
本文是《WebAssembly 权威指南》系列文章第 4 篇,系列文章列表:
WebAssembly 就像一个运行时环境,它需要一种方法来分配和释放内存以进行数据处理。在本章中,我将向你展示它如何模拟这种行为以提高效率,但不会出现 C 和 C++ 等语言典型的内存操作问题风险(即使我们正在运行它们)。由于我们有可能在 Internet 上下载任意代码,因此这是一个重要的安全考虑因素。
计算的整个概念通常涉及某种形式的数据处理。无论我们是在对文档进行拼写检查、处理图像、进行机器学习、对蛋白质进行测序、玩视频游戏、看电影,还是只是在电子表格中处理数字,我们都经常与任意数据块进行交互。这些系统中最关键的性能考虑因素之一是如何将数据获取到需要的位置,以便可以以某种方式对其进行查询或转换。
当数据在寄存器或高速缓存中可用时,中央处理器 (CPU) 工作得最快。显然,这些都是非常小的容器,因此大型数据集永远不会完全加载到 CPU 上。我们必须花费一些精力将数据移入和移出内存。等待数据加载到这些位置之一的成本是 CPU 时钟时间。这就是它们变得如此复杂的原因之一。现代芯片具有各种形式的多线程、预测分支和指令重写,当我们从网络读取到主内存,从主内存到多级缓存,最后到我们需要使用它的地方时,这些芯片可以保持 CPU 处于忙碌状态。
传统程序通常有堆栈内存来管理小的或固定大小的短期变量。它们使用基于堆的内存来管理长期存在的、任意大小的数据块。这些通常只是分配给程序的不同内存区域,它们的处理方式不同。堆栈内存经常被执行期间调用的函数覆盖。堆内存在不再需要时被使用和清理。如果一个程序用完了内存,它可以请求更多的内存,但它必须对如何使用它做出合理的决定。今天,虚拟分页系统和更便宜的内存使一台典型的计算机拥有数十 GB 以上的内存成为可能。能够快速有效地访问潜在大数据集的单个字节是软件运行时性能的关键。
TypedArray
传统上,JavaScript 不提供对内存中单个字节的轻松访问。这就是为什么时间敏感的低级功能通常由浏览器或某种插件提供。即使是 Node.js 应用程序也经常使用比 JavaScript 更好地处理内存操作的语言来实现某些功能。这使事情变得复杂,因为 JavaScript 是一种解释型语言,你需要一种有效的机制来在解释型、可移植代码和快速编译代码之间来回切换控制流。它还使部署变得更加棘手,因为应用程序的一部分本质上是可移植的,而另一部分则需要不同操作系统上的本机库支持。
在软件开发中通常需要权衡:语言要么快速要么安全。当你需要原始速度时,你可能会选择 C 或 C++,因为它们在内存中使用和操作数据时几乎不提供运行时检查。因此,它们非常快。当你需要安全时,你可以选择一种对数组引用进行运行时边界检查的语言。速度权衡的缺点是事情要么很慢,要么内存管理的负担落在程序员身上。不幸的是,忘记分配空间、重用释放的内存或在完成后未能释放空间是非常容易出错的。这就导致了用这些快速语言编写的应用程序经常出现错误、容易崩溃,并且是许多安全漏洞的来源之一。
Java 和 JavaScript 等具有垃圾回收功能的语言将开发人员从管理内存的负担中解放出来,但作为交换,运行时的性能往往会受到影响。运行时的一部分必须不断地找到未使用的内存并释放它。性能开销使得许多此类应用程序不可预测,因此不适合嵌入式应用程序、金融系统或其他对时间敏感的用例。
只要创建的内存大小适合你要放入的内容,分配内存就不是什么大问题。棘手的部分是何时清理。显然,在程序完成之前释放内存是不合适的,但是当不再需要它时不这样做就变得低效,你可能会耗尽内存。像 Rust 这样的语言在便利性和安全性之间取得了很好的平衡。编译器会强制你更清楚地表达你的意图,但当你这样做时,它会更有效地为你清理。
如何在运行时对其进行管理通常是语言及其运行时的定义特征之一。因此,并非每种语言都需要相同级别的支持。这就是为什么 WebAssembly 的设计者没有在 MVP 中过度指定垃圾收集等功能的原因之一。
JavaScript 是一种灵活且动态的语言,但它在历史上并未使处理大型数据集的单个字节变得简单或高效。这使底层库的使用变得复杂,因为必须将数据复制为 JavaScript 的本机格式,效率不高。使用 Array 类存储 JavaScript 对象,这意味着它必须准备好处理任意类型。Python 的许多容器也是灵活和臃肿的。通过指针快速遍历和操作内存是连续块中数据类型统一的产物。字节是最小的可寻址单位,尤其是在处理图像、视频和声音文件时。
处理数值数据需要更多的努力。一个 16 位整数占用两个字节。一个 32 位整数需要四个字节。字节数组中的位置 0 可能表示数据数组中的第一个这样的数字,但第二个数字将从位置 4 开始。
JavaScript 添加了 TypedArray 接口来解决这些问题,最初是为了提高 WebGL 性能。这些是内存的一部分,可通过 ArrayBuffer 实例访问,可以将其视为特定数据类型的同类块。可用内存受 ArrayBuffer 实例限制,但它可以以方便传递到本机库的内部格式存储。
在例 4-1 中,我们看到了创建 32 位无符号整数类型数组的基本功能。
例 4-1. 在 Uint32Array 中创建十个 32 位整数
var u32arr = new Uint32Array (10);
u32arr [0] = 257;
console.log (u32arr);
console.log ("u32arr length:" + u32arr.length);输出如下:
Uint32Array (10) [257, 0, 0, 0, 0, 0, 0, 0, 0, 0]
u32arr length: 10如你所见,对于整数数组,这正如你所期望的那样工作。请记住,这些是 4 字节整数(因此类型名称中的 32)。在例 4-2 中,我们从 Uint32Array 获取底层的 ArrayBuffer 并将其打印出来。这表明它的长度是 40。接下来,我们用表示无符号字节数组的 Uint8Array 包装缓冲区,并打印出它的内容和长度。
例 4-2. 访问 32 位整数作为 8 位字节的缓冲区
var u32buf = u32arr.buffer;
var u8arr = new Uint8Array (u32buf);
console.log (u8arr);
console.log ("u8arr length:" + u8arr.length);输出如下:
ArrayBuffer {byteLength: 40}
Uint8Array (40) [1, 1, 0, 0, 0, 0, 0, 0, 0, 0, ...]
u8arr length: 40ArrayBuffer 表示原始底层字节。TypedArray 是这些字节基于指定类型大小的相互预设视图。所以当我们初始化 Uint32Array 的长度为 10 时,这意味着 10 个 32 位整数,需要 40 个字节来表示。分离缓冲区非常大,可以容纳所有 10 个整数。由于 Uint8Array 的大小定义,它将每个字节视为一个单独的元素。
看看图 4-1,你就会明白发生了什么。Uint32Array 的第一个元素(位置 0)只是值 257。这是 ArrayBuffer 中底层字节的解释视图。Uint8Array 直接反映缓冲区的底层字节。图底部的位模式反映了前两个字节中每个字节的位。
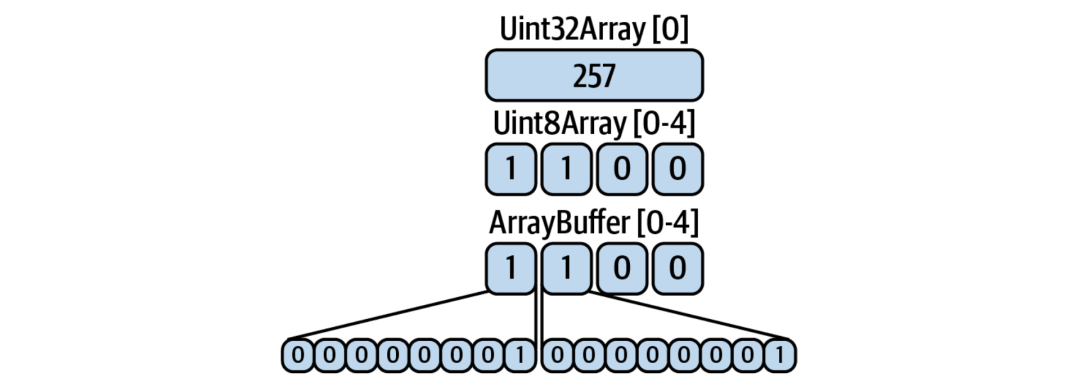
你可能会对前两个字节中出现 1 感到惊讶。这是由于我们在内存中存储数字时出现的一个令人困惑的概念,称为字节序(endianess)。在这种情况下,小端序系统将最低有效字节放在首位 (1)。大端序系统将首先存储 0。总的来说,它们的存储方式并不重要,但不同的系统和协议会选择其中一种。你只需要跟踪你看到的是哪种格式。
{ {<callout note "什么是字节序?">}}
在计算机领域,endianess(字节序)指的是计算机存储多字节数据类型(如整数、浮点数等)时,字节的存储顺序。
在计算机中,每个多字节数据类型都可以被表示为一系列字节,每个字节都有一个地址。对于一个多字节数据类型,字节可以按照两种不同的方式存储:大端序和小端序。
在大端序中,最高有效字节(即最高位字节)存储在最低地址中,而最低有效字节(即最低位字节)存储在最高地址中。在小端序中,最低有效字节存储在最低地址中,而最高有效字节存储在最高地址中。
例如,对于一个 16 位整数(即两个字节),如果它的值为 0x1234,则在大端序中,它的存储顺序为 0x12 0x34,而在小端序中,它的存储顺序为 0x34 0x12。
计算机的字节序由硬件架构决定,不同的处理器可能采用不同的字节序。在网络通信中,为了确保不同的处理器能够正确解释数据,需要使用特定的协议来定义字节序,例如网络字节序(大端序)。
{ {}}
如前所述,TypedArray 类最初是为 WebGL 引入的,但从那时起,它们已被其他 API 所采用,包括 Canvas2D、XMLHttpRe-quest2、File、Binary WebSockets 等等。请注意,这些是较低级别的、面向性能的 I/O 和可视化 API,它们必须与本机库交互。底层内存表示可以在这些层之间有效地传递。正是由于这些原因,它们对于 WebAssembly 内存实例也很有用。
WebAssembly 内存实例
WebAssembly 内存是与模块关联的底层 ArrayBuffer(或 SharedArrayBuffer,我们稍后会看到)。目前,MVP 仅限于每个模块一个实例,但这在不久的将来可能会改变。模块可以创建自己的 Memory 实例,也可以从其主机环境中获取。这些实例可以导入或导出,就像我们到目前为止对函数所做的一样。模块结构中还有一个相关的 Memory 部分,我们在第 3 章中跳过了它。因为我们还没有涵盖这个概念。现在我们来弥补这个疏漏。
在例 4-3 中,我们有一个 Wat 文件,它定义了一个 Memory 实例并以名称 “memory” 导出它。这意味着一个连续的内存块被限制在一个特定的 ArrayBuffer 实例中。这是我们在内存中模拟类似 C/C++ 的同类字节数组的能力的开始。每个实例由一个或多个 64KB 内存页块组成。在此示例中,我们将其初始化为一页,但允许它增长到 10 页,总共 640 KB,这对任何人来说都足够了。你会立即看到如何增加可用内存。现在,我们只是将字节 1、1、0 和 0 写入缓冲区的开头。i32.const 指令将常量值加载到堆栈中。我们要写入缓冲区的开头,所以我们使用值 0x0。data 指令是初始化 Memory 实例的一部分的便捷方法。
例 4-3. 在 WebAssembly 模块中创建和导出 Memory 实例
(module
(memory (export "memory") 1 10)
(data (i32.const 0x0) "\01\01\00\00")
)如果我们用 wat2wasm 将这个文件编译成二进制表示,然后调用 wasm-objdump,我们会看到一些我们还没有遇到的新细节。
brian@tweezer ~/g/w/s/ch04> wasm-objdump -x memory.wasm
memory.wasm: file format wasm 0x1
Section Details:
Memory [1]:
- memory [0] pages: initial=1 max=10
Export [1]:
- memory [0] -> "memory"
Data [1]:
- segment [0] memory=0 size=4 - init i32=0
- 0000000: 0101 0000在 Memory 部分中,有一个已配置的 Memory 实例,反映了我们的初始大小为 1 页,最大大小为 10 页。我们看到它在 Export 部分被导出为 “memory”。我们还看到数据部分已经用我们写入的四个字节初始化了我们的内存实例。
现在我们可以通过在浏览器中的一些 JavaScript 中导入它来使用我们导出的内存。在此示例中,我们将加载模块并获取 Memory 实例。然后我们显示缓冲区大小(以字节为单位)、页数以及内存缓冲区中当前的内容。
HTML 文件的基本结构如例 4-4 所示。我们有一系列 <span> 元素,这些元素将通过名为 show Details() 的函数填充详细信息,该函数将获取对内存中实例的引用。
例 4-4. 在浏览器中显示内存详细信息
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="stylesheet" href="bootstrap.min.css" />
<title>Memory</title>
<script src="utils.js"></script>
</head>
<body>
<div class="container">
<h1>Memory</h1>
<div>Your memory instance is <span id="mem"></span> bytes.</div>
<div>It has this many pages: <span id="pages"></span>.</div>
<div>Uint32Buffer [0] = <span id="firstint"></span>.</div>
<div>Uint8Buffer [0-4] = <span id="firstbytes"></span>.</div>
</div>
<button id="expand">Expand</button>
<script>
<!-- Shown below --> </script>
</body>
</html>在例 4-5 中,我们看到 <script> 元素的 JavaScript。首先看一下 fetchAndInstantiate () 的调用。在加载模块方面,它的行为与我们之前看到的相同。在这里,我们通过 Export 部分获得对 Memory 实例的引用。我们为我们的按钮附加了一个 onClick () 函数,点击按钮后就会马上处理。
例 4-5. 我们示例的 JavaScript 代码
function showDetails (mem) {
var buf = mem.buffer;
var memEl = document.getElementById ('mem');
var pagesEl = document.getElementById ('pages');
var firstIntEl = document.getElementById ('firstint');
var firstBytesEl = document.getElementById ('firstbytes');
memEl.innerText=buf.byteLength;
pagesEl.innerText=buf.byteLength/65536;
var i32 = new Uint32Array (buf);
var u8 = new Uint8Array (buf);
firstIntEl.innerText=i32 [0];
firstBytesEl.innerText= "[" + u8 [0] + "," + u8 [1] + "," +
u8 [2] + "," + u8 [3] + "]"; fetchAndInstantiate ('memory.wasm').then (function (instance) {};
var mem = instance.exports.memory;
var button = document.getElementById ("expand"); button.onclick = function () {try { mem.grow (1);
showDetails (mem); } catch (re) {alert ("You cannot grow the Memory any more!");
};
};
showDetails (mem);
});最后,我们调用 showDetails() 函数并传入我们的 mem 变量。此函数将检索底层 ArrayBuffer 和 <span> 对我们各种元素的引用以显示详细信息。缓冲区的长度存储在我们的第一个 <span> innerText 字段中。页数就是这个长度除以 64KB 表示页数。然后,我们用 Uint32Array 包装 ArrayBuffer,这允许我们将内存值作为 4 字节整数获取。它的第一个元素显示在下一个 <span> 中。我们还用 Uint8Array 包装我们的 ArrayBuffer 并显示前四个字节。经过我们之前的讨论,你应该不会对图 4-2 中显示的细节感到惊讶。
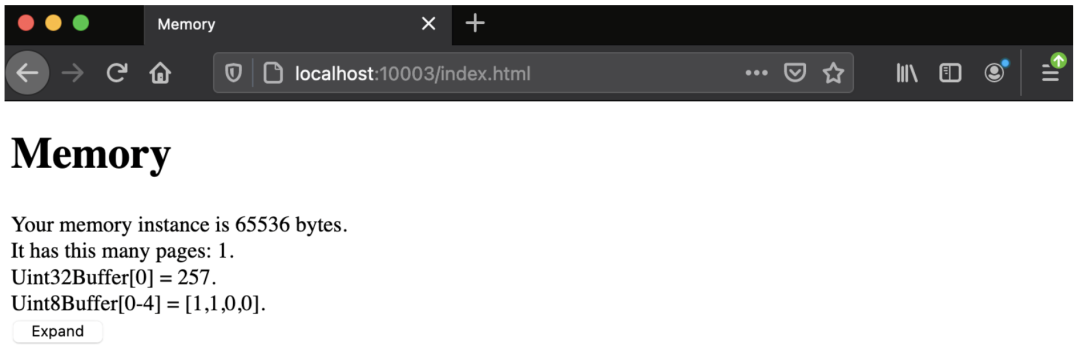
onClick() 函数调用 Memory 实例上的一个方法,该方法将分配的内存大小增加一页。这会导致原始 ArrayBuffer 与实例分离,并复制现有数据。如果成功,我们将再次调用 showDetails() 函数并提取新的 ArrayBuffer。如果按钮被按下一次,你应该看到该实例现在代表两页内存,代表 128KB 内存。初始化的开头的数据应该不变。
如果按按钮次数太多,分配的页数将超过 10 页的最大指定量。此时无法再扩展内存,会抛出 RangeError。当这种情况发生时,我们的例子会弹出一个警告窗口。
使用 WebAssembly 内存 API
在后面的章节中,我们将看到更细粒度的内存使用,但我们希望使用比 Wat 更高级的语言来处理严肃的事情。现在,我们将保持我们的示例更简单,但仍会尝试扩展我们所看到的内容。
我们将从 HTML 开始,以便你了解整个工作流程,然后我们将深入探讨新模块的细节。在例 4-6 中,你可以看到我们使用了一个与之前使用的类似的 HTML 结构。有一个 ID 为的 container 的 <div>,我们将在其中放置一系列斐波那契数列的元素。如果你不熟悉这些数字,它们在许多自然系统中都非常重要,我鼓励你自己研究它们。前两个数字定义为 0 和 1,后面的数字设置为前两个数字的和。所以第三个数字将是 1 (0+1)。第四个数字将是 “2”(1+1)。第五个数字将是 3 (2+1),依此类推。
例 4-6. 在 JavaScript 中创建内存并将其导入模块
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<link rel="stylesheet" href="bootstrap.min.css">
<title>Fibonacci</title>
<script src="utils.js"></script>
</head>
<body>
<div id="container"></div>
<script>
var memory = new WebAssembly.Memory ({initial:10, maximum:100});
var importObject = {js: { mem: memory}
};
fetchAndInstantiate ('memory2.wasm', importObject).then (function (instance) {
var fibNum = 20;
instance.exports.fibonacci (fibNum);
var i32 = new Uint32Array (memory.buffer);
var container = document.getElementById ('container');
for (var i = 0; i < fibNum; i++) {container.innerText += `Fib [${i}]: ${i32 [i]}\n`;
}
});
</script>
</body>
</html>实际的计算是用 Wat 编写的,如例 4-7 所示,但在进行到那一步之前,我们看到了 <script> 元素的第一行创建了 Memory 实例。我们使用的是 JavaScript API,但其意图与我们在 <script> 中使用的 (memory) 元素是一样的。在例 4-3 中我们创建一个初始大小为一页的内存,最大大小为 10 页。在这种情况下,我们永远不会需要超过一页的内存,但你现在看到了如何做到这一点。内存实例是通过 importObject 提供给模块的。正如你即将看到的,Wasm 模块中的函数将接受一个参数,表明要向 Memory 缓冲区写入多少个斐波那契数。在这个例子中,我们将传入一个 20 的参数。
一旦我们的模块被实例化,我们就调用它导出的 fibonacci() 函数。我们可以访问上面的内存变量,所以我们可以在函数调用完成后直接检索底层的 Array Buffer。由于斐波那契数是整数,我们将缓冲区包装在 Uint32Array 实例中,以便我们可以迭代各个元素。当我们检索这些数字时,我们不必担心它们是 4 字节整数。读取每个值时,我们用数字的字符串版本扩展 container 元素的 innerText。
例 4-7 中的计算比我们目前看到的任何 Wat 都复杂得多,但是通过分块计算,你应该能够弄清楚。
例 4-7. 用 Wat 表示的斐波那契计算方法
(module
(memory (import "js" "mem") 1) ①
(func (export "fibonacci") (param $n i32) ②
(local $index i32) ③
(local $ptr i32) ④
(i32.store (i32.const 0) (i32.const 0)) ⑤
(i32.store (i32.const 4) (i32.const 1))
(local.set $index (i32.const 2)) ⑥
(local.set $ptr (i32.const 8))
(block $break ⑦
(loop $top ⑧
(br_if $break (i32.eq (local.get $n) (local.get $index))) ⑨
(i32.store ⑩
(local.get $ptr)
(i32.add
(i32.load (i32.sub (local.get $ptr) (i32.const 4)))
(i32.load (i32.sub (local.get $ptr) (i32.const 8)))
)
)
(local.set $ptr (i32.add (local.get $ptr) (i32.const 4))) #11
(local.set $index (i32.add (local.get $index) (i32.const 1)))
(br $top) #12
)
)
)
)1. Memory 是从主机环境中导入的。
2. fibonacci 函数被定义并导出。
3.
$index是我们的数字计数器。4.
$ptr是我们在 Memory 实例中的当前位置。5.
i32.store函数将一个值写到缓冲区的指定位置。6.
$index变量被设置为 2,用于控制循环计算的起始值,$ptr被设置为 8。7. 定义一个命名的块,以便在我们的循环中返回。
8. 在块中定义一个命名的循环。
9. 当
$index变量等于$n时,我们就脱离了循环。10. 将前两个元素的总和写到
$ptr的当前位置。11. 将
$ptr增加 4,$index变量增加 1。12. 离开循环到顶部。
希望例 4-7 中附加的数值说明是有意义的,但它的复杂性需要进行简短的讨论。这是一个基于栈的虚拟机,所以所有的指令都涉及栈顶的操作。在第一次调用中,我们导入了在 JavaScript 中定义的内存。它代表默认分配的页面,现在应该足够了。虽然这是一种正确的实现方式,但并不安全。错误的输入会扰乱流程,但我们会在引入更高级别的语言支持时更加关注这一点,因为在那里处理这些细节更容易。
输出函数被定义为接受参数 $n,表示要计算的斐波那契数的数量。我们使用在第三次和第四次调用中定义的两个局部变量。第一个代表我们正在处理的数字,默认为 0。第二个将充当内存中的指针。它将被索引到内存缓冲区中。请记住,i32 数据值表示 4 个字节,因此 $index 的每一次前进都将 $ptr 增加 4。在交互的这一边,我们没有 TypedArrays 的好处,所以我们必须自己处理这些细节。同样,更高级别的语言会使我们免受这些细节的影响。
根据定义,前两个斐波那契数是 0 和 1,因此我们将它们写入缓冲区。i32.store 将一个整数值写入一个位置。它期望在栈顶找到这些值,所以语句接下来的两部分调用了 i32.const 指令,该指令将指定的值压入栈顶。首先,偏移量 0 意味着我们正在写入缓冲区的开头。第二行将数字 0 压入堆栈,表明我们要写入 0 的位置。下一行对下一个斐波那契数重复该过程。上一行的 i32 占用了 4 个字节,所以我们将值 1 写入位置 4。
下一步是迭代剩余的数字,每个数字定义为前两个数字的和。这就是为什么我们需要从我们刚刚拥有的两个数字开始。我们将 $index 变量推进到 2,因此我们需要 $n-2 次循环迭代。我们写了两个 i32 整数,所以我们将 $ptr 增加到 8。
Wat 引用了本书中介绍的几个 WebAssembly 指令。在这里你可以看到一些循环结构。我们在第七次调用时定义了一个块,并给它一个 $break 标签。下一步引入一个循环,其入口点是 $top。循环中的第一条指令检查 $n 和 $index 是否相等,表明我们已经处理了所有数字。如果是,则跳出循环。如果没有,则继续。
第 10 次调用的 i32.store 指令写入 $ptr 位置。使用 local.get 将变量的值压入堆栈顶部。要写入的值是前两个数字的值的加法。 i32.add 期望在堆栈的顶部找到它的两个添加项。所以我们加载一个比 $ptr 小 4 的整数位置。这代表 $n - 1。然后我们加载存储在位置 $ptr 减 8 的整数,它代表 $n - 2。i32.add 将这些加数从堆栈顶部弹出并将它们的总和写回到顶部。栈顶现在包含这个值和当前 $ptr 值的位置,这是 i32.store 所期望的。
下一步是将 $ptr 增加 4,因为我们现在已经将另一个 Fibonacci 数写入缓冲区。我们将 $n 递增 1,然后跳转到循环的顶部,并重复该过程。一旦我们将 $n 个数字写入缓冲区,该函数就会返回。它不需要返回任何东西,因为主机环境可以访问内存缓冲区,并且可以使用 TypedArrays 直接读取结果,正如我们之前看到的那样。
将我们的 HTML 加载到浏览器并显示前 20 个斐波那契数的结果如图 4-3 所示。
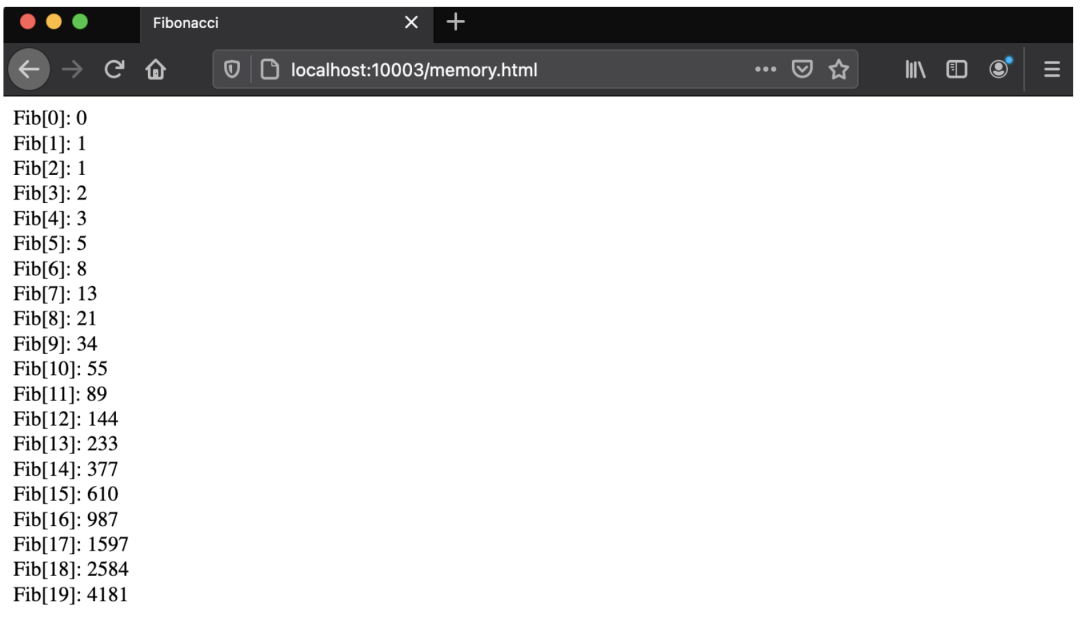
如果你经常处理这种级别的细节,那么你会被烦死,但幸运的是,你不必这样做。不过,你需要了解事情在这个级别上是如何工作的,我们可以在这个级别上模拟连续的线性内存块以进行高效处理。
最后是字符串
在本书后面的章节中,有很多工具可以让事情变得更简单,但是我们可以使用 Wat 中的一些便利来将字符串写入内存缓冲区并在 JavaScript 端读取它们。
在例 4-8 中,你可以看到一个非常简单的模块,它导出一个单页 Memory 实例。然后它使用数据指令将字节串写入模块内存中的某个位置。它从位置 0 开始并将字节写入后续字符串。如果你愿意,这是一种不必将多字节字符串转换为其构成字节的便利。该字符串的日语后跟英语翻译。
例 4-8. Wat 中字符串的简单使用
(module
(memory (export "memory") 1)
(data (i32.const 0x0) "私は横浜に住んでいました。I used to live in Yokohama.")
)一旦我们将 Wat 编译到 Wasm,我们就会发现我们的模块中有一个新的填充部分。你可以通过 wasm-objdump 命令看到这一点:
brian@tweezer ~/g/w/s/ch04> wasm-objdump -x strings.wasm
strings.wasm: file format wasm 0x1
Section Details:
Memory[1]:
- memory[0] pages: initial=1
Export[1]:
- memory[0] -> "memory"
Data[1]:
- segment[0] memory=0 size=66 - init i32=0
- 0000000: e7a7 81e3 81af e6a8 aae6 b59c e381 abe4 ................
- 0000010: bd8f e382 93e3 81a7 e381 84e3 81be e381 ................
- 0000020: 97e3 819f e380 8249 2075 7365 6420 746f .......I used to
- 0000030: 206c 6976 6520 696e 2059 6f6b 6f68 616d live in Yokoham
- 0000040: 612e a.Memory、Export 和 Data 部分填写了我们写入内存的字符串的详细信息。该实例已初始化,因此当主机环境从缓冲区读取时,字符串已经存在。
在例 4-9 中,你可以看到,我们有两个 <span>,一个用于日语句子,一个用于英语句子。为了提取各个字节,我们可以用 Uint8Array 包住我们从模块中导入的 Memory 实例缓冲区。注意,我们只包裹了前 39 个字节。这些字节通过 TextDecoder 实例被解码为 UTF-8 字符串,然后我们为日语句子设置指定的 <span> 的 innerText。然后,我们用一个单独的 Uint8Array 包住缓冲区中从第 39 位开始的部分,包括随后的 26 个字节。
例 4-9. 从导入的 Memory 实例中读取字符串
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<link rel="stylesheet" href="bootstrap.min.css">
<title>Reading Strings From Memory</title>
<script src="utils.js"></script>
</head>
<body>
<div>
<div>Japanese: <span id="japanese"></span></div>
<div>English: <span id="english"></span></div>
</div>
<script>
fetchAndInstantiate ('strings.wasm').then (function (instance) {
var mem = instance.exports.memory;
var bytes = new Uint8Array (mem.buffer, 0, 39);
var string = new TextDecoder ('utf8').decode (bytes);
var japanese = document.getElementById ('japanese');
japanese.innerText = string;
bytes = new Uint8Array (mem.buffer, 39, 26);
string = new TextDecoder ('utf8').decode (bytes);
var english = document.getElementById ('english');
english.innerText = string;
});
</script>
</body>
</html>在图 4-4 中,我们看到了从缓冲区中读取字节并将其渲染为 UTF-8 字符串的成功结果。

虽然这些结果很酷,但我们如何知道要打包多少字节以及在何处查找字符串? 一点侦探工作可以帮助我们。大写字母 “I” 在十六进制中表示为 49。wasm-objdump 的输出为我们提供了数据段中每个字节的偏移量。我们在以 0000020: 开头的行中第一次看到值 49。49 表示第 7 个字节,所以第二句是从 27 的位置开始的,是 2×16+7 的十进制,所以是 39。日文字符串表示 0 到 39 之间的字节。英文字符串从 39 开始位置。
但是等一下! 原来是我们把英文句子算错了,差了一个。从 WebAssembly 模块中获取字符串似乎是一项繁琐且容易出错的工作。即使在如此低的水平上也很难处理。我们先把字符串的位置写出来,这样就不用自己考虑了。
例 4-10 看起来更复杂。我们现在有两个数据段。第一个数据段写入第一个字符串的起始位置和长度,然后写入第二个字符串的相同信息。由于我们使用相同的缓冲区来写入索引和字符串,因此我们必须注意局部性。
由于我们的字符串不是很长,我们可以使用单个字节作为偏移量和长度。总的来说,这可能不是一个好的策略,但它会显示出一些额外的灵活性。所以,我们写出值 4 和值 27。这表示偏移量为 4 个字节,长度为 39。偏移量为 4,因为我们在缓冲区的开头有这四个数字(作为单个字节)并且需要跳过它们以获取字符串。众所周知,27 的十六进制为 39,是日文字符串的长度。一个英文句子将从索引 4+39=43 开始,即十六进制的 2b (2×16+11),长度为 27 个字节,十六进制的 1b (1×16+11)。
第二个数据段从位置 0x4 开始,因为我们需要跳过这些偏移量和长度。
例 4-10. 在 Wat 中更复杂地使用字符串
(module
(memory (export "memory") 1)
(data (i32.const 0x0) "\04\27\2b\1b")
(data (i32.const 0x4) "私は横浜に住んでいました。I used to live in Yokohama.")
)在例 4-11 中,我们看到了读取字符串的另一面。现在肯定更复杂了,但工作量也减少了,因为模块会告诉我们确切的查找位置。使用 TypedArrays 的另一个选项是 DataView,它允许你从内存缓冲区中提取任意数据类型。它们不需要像普通的 TypedArray(例如 Uint32Array)那样是同类的。
例 4-11. 从内存缓冲区中读取我们的索引字符串
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<link rel="stylesheet" href="bootstrap.min.css">
<title>Reading Strings From Memory</title>
<script src="utils.js"></script>
</head>
<body>
<div>
<div>Japanese: <span id="japanese"></span></div>
<div>English: <span id="english"></span></div>
</div>
<script>
fetchAndInstantiate ('strings2.wasm').then (function (instance) {
var mem = instance.exports.memory;
var dv = new DataView (mem.buffer);
var start = dv.getUint8 (0);
var end = dv.getUint8 (1);
var bytes = new Uint8Array (mem.buffer, start, end);
var string = new TextDecoder ('utf8').decode (bytes);
var japanese = document.getElementById ('japanese');
japanese.innerText = string;
start = dv.getUint8 (2);
end = dv.getUint8 (3);
bytes = new Uint8Array (mem.buffer, start, end);
string = new TextDecoder ('utf8').decode (bytes);
var english = document.getElementById ('english');
english.innerText = string;
});
</script>
</body>
</html>因此,我们用 DataView 实例包装导出的 Memory 缓冲区,并通过调用 getUint8() 函数读取位置 0 和位置 1 的前两个字节。这些表示日语字符串在缓冲区中的位置和偏移量。除了我们不再使用硬编码数字之外,我们之前的其余代码是相同的。接下来我们读取 2 和 3 位置的两个字节,分别代表英文句子的位置和长度。这也转换为 UTF-8 字符串,这次如图 4-5 所示,更新正确。

你可以尝试自己创建一个更灵活的方法,告诉你需要读取多少个字符串,它们的位置和长度。读取它的 JavaScript 可以做成一个循环,整个过程应该更加灵活。
Memory 实例还有很多内容,你稍后会看到,但就目前而言,我们已经涵盖了足够多的 WebAssembly 基础知识,尝试在 Wat 中手动完成更复杂的事情将会非常痛苦。因此,是时候使用更高级的语言了,比如 C。
获取更多云原生社区资讯,加入微信群,请加入云原生社区,点击阅读原文了解更多。