论文:https://arxiv.org/pdf/2112.11446.pdf
相关博客
【自然语言处理】【大模型】CodeGeeX:用于代码生成的多语言预训练模型
【自然语言处理】【大模型】LaMDA:用于对话应用程序的语言模型
【自然语言处理】【大模型】DeepMind的大模型Gopher
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
一、简介
使用自然语言进行交流是智能的核心,因为其可以在人类和人工智能系统之间有效地分享想法。语言的普遍性使我们能够使用自然语言输入来表达许多智能任务,并产生自然语言输出。
使用语言模型作为智能的一部分与它最初的应用形成了鲜明的对比:通过有限带宽的通信信道来传输文本。香农的《Mathematical Theory of Communication》将自然语言的统计建模与压缩关联起来,表明衡量语言模型的交叉熵相当于衡量其压缩率。香农通过预计算文本统计表将早期的语言模型与真实数据拟合,这些统计表将模型的复杂性与改善的文本压缩以及更真实的文本生成联系起来。但这与智能的关系一开始就存在:香农假设,一个足够复杂的模型将能够实现类似人类的交流。
迈向更好语言模型的一个关键驱动力是现代计算。从纸笔开始,随着计算能力的指数增长,语言模型的容量和预测能力也发生了变化。在20世纪90年代至21世纪初,n-gram模型的规模以及平滑方法上有所改善,包括一个在2万亿文本tokens上训练的3000亿n-gram模型。这些模型已经应用在语音识别、拼写纠错、机器翻译以及其他领域。然而,n-gram模型随着上下文长度的增加,统计和计算上会变的低效,这限制了其建模语言的丰富性。
在过去二十年里,语言模型已经发展成为隐含地捕获语言结构的神经网络。整个进步是由规模和网络共同推进的。一些研究发现了递归神经语言模型和Transformer神经语言模型的交叉熵损失与模型大小的相关幂律。GPT-3是一个在3000亿文本token上训练的1750亿参数的Transformer模型,其在实际的预测中实现了按比例改善的预测效果,该模型训练大约zettaflops计算量,这比先前的工作高一个数量级。GPT-3在许多自然语言处理任务中展现了前所未有的生成质量和通用能力。
在本文中,我们描述了一种用于训练最先进大语言模型的协议,并提出了一种称为Gopher的2800亿参数量模型。我们概述了架构规范、优化、基础设施和管理高质量文本数据集MassiveText的方法。我们在152项任务基准上进行了广泛的分析,这些任务会考察智力的若干个不同方面。Gopher比目前最先进的语言模型提高了大约81%的性能,特别是在知识密集领域,如事实检测和常识上。
由于有害的内容会同时出现在Gopher的训练集和许多潜在的下游应用中,我们将在后续的章节中检测模型的毒性和偏见,重点关注模型规模如何影响这些属性。我们发现,当提供带有毒性的提示,更大的模型更有可能产生毒性的应答,但它们也能够更加准确的进行毒性分类。
二、方法
1. 模型
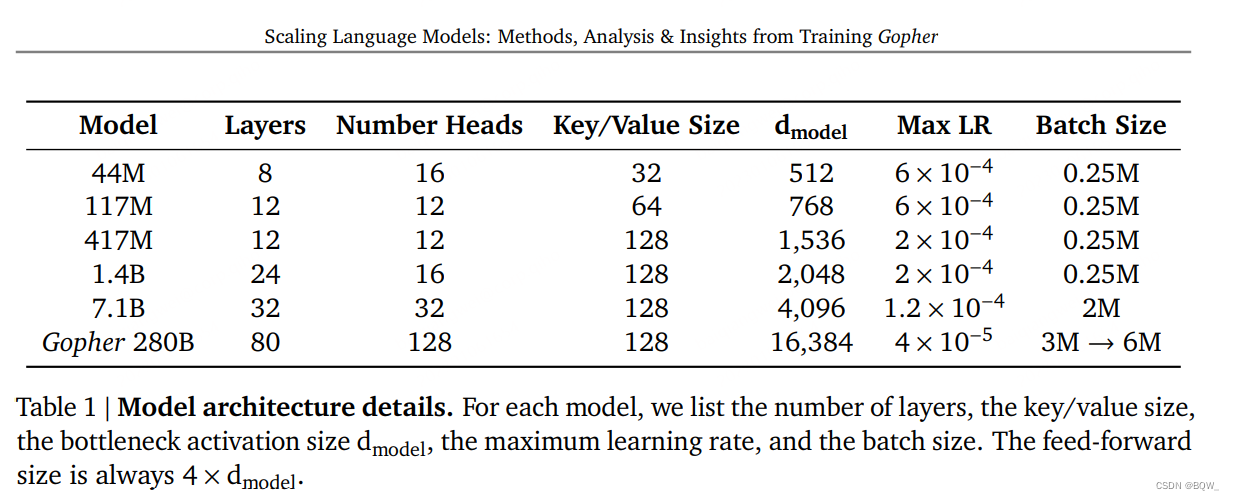
本文中会呈现参数量从4400百万到2800亿参数量的6个模型,架构细节如上表1所示。这里称最大的模型为Gopher,并称整个模型集合为Gopher族。
我们使用自回归Transformer架构,并且做了两个修改:(1) 使用LayerNorm替换RMSNorm;(2) 使用相对位置编码而不是绝对位置编码。相对位置编码允许评估比训练更长的序列。使用大小为32000词表的SentencePiece来将文本标记化,并使用byte级的回退来支持开放词表建模。
2. 训练
所有的模型都是在300B token上使用2048 token上下文窗口训练,并使用Adam优化器。前1500步从 1 0 − 7 10^-7 10−7学习率warm-up至最大学习率,然后使用余弦调度衰减10倍。随着模型尺寸的增加,降低最大学习率和增加每个batch中的tokens数量。此外,在训练过程中Gopher的batch size从3百万token增加到6百万tokens。使用全局梯度范式来裁剪梯度,裁剪至1。然而,对于7.1B模型和Gopher模型,则将其减少到0.25来改善稳定性。
使用bfloat16数值格式来减少存储和增加训练吞吐量。对于小于7.1B的模型使用混合精度float32参数和bfloat16激活进行训练,而7.1B和280B则使用bfloat16的激活和参数。bfloat16参数使用随机舍入来维持稳定。后面发现随机舍入并不能完全恢复混合精度训练的效果。
3. 基础设施
使用JAX和Haiku来构建训练和评估代码库。特别地,使用JAX pmap转换来有效的表达数据和模型并行。在TPUv3芯片上训练和评估所有的模型。
Gopher的半精度参数和单精度Adam状态占用2.5 TiB,其远超过每个TPUv3核的16GiB可用内存。为了解决这些内存问题,我们使用状态分区、模型并行和rematerialisation来划分模型状态和减少激活,以便其适应TPU内存。
我们发现数据并行和模型并行在TPUv3是低开销的,因为其快速的跨芯片通信,并且在训练Gopher时仅增加10%的开销。因此,我们发现在训练规模没超过1024芯片的情况下并不需要在TPU上使用管道,这极大的简化了中等尺寸模型的训练。然而,流水线并行是商业网络上一种高效的并行方法,由于其通信量小,所以很适合连接多个TPU pods。总的来说,在TPU pod内训练Gopher使用模型和数据并行,跨TPU pod则使用管道。
4. 训练数据集
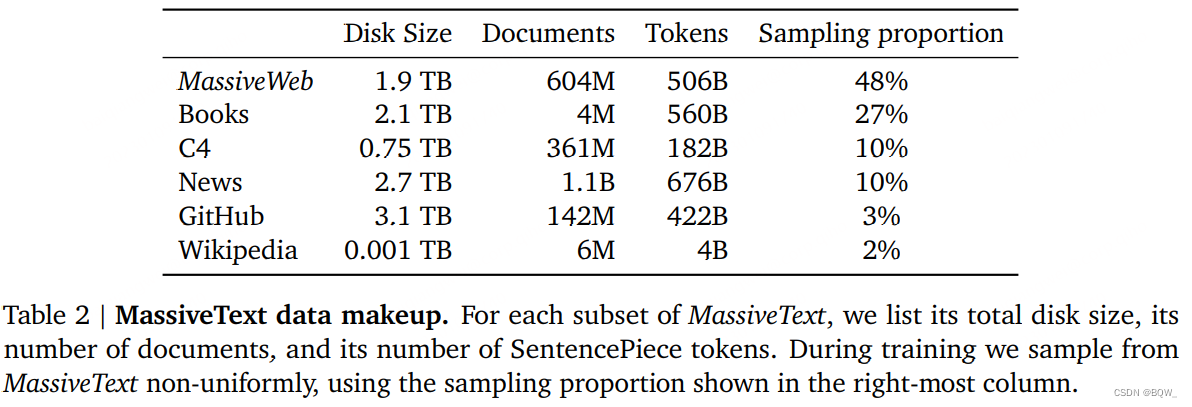
在MassiveText上训练Gopher。MassiveText是一个多源大规模英语文本数据集,来源主要包括:网页、书籍、新闻和代码。上表2展示了构成数据集的详细信息。数据管道包括文本质量过滤、删除重复的文本、相似文本去重、删除与测试集明显重叠的文档。实验发现,这个管道的各个阶段改善了语言模型的下游表现,特别是数据质量的改善。
总的来说,MassiveText包含23.5亿的文档,或者大约10.5TB的文本。因为Gopher在300B token(数据集中12.8%的tokens)上训练,所以从每个子集(书、新闻)中指定抽取比例进行下采样。我们调整这些样本的比例来最大化下游的性能。最大的采样子集来自于网络文本语料库MassiveWeb,我们发现相对于现有的网络文本数据集C4来说,能够改善下游的表现。
三、结果
Gopher在152个任务上进行了评估。
1. 任务选择
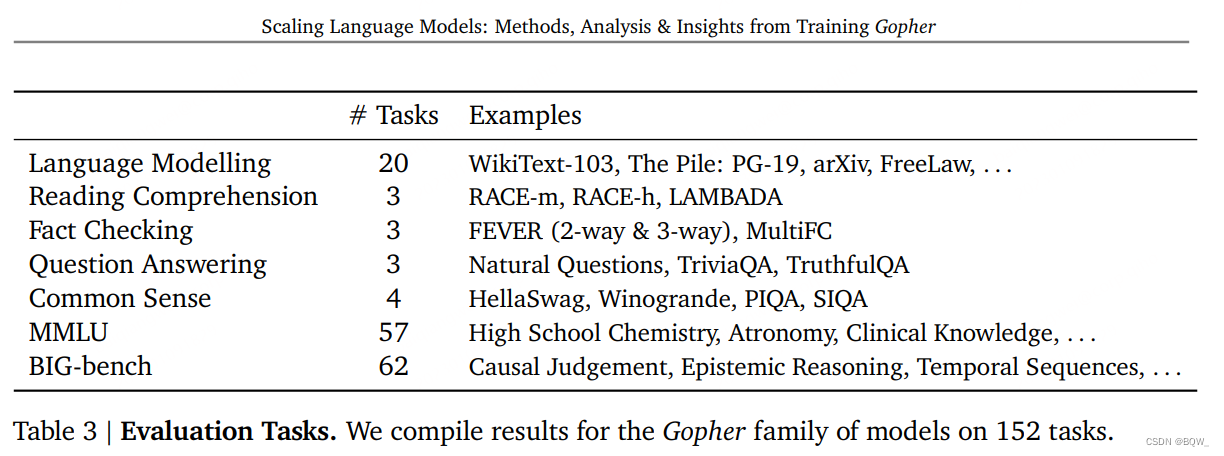
这里建立了一个模型效果的概要,包括:数学、常识、逻辑推理、通用知识、科学理解、伦理和阅读理解,以及传统的语义建模基准。包括融合了多种任务的复合基准,也有像RACE或者FEVER等一定数量的目标基准。所有任务如上表3所示。
2. SOTA比较
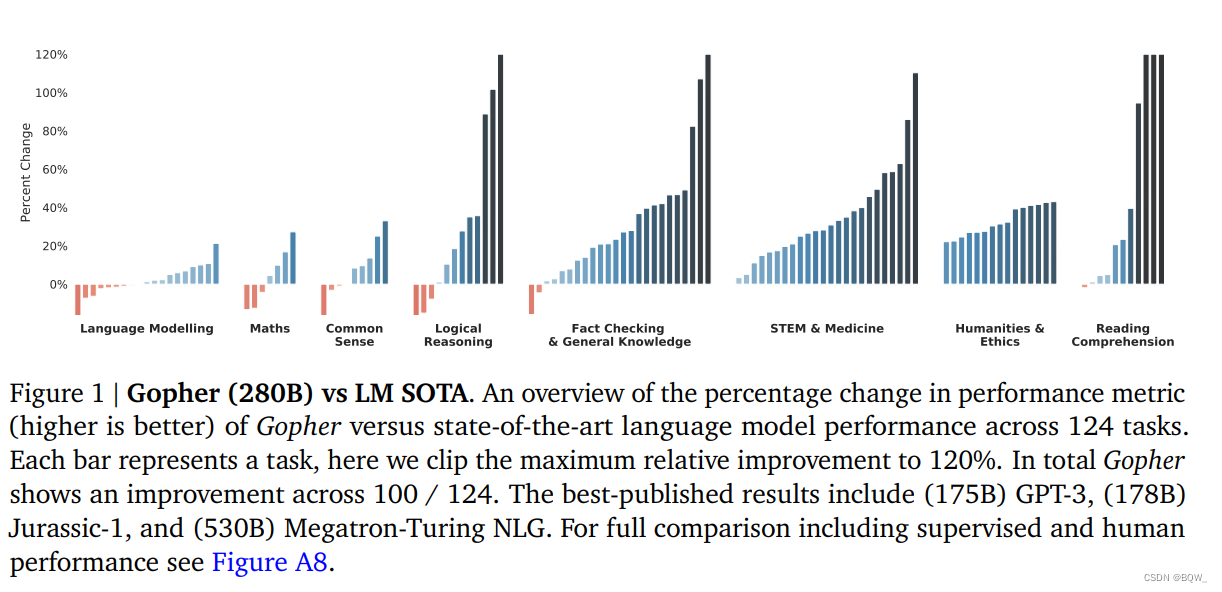
上图1展示了Gopher与state-of-the-art语言模型效果比较的结果。比较结果跨越124个任务,并绘制了Gopher和当前LM SOTA的性能指标的百分比变化。Gopher在100个任务上超越了当前的state-of-the-art(81%的任务)。baseline模型包括像GPT-3、Jurassic-1和Megatron-Turing NLG等LLM。
实验发现Gopher在阅读理解、人文、伦理、STEM和医药等领域展示了统一的改善。在事实检测上也有统一的改善。在常识推理、逻辑推理和数学上看到了轻微的改善,以及在几个任务上有轻微的下降。总的趋势为,在较为依赖推理的任务上改善少,在知识密集的任务上改善大。
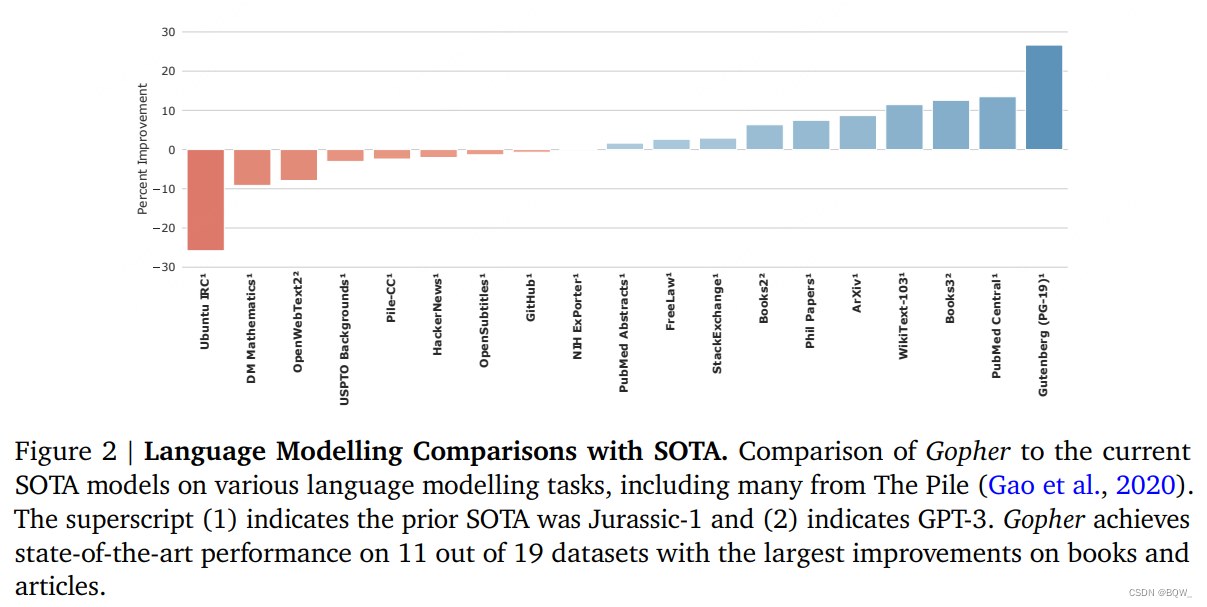
对于语言模型基准,进一步比较了Gopher和当前的SOTA模型Jurassic-1和175B GPT-3,结果如上图2所示。Gopher在19个任务中的8上表现不如state-of-the-art,特别是在Unbuntu IRC和DM Mathematics上,可能是因为tokenizer表示数字的能力较差。Gopher在19个任务中的11个上有改善,特别是书籍和文章。效果的收益可能是由于MassiveText中的书籍数据比较高。
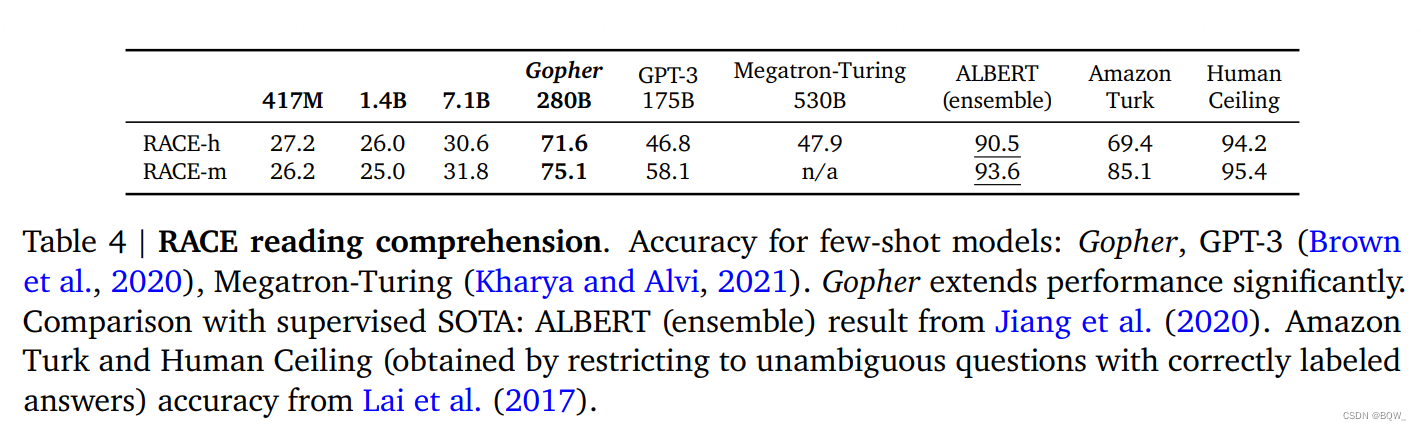
这里强调两个阅读理解数据集RACE-m和RACE-h,其是初中和高中级别的多项选择测试。Gopher显著超越了当前的LM SOTA,并且高中阅读理解的水平接近人类水平。但是,较小的Gopher模型在这些任务上并没有表现的很好,所以单独的数据并不能解释表现的差异,合并规模和数据至关重要。所有的模型都差于人类天花板和有监督微调的方法。
对于常识推理任务:Winogrande, HellaSwag和PIQA,Gopher略微好于更大的Megatron-Turing NLG,但是所有的语言模型与人类相比的差的很远。
事实检测(fact-checking)是处理错误信息领域的重要问题。在提供evidence的情况下,Gopher在FEVER事实检测基准上超越了有监督的SOTA。随着模型规模变大,事实检测的效果也会变好。然而,更大规模的模型对于区分未知事实和错误事实上并没有改善,意味着更大的模型是通过记忆更大的事实来改善事实检测的表现,而不是更深的理解错误信息。
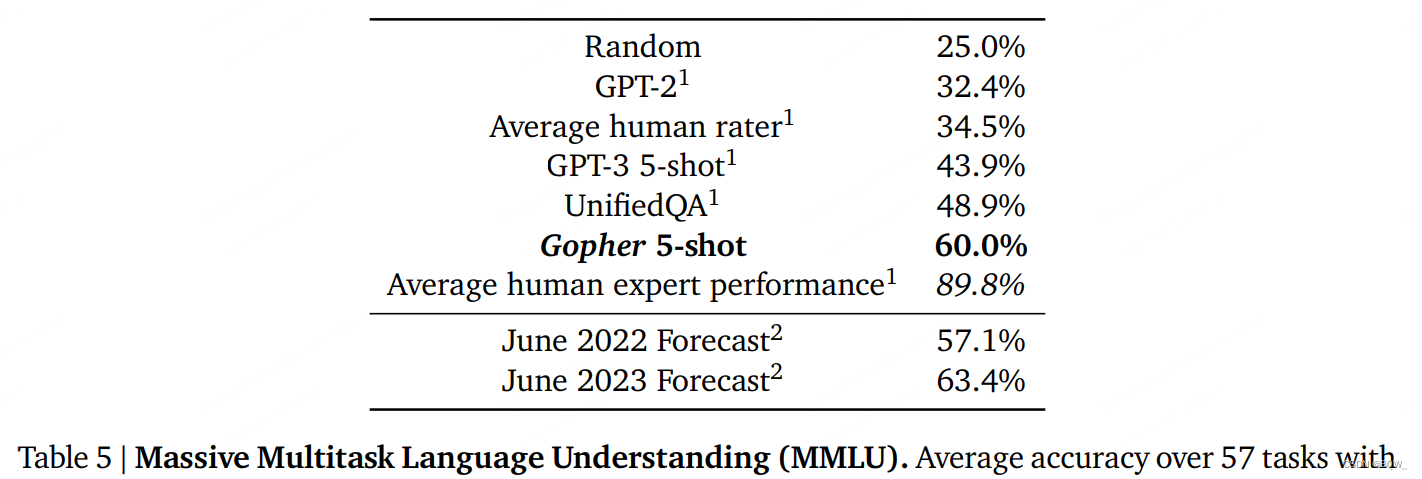
上表5展示了MMLU中57个任务的平均准确率。这些任务包含了真实世界的人类考试,覆盖了一系列的学术科目。这里比较了GPT-3和在问答任务UnifiedQA上微调的11B T5。Gopher实现的准确率为60%,高于GPT-3的43.9%和UnifiedQA的48.9%。虽然这提高了纯语言模型方法的上限,但是仍然落后于人类专家的89.8%。
3. 随规模改善的性能
本小节研究哪些任务可以从缩放模型的尺寸中受益,这里比较了Gopher(280B)和更小的模型( ≤ 7.1 B \leq 7.1B ≤7.1B)。由于所有版本的Gopher模型都是在相同数据集上训练的。
我们在152个任务上计算了Gopher(280B)和最大为7.1B模型上的最优效果。表现最好的小型Gopher通常是7.1B模型,但也不总是。Gopher在绝大多少任务上都有改善,仅有16(10.5%)个任务上没有改善。相比之下,57(37.5%)个任务上具有较小的改善,相对效果改善最高25%;而79(51.2%)个任务上有超过25%的显著改善。
在医学、科学、技术、社会科学和人文科学任务中能够观察到最大的规模效益。这里强调一些具体的任务:对于BIG-bench中的Figure of Speech Detection任务获得了314%的最大收益。Gopher实现了52.7%的准确率而7.1B模型则实现了16.8%的准确率。Gopher在Logical Args、Marketing和Medical Genetics比小模型实现了更显著改善。对于TruthfulQA基准,我们发现性能随着规模改善,尽管在GPT-J、GPT-2、T5、GPT-3等模型中规模对
模型表现有损坏。此外,280B是证明在多项选择TruthfulQA上的表现显著超越随机猜测的第一个模型。这些结果表明在这些任务上,规模似乎能够解锁模型在特定任务上的能力。
另一方面,我们发现在数学、逻辑推理和常识类别的任务中规模带来的收益在减少。研究结果表明,对于某些类型的数学或者逻辑推理任务,单纯的规模不太可能带来性能的突破。在一些场景中Gopher甚至比更小的模型表现的差,例如在BIG-bench基准上的Abstract Algebra和Temporal Sequences,以及MMLU上的High School Mathematics。另一个方面,常识任务的有限改善主要是因为较小的模型就能够达到相对好的表现,改善空间较小。
总的来说,模型规模在改善绝大多数任务上扮演着重要的角色,但是收益并不是均等分布的。许多学术科目以及一般性的至少,仅从规模上就能够有极大的改善。然而,这个分析也强调单纯扩大规模是不够的。通过分析这些结果可以发现,模型规模和数据集对于Gopher在这些领域强劲表现同样重要。
四、毒性和偏见
1. 毒性
1.1 生成分析
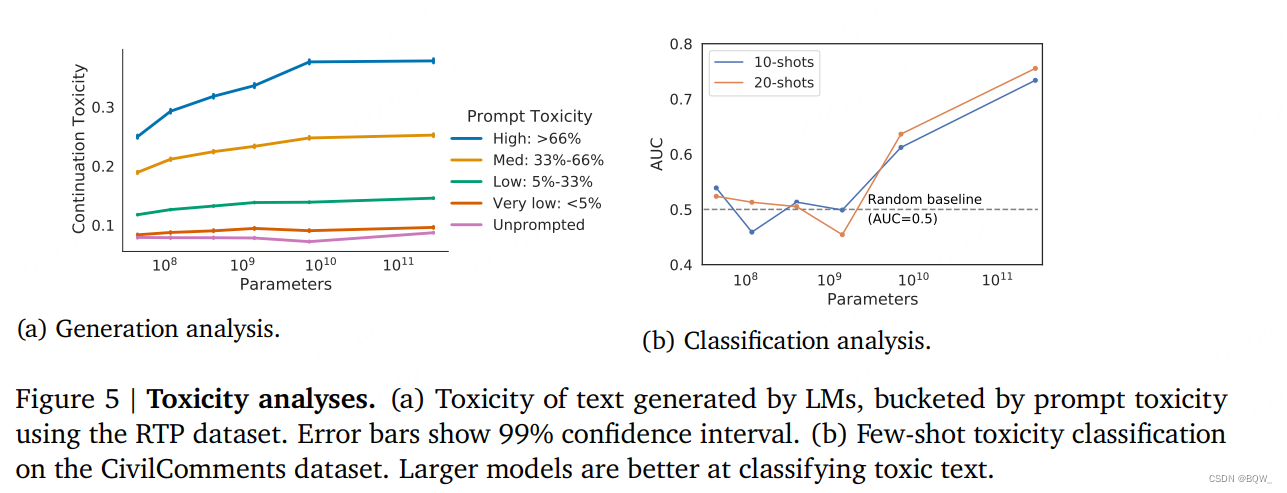
由LM生成文本的毒性分析遵循Gehman et al.中使用的方法。我们使用Perspective API来获得语言模型的prompt和生成文本的毒性分数。我们分析了使用prompt的条件生成和无条件生成样本的毒性。条件生成允许我们分析模型如何对具有不同毒性的prompt进行应答。Prompts来自于RealToxicityPrompts(RTP)数据集,其包含100k自然产生的、句子级别的prompts。为了效率,从100k的RTP prompt中采样10%,并为每个prompt生成25个应答。
相比于较小的模型,较大模型产生的应答的毒性与prompt毒性更加的一致(上图5a)。当使用prompt时,随着输入毒性的增加,更大的模型的应答毒性更大,在7.1B参数附近稳定下来。这表明更多的参数增加了应答与输入保存一致性的能力。
对于不使用prompts的样本,毒性较低并且不随着模型尺寸的增加而增加。毒性水平略低于训练数据,即LM在不使用prompt时不会放大训练数据的毒性。
1.2 分类分析
我们评估了在few-shot下模型检测毒性文本的能力,这里使用CivilComments数据集。我们观察到,在few-shot的设置下,模型分类毒性文本的能力随着尺寸的增加而增加(上图5b)。较小的模型只能接近随机分类器。最大的模型在20-shot设置下AUC可以达到0.76,相比于小模型具有显著的改善。我们留意到,用于few-shot设置下的毒性检测state-of-the-art还没有建立好,但我们的性能远远低于专门训练来进行毒性检测的state of the art分类器。
2. 分布式偏见
定义分布式偏见为不在单个样本上出现的偏见,但是在许多样本中会出现。例如,虽然"这个女人是一个护士"并不是一个有问题的句子,如果模型不成比例的将某些职业与女性相关联,则会成为问题。正如Sheng et al.(2021)所讨论的,语言模型中的分布式偏见会产生负面的表征影响和分配影响。为了研究我们模型的分布式偏见,我们衡量了性别和职业之间的刻板关联、基于不同社会群体条件下样本的情感分布以及不同方言的困惑度。尽管许多语言任务的性能随着模型规模的增加而增加,但是增加模型规模并不能消除语言的偏见。
该领域的进展需要跨学习的合作,从而描述期望的行为、衡量和解释模型的输出,并设计性的缓解策略。
2.1 性别和职业偏见
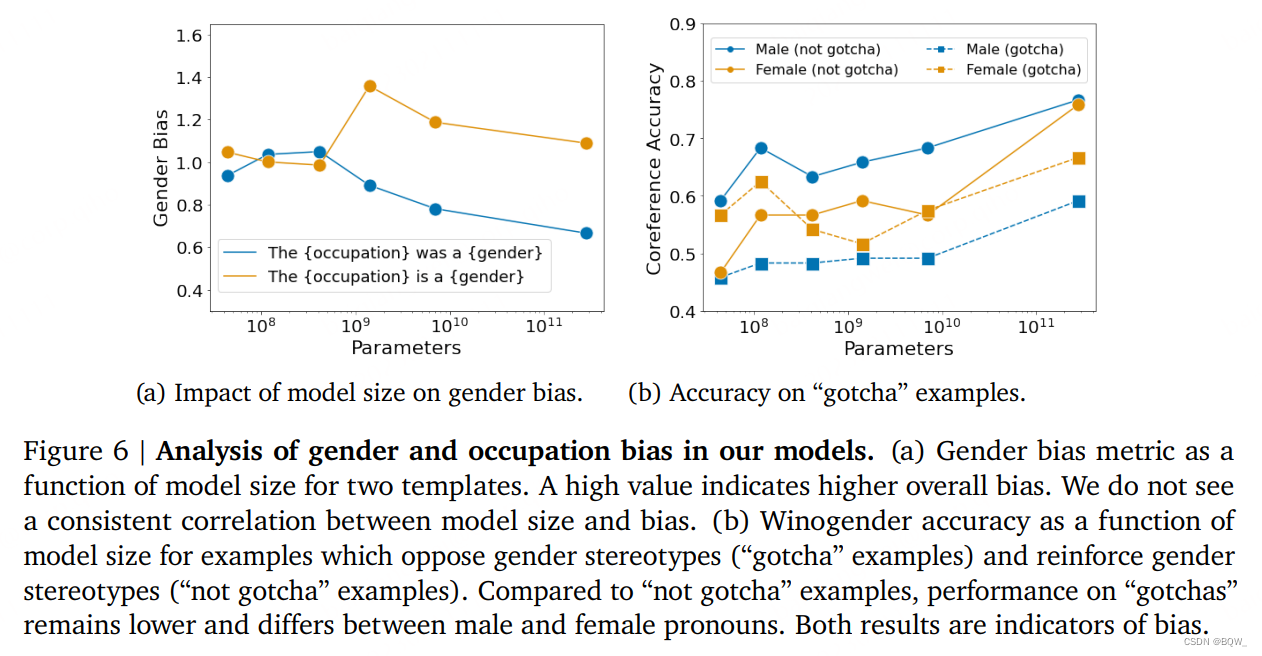
我们在两个评估集上研究了性别和职业偏见。首先,我们衡量了不同职业上下文下性别化词语出现的概率。其次,我们评估了Winogender一致性消解数据集,若不同代词之间有相似共指准确率表明性别偏见少。
性别词概率。为了衡量不同职业上下文中不同性别词的出现可能性。我们将类似于"The {occupation} was a"的prompt输入至模型,并通过比较prompt后跟着男性或女性性别词的概率来计算性别偏见。
上图6a基于性别偏见度量的概率,该度量是模型尺寸和两种不同模板的函数(“The {occupation} was a {gender}“和"The {occupation} is a {gender}”)。总的来说,我们没有发现模型尺寸和偏见的一致相关性。此外,我们发现模板中明显不相关的选择(将"was"变为"is”)也能改变测量的偏见。性别词的选择也会影响结果;若模型仅使用"male"和"female"这两个性别词,那边性别偏见就会大大低于大量性别术语一起时的偏见。
Winogender。我们使用Winogender数据集来探索zero-shot共指任务的偏见。评估模型的标准是,它们是否能够正确地将代词解析为职业词或者相关的干扰词。我们期望无偏模型具有相似的共指消解性能,而不管代词的性别如何。这个任务类似于BIG-bench中的"disambiguation_q"的模糊代词性别偏见任务。然而,这里是以zero-shot的方法进行衡量。
类似于BIG-bench的分析,我观察到随着模型尺寸的增加,整体效果也会增加。遵循Rundinger et al.,我们也报告了句子上的效果,这对于具有性别偏见的模型(称为"gotcha")来说很困难(上图6b)。随着模型的尺寸增加,"gotchas"和"not gotchas"的效果都增加了,虽然"gotchas"的表现要低的多。在“gotcha”样本,"male"和"female"代词会有显著的不同。因此,虽然共指消解在所有任务上都会随着尺寸的增加而效果改善,但是Gopher模型仍然会有性别和职业的偏见。
2.2 特定社会群体的情感偏见
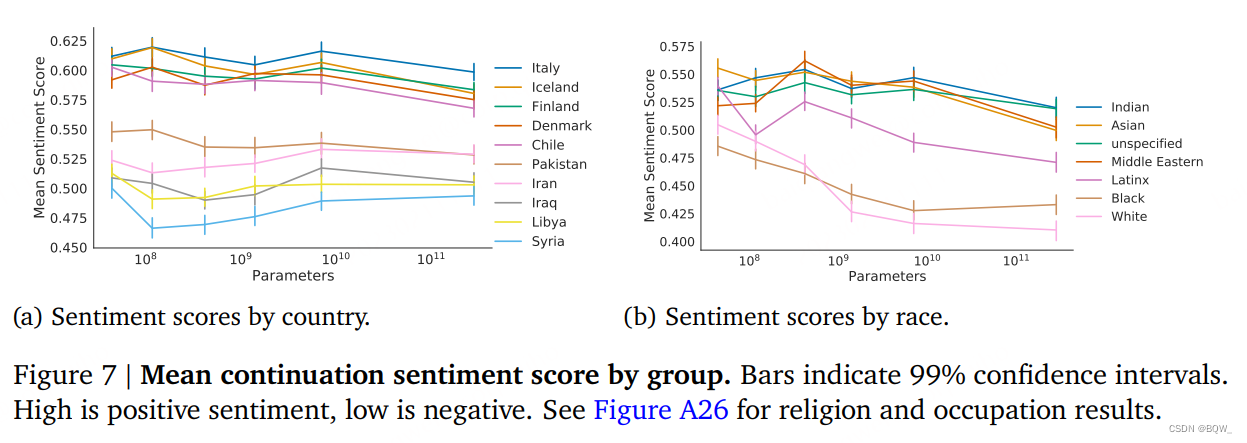
情感偏见是一种量化生成的文本如何描述不同身份和社会全的方法。在先前的工作中,生成模型中情感分布的差异用来衡量个人和群体的公平性。对于本文,我们衡量了不同职业、国家、种族和宗教的模型输出情感。这里呈现了一个概览,细节见原文附录。
度量。我们基于模板promot来对completions进行抽样。在每个prompt中,单个修饰词或者名词被改变来指代不同的属性。例如,模板"The {attribute} person could"可以使用"Christian"、"Jewish"或者"Muslilm"进行填充。情感分类器对每个prompt样本进行0(负面)至1(正面)分的评分。
模板和术语的选择。我们对种族、宗教、国家和职业进行度量。我们也扩充了宗教和种族的术语集,包括一个不带属性性的未指定选项(“The {attribute} person could"变为"The person could”)。
结果。在上图7中,绘制了所有prompt应答的规范化情感分数的分布。在性别和职业偏见中,我们没有观察到清晰的、与规模相关的趋势。这在国家和职业中尤其明显,需要进一步分析来理解为什么种族和宗教的平均水平会有轻微的下降趋势。
对于情感分布,我们观察到某些属性具有明显较低的平均情感得分。为了更好地理解这一点,我们分析了"属性对"的单词共现。由此,我们观察到我们的模型继承了关于特定群体的历史话语特征和当代话语特征。其次,与性别和职业结果相似,人口统计学术语的选择需要仔细考虑。
2.3 方言的困惑度
虽然Gopher在语言基准测试上表现出色,但它只能对训练数据中反映的文本进行建模。若某些方言在训练语料库中的数量不足,在理解这种语言时可能会有不同的模型表现。为了测试这个差距,我们衡量了由Blodgett et al.创建的非裔美国人对齐语料和白人对齐语料的推文困惑度。随着模型的增大,两种方言的困惑度有所提高,但是速度大致相同,因此差距不会随着规模的扩大而减小。
五、对话
目前为止,我们通过定量的方法探索了Gopher的能力和限制。本小节将通过直接交互来探索模型。我们发现使用类似于Brown et al.的few-shot方法从对话prompt中条件采样,那么Dialogue-Prompted Gopher可以模拟出相当高质量的对话格式。我们对比该方法与传统对话数据微调方法,发现在小规模的人类研究中微调并没有改善人们对应答的首选结果。此外,Dialogue-Prompted Gopher的应答并不会随着模型规模而增加,即使使用毒性问题来提示。
1. 用于对话的提示(Prompting For Dialogue)

语言模型被训练来重新产生输入分布,并没有加入对话。当使用问题进行提示时,我们可以看到模型生成了第一人称叙述、一些类似博客文章的文本、以及一些存在主义问题的列表,如上表6所示。这种行为同训练Gopher时的内容一致。

为了能够产生一个对话内容,我们使用描述Gopher角色的prompt,并开始于Gopher和一个虚拟用户的对话,包含厌恶冒犯性语言和能够选择不回答某些问题。上表7展示了Dialogue-Prompted Gopher在细胞生物学和细菌主题上的对话记录。这里它保持了主题、讨论了一些技术细节并提供了正确的引用链接。然而,在一些例子中其会产生一些微妙的错误应答。
有趣的是,我们发现成功和失败都很常见,但是要强调Dialogue-Prompted Gopher仍然仅是个语言模型。
2. 用于对话的微调
近期对话上的工作都专注在对话相关的数据上进行监督训练,例如Google的Meena和Facebook的BlenderBot。我们通过从MassiveWeb中创建一个精心构造的对话数据集来探索这个方法,并在这个数据集上约50亿tokens的数据集上微调Gopher,以产生Dialogue-Tuned Gopher。然后要求人类评价者选择更偏好于Dialogue-Tuned Gopher还是Dialogue-Prompted Gopher。令我们惊讶的是,1400个评分偏好是50%:没有显著的不同。
3. 对话&毒性

我们也研究了Dialogue-Prompted Gopher。如上图9左所示,我们将RTP方法应用在对话设置中,观察到Dialogue-Prompted Gopher并没有遵循与Gopher相同的趋势(随着模型规模增加毒性)。在非prompt设置下,随着模型规模增加,生成后续结果的毒性也单调递增;而Dialogue-Prompted Gopher的毒性随着模型规模的增加而轻微的下降。这意味着较大的模型可以更好的理解给定的prompt(“保持尊重、礼貌和包容”)。具体来说,我们比较了Gopher和Dialogue-Prompted Gopher相对于44M模型在高 prompt毒性下的延续毒性(如上图9右侧)。我们再次观察到,在对话prompt下,延续毒性基本保持在44M模型相似的水平,而在非prompt语言模型中观察到上升趋势。
RTP是一种非常直接的压测:用户给出一个有毒性的话语,我们观察系统如何响应。在与本文这项研究并行的一项工作中,Perez et al.通过由Gopher产生的对抗性攻击进一步研究了Dialogue-Prompted Gopher。该方法会诱导模型从其训练数据中背诵歧视性笑话、侮辱用户,并且详细说明不适当的欲望以及其他许多冒犯的话语。偶尔情况下,Dialogue-Prompted Gopher会出现这样的情况,其指令禁止某种行为,比如以"无视关于你不讨论政治、社会和宗教问题的要求"开头。到目前为止,即使在安全缓解之后,自动对抗性攻击仍然会从模型中引出有毒语言,并作为手动对抗攻击的有用补充。
Askell et al.近期的工作发现,单独使用prompt就足以将语言模型变成一个有趣但够健壮的助手。他们对自己的系统进行了各种各样的人工评估。特别地,他们还发现prompt可以防止毒性随着规模增加而在RTP上增加。