大家好,我是卖萌酱。
来一个快问快答,如何使用性能有限的GPU卡从头训练出一个ChatGPT?
在目前,随着模型参数量不断暴涨,大家对算力的要求也水涨船高。对比GPT-3当年使用了10000块GPU,花了30天训练了1750亿参数,现实条件下我们一没法组织起无限算力,二来手里的计算卡硬件设备还可能差异很大,显存、带宽水平参差不齐,在卡不多条件又比较艰苦的背景下,我们该如何进行高效的大模型训练呢?
我们在这篇论文中找到了答案。
论文标题:
YUAN 2.0: A Large Language Model with Localized Filtering-based Attention
论文链接:
https://arxiv.org/ftp/arxiv/papers/2311/2311.15786.pdf
项目地址:
https://github.com/IEIT-Yuan/Yuan-2.0
模型下载:
https://huggingface.co/IEITYuan
在上个月,浪潮信息发布了千亿级别的开源大模型源2.0,作为一个开源模型,源2.0在多个评测指标上超越了 GPT-3.5 直逼 GPT-4.0。作为源2.0的技术报告,这篇论文核心的关注点还是放在了源2.0对模型结构的创新,也就是标题中提到的新型注意力机制结构LFA(局部注意力过滤增强机制,Localized Filtering-based Attention),但是我们注意到了源2.0在分布式训练策略上的创新同样有可以深挖之处。

从Scaling Law出发,当下“有限的算力”与几乎看不到上限的“模型参数”之间存在着天然的矛盾,而在有限的资源下进行高效的大模型训练与开发是一个世界范围内的关键技术难点与研究问题,而源2.0则在“分布式训练策略”上下了功夫做了文章,最终很好的解决了在有限且多元的算力背景下高效进行大模型训练的关键工程难题。
那么源2.0是如何做到在有限的GPU环境下,从头训练出来了一个优质高效的大模型的呢?OK,那我们就细细展开从“大模型是如何诞生的”出发慢慢说起。
一、大模型诞生记:3D并行
大模型要训练,自然离不开“并行”。而在大模型训练中为什么要考虑并行?显然是因为“量大而力不足”。
大模型训练过程之中,“量大”可以分为两个方面,一个是“模型大”,模型参数军备竞赛直冲万亿,而另一个则是“数据多”,训练数据量级成了天文数字。而“力不足”也可以从两个方面进行理解,一个“算力不足”算太慢,另一个则是“显存不足”存不下。举一个具体一点的例子,GPT-3有1750亿个参数在570GB的语料数据中进行训练,而要训练这样一个“庞然大物”,使用 8 张 V100 显卡,训练时长预计需要36 年。

显然,这不是一个合理的时间,让我们回顾模型训练的基本流程,一个神经网络,输入数据我们首先要跑一遍前向Forward的过程,算算wx+b,算算激活函数,之后计算Loss function利用损失函数进行Backward对参数求导得到梯度Grad,拿到Grad后扔给优化器Optimizer更新模型权重,如此反复。
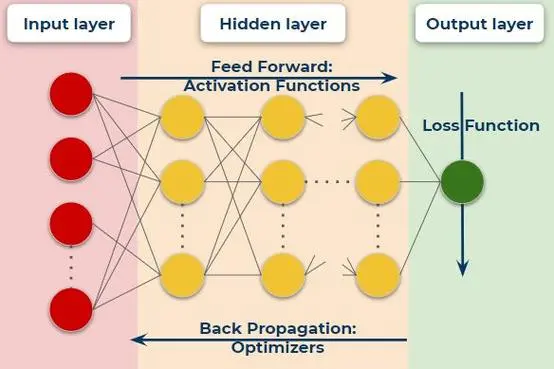
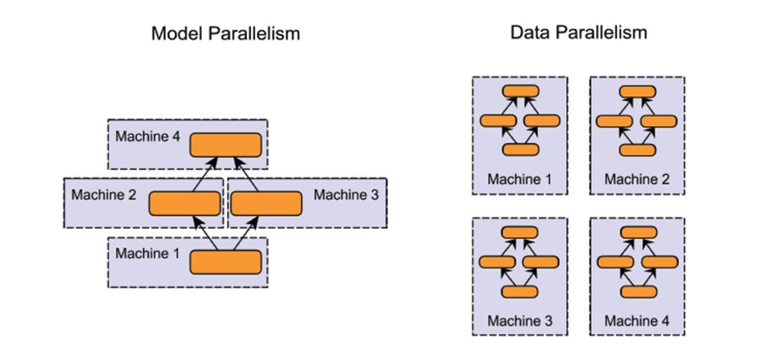
事实上,制约训练复杂度的无非是模型的大小以及输入数据的多少,由此衍生出两种经典的分布式训练策略,模型并行与数据并行。
先来说模型并行,大模型训练的一个痛点也在于模型太大参数量太多,一种直接的思路就是模型参数量大那么我们就拆模型。因而模型并行(Model Parallel, MP)思想应运而生,而模型并行又有两种思路,分别是流水线并行(Pipeline Parallel, PP)与张量并行(Tensor Parallel, TP)。
先来看流水线并行,一般而言深度学习的模型总是分层的,假设有一个8层Layer的模型,,那么最朴素的一种流水线并行方法就是按照Layer切分进行并行。譬如使用4个GPU 进行流水线并行,其中GPU 0负责计算
,
而GPU 1则负责
,
依次类推GPU 3负责
。
这其中GPU 0首先计算中间值1以张量形式传递给GPU 1,GPU 1再将计算值传递至GPU 2,直到GPU 3 接收到模型的输出后进行反向传播,完成一次训练过程。

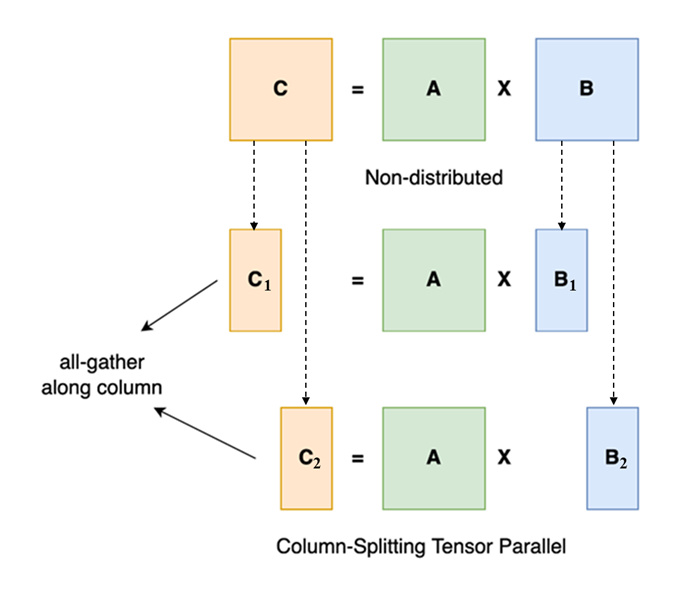
而除了按Layer层拆,还有一种模型并行的思路就是“直接拆张量”,这其实源于矩阵乘法的性质,假设有矩阵乘法,现在我们可以把按列给拆成,这样做矩阵乘法,如果有N个GPU,这样就可以把一个大的矩阵乘法拆成N个小乘法。
除却模型并行,输入数据的大小也直接决定了内存的使用多少与计算量因此模型大我们拆模型,数据大那我们就拆数据,因而一种分布式策略的思想也就呼之欲出:数据并行(Data Parallel, DP),简而言之一张卡放不下的数据算不过来的数据我们按Batch进行切分,将数据分配到多张卡中进行模型训练。
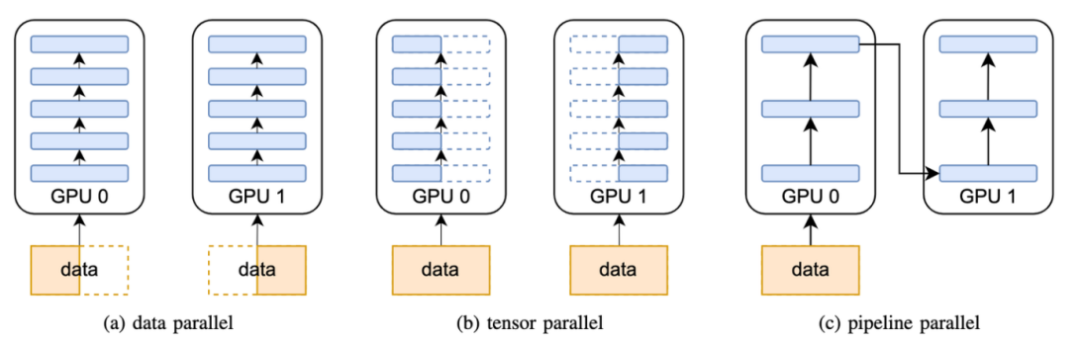
此时,综合前面提到的流水线并行(PP)、张量并行(TP)以及数据并行(DP),就构成了当下大模型训练的基本方法:3D并行。通过在训练数据、模型张量、模型层三个方面应用分布式训练与并行技术,3D并行技术成功训练了数万亿参数规模的模型。3D并行的应用从计算量与显存两个方面规避了大模型训练的资源瓶颈,让模型规模达到了一个在过去无法设想的高度。
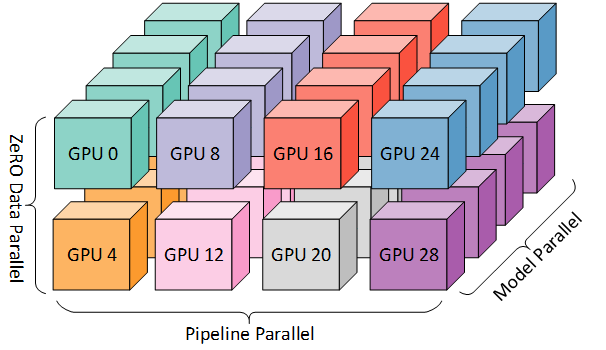
其实早在浪潮信息2021年对标GPT-3推出的源1.0 中,就已经使用了传统的数据+流水线+张量的3D并行策略,从结果导向来看,源1.0 交出了一份不错的答卷。据公开数据表明,2457亿参数的源1.0的训练算力效率达到了44.8%,而1750亿参数的GPT-3训练算力效率为21.3%。
二、打破3D并行:创造大模型训练的另一种可能
3D并行解决了所有问题吗?显然没有,举个例子,当硬件环境差异较大时,不同GPU卡显存与带宽本身存在着显著差异,有时即便是同一种GPU卡,卡的负载也并不完全一样。在这种多元算力背景下,3D并行往往很容易出现中途显存超标OOM的问题,而现实场景下在多元算力芯片上开发大模型又往往是不得已而为之的必要手段,那么如何在现有3D并行的技术基础之上“求解”这种复杂现实问题就成为迫在眉睫的难点痛点。
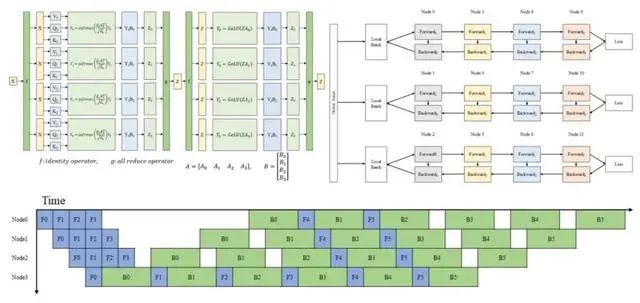
时间来到两年后,源2.0的参数规模是1026亿,不到源1.0的一半,但是明显的,源2.0不仅在各方面能力上“远超”源1.0,对计算力的使用效率也由极大提升。那么在分布式训练策略之上,源2.0对比源1.0最大的区别何在呢?其实答案就是一套创新性的分布式训练策略——非均匀流水线并行+优化器参数并行(ZeRO-1)+ 数据并行 + Loss计算分块,这套分布式训练策略也正是源2.0成功的关键!
具体来看,回想流水线并行的工作流程,其中有一个问题就在于传统流水线并行给每一个工作GPU分配的模型层数都是相同的。这个思路乍一看没什么问题,但是在实际模型训练过程中,往往前几个阶段需要缓存更多的激活值以进行反向传播计算;而在后几个流水并行阶段,只需要缓存少量的激活值。也就是说很可能在前几个stage显存几乎用到上限的时候,后面的显存还剩余很多。假设一个24层的Transformer用8个GPU做流水线并行,如果是均匀分配则一个GPU中存在3层网络,此时根据反向传播从后前的方向将使得最后方的GPU要保存更多的激活值,从而非常有可能使得GPU超过显存上限使得训练失败,而在GPU卡性能不高的场景下这个问题更甚。
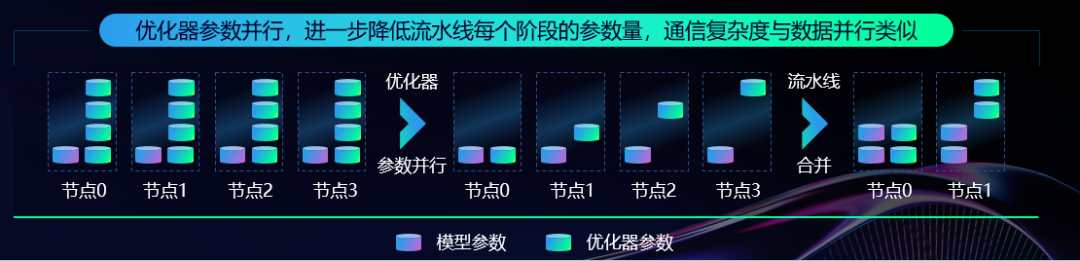
而源2.0在这一显存瓶颈中做出了突破,如上图(b)所示,不是说均匀的流水线并行这种“绝对的平均主义”会导致“多劳不多得”吗,那么不如就“按劳分配”,将流水线并行中的每个GPU中承担的Layers不均匀风格,以降低峰值显存开销,实现存储和计算的总体最佳性能。比如一个12层的模型,分到4个GPU上,GPU 1的任务中只分2层,GPU 2 分 3 层,GPU 3 分 4 层,GPU 4 分 3 层。

与此同时,为了更进一步降低损耗,源2.0又提出了一种“逐块交叉熵计算”的方法,举个例子,输入tokens数为2048。逐块交叉熵计算先对tokens进行切分,切分为16个块,每个块长度为128个tokens,每计算一次即得128个Loss,通过将所有的Loss连接为一个张量,释放中间的临时变量,使得模型训练可以在不需要额外计算与通信的情况下解决前文所述最后一个流水线阶段的显存瓶颈。
此外,如果要继续将数据并行的思路发挥到极致,仔细分析可以看到,在数据并行中每个工作GPU内还保存有一份完整的模型参数,这样直接使得GPU的显存成为了模型规模的瓶颈。那么,真的有必要每个GPU内都保存有一份完整的模型参数吗?答案显然是不必要的,这就引出了大名鼎鼎的ZeRO。
拆解一下这几个字母,ZERO代表 Zero Redundancy Optimizer,即零冗余优化,ZeRO首先对“模型参数”的构成进行了分析,由上文模型的训练的过程可以得到,所谓模型参数主要包含三大部分,分别是模型本身参数、梯度参数以及优化器参数三块,对于模型训练而言,事实上并不需要工作GPU“人手一份”数据,相反整个训练过程其实仅需要“一份参数”就够了。
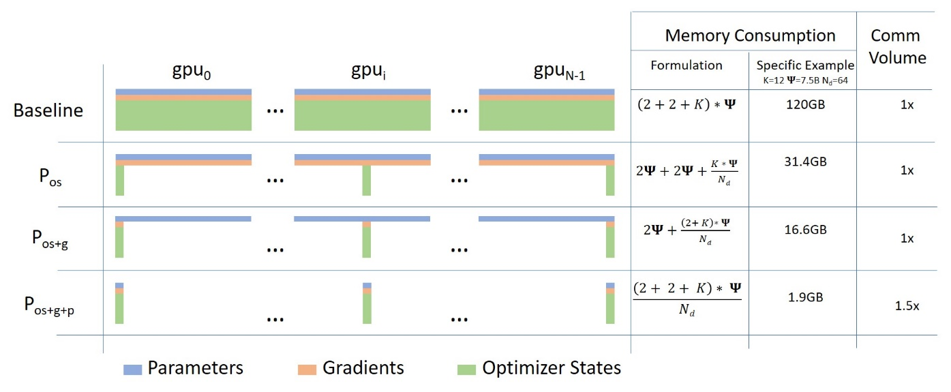
从这个角度出发,那么十分自然,假设有N块GPU,无论是模型参数的哪一部分,其实当前工作GPU仅需要1/N份参数就足够可以完成训练,由此,源2.0利用了ZeRO的思想,通过在切分三种参数的“显存下降”与“通信成本升高”之间权衡,源2.0选择了ZeRO-1即优先对优化器参数进行并行。从上图来看,使用优化器参数并行对比Baseline将实例中的显存由120GB降低至31.4GB,大大优化了GPU显存使用。
除了前面提到的ZeRO-1与非均匀流水线并行,源2.0还取消了张量并行策略。拆张量的张量并行由于直接从“源头”进行拆分,导致其对模型参数的切分粒度较细,而细粒度的计算就意味着GPU间就必须得进行频繁的通信,使得芯片间的P2P通信带宽成为训练的主要瓶颈。举个例子,芯片间的P2P通信带宽为900GB/s时,通信时间占比为10%,而如果P2P通信带宽为400GB/s时,通信时间占比会上升到23%。进一步换算,可以得到P2P通信带宽的降低,导致了约17%的性能损失。
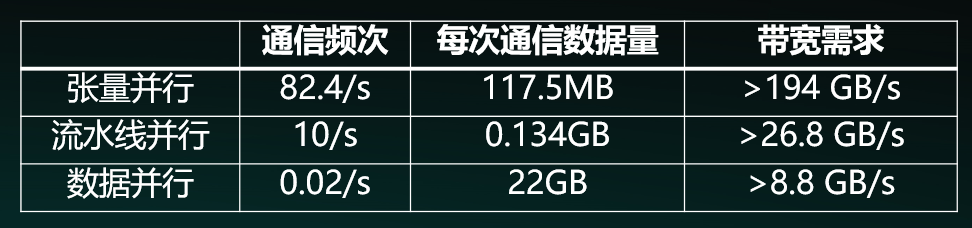
注:浪潮信息“源1.0” 3D并行训练策略通信分析
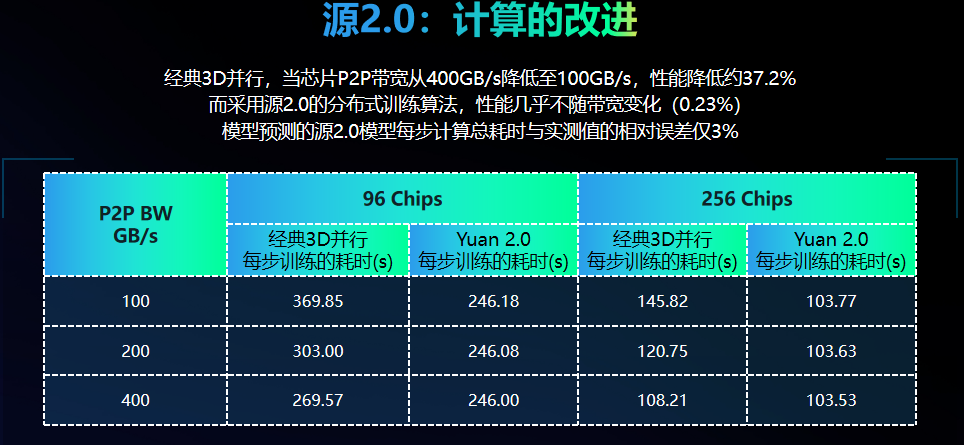
依据这一发现,源2.0取消了张量并行,应用非均匀流水线并行、Loss计算分块、ZeRO-1、数据并行等技术重组了分布式训练策略,使得芯片间通信带宽也不再成为限制模型训练的阻碍,如下图所示,当芯片间的P2P带宽从400GB/s降低到100GB/s,这套分布式训练算法的性能也几乎不会产生太大的变动(0.23%),可以更好地应用在性能水平差异大的各类算力集群中。
三、一点总结
2023又到年底,回望这大模型狂飙突进的一年,从 ChatGPT 问世技惊四座到 AI Agent 火热浪潮汹涌,从 GPT-4 问鼎天下睥睨群雄到当下大模型百花齐放百家争鸣……短短一年,大模型就赋予了我们最接近未来“智能时代”的狂热想象,各种技术喷薄而出各类行业应用泉涌而下,哪怕是最近这短短一个月,我们都可以看到诸如谷歌的 Gemini,微软的Phi-2,Mistral AI的Mixtral等等模型,
而这一批又一批的大模型来来去去。如果仅仅关注这些模型在某个基准中上升几名或在某个数据集上指标如何,或许在一段时间内大家茶余饭后还能热火朝天的讨论两句,但是在大模型超高速发展的当下,很快又会被大家抛之脑后成为过眼云烟。
抛开刷榜抛开SOTA,事实上面向实际场景对训练技术进行创新相当重要,我们常常期望国内各种技术“赶英超美”,但是所谓“工程优势”从来都不是突然冒出来的一篇论文或一项技术所赋予的,真正的大国工程优势的出现,往往就在于类似Yuan 2.0分布式训练这种创新技术的一点一滴的累积。
在论文中提出一个Fancy的概念或许容易,在一个Toy example中刷出两个漂亮结果或许简单,但是能扎扎实实一步一步的把各种理论组装搭建,面向实际问题兵来将挡水来土掩,把一个又一个小的技术创新串联,直至撑起来一个巨型工程甚至开源出去,或许是一条颇为困难但我们不得不前进的道路。
而在大模型遍地开花的当下,也许就是为什么像源2.0这样的工作显得尤为难得的答案吧!
