开头话也不太会说,今天上机课正好写了非递归遍历的代码,于是就写写博客发出来了。
在讲解之前需要先说一下为什么要把好好的递归函数改写为非递归函数,原因如下:
- 递归会占用系统堆栈,当递归深度过深会导致栈溢出。
- 迭代的效率远比递归高,从汇编的角度来看,迭代需要做的只是更新变量和条件跳转,而递归则需要在递归调用时保存现场(中断),时间和空间开销相对迭代是非常大的。
下面先来复习一下后序遍历,后续遍历的顺序是左—右—根,下图一颗二叉树(好了,我知道画的不好看,别吐槽)
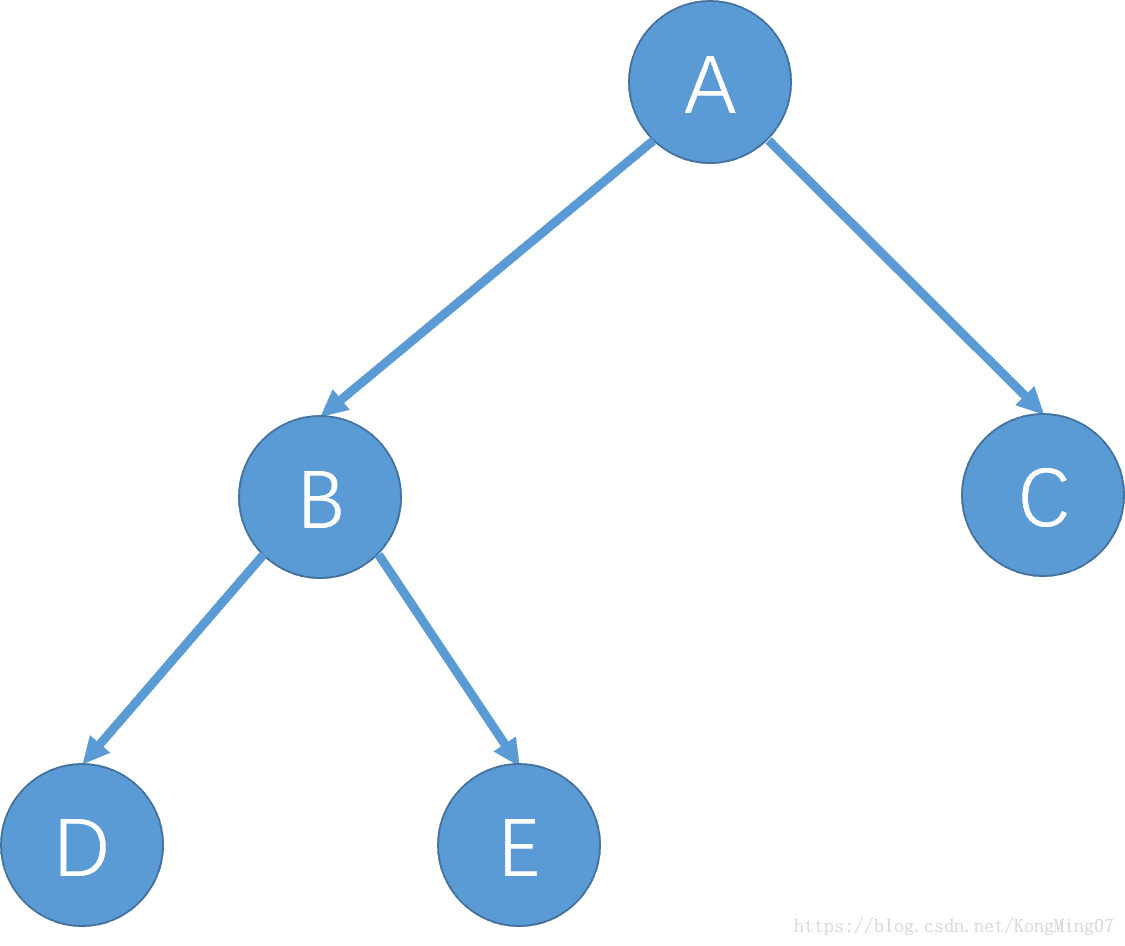
这棵树的后序遍历得到的序列是DFBCA。
先还原一下递归函数遍历时的过程:
- 将A节点入栈,进入A的左子树B节点。
- 将B节点入栈,进入B的左子树D节点。
- 将D节点入栈,进入D的左子树(空树)。
- 发现D节点不存在左子树,取栈顶元素D节点,回到D节点。
- 进入D节点的右子树(空树)
- 发现D节点不存在右子树,栈顶元素D节点出栈,回到D节点,输出D节点内容。
- 取栈顶元素B节点,回到B节点。
- 进入B节点的右子树E节点。
- 将E节点入栈,进入E的左子树(空树)。
- 发现E不存在左子树,取栈顶元素E节点,回到E节点。
- 进入E的右子树(空树)。
- 发现E不存在右子树,栈顶E节点出栈,回到E节点。输出E节点内容。
- 栈顶元素B节点出栈,回到B节点。输出B节点内容。
- 取栈顶A节点,回到A节点。
- 进入A节点的右子树C节点。
- 将C节点入栈,进入C节点的左子树(空树)。
- 发现C节点不存在左子树,取栈顶元素C节点,回到C节点。
- 进入C节点的右子树(空树)。
- 发现C节点不存在右子树,栈顶元素C节点出栈,回到C节点。输出C节点内容。
- 栈顶元素A节点出栈,输出A节点内容。
- 递归结束。
上述过程可以总结一下。
- 若当前节点不为空:
(1)此节点没有被访问,则将此节点入栈,进入该节点的左子树。
(2)若此节点为栈顶元素且之前被访问过一次,则进入该节点的右子树。
(3)若此节点为栈顶元素之前被访问过两次,则输出此节点内容并出栈此节点,回到当前栈顶元素所在的节点。 - 若当前节点为空
(1)回到当前栈顶元素所指的节点,按照“节点不为空”的流程继续执行。
(2)若此时栈也为空,则结束遍历流程。
这样就可以写出伪代码
struct _node
{
tree_node* ptr;
bool isFirst;
}
postorder traversal(root)
{
p=root;
stack<_node> s;
_node q;
while(p!=NULL && s.isEmpty()!=true)
{
if(p!=NULL)
{
q.ptr=p;
p.isFirst=true;
s.push(p);
p=p.left;
}
else
{
if(s.getTop().isFirst==true)
{
s.getTop().isFirst=false;
p=s.getTop().ptr;
p=p.left;
}
else
{
p=s.pop().ptr;
print(p.data);
p=NULL;
}
}
}
}后者的伪代码为:
postorder traversal(root)
{
p=root;
stack s;
map m;
while(p!=NULL && s.isEmpty()!=true)
{
if(p!=NULL)
{
//在散列表内插入此节点,key为节点p,value为数字1
m.insert(<p,1>);
s.push(p);
p=p.left;
}
else
{
//如果散了表内包含栈顶元素
if(m.find(s.getTop()).times==1)
{
m.find(s.getTop()).times=2;
p=s.getTop();
p=p.left;
}
else
{
p=s.pop();
print(p.data);
p=NULL;
}
}
}
}两种方法的时间复杂度比较
- 向节点内添加成员的方法中,访问和修改成员的时间均为Θ(1)。
- 利用散列表插记录访问状态的方法中,散列表的查找,插入和修改操作都是Θ(1)的时间。
- 综上所述,二者在时间上相差十分微小,不过鉴于散列表的底层实现机制,以及可能会存在空间扩张的操作,所以统计性能上应该是第一种更快一些。
两种方法的空间复杂度比较
- 新的带访问次数的节点在程序退后后所占用的空间会被释放。
- 利用散列表插记录访问状态的方法中,额外的空间都是在遍历过程中存在的,遍历结束后空间会被释放。
- 综上所述,两种方法的空间复杂度相同。
#include <iostream>
#include <stack>
using namespace std;
struct Node
{
int data;
Node* left, *right;
bool isFirst;
Node(int data) {
this->data = data;
isFirst = false;
left = right = nullptr;
}
};
//创建一个二叉树
Node* create();
//后序遍历
void postorder_traversal(Node* root);
int main()
{
Node* root = create();
postorder_traversal(root);
cout << endl;
system("pause");
return 0;
}
Node * create()
{
Node* root = new Node(0);
Node*p = root;
p->left = new Node(1);
p->right = new Node(2);
p->right->left = new Node(3);
p->left->left = new Node(4);
p->left->right = new Node(5);
return root;
}
void postorder_traversal(Node* root)
{
stack<Node*> s;
Node* p = root;
while (p != nullptr || !s.empty())
{
if (p != nullptr)
{
p->isFirst = true;
s.push(p);
p = p->left;
}
else
{
if (s.top()->isFirst == true)
{
p = s.top();
p->isFirst = false;
p = p->right;
}
else
{
p = s.top();
s.pop();
cout << p->data << " ";
p = nullptr;
}
}
}
}第二种方法的C++代码:
#include <iostream>
#include <stack>
#include <map>
using namespace std;
struct Node
{
int data;
Node* left, *right;
Node(int data) {
this->data = data;
left = right = nullptr;
}
};
typedef pair<Node*, int> NodeInMap;
//创建二叉树
Node* create();
//后序遍历
void postorder_traversal(Node* root);
int main()
{
Node* root = create();
postorder_traversal(root);
cout << endl;
system("pause");
return 0;
}
Node * create()
{
Node* root = new Node(0);
Node*p = root;
p->left = new Node(1);
p->right = new Node(2);
p->right->left = new Node(3);
p->left->left = new Node(4);
p->left->right = new Node(5);
return root;
}
void postorder_traversal(Node* root)
{
stack<Node*> s;
Node* p = root;
map<Node*,int> m;
NodeInMap node_int;
map<Node*, int>::iterator itor;
while (p != nullptr || !s.empty())
{
if (p != nullptr)
{
node_int.first = p;
node_int.second = 1;
//插入散列表内
m.insert(node_int);
s.push(p);
p = p->left;
}
else
{
itor = m.find(s.top());
if (itor!=m.end()&&itor->second==1)
{
//如果访问次数为一
itor->second = 2;
p = s.top();
p = p->right;
}
else
{
p = s.top();
s.pop();
cout << p->data << " ";
p = nullptr;
}
}
}
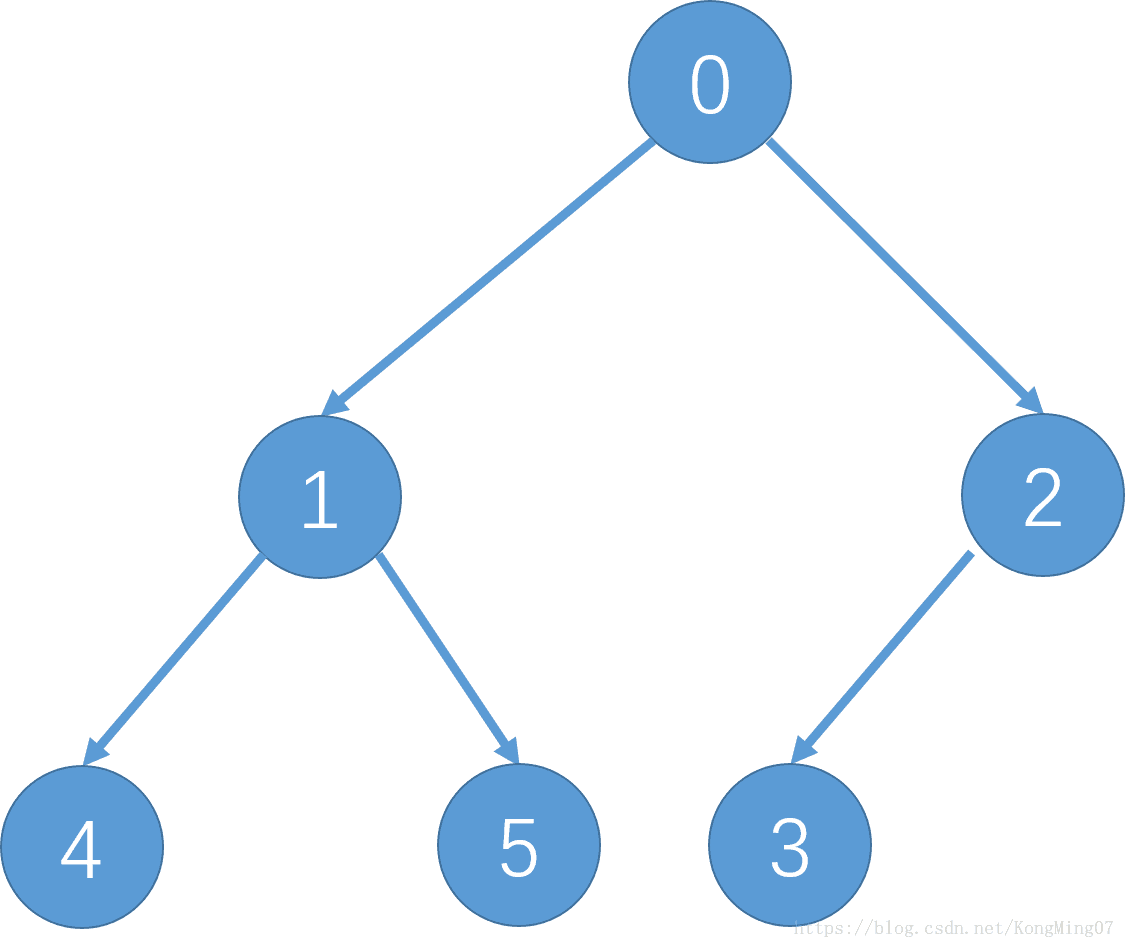
}C++代码中二叉树如图: