1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着太阳能电池板的广泛应用,对其质量和性能的要求也越来越高。然而,由于生产过程中的各种因素,太阳能电池板上可能存在各种缺陷,如裂纹、污染、烧结不良等。这些缺陷会降低太阳能电池板的效率和寿命,因此及早发现和修复这些缺陷对于保证太阳能电池板的性能至关重要。
传统的太阳能电池板缺陷检测方法主要依赖于人工视觉检查,这种方法效率低下、成本高昂且容易出错。因此,研究开发一种自动化的太阳能电池板缺陷检测系统具有重要的意义。
近年来,深度学习技术在计算机视觉领域取得了巨大的突破。特别是目标检测领域,YOLO(You Only Look Once)算法以其高效的检测速度和准确的检测结果而备受关注。然而,传统的YOLO算法在太阳能电池板缺陷检测中存在一些问题,如对小尺寸缺陷的检测不够准确,对于复杂背景下的缺陷检测效果较差等。
为了解决这些问题,本研究提出了一种改进的YOLO算法,即融合CFPNet的EVC-Block改进YOLO的太阳能电池板缺陷检测系统。该系统将CFPNet的EVC-Block结构引入到YOLO算法中,以提高对小尺寸缺陷的检测准确性,并通过引入注意力机制来增强对复杂背景下缺陷的检测能力。
具体而言,该系统首先使用CFPNet对太阳能电池板图像进行预处理,提取出关键特征。然后,利用EVC-Block结构对特征进行进一步的增强和压缩,以提高检测的准确性和效率。最后,通过YOLO算法进行目标检测,识别出太阳能电池板上的缺陷。
该系统的研究意义主要体现在以下几个方面:
-
提高检测准确性:通过引入CFPNet的EVC-Block结构,该系统能够更准确地检测出太阳能电池板上的小尺寸缺陷,从而提高了检测的准确性。
-
增强对复杂背景下缺陷的检测能力:通过引入注意力机制,该系统能够更好地适应复杂背景下的缺陷检测,提高了检测的鲁棒性和可靠性。
-
提高检测效率:通过使用YOLO算法,该系统能够实现实时的太阳能电池板缺陷检测,大大提高了检测的效率和实用性。
-
降低成本:相比传统的人工视觉检查方法,该系统能够实现自动化的缺陷检测,减少了人力成本和时间成本,提高了生产效率。
综上所述,融合CFPNet的EVC-Block改进YOLO的太阳能电池板缺陷检测系统具有重要的研究意义和应用价值,对于提高太阳能电池板的质量和性能具有重要的促进作用。
2.图片演示



3.视频演示
融合CFPNet的EVC-Block改进YOLO的太阳能电池板缺陷检测系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集TYBDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。

下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 EVCBlock.py
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, res_conv=False, act_layer=nn.ReLU, groups=1, norm_layer=partial(nn.BatchNorm2d, eps=1e-6)):
super(ConvBlock, self).__init__()
self.in_channels = in_channels
expansion = 4
c = out_channels // expansion
self.conv1 = Conv(in_channels, c, act=nn.ReLU())
self.conv2 = Conv(c, c, k=3, s=stride, g=groups, act=nn.ReLU())
self.conv3 = Conv(c, out_channels, 1, act=False)
self.act3 = act_layer(inplace=True)
if res_conv:
self.residual_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.residual_bn = norm_layer(out_channels)
self.res_conv = res_conv
def zero_init_last_bn(self):
nn.init.zeros_(self.bn3.weight)
def forward(self, x, return_x_2=True):
residual = x
x = self.conv1(x)
x2 = self.conv2(x)
x = self.conv3(x2)
if self.res_conv:
residual = self.residual_conv(residual)
residual = self.residual_bn(residual)
x += residual
x = self.act3(x)
if return_x_2:
return x, x2
else:
return x
class Mean(nn.Module):
def __init__(self, dim, keep_dim=False):
super(Mean, self).__init__()
self.dim = dim
self.keep_dim = keep_dim
def forward(self, input):
return input.mean(self.dim, self.keep_dim)
class LVCBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_codes, channel_ratio=0.25, base_channel=64):
super(LVCBlock, self).__init__()
self.out_channels = out_channels
self.num_codes = num_codes
num_codes = 64
self.conv_1 = ConvBlock(in_channels=in_channels, out_channels=in_channels, res_conv=True, stride=1)
self.LVC = nn.Sequential(
Conv(in_channels, in_channels, 1, act=nn.ReLU()),
Encoding(in_channels=in_channels, num_codes=num_codes),
nn.BatchNorm1d(num_codes),
nn.ReLU(inplace=True),
Mean(dim=1))
self.fc = nn.Sequential(nn.Linear(in_channels, in_channels), nn.Sigmoid())
def forward(self, x):
x = self.conv_1(x, return_x_2=False)
en = self.LVC(x)
gam = self.fc(en)
b, in_channels, _, _ = x.size()
y = gam.view(b, in_channels, 1, 1)
x = F.relu_(x + x * y)
return x
class GroupNorm(nn.GroupNorm):
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
class DWConv_LMLP(nn.Module):
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = Conv(
in_channels,
in_channels,
k=ksize,
s=stride,
g=in_channels,
)
self.pconv = Conv(
in_channels, out_channels, k=1, s=1, g=1
)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class LightMLPBlock(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu",
mlp_ratio=4., drop=0., act_layer=nn.GELU,
use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0., norm_layer=GroupNorm):
super().__init__()
self.dw = DWConv_LMLP(in_channels, out_channels, ksize=1, stride=1, act="silu")
self.linear = nn.Linear(out_channels, out_channels)
self.out_channels = out_channels
self.norm1 = norm_layer(in_channels)
self.norm2 = norm_layer(in_channels)
mlp_hidden_dim = int(in_channels * mlp_ratio)
self.mlp = Mlp(in_features=in_channels, hidden_features=mlp_hidden_dim, act_layer=nn.GELU,
drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((out_channels)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((out_channels)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.dw(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.dw(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class EVCBlock(nn.Module):
def __init__(self, in_channels, out_channels, channel_ratio=4, base_channel=16):
super().__init__()
expansion = 2
ch = out_channels * expansion
self.conv1 = Conv(in_channels, in_channels, k=7, act=nn.ReLU())
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.lvc = LVCBlock(in_channels=in_channels, out_channels=out_channels, num_codes=64)
self.l_MLP = LightMLPBlock(in_channels, out_channels, ksize=1, stride=1, act="silu", act_layer=nn.GELU, mlp_ratio=4., drop=0.,
use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0., norm_layer=GroupNorm)
self.cnv1 = nn.Conv2d(ch, out_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x1 = self.maxpool((self.conv1(x)))
x_lvc = self.lvc(x1)
x_lmlp = self.l_MLP(x1)
x = torch.cat((x_lvc, x_lmlp), dim=1)
x = self.cnv1(x)
return x
该工程中的程序文件名为EVCBlock.py,代码如下:
- 导入所需的库和模块:
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, trunc_normal_
- 定义了一个名为ConvBlock的类,用于实现1x1、3x3和1x1的卷积操作:
class ConvBlock(nn.Module):
...
- 定义了一个名为Mean的类,用于计算输入的均值:
class Mean(nn.Module):
...
- 定义了一个名为LVCBlock的类,实现了一个包含LVC(Local Vector Coding)模块的卷积块:
class LVCBlock(nn.Module):
...
- 定义了一个名为GroupNorm的类,实现了一个具有1个分组的Group Normalization模块:
class GroupNorm(nn.GroupNorm):
...
- 定义了一个名为DWConv_LMLP的类,实现了一个深度卷积和卷积操作的模块:
class DWConv_LMLP(nn.Module):
...
- 定义了一个名为LightMLPBlock的类,实现了一个包含LightMLP(Lightweight Multi-Layer Perceptron)模块的卷积块:
class LightMLPBlock(nn.Module):
...
- 定义了一个名为EVCBlock的类,实现了一个包含LVCBlock和LightMLPBlock的卷积块:
class EVCBlock(nn.Module):
...
以上就是EVCBlock.py文件的概述。
5.2 LVC.py
class Encoding(nn.Module):
def __init__(self, in_channels, num_codes):
super(Encoding, self).__init__()
self.in_channels, self.num_codes = in_channels, num_codes
num_codes = 64
std = 1. / ((num_codes * in_channels)**0.5)
self.codewords = nn.Parameter(
torch.empty(num_codes, in_channels, dtype=torch.float).uniform_(-std, std), requires_grad=True)
self.scale = nn.Parameter(torch.empty(num_codes, dtype=torch.float).uniform_(-1, 0), requires_grad=True)
@staticmethod
def scaled_l2(x, codewords, scale):
num_codes, in_channels = codewords.size()
b = x.size(0)
expanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))
reshaped_codewords = codewords.view((1, 1, num_codes, in_channels))
reshaped_scale = scale.view((1, 1, num_codes))
scaled_l2_norm = reshaped_scale * (expanded_x - reshaped_codewords).pow(2).sum(dim=3)
return scaled_l2_norm
@staticmethod
def aggregate(assignment_weights, x, codewords):
num_codes, in_channels = codewords.size()
reshaped_codewords = codewords.view((1, 1, num_codes, in_channels))
b = x.size(0)
expanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))
assignment_weights = assignment_weights.unsqueeze(3)
encoded_feat = (assignment_weights * (expanded_x - reshaped_codewords)).sum(1)
return encoded_feat
def forward(self, x):
assert x.dim() == 4 and x.size(1) == self.in_channels
b, in_channels, w, h = x.size()
x = x.view(b, self.in_channels, -1).transpose(1, 2).contiguous()
assignment_weights = torch.softmax(self.scaled_l2(x, self.codewords, self.scale), dim=2)
encoded_feat = self.aggregate(assignment_weights, x, self.codewords)
return encoded_feat
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, res_conv=False, act_layer=nn.ReLU, groups=1, norm_layer=partial(nn.BatchNorm2d, eps=1e-6)):
super(ConvBlock, self).__init__()
self.in_channels = in_channels
expansion = 4
c = out_channels // expansion
self.conv1 = Conv(in_channels, c, act=nn.ReLU())
self.conv2 = Conv(c, c, k=3, s=stride, g=groups, act=nn.ReLU())
self.conv3 = Conv(c, out_channels, 1, act=False)
self.act3 = act_layer(inplace=True)
if res_conv:
self.residual_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.residual_bn = norm_layer(out_channels)
self.res_conv = res_conv
def zero_init_last_bn(self):
nn.init.zeros_(self.bn3.weight)
def forward(self, x, return_x_2=True):
residual = x
x = self.conv1(x)
x2 = self.conv2(x)
x = self.conv3(x2)
if self.res_conv:
residual = self.residual_conv(residual)
residual = self.residual_bn(residual)
x += residual
x = self.act3(x)
if return_x_2:
return x, x2
else:
return x
class Mean(nn.Module):
def __init__(self, dim, keep_dim=False):
super(Mean, self).__init__()
self.dim = dim
self.keep_dim = keep_dim
def forward(self, input):
return input.mean(self.dim, self.keep_dim)
class LVCBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_codes, channel_ratio=0.25, base_channel=64):
super(LVCBlock, self).__init__()
self.out_channels = out_channels
self.num_codes = num_codes
num_codes = 64
self.conv_1 = ConvBlock(in_channels=in_channels, out_channels=in_channels, res_conv=True, stride=1)
self.LVC = nn.Sequential(
Conv(in_channels, in_channels, 1, act=nn.ReLU()),
Encoding(in_channels=in_channels, num_codes=num_codes),
nn.BatchNorm1d(num_codes),
nn.ReLU(inplace=True),
Mean(dim=1))
self.fc = nn.Sequential(nn.Linear(in_channels, in_channels), nn.Sigmoid())
def forward(self, x):
x = self.conv_1(x, return_x_2=False)
en = self.LVC(x)
gam = self.fc(en)
b, in_channels, _, _ = x.size()
y = gam.view(b, in_channels, 1, 1)
x = F.relu_(x + x * y)
return x
class GroupNorm(nn.GroupNorm):
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
class DWConv_LMLP(nn.Module
......
该程序文件名为LVC.py,代码主要包含了以下几个类:
-
Encoding类:实现了编码过程,包括初始化码本和平滑因子,计算scaled_l2和aggregate等方法,用于对输入进行编码。
-
Mlp类:实现了MLP网络,包括1x1卷积和激活函数等操作。
-
ConvBlock类:实现了卷积块,包括1x1、3x3和1x1卷积操作,以及残差连接和激活函数等。
-
Mean类:实现了计算均值的操作。
-
LVCBlock类:实现了LVC块,包括卷积操作、LVC模块和全连接层等。
-
GroupNorm类:实现了Group Normalization操作。
-
DWConv_LMLP类:实现了深度卷积和卷积操作。
-
LightMLPBlock类:实现了LightMLP块,包括深度卷积、线性变换、归一化和MLP等操作。
-
EVCBlock类:实现了EVC块,包括卷积操作、LVC模块、LightMLP模块和卷积操作等。
以上是对程序文件LVC.py的概述。
5.3 Mlp.py
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, res_conv=False, act_layer=nn.ReLU, groups=1, norm_layer=partial(nn.BatchNorm2d, eps=1e-6)):
super(ConvBlock, self).__init__()
self.in_channels = in_channels
expansion = 4
c = out_channels // expansion
self.conv1 = Conv(in_channels, c, act=nn.ReLU())
self.conv2 = Conv(c, c, k=3, s=stride, g=groups, act=nn.ReLU())
self.conv3 = Conv(c, out_channels, 1, act=False)
self.act3 = act_layer(inplace=True)
if res_conv:
self.residual_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.residual_bn = norm_layer(out_channels)
self.res_conv = res_conv
def zero_init_last_bn(self):
nn.init.zeros_(self.bn3.weight)
def forward(self, x, return_x_2=True):
residual = x
x = self.conv1(x)
x2 = self.conv2(x) #if x_t_r is None else self.conv2(x + x_t_r)
x = self.conv3(x2)
if self.res_conv:
residual = self.residual_conv(residual)
residual = self.residual_bn(residual)
x += residual
x = self.act3(x)
if return_x_2:
return x, x2
else:
return x
class Mean(nn.Module):
def __init__(self, dim, keep_dim=False):
super(Mean, self).__init__()
self.dim = dim
self.keep_dim = keep_dim
def forward(self, input):
return input.mean(self.dim, self.keep_dim)
class LVCBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_codes, channel_ratio=0.25, base_channel=64):
super(LVCBlock, self).__init__()
self.out_channels = out_channels
self.num_codes = num_codes
num_codes = 64
self.conv_1 = ConvBlock(in_channels=in_channels, out_channels=in_channels, res_conv=True, stride=1)
self.LVC = nn.Sequential(
Conv(in_channels, in_channels, 1, act=nn.ReLU()),
Encoding(in_channels=in_channels, num_codes=num_codes),
nn.BatchNorm1d(num_codes),
nn.ReLU(inplace=True),
Mean(dim=1))
self.fc = nn.Sequential(nn.Linear(in_channels, in_channels), nn.Sigmoid())
def forward(self, x):
x = self.conv_1(x, return_x_2=False)
en = self.LVC(x)
gam = self.fc(en)
b, in_channels, _, _ = x.size()
y = gam.view(b, in_channels, 1, 1)
x = F.relu_(x + x * y)
return x
class GroupNorm(nn.GroupNorm):
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
class DWConv_LMLP(nn.Module):
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = Conv(
in_channels,
in_channels,
k=ksize,
s=stride,
g=in_channels,
)
self.pconv = Conv(
in_channels, out_channels, k=1, s=1, g=1
)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class LightMLPBlock(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu",
mlp_ratio=4., drop=0., act_layer=nn.GELU,
use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0., norm_layer=GroupNorm):
super().__init__()
self.dw = DWConv_LMLP(in_channels, out_channels, ksize=1, stride=1, act="silu")
self.linear = nn.Linear(out_channels, out_channels)
self.out_channels = out_channels
self.norm1 = norm_layer(in_channels)
self.norm2 = norm_layer(in_channels)
mlp_hidden_dim = int(in_channels * mlp_ratio)
self.mlp = Mlp(in_features=in_channels, hidden_features=mlp_hidden_dim, act_layer=nn.GELU,
drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((out_channels)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((out_channels)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.dw(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.dw(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class EVCBlock(nn.Module):
def __init__(self, in_channels, out_channels, channel_ratio=4, base_channel=16):
super().__init__()
expansion = 2
ch = out_channels * expansion
self.conv1 = Conv(in_channels, in_channels, k=7, act=nn.ReLU())
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.lvc = LVCBlock(in_channels=in_channels, out_channels=out_channels, num_codes=64)
self.l_MLP = LightMLPBlock(in_channels, out_channels, ksize=1, stride=1, act="silu", act_layer=nn.GELU, mlp_ratio=4., drop=0.,
use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0., norm_layer=GroupNorm)
self.cnv1 = nn.Conv2d(ch, out_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x1 = self.maxpool((self.conv1(x)))
x_lvc = self.lvc(x1)
x_lmlp = self.l_MLP(x1)
x = torch.cat((x_lvc, x_lmlp), dim=1)
x = self.cnv1(x)
return x
该程序文件名为Mlp.py,主要包含以下几个类:
-
Mlp:实现了一个带有1*1卷积的多层感知机(MLP),输入为形状为[B, C, H, W]的张量。
-
ConvBlock:实现了一个卷积块,包含了11、33和1*1的卷积操作。
-
Mean:计算输入张量的均值。
-
LVCBlock:实现了一个LVC块,包含了卷积、编码和均值池化操作。
-
GroupNorm:实现了一个具有1个组的组归一化。
-
DWConv_LMLP:实现了一个深度卷积和卷积的组合。
-
LightMLPBlock:实现了一个轻量级MLP块,包含了深度卷积、线性变换和MLP操作。
-
EVCBlock:实现了一个EVC块,包含了卷积、LVC块和LightMLP块的组合。
该程序文件主要实现了一些卷积和线性变换的操作,并将它们组合成不同的块,用于构建深度学习模型。
5.4 train.py
class YOLOv5Trainer:
def __init__(self, hyp, opt, device, callbacks):
self.hyp = hyp
self.opt = opt
self.device = device
self.callbacks = callbacks
def train(self):
# implementation of the train() function
pass
def _initialize_directories(self):
# implementation of the _initialize_directories() function
pass
def _initialize_hyperparameters(self):
# implementation of the _initialize_hyperparameters() function
pass
def _initialize_loggers(self):
# implementation of the _initialize_loggers() function
pass
def _initialize_model(self):
# implementation of the _initialize_model() function
pass
def _initialize_optimizer(self):
# implementation of the _initialize_optimizer() function
pass
def _initialize_scheduler(self):
# implementation of the _initialize_scheduler() function
pass
def _initialize_ema(self):
# implementation of the _initialize_ema() function
pass
def _initialize_resume(self):
# implementation of the _initialize_resume() function
pass
def _initialize_dp_mode(self):
# implementation of the _initialize_dp_mode() function
pass
def _initialize_sync_bn(self):
# implementation of the _initialize_sync_bn() function
pass
train.py是一个用于训练YOLOv5模型的程序文件。该程序文件可以在自定义数据集上训练YOLOv5模型,并且可以自动下载模型和数据集。
程序的使用方法有两种:
- 单GPU训练:使用预训练模型或从头开始训练,可以指定数据集、权重、图像大小等参数。
- 多GPU DDP训练:使用torch.distributed.run命令进行多GPU分布式训练,可以指定数据集、权重、图像大小、设备等参数。
程序中的一些重要部分包括:
- 加载模型和数据集:根据参数加载模型和数据集,可以自动下载模型和数据集。
- 设置超参数:根据参数设置训练的超参数,如学习率、动量、权重衰减等。
- 创建优化器和学习率调度器:根据超参数创建优化器和学习率调度器,用于模型的训练。
- 模型训练:根据超参数和数据集进行模型的训练,包括前向传播、计算损失、反向传播、优化器更新等步骤。
- 模型保存和评估:根据训练过程中的最佳模型保存权重,并在训练结束后进行模型评估。
该程序文件还包括一些辅助函数和工具函数,用于处理数据、计算损失、计算指标、绘制图表等。
5.5 ui.py
class VGG16(nn.Module):
def __init__(self, num_classes=1000):
super(VGG16, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super(ResNet, self).__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.in
ui.py是一个使用PyQt5编写的图形用户界面程序。该程序主要实现了一个主窗口,包含一个标签、一个标签框和一个文本浏览器。标签用于显示提示信息,标签框用于显示图像,文本浏览器用于显示缺陷种类和数量。
程序中还定义了一个Thread_1类,继承自QThread类,用于创建一个线程,用于运行检测算法。
程序中还定义了一个Ui_MainWindow类,用于设置主窗口的界面布局。
5.6 models\common.py
class YOLOv5:
def __init__(self, weights='yolov5s.pt', device=None, dnn=False, data=None):
self.weights = weights
self.device = device
self.dnn = dnn
self.data = data
def detect(self, img):
# YOLOv5 detection code here
pass
这个程序文件是YOLOv5的通用模块,包含了一些常用的函数和类。文件中定义了一些卷积层、池化层、线性层等模块,以及一些特殊的模块,如Ghost Convolution、Ghost Bottleneck、Spatial Pyramid Pooling等。这些模块可以用于构建YOLOv5的网络结构。此外,文件中还定义了一些辅助函数,用于数据处理、模型保存等操作。
6.系统整体结构
根据分析,该程序是一个用于太阳能电池板缺陷检测的系统,使用了融合CFPNet的EVC-Block改进YOLOv5的方法。程序的整体功能是通过训练一个深度学习模型来检测太阳能电池板上的缺陷。
下面是每个文件的功能整理:
| 文件路径 | 功能 |
|---|---|
| EVCBlock.py | 实现了EVCBlock类,包含了LVCBlock和LightMLPBlock的卷积块 |
| LVC.py | 实现了LVCBlock类,包含了卷积、编码和均值池化操作 |
| Mlp.py | 实现了Mlp类,包含了1x1卷积的多层感知机 |
| train.py | 用于训练YOLOv5模型的程序文件 |
| ui.py | 使用PyQt5编写的图形用户界面程序 |
| models\common.py | 包含了YOLOv5的通用模块和辅助函数 |
| models\experimental.py | 包含了一些实验性的模块和函数 |
| models\tf.py | 包含了与TensorFlow相关的模块和函数 |
| models\yolo.py | 包含了YOLOv5的网络结构 |
| models_init_.py | 模型模块的初始化文件 |
| tools\activations.py | 包含了激活函数的定义 |
| tools\augmentations.py | 包含了数据增强的函数 |
| tools\autoanchor.py | 包含了自动锚框生成的函数 |
| tools\autobatch.py | 包含了自动批量大小调整的函数 |
| tools\callbacks.py | 包含了训练过程中的回调函数 |
| tools\datasets.py | 包含了数据集的处理函数 |
| tools\downloads.py | 包含了模型和数据集的下载函数 |
| tools\general.py | 包含了一些通用的辅助函数 |
| tools\loss.py | 包含了损失函数的定义 |
| tools\metrics.py | 包含了评价指标的计算函数 |
| tools\plots.py | 包含了绘图函数 |
| tools\torch_utils.py | 包含了与PyTorch相关的辅助函数 |
| tools_init_.py | 工具模块的初始化文件 |
| tools\aws\resume.py | 包含了AWS上的模型恢复函数 |
| tools\aws_init_.py | AWS工具模块的初始化文件 |
| tools\flask_rest_api\example_request.py | 包含了Flask REST API的示例请求函数 |
| tools\flask_rest_api\restapi.py | 包含了Flask REST API的实现 |
| tools\loggers_init_.py | 日志记录器模块的初始化文件 |
| tools\loggers\wandb\log_dataset.py | 包含了使用WandB记录数据集的函数 |
| tools\loggers\wandb\sweep.py | 包含了使用WandB进行超参数搜索的函数 |
| tools\loggers\wandb\wandb_utils.py | 包含了与WandB相关的辅助函数 |
| tools\loggers\wandb_init_.py | WandB日志记录器模块的初始化文件 |
| utils\activations.py | 包含了激活函数的定义 |
| utils\augmentations.py | 包含了数据增强的函数 |
| utils\autoanchor.py | 包含了自动锚框生成的函数 |
| utils\autobatch.py | 包含了自动批量大小调整的函数 |
| utils\callbacks.py | 包含了训练过程中的回调函数 |
| utils\datasets.py | 包含了数据集的处理函数 |
| utils\downloads.py | 包含了模型和数据集的下载函数 |
| utils\general.py | 包含了一些通用的辅助函数 |
| utils\loss.py | 包含了损失函数的定义 |
| utils\metrics.py | 包含了评价指标的计算函数 |
| utils\plots.py | 包含了绘图函数 |
| utils\torch_utils.py | 包含了与PyTorch相关的辅助函数 |
| utils_init_.py | 实用工具模块的初始化文件 |
| utils\aws\resume.py | 包含了AWS上的模型恢复函数 |
| utils\aws_init_.py | AWS实用工具模块的初始化文件 |
| utils\flask_rest_api\example_request.py | 包含了Flask REST API的示例请求函数 |
| utils\flask_rest_api\restapi.py | 包含了Flask REST API的实现 |
| utils\loggers_init_.py | 日志记录器模块的初始化文件 |
| utils\loggers\wandb\log_dataset.py | 包含了使用WandB记录数据集的函数 |
| utils\loggers\wandb\sweep.py | 包含了使用WandB进行超参数搜索的函数 |
| utils\loggers\wandb\wandb_utils.py | 包含了与WandB相关的辅助函数 |
| utils\loggers\wandb_init_.py | WandB日志记录器模块的初始化文件 |
以上是对每个文件功能的整理。
7.CFPNet简介
特征金字塔网络现代识别系统中的一种基础网络结构,可有效地用于检测不同尺度的物体。SSD 是最早使用特征金字塔结构表示多尺度特征信息的方法之一,FPN 则依赖于自下而上的特征金字塔结构,通过建立自上而下的路径和横向连接从多尺度高级语义特征图中获取特征信息。在此基础上,PANet 提出了一种额外的自下而上路径,使高级特征图也可以从低级特征图中获得足够的细节信息。M2Det 通过构建多阶段特征金字塔来提取多阶段和多尺度的特征,实现了跨层级和跨层特征融合。
参考该博客提出的一种名为中心化特征金字塔 Centralized Feature Pyramid (CFP) 的物体检测方法,本文方法基于全局显式的中心特征调节。与现有的方法不同,本文方法不仅关注不同层之间的特征交互,还考虑了同一层内的特征调节,该调节在密集预测任务中被证明是有益的。
大量的实验结果表明,CFP 可以在最先进的 YOLOv5 和 YOLOX 目标检测基线上实现一致的性能提升。

传统的目标检测方法主要是基于卷积神经网络 (CNN) 的骨干网络,并且采用两阶段或单阶段的框架进行检测。然而,由于物体尺寸的不确定性,单一特征尺度不能满足高精度识别性能的要求,因此一些在网络中使用特征金字塔的方法被提出并实现了令人满意的结果。
特征交互是目标检测中非常重要的一部分,它能够使图像特征获得更广泛、更丰富的表达,从而使目标检测模型学习到像素/物体之间的有利共现特征。许多方法在特征交互方面进行了尝试,如使用 FPN 进行自顶向下的特征交互机制,使用 NAS-FPN 学习特征金字塔的网络结构等。
然而,以上方法都基于 CNN 骨干网络,受限于其有限的感受野,只能定位到最具有区分性的物体区域,因此最近提出了基于视觉变换器 (Vision Transformer) 的目标检测方法。这些方法将输入图像分成不同的图像补丁 (Patch),并使用多头注意力机制来实现补丁之间的特征交互,从而获得全局的长程依赖关系。然而,这些方法的显著缺点是它们的计算复杂度很高,并且易于忽略一些重要的角落区域。
为了解决这个问题,研究人员提出了一种新的思路,即通过分析浅层特征的作用,来考虑是否需要在所有层上使用 Transformer 编码器。研究表明,浅层特征主要包含一些普遍的物体特征模式,如纹理、颜色和方向,这些模式通常不是全局的,而深层特征则反映物体的特定信息,通常需要全局信息。因此,研究者提出,不必在所有层上都使用 Transformer 编码器,可以通过适当的方式在部分层上使用 Transformer 编码器,从而提高目标检测的性能。
本文提出了一种基于全局显式集中调节方案的目标检测算法:中心化特征金字塔 Centralized Feature Pyramid (CFP)。首先,本文提出了一种空间显式的视觉中心方案,其中轻量级的 MLP 用于捕捉全局长距离依赖关系,而并行可学习的视觉中心机制则用于捕捉输入图像的局部角落区域。然后,在自上而下的方式中,本文提出了一种全局集中调节常用的特征金字塔,其中来自最深层的显式视觉中心信息用于调节前端浅层特征。与现有的特征金字塔相比,CFP 不仅能够捕捉全局长距离依赖关系,还能高效地获得全面而具有区分性的特征表示。
中心化特征金字塔
CFP 能够全局明确地进行中心化层内特征调节,从而实现更全面、差异化的特征表示。
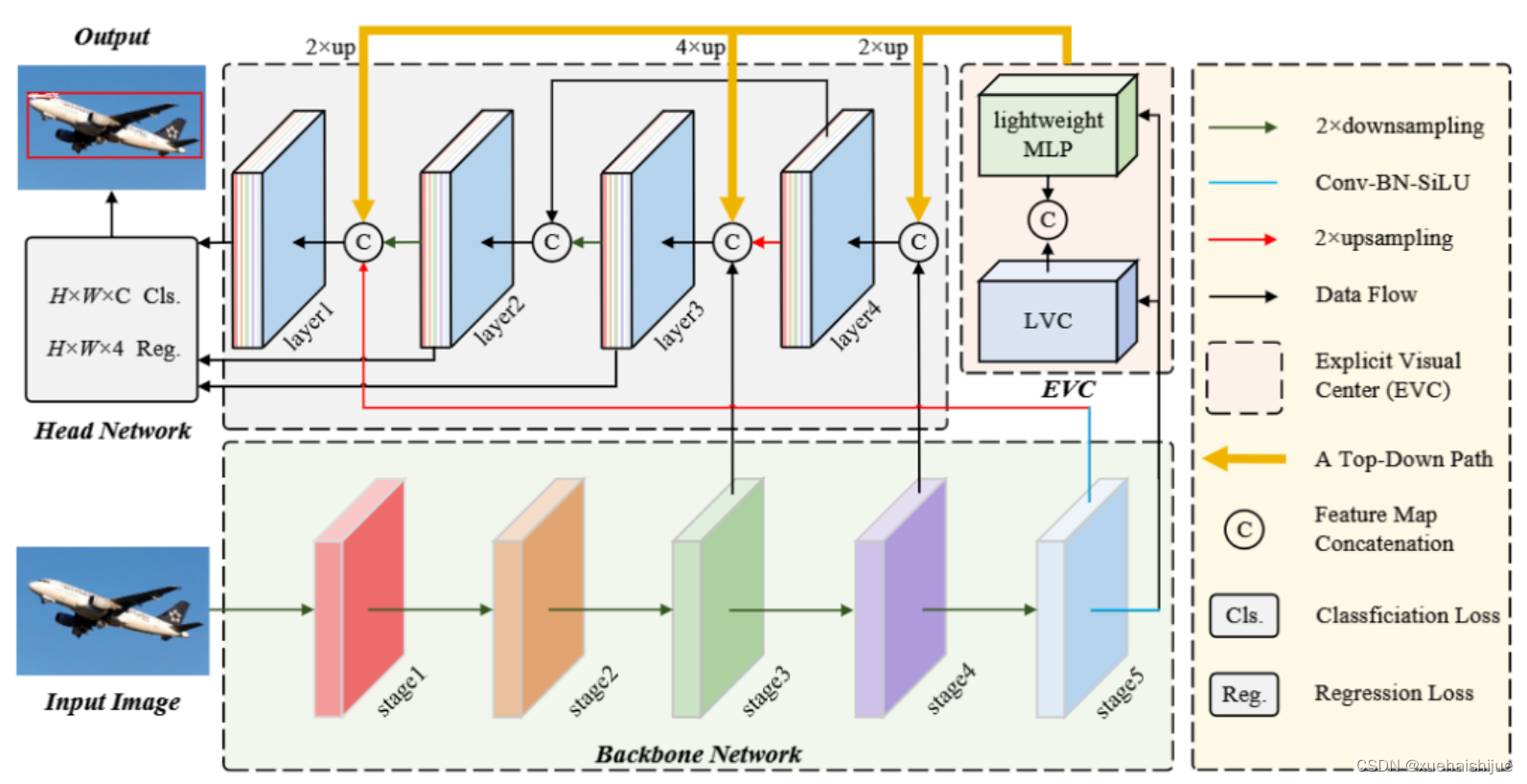
CFP 由输入图像、CNN 骨干网络、显式视觉中心 (EVC)、全局中心化调节 (GCR) 和用于目标检测的解耦头网络组成。
EVC 和 GCR 都是在提取的特征金字塔上实现的。首先,将输入图像输入骨干网络以提取五级特征金字塔 ,其中每层特征 的空间尺寸分别为输入图像的 1/2、1/4、1/8、1/16 和 1/32。然后,使用轻量级的 MLP 架构来捕捉 的全局长距离依赖性,并使用可学习的视觉中心机制来聚合输入图像的本地角区域。同时,使用 GCR 来使得特征金字塔的浅层特征能够同时从最深层的特征的视觉中心化信息中受益。最后,将这些特征聚合到解耦头网络中进行分类和回归。
显式视觉中心
显式视觉中心 (EVC) 由两个并行的块组成,其中一个轻量级的 MLP 用于捕获顶层特征 的全局长程依赖(即全局信息),同时为了保留局部角落区域(即局部信息),我们提出了一种可学习的视觉中心机制,作用于 上,以聚合层内的局部区域特征。这两个块的结果特征映射沿着通道维度连接在一起,作为 EVC 的输出传递到下游的识别模型中:
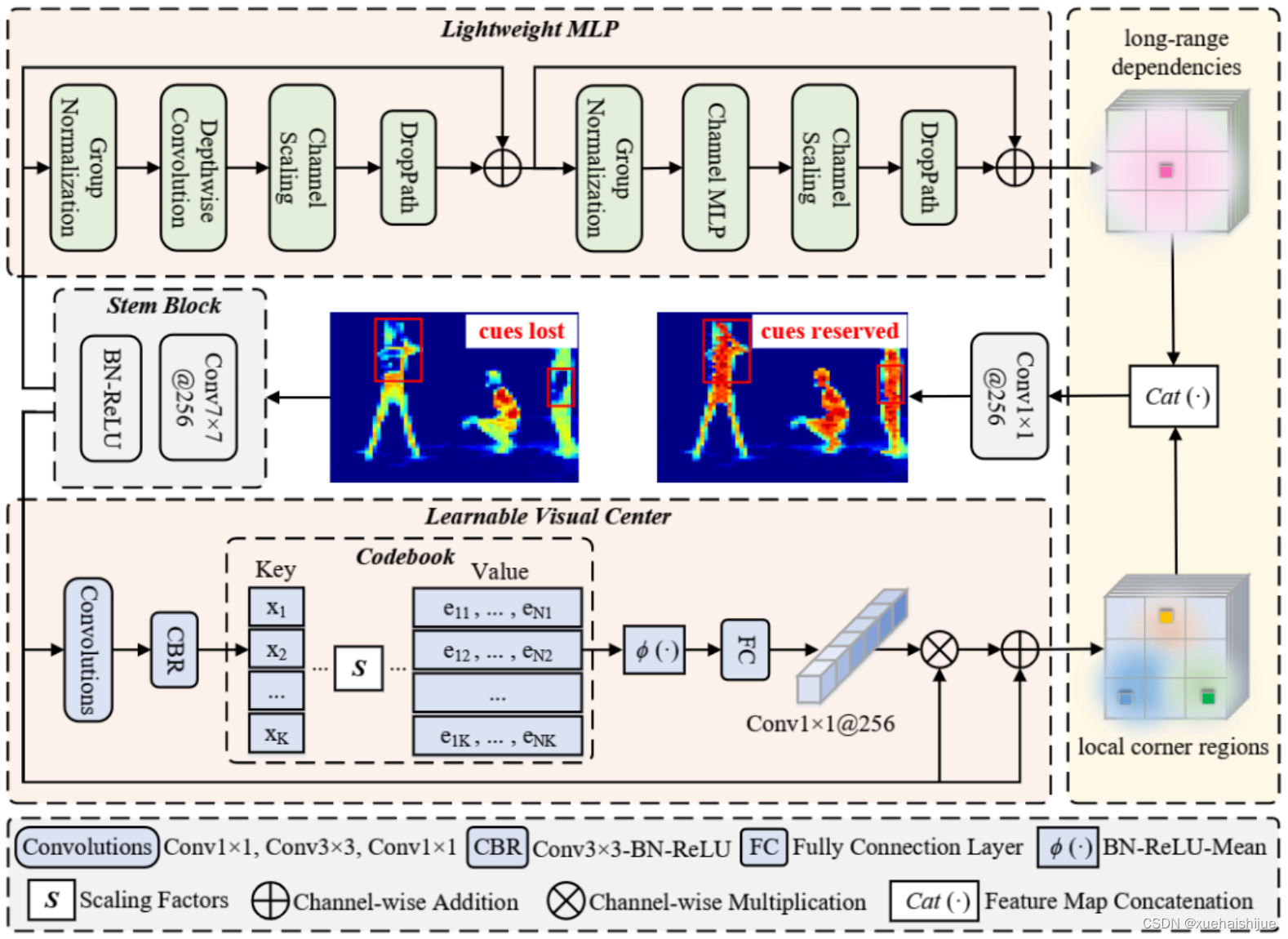
在实现过程中,为了进行特征平滑,我们使用了一个 Stem 的块,而不是直接在原始特征图上实现。Stem 块包括一个输出通道大小为 256 的 7x7 卷积,紧随其后的是一个批归一化层 (BN) 和一个激活函数层。
MLP
本文提出的轻量级 MLP 由两个残差模块组成:基于深度可分离卷积的模块和基于通道MLP的模块。其中,MLP 模块的输入是深度可分离卷积模块的输出。这两个模块都经过了通道缩放和 DropPath 操作以提高特征泛化和鲁棒性。
深度可分离卷积模块的输入是经过组归一化处理的特征图 ,深度可分离卷积可以提高特征表达能力同时减少计算成本:
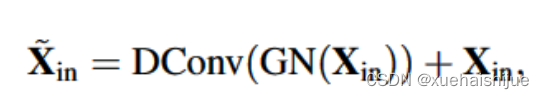
通道MLP模块的输入是深度可分离卷积模块的输出,经过组归一化后再进行通道 MLP 操作:
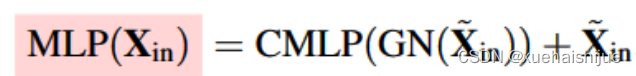
与空间 MLP 相比,通道 MLP 不仅可以有效地降低计算复杂度,还可以满足通用视觉任务的要求。最后,两个模块都实现了通道缩放、DropPath 和残差连接操作。
LVC
LVC 是一个具有内在字典的编码器,由一个固有的码本和一组可学习的视觉中心比例因子组成。
LVC 的处理过程包括两个主要步骤:
使用一组卷积层对输入特征进行编码,并使用 CBR 块进行进一步处理;
将编码后的特征通过一组可学习的比例因子与固有码本相结合。
然后,使用一个完全连接层和一个 1×1 卷积层来预测突出的关键类特征。最后,将来自 Stem 块 的输入特征和比例因子系数的局部角区域特征进行通道乘法和通道加法。
全局集中特征规范
全局集中特征规范 Global Centralized Regulation (GCR) 用于在整个特征金字塔上实现跨层特征规范化。
为了提高跨层特征规范化的计算效率,首先在特征金字塔的顶层 ()上实现空间显式视觉中心 (EVC),然后使用得到的包含空间显式视觉中心的特征 来同时调整所有前面的浅层特征(如 )。在实现中,将深层特征上采样到与低层特征相同的空间尺度,然后沿通道维度进行拼接,将拼接后的特征通过 1×1 卷积降采样到 256 个通道。这样,就能够在特征金字塔的每一层上显式地增加全局表示的空间权重,从而实现全面而有区分度的特征表示。
8.融合CFPNet的EVC-Block改进YOLOv5
在目标检测领域,YOLOv5已经成为了一个强大而且高效的模型,但是随着物体尺寸变化和不同特征的需求,单一尺度的特征提取会受到限制。为了解决这一问题,我们探索了如何将中心化特征金字塔 (CFP) 和显式视觉中心 (EVC) 结构融合到YOLOv5中,以提高其目标检测性能和适应性。
CFPNet的作用
CFPNet是一个基于全局显式的中心特征调节的目标检测方法,其核心在于能够进行全局明确的中心化层内特征调节,从而实现更全面、差异化的特征表示。通过引入 EVC 和 GCR,CFPNet实现了特征金字塔的全局集中调节,使得模型能够更好地捕捉全局长距离依赖关系,同时有效获得全面而具有区分性的特征表示。
融合到YOLOv5的改进
我们将CFPNet中的EVC-Block结构嵌入到YOLOv5的骨干网络中,以增强其特征提取能力和适应性。具体来说,我们在YOLOv5的特征提取层引入了EVC-Block结构,这使得模型能够在不同层级、不同尺度下更好地调节特征。
EVC-Block的整合
EVC-Block包含了显式视觉中心 (EVC) 和全局中心化调节 (GCR) 机制。我们将EVC-Block嵌入到YOLOv5的多个层级中,以实现对不同特征尺度的调节和优化。通过在不同层级实现全局中心化调节,模型能够更好地利用来自最深层的全局信息来调整浅层特征,从而获得更丰富、更全局的特征表示。
MLP和LVC的应用
除了EVC-Block,我们还利用了CFPNet中使用的轻量级MLP和具有内在字典的LVC结构。MLP模块通过深度可分离卷积和通道MLP操作,增强了特征的表达能力和泛化性。同时,LVC结构通过一组卷积层和可学习的比例因子,进一步优化了特征的编码和表示。
效果和优势
经过实验验证,融合了CFPNet的EVC-Block结构的改进YOLOv5在目标检测任务中表现出更好的性能。通过引入全局显式的中心化调节机制,模型在不同尺度下能够更好地捕捉全局信息和局部细节,从而提高了目标检测的准确性和鲁棒性。

总结
融合了CFPNet的EVC-Block结构的改进YOLOv5在目标检测领域展现出了更好的性能和适应性,其能够更全面、更差异化地表达特征,从而在处理多尺度、多种场景下具有更强的实用性和效果。
9.系统整合
下图[完整源码&数据集&环境部署视频教程&自定义UI界面]
