果你仔细看一下这个实现,它使用的是 C++ 的 new 操作符。为了我们的目的,只需假设这与调用 malloc () 的意思相同。free_mem ory_for_int_array () 函数通过使用 delete 操作符,起到了与 free () 调用类似的作用。
有一个 #define 宏赋予这些函数外部可见性,以确保对要调用它们的 JavaScript 代码可用。
接下来,我们有一个函数提供了一个合并排序的实现,还有一个函数可以反转数组。
C/C++ 应用程序和库的构建系统并不像 Rust 的 cargo 命令那样现代和友好,但它们是坚实和灵活的。我们将使用一个简单的基于 Makefile 的方法。这些细节我们没有时间深入介绍,但基本上我们定义了一套规则来构建目标。当源代码发生变化时,它会导致重新评估依赖关系并构建任何需要构建的东西。这个文件的内容可以通过本书的代码仓库 [5] 找到。
为了构建我们的代码,我们将使用 make 命令,这样我们就能知道进展如何:
brian@tweezer ~/g/w/s/c/helloworld> make
... Lots of noise goes by...
brian@tweezer ~/g/w/s/c/helloworld> ls -laF *.wasm
-rwxr-xr-x 1 brian staff 5309 Feb 19 20:03 library.wasm*我将把它留给你去详细探索模块的内容,但我想强调几个要点。注意我们的模块导出了自己的 Memory。你可以改变这种行为,从 JavaScript 方面导入一个 Memory 实例,但我们现在不打算这么做。
目前你需要关注的是,我们的 C/C++ 代码有一个很小的 libc 实现 ,它将从一个导出的 Memory 实例中分配和释放内存,而这一实例,在第 4 章 [6] 后,应该可以运行起来:
brian@tweezer ~/g/w/s/c/helloworld> wasm-objdump -x library.wasm
...
Export [11]:
- memory [0] -> "memory"
- func [1] <get_memory_for_int_array> -> "get_memory_for_int_array"
- func [14] <_Znam> -> "_Znam"
- func [3] <free_memory_for_int_array> -> "free_memory_for_int_array"
- func [16] <_ZdaPv> -> "_ZdaPv"
- func [5] <debug_dump_memory> -> "debug_dump_memory"
- func [7] <mergeSort> -> "mergeSort"
- func [8] <reverse> -> "reverse"
- func [9] <helloWorld> -> "helloWorld"
- func [11] <_Znwm> -> "_Znwm"
- func [15] <_ZdlPv> -> "_ZdlPv"
...接下来我们将需要一些 HTML 代码来调用我们的 C/C++ 行为。大部分的结构与我们之前看到的相似,但我将强调你需要理解的部分,即例 5-14。
例 5-14. 我们的 HTML 文件的相关部分
<script>
let wasm;
...
WebAssembly.instantiateStreaming (fetch ('library.wasm'), importObject).then (function (obj) {①
wasm = obj;②
const ptr = wasm.instance.exports.get_memory_for_int_array (10);③
const memory = new Uint8Array (wasm.instance.exports.memory.buffer);④
const nums = memory.subarray (ptr);⑤
for (vari = 0; i < 10; i++) {nums [i] = i;
}
console.log (nums);
wasm.instance.exports.reverse (ptr, 10);⑥
console.log (nums);
vararr = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10];⑦
shuffleArray (arr);
for (vari = 0; i < 10; i++) {nums [i] = arr [i];
}
console.log (nums);
wasm.instance.exports.mergeSort (ptr, 10);⑧
console.log (nums);
wasm.instance.exports.free_memory_for_int_array (ptr);⑨
...
}
</script>1. 模块在 JavaScript 主机中的创建方式和平时一样。
2. 一旦模块实例可用,我们希望在其他地方访问它。
3. 在模块中为 10 个整数初始化了足够的空间。我们捕获返回的 "指针"。
4. 底层缓冲区被 Uint8Array 包裹着。
5. 一个子 Uint8Array 被创建,涵盖了之前返回的 "指针" 所引用的部分。
6. 模块中的
reverse ()方法被调用。7. 我们依靠 JavaScript 功能来打乱一些数据。
8.
mergeSort ()方法被调用,有一个指向 "指针" 的引用。9. 内存在模块端被释放。
我们首先通过 HTTP 提供 HTML 和 WebAssembly 模块,就像我们之前做的那样。该模块的加载和实例化使用的是与之前相同的实用程序库,尽管它是通过一个完全不同的过程生成的。一旦模块实例可用,我们就把变量分配给本块语法范围之外定义的另一个变量,这样我们就可以在其他地方使用它。
因为我们代码的 C/C++ 端并没有意识到正在发生的事情,我们必须从它的角度分配足够的内存来存储来自 JavaScript 端的一些数据。之前我们只是将数据直接写入导出的 Memory 实例中。因为我们要模拟指针,所以我们必须在那一边创建一些看起来合适的东西。我们调用 get_memory_for_int_array () 函数,要求它为 10 个整数分配空间。该函数在 C/C++ 端返回一个指针。从这个方面来看,它更应该被认为是一个 "指针"。它并不像你前面看到的那样直接是对堆中某个位置的引用。相反,它是对底层缓冲区的一个索引,libc 实现将数据分配到该缓冲区。当我们把它传回给另一方时,我们将使用这个引用作为对内存的偏移。
我们用一个 Uint8Array 包装器包围底层 ArrayBuffer,这样我们就可以从这边轻松地写 8 比特整数。如果你重新审视一下例 5-12 的代码,你可能会注意到我们的排序和反转函数接受 char *.C 可以通过在 ints、chars、address、booleans 等之间进行自动类型强制来实现相当的灵活性。它是非常灵活的,而且常常有很大的错误。这些字符不能大于 8 比特,所以它们的最大尺寸为 255。我们用一个 Uint8Array 来包裹缓冲区,这样就不用担心这个问题了。
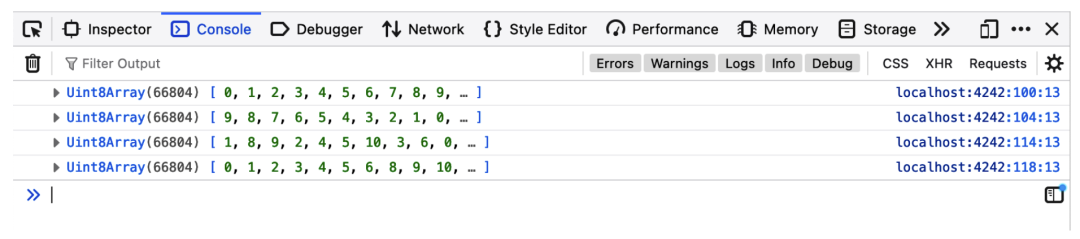
在这之后,一个 Uint8Array 类型的子数组被生成,用于从我们的 "指针" 开始的部分。这使得我们可以忽略在我们的数组之前可能已经分配的所有东西,我们可以使用 JavaScript 数字方便地开始向其中写入。这样做的结果会被转到控制台,向你展示正在发生的事情。
下一步是调用 reverse () 函数。这个实现的写法让人觉得它只是在内存中交换数值,而且,值得注意的是,它不需要改变。我们不需要这个函数的返回值,因为数组被反转到位了。这就是 C 语言能够如此快速的原因之一。它避免了创建大量不必要的内存,而且检索数值和迭代内存位置的开销非常低。在 JavaScript 方面,我们的 "指针" 仍将指向新反转的数组的开始,为了清晰起见,它被转储到控制台。
为了展示排序功能,我们需要一些打乱的数据。当然,用 C 语言写这样的代码是可能的,但是我们需要依靠一个随机数生成器来实现洗牌算法。这将使我们的依赖性变得复杂,所以我们只是依赖 JavaScript 对随机数生成的支持。你可能有时会依赖浏览器的行为,有时则依赖 WebAssembly 模块中的代码。
一个新创建的数组被填充、洗牌并转储到控制台。我们将洗过的值写回我们的 C/C++ 数组中的 "指针" 所指示的位置,然后调用 mergeSort () 功能。这也是假设它可以访问内存中的一个位置,所以它可以有效地重新排列要排序的数据。
当我们返回到 JavaScript 时,我们将结果转储到控制台,然后释放我们分配的内存,因为我们不再使用它了。
在图 5-4 中,你可以看到到目前为止我们最复杂的例子的显著结果。我们得到了重用代码的好处,这些代码在浏览器中以接近原生的速度执行。对于小数据集来说,这可能微不足道,但在其他情况下,很容易就能证明这一点。
最后,WebAssembly 中的 "Hello, World!"
通过以上讲解我希望现实中的可能性已经开始变得清晰。我们还有很多东西要给你看,但现在是时候兑现我的承诺,给你一个 "Hello, World!" 的例子了。为了简单起见,我不准备写一个典型的 main () 程序。相反,我将在我们的 library.cpp 文件中以另一个函数的形式暴露行为。例 5-15 向你展示了这是多么简单。
例 5-15. "Hello, World!" 作为 C/C++ 代码中的一个函数
WASM_EXPORT void helloWorld () {printf ("Hello, World!\n");
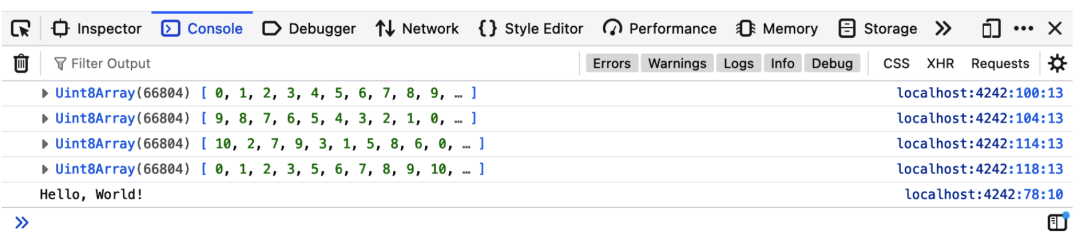
}如果我在 HTML 中的其他代码之后添加对这个新函数的调用,你可以看到如图 5-5 的结果。
这到底是怎么做到的?如果这么简单,为什么我们要等到第五章的结尾呢?
让我在 HTML 中向你展示一些更多的细节。例 5-16 有一个新的函数调用 get_memory (),它只是返回一个 Uint8Array 实例。有解码器和编码器变量可用于转换 UTF-8 字符串。有一个叫做 charPtrToString () 的函数,可以将一个 "字符指针"(即 C 语言字符串)转换成 UTF-8 字符串,供 JavaScript 使用。
在下方我们有一个 printString () 的函数,它将被调用,并将一个 JavaScript 字符串输出到控制台。我们的 importObject 被配置为名为 print_string 的方法,它将在调用方法之前把一个 "字符指针" 转换成一个字符串,并将其转储到控制台。你会记得,importObject 允许模块实例共享函数和数据。
例 5-16 让 "Hello, World!" 的后端
<script>
function get_memory () {
return new Uint8Array (wasm.instance.exports.memory.buffer);
}
const decoder = new TextDecoder ("utf-8");
const encoder = new TextEncoder ("utf-8");
function charPtrToString (str) {
const memory = get_memory ();
let length=0;
for (; memory [str + length] !== 0 ;++length) {}
return decoder.decode (memory.subarray (str, str + length));
}
let printString = function (str) {console.log (str);
};
const importObject = {
env: {print_string: function (str) {printString (charPtrToString (str));
}
}
};
...
</script>这涵盖了 JavaScript 方面。在 C/C++ 方面,我们看到在例 5-17 的 nanolibc/libc_extra.h 头中定义了一个名为 print_string () 的函数,它接收一个 char *。
例 5-17. 将 JavaScript 函数暴露为 C 函数
#ifndef _NANOLIB_C_EXTRA_H
#define _NANOLIB_C_EXTRA_H
extern "C" {
// Will be provided by Javascript.
void print_string (const char* str);
}
#endif在 nanolibc 目录下有一个文件,定义了我们的 printf () 实例。其中的细节很复杂,所以我不想深入研究,但我要指出的是,它调用 puts () 将一个 char * 输出到控制台。通常这是一个低级别的服务,但根据你目前所看到的,一旦我们在例 5-18 中把最后一块连接起来,我们的 JavaScript 处理程序就会把它输出到控制台。
例 5-18. 将 JavaScript 函数暴露为 C 函数
int puts (const char * str){
print_string (str); ①
return 0;
}1.
puts ()用一个char *调用 JavaScript 函数。
终于,我们看到了这是如何工作的。我们的函数调用 printf (),后者调用 puts (),后者被定义为调用所提供的函数。我现在不打算描述它是如何调用的,但我希望其结果还是令人满意的。关于使用 C/C++ 和 WebAssembly 还有更多的知识,但那是接下来的章节的主题。在那之前,你刚刚跨越了一个重要的鸿沟,了解了 WebAssembly 在幕后的工作情况。接下来,我们将学习如何将现有的软件移植到浏览器中运行。
引用链接
[1] C 编程语言: https://en.wikipedia.org/wiki/The_C_Programming_Language[2] 第 6 章: ../apply-wasm-lagacy-code-in-the-browser/[3] 附录: ../appendix/[4] Petter Strandmark 提供的样例项目: https://github.com/PetterS/clang-wasm[5] 代码仓库: https://github.com/bsletten/wasm_tdg[6] 第 4 章: ../wasm-definitive-guide/wasm-memory/
获取更多云原生社区资讯,加入微信群,请加入云原生社区,点击阅读原文了解更多。