参考文献:《DUAL-PATH RNN: EFFICIENT LONG SEQUENCE MODELING FOR TIME-DOMAIN SINGLE-CHANNEL SPEECH SEPARATION》
DPRNN网络是Con-Tasnet的改进网络
Con-Tasnet介绍详情请看上一篇文章
单通道说话人语音分离——Conv-TasNet(Convolutional Time-domain audio separation Network)
1.背景
近年来,基于深度学习的语音分离的研究证明了时域方法优于传统的基于时频的方法。与时频域方法不同,时域分离系统通常接收由大量时间步长组成的输入序列,这给极长序列的建模带来了挑战。传统的递归神经网络(RNNs)由于优化困难,对如此长的序列建模无效,而一维卷积神经网络(一维CNNs)在其接受域小于序列长度时,无法进行话语级序列建模。
这里提出了双路径递归神经网络(DPRNN),这是一种简单而有效的方法,将RNN层组织成一个深度结构来建模极长的序列。DPRNN将长序列的输入分割成更小的块,并迭代地应用块内和块间的操作,其中输入长度可以与每个操作中原始序列长度的平方根成正比。实验表明,通过用DPRNN替换一维CNN,并在时域音频分离网络(TasNet)中应用样本级建模,WSJ0-2混合模型的性能比之前的最佳系统小20倍。
2.DPRNN模型介绍
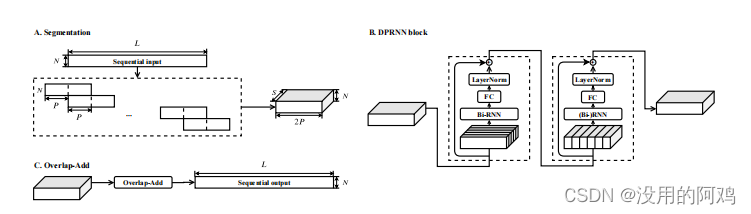
如上图所示,这是双路RNN系统流程图(DPRNN)。
(A)分割阶段将一个连续输入的部分分割成有或没有重叠的块,并将它们连接起来形成一个三维张量。在我们的实现中,重叠比被设置为50%。
(B)每个DPRNN块由两个在不同维度上具有循环连接的rnn组成。块内双向RNN首先并行应用于单个块,以处理局部信息。然后跨块应用块间RNN以捕获全局依赖关系。可以堆叠多个块,以增加网络的总深度。
(C)通过对最后一个DPRNN块执行重叠添加,该块的三维输出被转换为顺序输出。
双路径RNN(DPRNN)包括分割、块处理和重叠添加三个阶段。分割阶段将一个顺序的输入分割成重叠的块,并将所有的块连接成一个三维张量。然后将张量传递给堆叠的DPRNN块,以另一种方式迭代地应用局部(块内)和全局(块间)建模。最后一层的输出通过重叠添加方法转换回顺序输出。
训练目标
训练端到端系统的目标是最大化尺度不变的源噪比(SI-SNR),这通常被用作源分离的评估度量,取代标准的源失真比(SDR)
数据集
华尔街日报的说话人数据集
3.实验结果
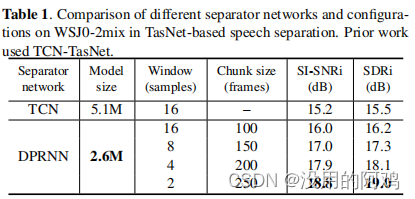
DPRNN 模型不同设置下的性能对比
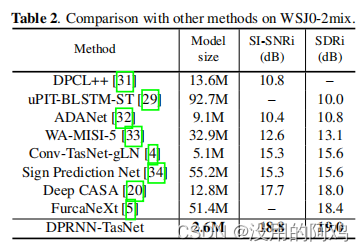
与以往的模型的性能对比
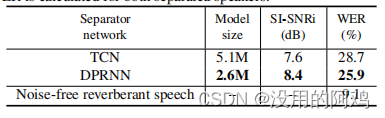
分离后语音识别任务性能的对比
4.展望
说话人分离目前是热门方向,特别是在会议系统里面有很多的应用场景。
这个模型还是比较好用的,很多地方都能用,关键看怎么用