Iceberg从入门到精通系列之十七:Apache InLong往Iceberg同步数据
一、概览
- Apache Iceberg是一种用于大型分析表的高性能格式。
二、版本支持
| 提取节点 | 版本 |
|---|---|
| Iceberg | Iceberg:0.12.x,0.13.x |
三、依赖项
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-iceberg</artifactId>
<version>1.7.0</version>
</dependency>
四、SQL API 用法
在 flink 中创建Iceberg表,我们推荐使用Flink SQL Client,因为它更便于用户理解概念。
Step.1 在hadoop环境下启动一个独立的flink集群。
# HADOOP_HOME is your hadoop root directory after unpack the binary package.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
# Start the flink standalone cluster
./bin/start-cluster.sh
Step.2 启动flink SQL客户端。
flink-runtime在 iceberg 项目中创建了一个单独的模块来生成一个捆绑的 jar,可以直接由 flink SQL 客户端加载。
如果想要flink-runtime手动构建捆绑的 jar,只需构建inlong项目,它将在<inlong-root-dir>/inlong-sort/sort-connectors/iceberg/target。
默认情况下,iceberg 包含用于 hadoop 目录的 hadoop jars。如果我们要使用 hive 目录,我们需要在打开 flink sql 客户端时加载 hive jars。幸运的是,apache inlong将 一个捆绑的hive jar打包进入Iceberg。所以我们可以如下打开sql客户端:
# HADOOP_HOME is your hadoop root directory after unpack the binary package.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
./bin/sql-client.sh embedded -j <flink-runtime-directory>/iceberg-flink-runtime-xxx.jar shell
Step.3 在当前 Flink 目录中创建表
默认情况下,我们不需要创建目录,只需使用内存目录即可。在目录中如果catalog-database.catalog-table不存在,会自动创建。这里我们只是加载数据。
在 Hive 目录中管理的表
下面的 SQL 会在当前 Flink 目录中创建一个 Flink 表,映射到 iceberg 目录中default_database.iceberg_table管理的 iceberg 表。由于目录类型默认是 hive,所以这里不需要放catalog-type.
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hive_prod',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
如果要创建 Flink 表映射到 Hive 目录中管理的不同Iceberg表(例如hive_db.hive_iceberg_table在 Hive 中),则可以创建 Flink 表,如下所示:
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hive_prod',
'catalog-database'='hive_db',
'catalog-table'='hive_iceberg_table',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
将记录写入 Flink 表时,如果底层目录数据库(hive_db上例中)不存在,则会自动创建它。
在 hadoop 目录中管理的表
以下 SQL 将在当前 Flink 目录中创建一个 Flink 表,该表映射到default_database.flink_tablehadoop 目录中管理Iceberg表。
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hadoop_prod',
'catalog-type'='hadoop',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
Step.6 向Iceberg表中插入数据
INSERT INTO `flink_table`
SELECT
`id` AS `id`,
`d` AS `name`
FROM `source_table`
在自定义Catalog中管理的表
以下 SQL 将在当前 Flink 目录中创建一个 Flink 表,该表映射到default_database.flink_table自定义目录中管理的Iceberg表。
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='custom_prod',
'catalog-type'='custom',
'catalog-impl'='com.my.custom.CatalogImpl',
-- More table properties for the customized catalog
'my-additional-catalog-config'='my-value',
...
);
五、多表写入
目前 Iceberg 支持多表同时写入,需要在 FLINK SQL 的建表参数上添加 ‘sink.multiple.enable’ = ‘true’ 并且目标表的schema 只能定义成 BYTES 或者 STRING ,以下是一个建表语句举例:
CREATE TABLE `table_2`(
`data` STRING)
WITH (
'connector'='iceberg-inlong',
'catalog-name'='hive_prod',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://localhost:8020/hive/warehouse',
'sink.multiple.enable' = 'true',
'sink.multiple.format' = 'canal-json',
'sink.multiple.add-column.policy' = 'TRY_IT_BEST',
'sink.multiple.database-pattern' = '${database}',
'sink.multiple.table-pattern' = 'test_${table}'
);
要支持多表写入同时需要设置上游数据的序列化格式(通过选项 ‘sink.multiple.format’ 来设置, 目前仅支持 [canal-json|debezium-json])。
六、动态表名映射
Iceberg 在多表写入的时可以自定义映射的数据库名和表名的规则,可以填充占位符然后添加前后缀来修改映射的目标表名称。 Iceberg Load Node 会解析 ‘sink.multiple.database-pattern’ 作为目的端的 数据库名, 解析 ‘sink.multiple.table-pattern’ 作为目的端的表名,占位符是从数据中解析出来的,变量是严格通过 ‘${VARIABLE_NAME}’ 来表示, 变量的取值来自于数据本身, 即可以是通过 ‘sink.multiple.format’ 指定的某种 Format 的元数据字段, 也可以是数据中的物理字段。 关于 ‘topic-parttern’ 的例子如下:
- ‘sink.multiple.format’ 为 ‘canal-json’:
- ‘topic-pattern’ 为 ‘{database}_${table}’, 提取后的 Topic 为 ‘inventory_products’ (‘database’, ‘table’ 为元数据字段, ‘id’ 为物理字段)
- ‘topic-pattern’ 为 ‘{database} t a b l e {table} table{id}’, 提取后的 Topic 为 ‘inventory_products_111’ (‘database’, ‘table’ 为元数据字段, ‘id’ 为物理字段)
七、动态建库、建表
Iceberg在多表写入时遇到不存在的表和不存在的库时会自动创建数据库和数据表,并且支持在运行过程中新增捕获额外的表入库。 默认的Iceberg表参数为:‘format-version’ = ‘2’、‘write.upsert.enabled’ = ‘true’'、‘engine.hive.enabled’ = ‘true’
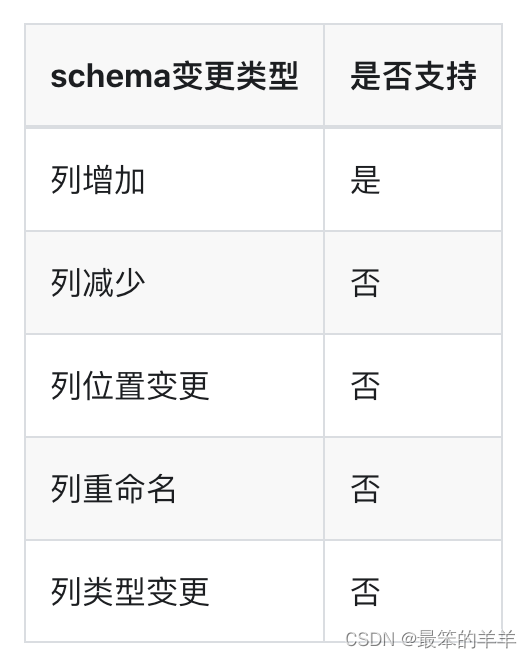
八、动态schema变更
Iceberg在多表写入时支持同步源表结构变更到目标表(DDL同步),支持的schema变更如下:
九、Iceberg Load 节点参数
| 选项 | 是否必须 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| connector | 必需 | (none) | String | 指定要使用的连接器,应该是’iceberg’ |
| catalog-type | 必需 | hive | String | hive或hadoop用于内置目录,或为使用catalog-impl的自定义目录实现未设置 |
| catalog-name | 必需 | (none) | String | 目录名称 |
| catalog-database | 必需 | (none) | String | 目录名称 |
| catalog-table | 必需 | (none) | String | 在Iceberg目录中管理的数据库名称 |
| catalog-impl | 自定义custom可选 | (none) | String | 如果未设置,则必须设置完全限定的类名自定义目录实现catalog-type |
| cache-enabled | 可选 | true | Boolean | 是否启用目录缓存,默认值为true |
| uri | hive catalog可选 | (none) | String | Hive元存储的thrift URI |
| clients | hive catalog可选 | 2 | Integer | Hive Metastore客户端池大小,默认值为2 |
| warehouse | hive catalog或hadoop catalog可选 | (none) | String | 对于Hive目录,是Hive仓库位置,如果既不设置hive-conf-dir指定包含hive-site.xml配置文件的位置也不添加正确hive-site.xml的类路径,用户应指定此路径。对于hadoop目录,HDFS目录存放元数据文件和数据文件 |
| hive-conf-dir | hive catalog可选 | (none) | String | hive-site.xml包含将用于提供自定义 Hive 配置值的配置文件的目录的路径。如果同时设置和创建Iceberg目录时,hive.metastore.warehouse.dirfrom <hive-conf-dir>/hive-site.xml(或来自类路径的 hive 配置文件)的值将被该值覆盖。warehousehive-conf-dirwarehouse |
| inlong.metric.labels | 可选 | (none) | String | inlong metric 的标签值,该值的构成为groupId={groupId}&streamId={streamId}&nodeId={nodeId}。 |
| sink.multiple.enable | 可选 | false | Boolean | 是否开启多路写入 |
| sink.multiple.schema-update.policy | 可选 | TRY_IT_BEST | Enum | 遇到数据中schema和目标表不一致时的处理策略TRY_IT_BEST:尽力而为,尽可能处理,处理不了的则忽略IGNORE_WITH_LOG:忽略并且记录日志,后续该表数据不再处理THROW_WITH_STOP:抛异常并且停止任务,直到用户手动处理schema不一致的情况 |
| sink.multiple.pk-auto-generated | 可选 | false | Boolean | 是否自动生成主键,对于多路写入自动建表时当源表无主键时是否将所有字段当作主键 |
| sink.multiple.typemap-compatible-with-spark | 可选 | false | Boolean | 是否适配spark的类型系统,对于多路写入自动建表时是否需要适配spark的类型系统 |
十、数据类型映射
Iceberg数据类型详细信息。这里介绍了加载数据如何将 Iceberg 类型转换为 Flink 类型。
| Flink SQL类型 | Iceberg类型 |
|---|---|
| CHAR | STRING |
| VARCHAR | STRING |
| STRING | STRING |
| BOOLEAN | BOOLEAN |
| BINARY | FIXED(L) |
| VARBINARY | BINARY |
| DECIMAL | DECIMAL(P,S) |
| TINYINT | INT |
| SMALLINT | INT |
| INTEGER | INT |
| BIGINT | LONG |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| DATE | DATE |
| TIME | TIME |
| TIMESTAMP | TIMESTAMP |
| TIMESTAMP_LTZ | TIMESTAMPTZ |
| INTERVAL | - |
| ARRAY | LIST |
| MULTISET | MAP |
| MAP | MAP |
| ROW | STRUCT |
| RAW | - |