摘要:本文整理自 SmartNews 数据平台架构师 Apache Iceberg Contributor 戢清雨,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为五个部分:
1. SmartNews 数据湖介绍
2. 基于 Icebergv1 格式的数据湖实践
3. 基于 Flink 实时更新的数据湖(Iceberg v2)解决方案
4. 实时更新小文件问题的优化
5. 总结与展望
Tips:点击「阅读原文」免费领取 5000CU*小时 Flink 云资源
01
SmartNews 数据湖介绍

2012 年,SmartNews 公司在日本东京成立。一直专注于 PGC 新闻,是一款在日本处于领先地位的新闻 APP。目前,服务的客户主要集中在日本、欧美等国家。SmartNews 公司在日本、美国和中国均设有办公室,在 2019 年入驻北京和上海。

SmartNews 数据湖主要存储所有广告数据,包括从服务器端收集到的点击/转化等事件信息,维表信息。其主要的广告信息都存储在 Kafka 上,服务器端在收集到事件后,会直接实时写入 Kafka。其他的维表信息,比如广告信息、统计信息等等,主要存储在 MySQL 或 Hive 中。这些信息一般以实时或小时级别更新。
数据湖的下游是业务端的 ETL 或实时报表数据,是下游数据的统一入口。因此,我们尽量把所有维度都放进来,做成一个大宽表,供下游实时查询使用。

接下来介绍下数据湖需要解决的技术挑战。
第一,按照广告主键去重。上游数据按照每条广告的事件,进行收集。比如一条广告的点击或者转化会生成多条记录,因此我们需要将这些事件打平。其次是上游的 Kafka 数据,可能包含了一定程度的重复数据。
第二,需要更新点击/转化时间戳字段。比如事件的时间戳,需要计算最新一次的时间,需要对数据湖执行更新操作。
第三,下游近实时读取。要求数据湖具有同时写入/读取的操作。而 Hive 在重写数据的过程中是会影响到下游正在发生的查询,这就要求我们需要一个新的解决方案。
02
基于 Icebergv1 格式的数据湖实践
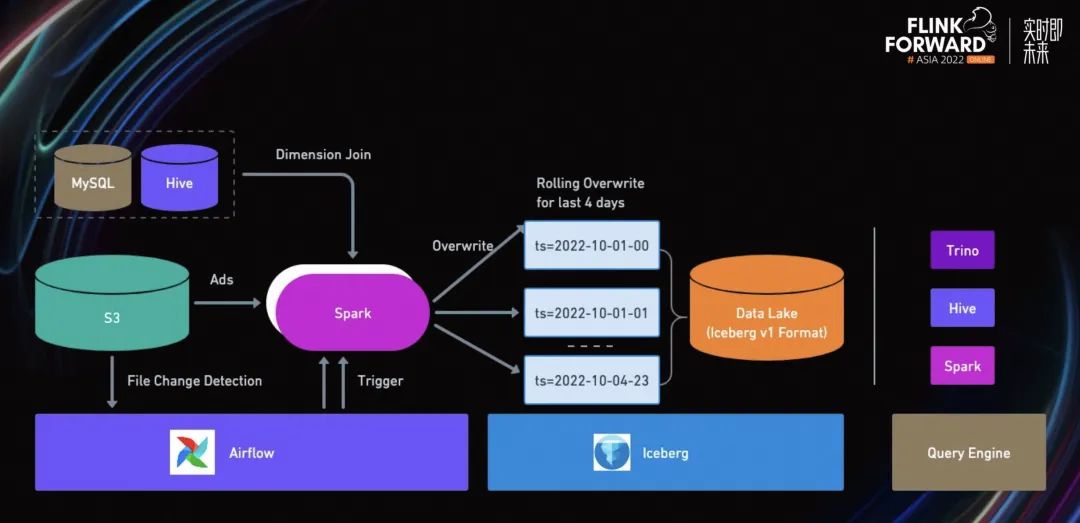
上图是我们第一个解决方案的整体架构。在这个解决方案中,我们采用了 Spark 计算引擎,把所有的广告事件按照主键进行打平并去重。然后,所有的维表进行查询 join。
除此之外,我们将数据源切换成 S3 文件,没有用流式数据源。其主要原因如下:
第一,这个方案是一个小时级别的解决方案,并不需要实时读取流式数据。
第二,我们在设计 Spark 任务时,会定义一个最小的执行单元。将目标数据源限制在某一天的某一时间。通过 S3 文件的分区信息,就可以直接进行读取。
第三,为了降低一定的容错概率。目前,我们的业务需要回滚过去四天的数据。比如有一个比较大的 Spark 任务需要重写,如果 Spark 任务失败,会导致整个任务失败。如果设计为最小执行单元,每个 Spark 任务只处理某个小时的数据,容错几率会大幅提升。
为了避免一些重复计算,我们也会去检测当前小时是否比上次 Spark 任务启动的时候有新添加文件,通过 airflow 来控制 Spark 任务的启动与重试。
每一个独立的 Spark 任务都会去尝试 overwrite 某一个小时的数据到 Iceberg 中。滚动刷新过去 4 天/96 个小时的数据 - 这也是这个解决方案的一个限制,其实际场景中这个刷新的窗口理论值是 30 天,但是考虑到成本等因素,这个方案只回刷过去 96 个小时。与此同时,下游也会通过一些查询引擎来对这个数据湖数据进行实时查询。

在这个解决方案中,解决了之前我们提到的一些挑战。比如在 Spark 作业中,按照主键进行去重,并且更新相应的时间戳。通过 Iceberg 解决方案,不但隔离上下游的读写,而且提供了小时级别的更新。

但这个方案也有很多不足。比如占用 Infra 资源太多,计算资源的浪费。通过计算发现,需要更新的行只占总体的 1%~2%左右。除此之外,还有存储资源浪费的问题。Spark 每次从 overwrite 提交到 Iceberg 的过程中,都需要重写整个数据。关于并行提交到 Iceberg 的锁问题,每个最小的 Spark 执行单元,会同时执行提交 Iceberg 操作。在向 Iceberg 提交的过程中,会先从 Hive 里拿一个锁,导致大家对锁存在竞争,造成了资源的浪费。
03
基于 Flink 实时更新的数据湖
(Iceberg v2)解决方案

我们经过充分的调研之后,决定采用 Flink+Iceberg V2 的方式,进行实时更新。这个解决方案利用了 Iceberg V2 支持行级别更新,其次是 Flink 的实时写入。因为 Flink 在写入 Iceberg 的过程中,使用了 Merge On Read。所以 Flink 只会写入需要更新的数据。
由于我们只有 1%的数据量需要更新,所以 Merge On Read 模式非常适合当前的业务场景。
除此之外,我们希望通过 MySQL CDC 的流式解决方案,解决 dimension join 维表查询,可以更快、更准确的将维表信息写入数据库。
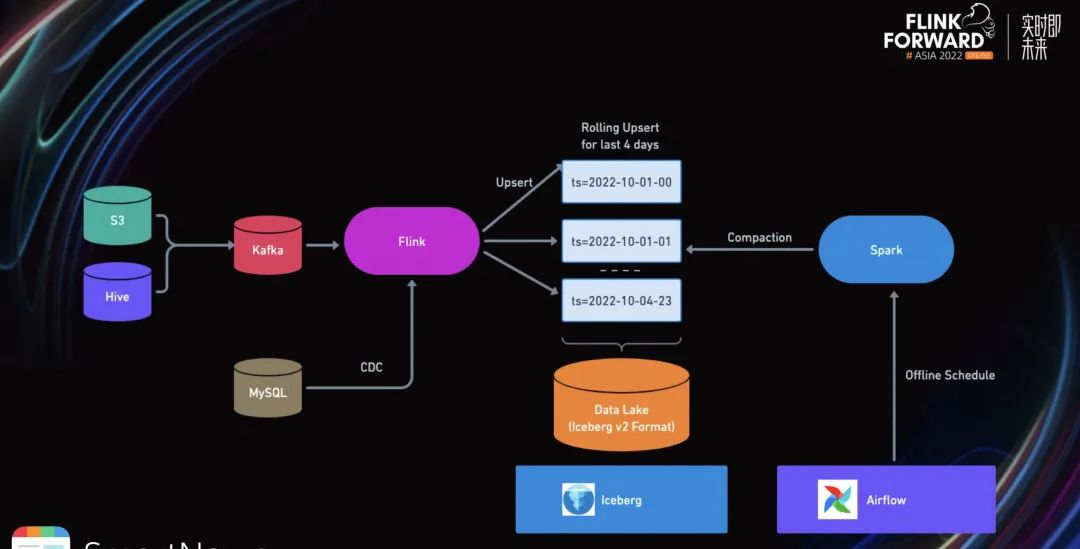
在这个新的解决方案中,我们将上游的数据源都流式化,发送到 Kafka 中。与此同时,将 MySQL 的维表信息通过 CDC 的方式,输入到 Flink 任务里。Flink 再将这些维表信息通过 broadcast 到 State 中,供下游查询。
Flink 在通过 Iceberg Sink 的 Upsert Mode 来将数据实时写入到数据湖中。offline 的话,我们再通过 airflow 来定时启动一些 Spark 任务来做数据文件的合并,主要是为了解决小文件的问题,我们在后面的章节也会有详细介绍。
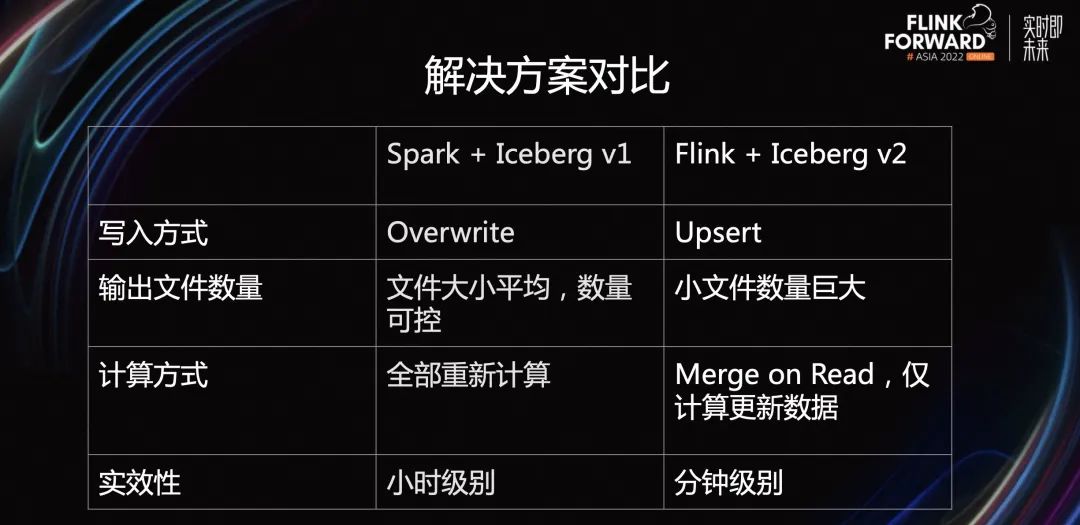
对比上述两种不同的解决方案,可以看出以下区别。首先,Spark + Iceberg v1 的写入方式是 overwrite。每次会将所有的数据集重新计算,然后重新放到数据湖中。Flink + Iceberg v2 的写入方式是 Upsert,只是将更新的数据写入到数据湖中。
从输出文件数量的角度来讲,Spark + Iceberg v1 的文件大小可控,数量可控。因为每次输入的都是这个小时的全量数据,可以按照需求来控制文件大小,控制文件数量。Flink + Iceberg v2 会产生大量的小文件,带来巨大的挑战。
从计算方式的角度来讲,Spark 需要全部重新计算。Flink + Iceberg v2 仅需要计算更新的数据。
从时效性的角度来讲,Spark + Iceberg v1 提供的是小时级别的解决方案。Flink + Iceberg v2 提供的是分钟级别的解决方案,给下游查询 ETL 带来了极大优势。
04
实时更新小文件问题的优化

刚才提到的实时小文件问题,会在很大程度上影响下游查询任务的性能。接下来,着重介绍一下我们如何解决小文件问题的。首先,介绍一下 Iceberg Sink 的写入模式。由于存在更新数据的情况,所以选择使用 Upsert Mode。
在每次写入数据的过程中,会生成两条 Record 数据,即 Delete 和 Insert。在一定程度上,这种方式造成了存储空间的浪费。下游 Writer 算子会有 CPU 压力,它需要处理的数据量更多,需要写入的数据更多。
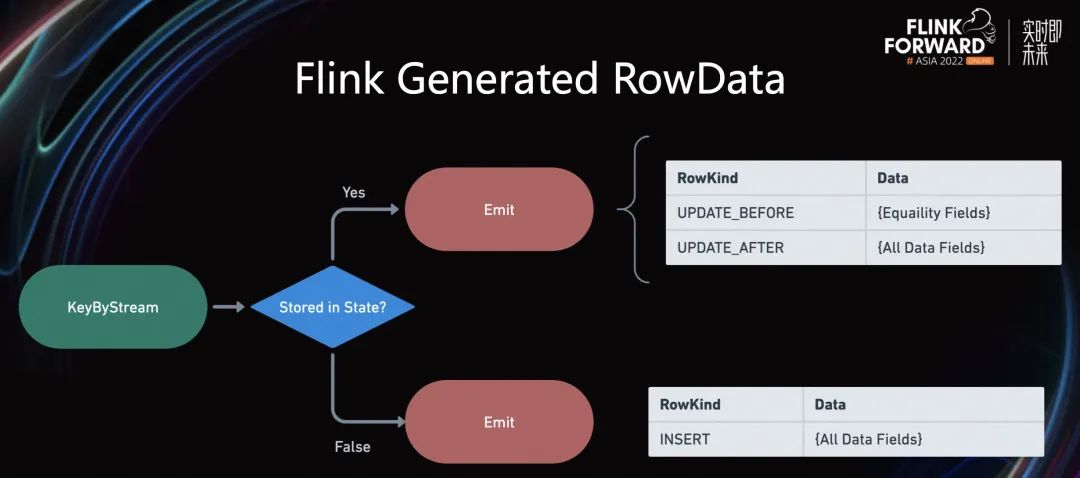
通过引入 Flink State 的方式,在一定程度上解决了 Upsert 写入多行的问题。首先,按照广告主键进行 KeyBy Stream。如果当前主键不在 Flink State 中,这条数据是第一次写入,会向下游输出一条 RowKind INSERT 数据,表明这是一条全新的数据。
如果该数据主键已经存在于 Flink State 中,会向下游输出两条记录。一条是 UPDATE_BEFORE,另一条是 UPDATE_AFTER。在这一环节,会更加详细的检查是否需要输出,比如是否有时间戳的更新,是否有维表信息更新等等。
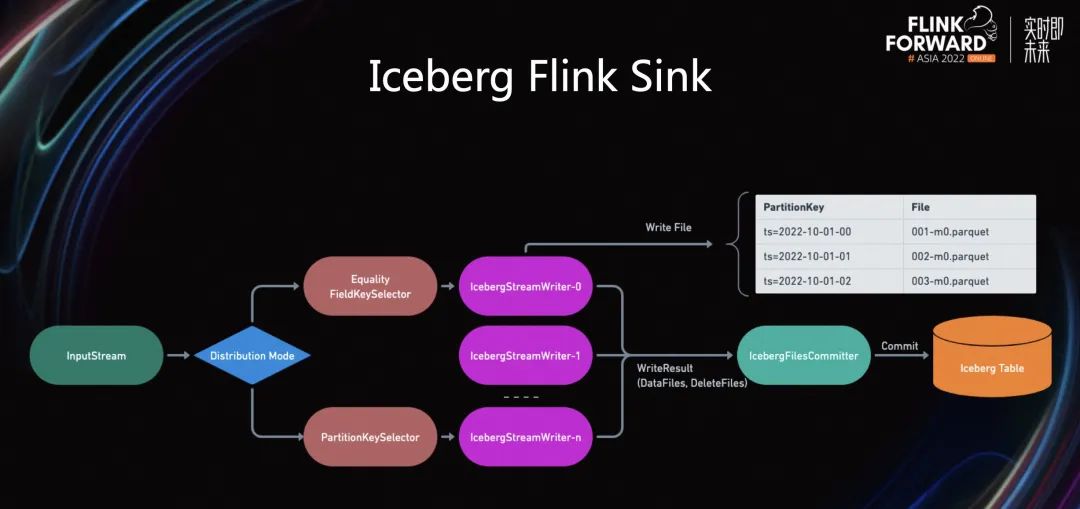
通过这些操作,可以在一定程度上,减少一部分的小文件。但在实际情况下,我们发现该方法仍有不足,依然会有很多的小文件生成。基于 Iceberg Flink Sink 原理,大量的小文件通过 IcebergStreamWriter 生成的。
Iceberg 支持两种不同的 Distribution 模式,将数据从上游的 input stream,传输到下游的 Writer 算子中。第一种是 Equality Field KeySelector,即将RowData的equality filed 进行 hash。第二种是 PartitionKeySelector,即将 RowData 的 parition field 进行 hash。
这两种方式有什么区别呢?Equality Field KeySelector 从语义上可以理解为将 RowData 以主键 hash 的方式传输到下游,这样可以最大化使用下游 Writer 算子的写出速度。而 partitionKeySelector,可以将具有相同 Parition 的 RowData 输出到同一个 Writer,确保同一个 Partition 的数据都是通过同一个 Writer 写出。
StreamWriter 负责将所有收到的数据输出到 DFS,比如 S3上,这里会根据表上是否带有 Partition 信息来区分到底是输出到同一个文件还是多个文件。
在我们这个用例中,数据湖是按照 Partition 来进行物理分区,即同一个小时的数据只会存在同一个路径下面,而同一个数据文件不能包含多个 Partition 的数据。下游的 Writer 在收到数据以后,就会按照 Partition 的信息来写出文件。
所有的 Writer 在 Checkpoint 阶段会将写出去的文件统计信息发送到最后的 Committer 算子。Commit 算子再将所有的修改提交到 Iceberg 中。

Equality Field KeySelector 是按照 Record 主键,Shuffle 到下游 Writer 中。
在同一个 Partition 路径下面,会有多个 Writer 同时写入。主要原因就是下游 Writer 接收到的 RowData 是按照主键来进行 hash Shuffle 的,所以每个 Writer 算子都有可能接收到同一个 Partition 下的数据。

假设 Checkpoint 的间隔为 20 分钟,使用 10 个 Writer 去写文件。理论上,每个小时可以写出 90 个小文件,是非常的典型的长尾型数据分布。由此可见,越靠近当前小时,需要处理的数据量越大的。如果距离当前小时越远,需要处理的数量非常小。对于这些 Partition 来说,它们需要生成的文件数量基本恒定。

PartitionKeySelector 按照 Record 的 Partition 信息,Shuffle 到下游 Writer。在同一个 Partition 路径下,只有 1 个 Writer 写入。
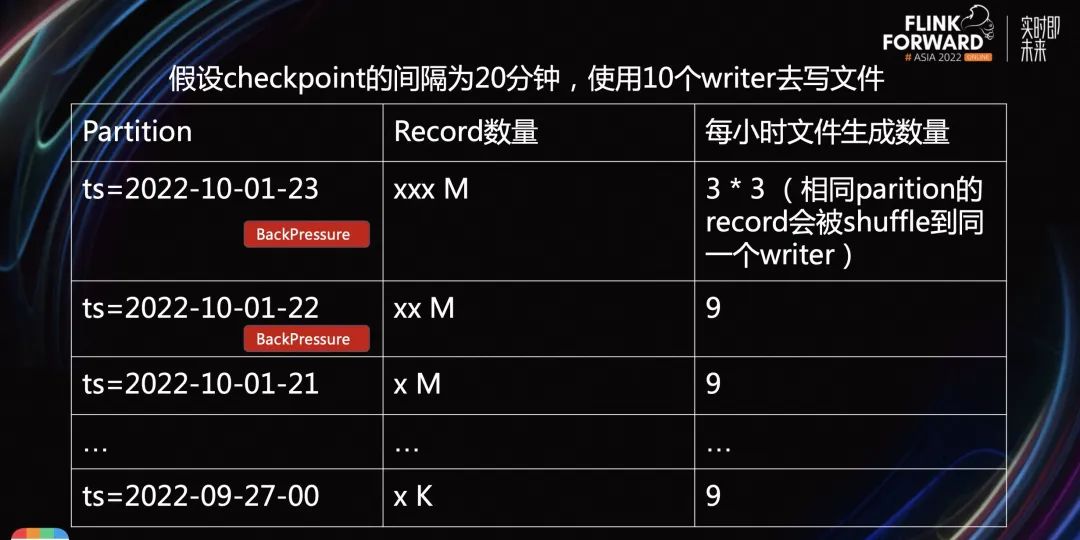
假设 Checkpoint 的间隔为 20 分钟,使用 1 个 Writer 去写文件。越靠近最新时间,它的反压越严重,导致整个 Flink 作业延迟。因为越是靠近当前小时,需要处理的数量级越大。越远离当前小时,需要处理的数据量是越小。
Equality Field KeySelector 的优势是高效,但问题在于小文件特别多。尤其在长尾末端,平均都是几十 kb 的小文件。PartitionKeySelector 的优势在于,小文件数量少,对于数据量较大的 Partition,会造成很大的反压。
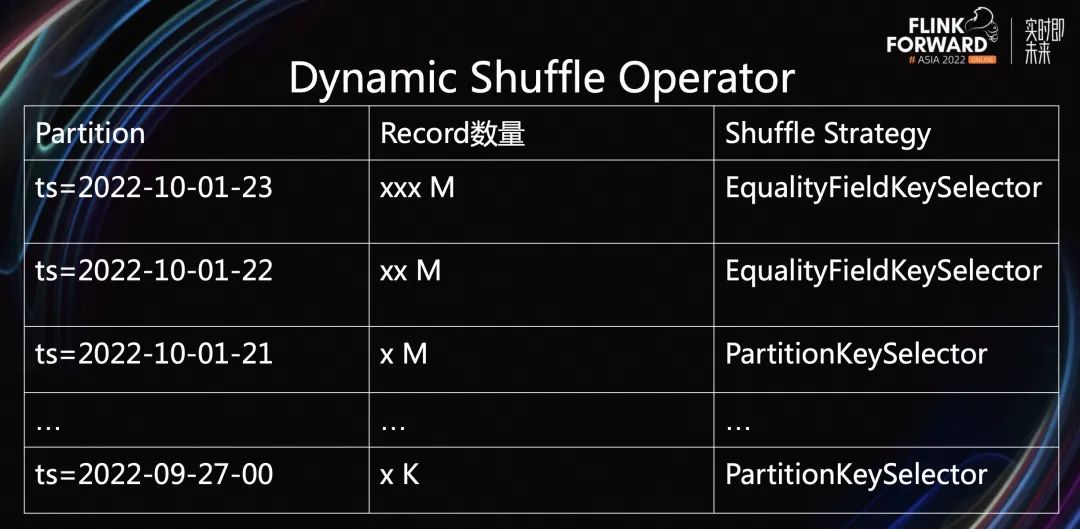
为了解决上述问题,我们引入了 Dynamic Shuffle Operator 算子。它可以按照不同的 Partition,选择不同的 KeySelector。
比如最近的 Partition 数据量特别大,Dynamic Shuffle Operator 会选择使用 Equality Field KeySelector。面对长尾的 Partition,Dynamic Shuffle Operator 会选择 PartitionKeySelector。该方案既保证了大批量的 Partition 数据,可以及时输出到文件中,也减少了在长尾末端生成的小文件。
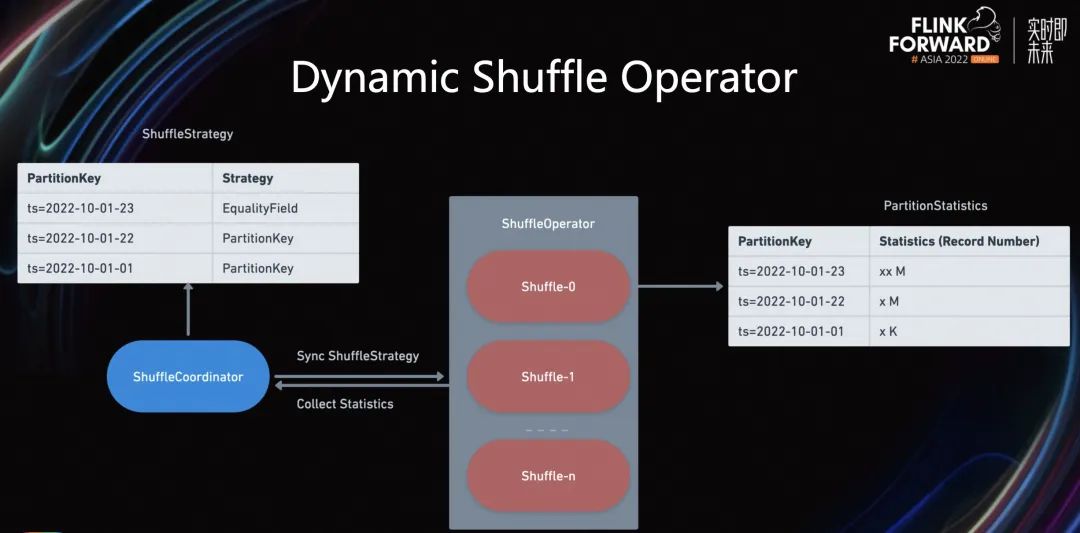
在这个解决方案中,通过引入 Dynamic Shuffle Operator,在数据输入到 Writer 前,先通过 Dynamic Shuffle Operator 进行一次物理 Partition,即物理分区。
而 Partition 策略会按照 Shuffle Operator 过去处理的统计信息,进行动态编排。如上图所示,首先通过引入 Shuffle Coordinator 解决不同 Shuffle Subtask 之间的信息通信问题。
其次我们需要确保的是不同的 Subtask 在输出文件的时候按照同一个ShuffleStrategy 来进行输出,因为 Iceberg 在处理 Delete 文件时,需要同一个主键的 RowData 在相同的 Writer 输出,比如我们现有一条 insert,再来一条 Update,如果这两个 RowData 是按照不同的 ShuffleStrategy 来进行 Shuffle,很有可能这两个数据会 Shuffle 到不同的 Writer 算子,这样会导致重复数据的产生。
除此之外,Shuffle Operator 负责将已经处理的统计信息发送给 Coordinator。比如各个 Partition 处理的数据量。
其目的是,Coordinator 在收集到 Shuffle Operator 的统计信息之后,可以按照历史信息动态的判断出,最新的 Partition 需要什么样的 Strategy。比如当最新的 Partition 已经写出了 70%的数据时,Coordinator 可以让 Shuffle Operator 切换到 PartitionKey,从而减少小文件的数量生成。

综上所述,Dynamic Shuffle KeySelector 按照当前最大 PartitionKey 来分配 ShuffleStrategy;按照历史数据信息来动态分配 Shuffle Strategy,最终确保所有 Subtask 都使用相同的 Shuffle Strategy。

接下来,介绍一下相关的实验对比。我们对比了 24 小时以内,每小时文件生成的数量以及平均大小。我们将 Flink 并发设置为 20。
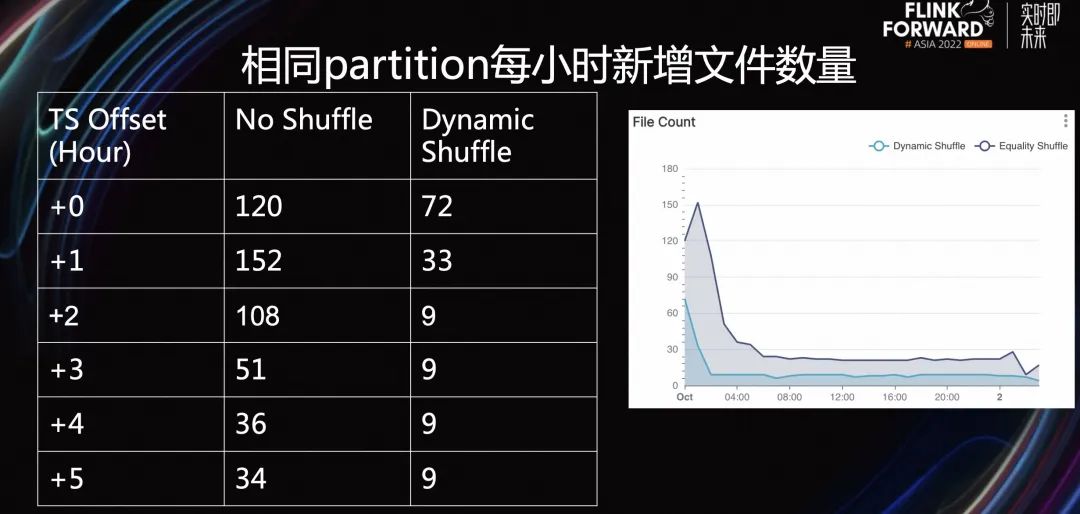
如上表所示,首先我们比较相同 Partition 每小时新增文件数量,+1 表示比最新的小时晚一个小时。No Shuffle 表示是用 Iceberg 的默认 Shuffle,即 EqualityFieldKeyBy。Dynamicshuffle 是新的 Shuffle Strategy。
可以看到不仅在最新的几个 Partition 中,Dynamic Shuffle 写出了更少的文件数量,而且在长尾的 Partition 也有更好的效果。
一般来说 当过了 1 个小时候之后,Dynamic Shuffle Operator 就会将该 Partition 的 Strategy 切换为 Partitionkeyby,因此当前小时的文件增长速率就是基本恒定的。
右侧的图也可以在反应这个长尾的现象:可以看出文件生成的高峰一般都是在第一个小时,而后续长尾小时基本是固定的。
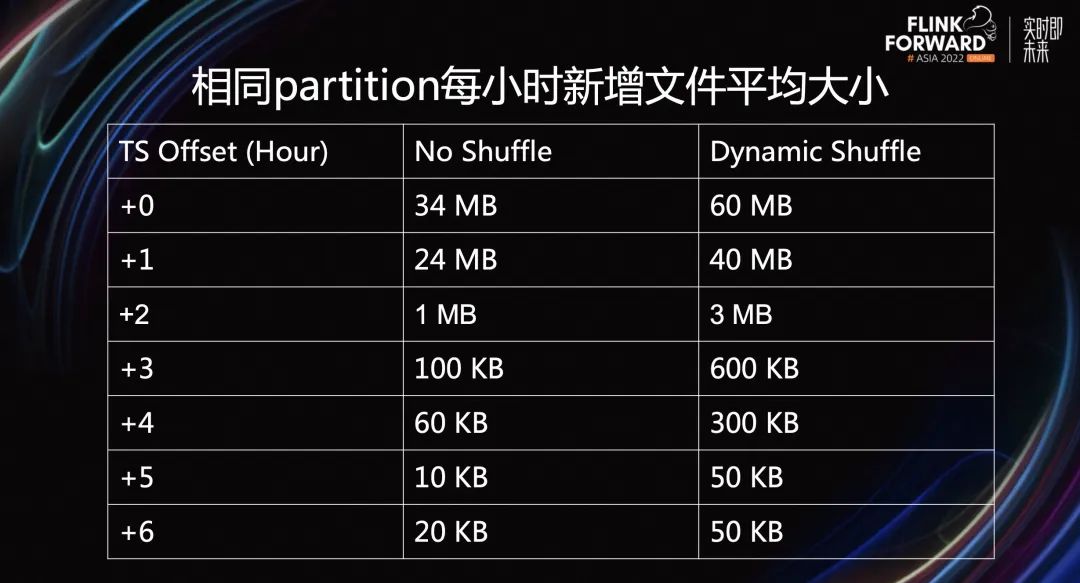
对于文件的平均大小,Dynamic Shuffle Operator 也有更好的表现。由于这里采取的指标是平均文件大小,而一次 Writer 的写入可能会有很大的 Data 文件,但 Delete 文件通常较小。因为只包含了部分主键或者位置信息。最近小时的平均大小效果比较显著。
05
总结与展望

Flink Forward Asia 2023 正式启动

▼ 「活动推荐」首购 99 元包月试用 ▼

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源
点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源