
Amoro 是一个构建在 Apache Iceberg 等开放数据湖表格之上的湖仓管理系统,提供了一套可插拔的数据自优化机制和管理服务,旨在为用户带来开箱即用的湖仓使用体验。
01 作者简介
喻志强,浙江电信大数据中心平台组负责人,拥有超10年电信行业数据仓库和大数据建设实施经验。资深商业化 MPP 数据库 Vertica 以及开源 MPP 数据库 StarRocks-DBA。目前主要参与基于 Apache Iceberg 的湖仓一体方向架构以及开源 MPP 产品数据应用集市的建设实施。
02 Apache Iceberg 在浙江电信
为什么选择 Iceberg
浙江电信大数据中心主要负责电信的业务数据汇聚和数仓生产以及部分数据应用。大数据架构革新到目前为止大体历经三个阶段。
阶段一:数仓改造 Hive 探索
随着大数据体系的迭代我们开始构建以 Hive 为基础的实时经分大数据系统,同步探索数仓改造至 Hive 的可行性,但在转向 Hive 后我们遇到了以下问题:
-
采用 MR 执行,离线批处理效率低下,相比在商业化 MPP 数据库上生产完成时间滞后了4-5小时
-
缺少了关系型数据库的约束、严格的字段类型限制和 ACID 的语义以及第三方工具和平台的辅助,导致后续数据质量维护成本较高,数据质量不达标
基于以上因素,数仓暂停了改造 Hive 的过程,转回寻找更加物美价廉的商业化 MPP 产品了(主要从原 MPP 行式存储瓶颈着手,引入基于 x86 架构的列式存储 MPP 数据库)。已构建完成的大数据集群同步基于 Hive 探索承接部分时效性要求不高的数据应用任务。数据写入 Hive 流程如下:

这里导数工具主要由本地采集团队通过 java 开发,定期通过访问 Oracle 从库抽取生成格式化的文本文件后写入 Hive。从而完成业务数据到数仓数据的同步。该方式的一大基础是 Oracle 从库的读取性能保证并且不影响业务系统库的使用,但同时定期触发的方式也注定了 Hive 中的数据时效性是比较差的。
阶段二:业务系统上云引起后端数仓以及应用系统的架构调整
后续随着浙江电信开启系统上云任务,业务系统库逐步从 Oracle 转为 TeleDB (电信基于 MySQL 自研关系型数据库),传统的直接读业务库数据写入数仓体系的数据流转链路会对 TeleDB 业务库造成很大的压力。在这些问题的驱动下我们的数据链路也发生了变化。

在这里导数工具主要采用了两款产品,一款来自外部产品,其通过开源 Canal 技术进行封装,后因该产品只做了 TeleDB 的适配,不满足实际需求(生产后续引入了 TelePG(电信基于 postgresql 自研)数据库),后又引入了电信自研的跨 IDC 同步工具,开启了数仓 ODS 层从离线数据采集革新到实时数据采集,但经营分析大数据系统 Hive 数据时效性依然比较差。
阶段三:重新思考大数据的方向,构建湖仓一体集群
生产系统上云结束趋于稳定后,数仓和应用集市也开启了系统上云的步骤,我们重新思考大数据的定位和方向,将逐渐边缘化的大数据集群考虑重构以支撑浙江电信全部业务系统数据实时汇聚、整合和数仓的重建。将原本使用的 CDH 集群进行了升级改造至电信自研的大数据底座版本。同步需要为湖仓的底座选择可以支持数据实时写入和实时读取的一种 format。随着现在数据湖技术的逐步成熟,也在集团鼓励大数据团队拥抱开源的背景下我们调研发现了数据湖产品可以很好的解决数据实时写入读取的问题。
通过对比 Hudi,Delta lake 和 Iceberg 后我们认为 Iceberg 在很好的支持 CDC 数据写入的同时对流批引擎以及 MPP 数据库的支持更丰富,可以根据不同业务分析场景选择不同的引擎来满足性能方面的需求,并且网易数据开发治理平台 EasyData(以下简称网易 EasyData)和有数 BI 对 Iceberg 也有很好的支持。最终我们选择 Iceberg 作为我们新的 table format。
数据链路这里也经历了两个阶段:
-
阶段一:

Kafka 写入 Iceberg 主要通过了网易 EasyData 实时开发 FlinkSQL 模块。但随着原引入同步工具的保障性不足以及数据中台的引入,故而进行了数据链路的优化调整。
-
阶段二:

TeleDB 初期通过网易 EasyData 实时数据传输(基于 FlinkCDC)实时写入 Iceberg,随着上线任务量越来越大,发现了对电信自研数据库 TeleDB 和 TelePG 适配的不完备问题,后期因项目上线时间紧,我们团队开启了基于 FlinkCDC 能力自研数据入湖采集平台实现业务数据实时入湖,目前整体运行稳定,但资源优化和使用便捷性还需进一步开展研发。
业务实践
我们团队数据来源非常广泛,包括了浙江电信 BMO 域以及其他系统的业务数据。在数据落入 ODS 层后进行 DWD 和 DWS 加工,后根据不同的业务分析场景需求(实时和离线报表)在有数平台生成各式各样的报表,并且会将这些报表的内容嵌入到业务和分析人员日常使用的 Application 中供各运营节点使用。
报表的不同的使用场景决定了数据的响应速度,这也决定了我们需要使用不同的计算引擎。日常的自助分析我们通过 Spark 和 Trino 来支持对 Iceberg 报表的查询,数仓生产层批处理主要以离线为主,主要依赖 Spark,应用层对于响应速度要求较高的场景我们会采用 Doris 数据库(catalog 直接访问 Iceberg 表),来支撑各类场景的需求。

使用情况
在确定了 Iceberg 作为数仓系统的 table format 后我们已将大部分 ODS 转为 Iceberg,后续也会逐步将 DWD 和 DWS 转为 Iceberg。
目前 Iceberg 表存储总量1.1PB,预计所有数仓转型完毕后预计会有10-15PB。其中实时写入的 Iceberg CDC 表有近1万张,预计初步转变完成之后总共3-4万张 Iceberg 表。
03 Amoro 在浙江电信
为什么选择 Amoro
实时写入 Iceberg 表会产生大量小文件,尤其是为了保证数据的一致性,我们在很多场景中都开启了 upsert 模式(该模式下每次写入一条数据都会产生一条 insert 和一条 delete 数据),产生大量 equality-delete 文件,加剧了小文件的问题,也对查询性能产生了较大影响,甚至引起引擎端 OOM。因此,及时监控并合并小文件、减少 equality-delete 文件,对保障 Iceberg 表的可用性十分重要。
进行 Iceberg 的文件合并时,我们主要遇到以下难点:
- equality-delete 文件的合并效果不理想:我们使用了 Iceberg 社区提供的合并方式,周期性调度 Flink Spark 任务进行文件合并,这种通过重写进行文件合并的方式,开销比较大,几百 G 数据的合并每次需要消耗几小时甚至更久,而且合并完成后仍然可能出现 equality-delete 文件没有被立即删除的问题。
- 大量积压的 equality-delete 文件导致合并失败:一旦没有及时检测到表的文件情况,或因为合并失败导致 equality-delete 积压,文件合并的 plan、内存消耗、读写开销都很大,往往会因为 OOM、执行时间过久等问题,最终导致合并无法完成,只能重建表来恢复,大大增加了维护成本。
基于以上问题我们希望有一个成熟的系统可以帮助我们及时发现碎片文件多的表并且及时地去 optimize 这些表。通过调研我们发现 Amoro 可以很好的解决这个场景,并且 Amoro 提供了多种能力帮助我们更好的管理表的 optimizing:
-
Web UI 展示了关于表和 optimizing 的指标可以帮助我们更直观的观察到表的文件情况,写入频率以及 optimizing 的详情和运行情况
-
常驻的任务持续地自动化 optimize table
-
optimizer 资源灵活地扩缩容
-
通过 optimizer group 隔离表的 optimizing 资源
使用情况
我们在部署了 Amoro 后很快接入了所有 Iceberg 表,初期我们在部署调试阶段做了大量的测试和验证,同步优化 iceberg table 的建表方式(如分区的使用等),也非常感谢社区的大力支持。目前根据表的体量和业务我们一共切分了2个 optimizer group,总共资源使用78 core 776GB memory(相对更耗内存资源),已能稳定高效进行小文件管理和合并。
使用效果
Amoro 提供了高效稳定的合并
Amoro 提供了一种轻量的 Minor Optimizing 的方式,在合并小文件、避免重写大文件的同时,将 equality-delete 文件转化成查询性能更高的 pos-delete 文件。这种合并方式相比 Iceberg 社区的文件合并方式,开销更小,因此可以更加频繁地执行,执行周期在分钟级别,从而有效避免了小文件的积压。
使用 Amoro 前,CDC 高频写入的 Iceberg表 equality-delete 文件数量经常保持在1000以上,单个 datafile 关联的 equality-delete file 大小在5GB 以上。
使用 Amoro 后 Iceberg 表 equality-delete 和小文件数量保持在50以下。
Amoro 处理积压的 equality-delete 文件
我们为所有 Iceberg 的表都开起了 upsert 配置后带来的问题是 Iceberg 表中有大量的 equality-delete 文件,一旦出现 equality-delete 积压的情况,很容易导致合并任务的 OOM。这是因为,在 Iceberg plan task 机制中,datafile 会关联所有 sequence number 比自身大的 equality-delete file(file 的 sequence number 默认情况下与 snapshot 的 sequence number 相等,snapshot 的 sequence number 会自增)。所以对于历史快照提交的文件会引用很多的 equality-delete file,这些 equality-delete file 在 Iceberg MOR、以及文件合并时都需要被读取到内存中用于删除关联到的 datafile 中的数据,从而消耗大量内存。
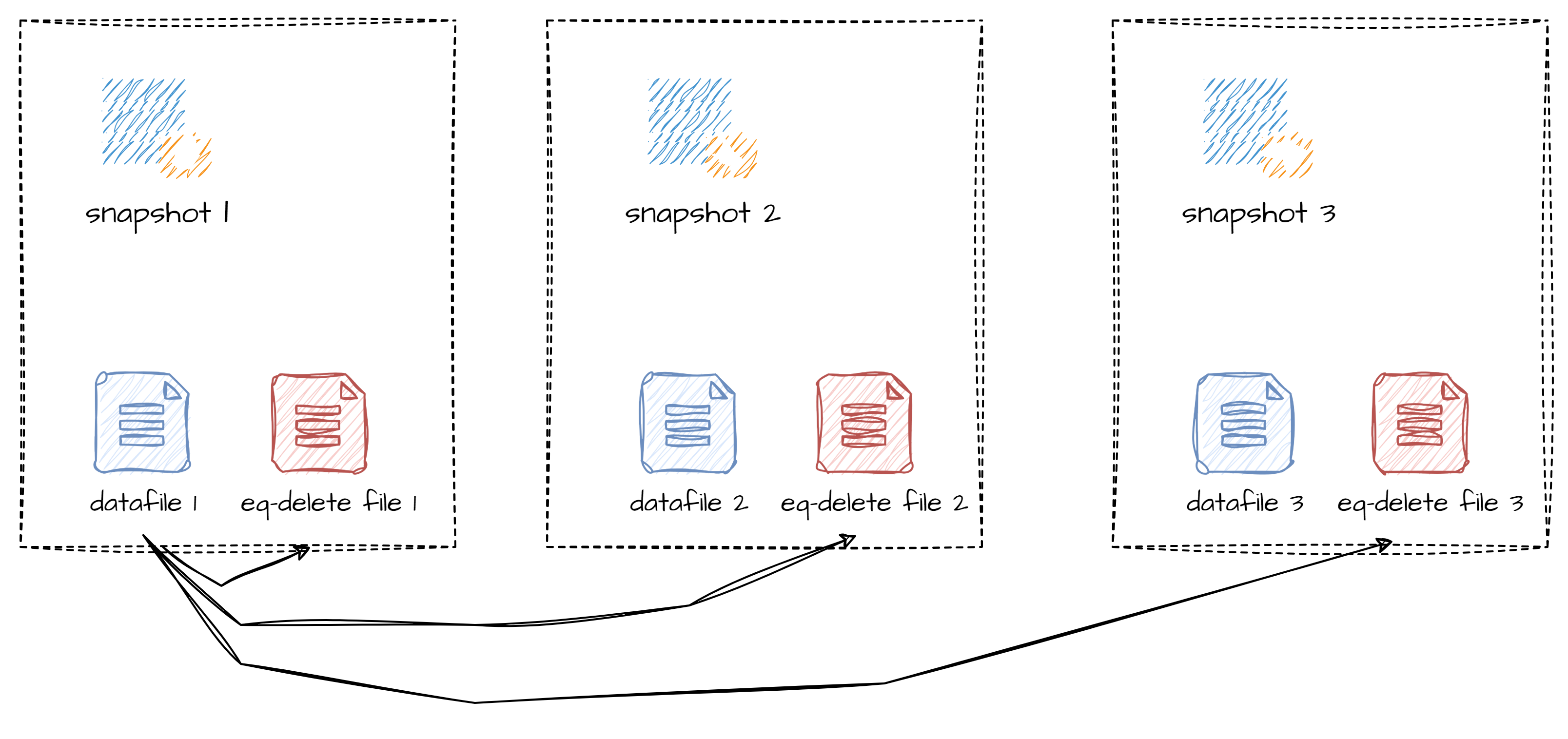
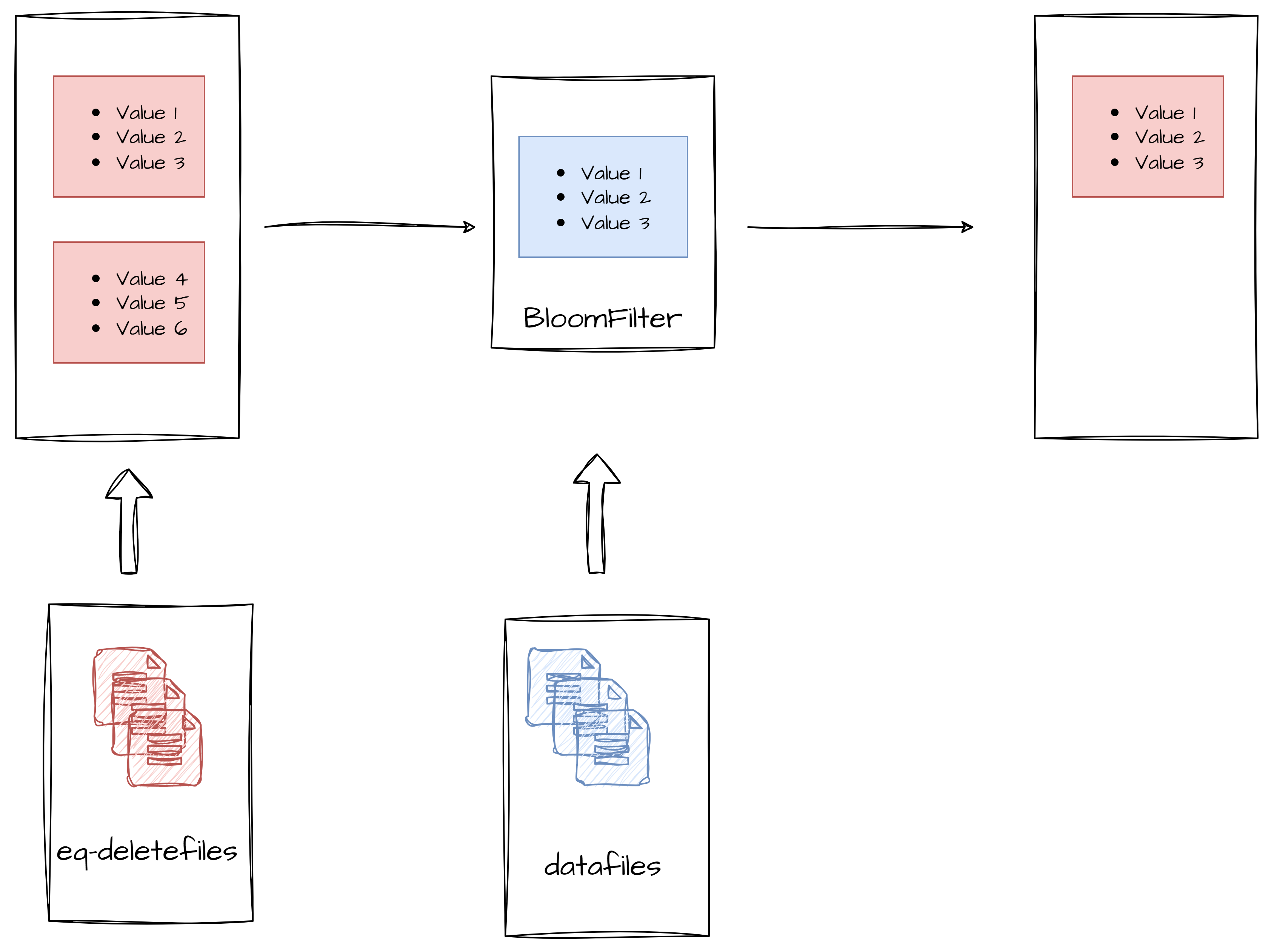
针对以上问题,Amoro 社区在 optimizing 方面做出了优化。在 upsert 场景中 datafile 关联到的 equality-delete file 中的数据很多是和当前 datafile 没有相关性的,所以其实读到内存中的 equality-delete 中有大量无效内容,但他们却占用了大量内存。另外 Amoro 在规划 self-optimizing task 时可以通过配置 self-optimizing.max-task-size-bytes 配置来限制每个 task 中 datafile 文件大小,所以每个 task 的 datafile 大小是可以预期的,但是 equality-delete file 大小是不可预期的。那么我们就可以使用 task 中 datafile 的内容来过滤掉不需要被缓存在内存中的 equality-delete records。
具体的实现方式是我们通过 task 中 datafile 的 equality field records 构建了一个 BloomFilter,通过这个 BloomFilter 筛选出与参与 self-optimizing datafile 相关联的众多 equality-delete 文件中 equality field data 与 datafile 有交叉的数据并加载到内存参与 MOR,显著的减少了内存的使用,从而避免了 upsert 场景 equality-delete file 文件较多时导致 optimizer OOM。
04 未来规划
-
未来我们会将当前 Iceberg 版本升级到电信自研 Iceberg 版本,首先会对 Flink 实时写入时的产生的文件数量做优化,减小 Amoro 在 self-optimizing 的压力,同步会积极同各方一道共建 Iceberg 开源社区
-
逐步将 DWD 和 DWS 层逐步从商业化 MPP 数据库转向基于 Iceberg 的湖仓一体集群
-
考虑到未来可能会有实时读取数据湖的需求,但是目前 Iceberg 还是不支持实时读取 V2表,所以我们也在调研和尝试使用 Amoro Mixed Iceberg 来解决实时读取数据湖的场景
最后再次感谢 Amoro 社区给予的大力支持,祝愿 Amoro 社区越来越好。
End~
如果你对数据湖,湖仓一体、table format 或 Amoro 社区感兴趣,欢迎联系我们深入交流。
关于 Amoro 的更多资讯可查看:
社群交流: 搜索kllnn999 , 添加芦田爱菜小助手微信加入社群

作者:喻志强
编辑:Viridian