背景
NL-to-SQL(自然语言到结构化查询语言)任务是自然语言处理(NLP)领域的一个难题。 它涉及将自然语言问题转换为 SQL 查询,然后可以针对关系数据库执行该查询来回答问题。 该任务是 NLP 中的一个专门子领域,与更广泛的自然语言理解 (NLU) 领域以及自然语言与数据库之间的接口 (NLIDB) 密切相关。
随着 GPT-4、Llama2 和 Falcon 等大型语言模型 (LLM) 开发的最新进展,业界和学术界对 NL 到 SQL 的关注已经转向利用这些 LLM 为现实世界生成 SQL 用例。 这将非常强大,因为它允许非技术用户直接从数据中找到见解。
在 Dataherald,我们构建了一个开源自然语言到 SQL 引擎,可与不同的 LLM 一起使用,尽管我们在企业部署中使用 GPT-4-32K。 当前 NL 到 SQL(例如 DAIL-SQL、C3 和 DIN-SQL)的最先进研究也使用闭源 LLM,例如 GPT-4 和 GPT-3.5-turbo。 这些模型既昂贵又引发了企业的数据隐私问题。 因此,我们开始研究 Llama2 和 Mistral 等开源LLMS如何与 OpenAI 的模型相比较。 以下是我们的结果。
开源的大语言模型
在这篇博文中,我们将探讨各个系列的开源 LLM(大型语言模型)的功能。 这里分享的信息来自最近的三篇论文,即大型语言模型之战、大型语言模型支持的文本到SQL、文本到SQL的分解上下文学习以及我们自己进行的内部测试 使用 Google Colab A100 GPU。
涉及的模型列表如下:
- Llama-7B
- Llama-33B
- MISTRAL-7B
- Alpaca-7B
- Llama-2-CHAT-7B
Llama-2-CHAT-13B
Vicuna-7B
Vicuna-33B
BARD-LAMDA
BARD-PALM2
GPT-3.5-turbo
GPT-4
其中一些模型,如 Llama、Llama2 和 MISTRAL ,是类似于 GPT-3.5-Turbo 的预训练模型,经过了监督微调和对比微调。 其他模型已经经历了对齐过程,其中涉及额外的指令调整,并且本质上与预训练的模型共享相同的架构。 特别是,Vicuna、Guanaco 和 Alpaca 是在特定数据集上训练的 Llama 模型的对齐版本。
Zero-shot NL-to-SQL 性能
在本节中,我们将评估开源LLM的零样本性能,并将其与更大的闭源对应项目进行对比。 零样本性能是指LLM仅根据给定问题和问题引用的相应数据库模式生成 SQL 查询的能力,而无需提示中的任何少量样本示例。
为了确保公平比较,我们对评估中使用的所有LLM保持一致的提示。 用于报告零样本性能的特定提示基于 Rajkumar 等人提出的模板,与其他提示格式相比,该模板以其卓越的性能而闻名。
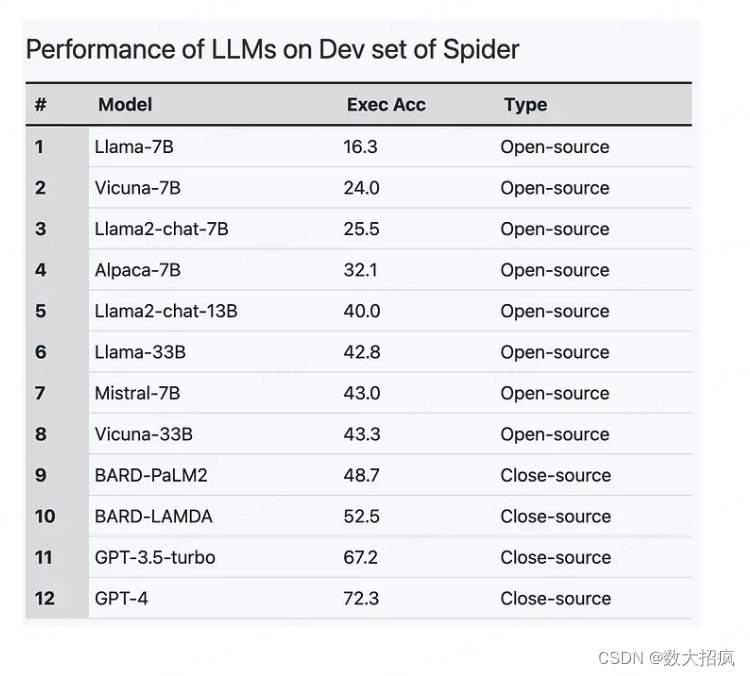
我们根据执行准确性评估这些模型的性能,其中包括执行模型生成的 SQL 查询和数据库上的参考 SQL 查询,然后比较它们的结果。 结果是通过在Spider数据集的开发集上使用LLM获得的。
结果如下:
要点
要点很明确:
- 闭源模型(GPT 模型和 BARD)在 NL 到 SQL 方面的性能显着优于开源模型。 可以肯定的是,这是因为他们接受了更多的参数训练。
- 与之前的模型相比,采用额外的监督微调步骤的模型表现出显着的性能改进。 例如,Alpaca-7B 模型比其前身 Llama-7B 改进了近16%。 这强调了使用相同的底层架构进行微调以实现增强性能的潜力。
- 与前辈相比,Mistral-7B 和 Llama2 等较新的开源模型表现出更优越的性能,并且正在缩小与闭源模型的差距。
对于 NL 到 SQL 工作负载,虽然较新的开源模型正在缩小与 OpenAI 模型的差距,但在开箱即用的准确性方面仍然存在很大差距。 然而,即使在相同的架构上,针对特定数据集的微调似乎也可以大大提高准确性。