导读
论文题目《Semantic understanding and prompt engineering for large-scale traffic data imputation》该论文于2023年发表于《Information Fusion》(影响因子:18.6),介绍了一种基于语义理解和提示工程的大规模交通数据补全模型。该模型结合了大语言模型(Large Language Model,LLM)的能力,成功地打破了交通数据补全领域的应用壁垒。这一创新使得非专家用户能够轻松地通过自然语言与复杂的模型进行交互,为LLM在智能交通系统领域的应用提供了可行的思路。论文的内容使交通数据补全变得更加通顺和连贯,为智能交通系统的发展提供了有力支持。(https://www.sciencedirect.com/science/article/abs/pii/S1566253523003548)。
摘要
智能交通系统需要应对大规模数据缺失的挑战。现有的研究主要通过建立网络级时空相关性模型来解决这个问题。然而,这些方法在捕捉全网络时空相关性时,往往会忽略道路网络中固有的丰富语义信息(如道路基础设施、传感器位置等)。该文提出了一种基于图变换的交通数据补全(GT-TDI)模型,该模型利用道路网络的时空语义理解来补全大量交通数据中的缺失值。该模型利用语义描述来捕捉道路网络中交通的空间和时间动态,从而提高了推断综合时空关系的能力。此外,为了增强模型的能力,该文采用了大型语言模型和提示工程,实现与交通数据补全系统的自然和直观的交互,允许用户使用简单的语言进行查询和请求,而不需要专业知识或复杂的数学模型。所提出的模型GT-TDI利用图神经网络和Transformer架构,将不足的观测、传感器社交连接和语义描述作为输入,进行大规模交通数据补全。
引言
在智能交通系统中,数据的缺失通常分为两类:随机缺失(Random Missing, RM)和非随机缺失(Non-random Missing, NM)。随机缺失指的是个别数据点随机丢失,可能是由于电网波动或数据包传输丢失导致的。而非随机缺失则是连续或相关数据在一定时间内缺失,可能是由于传感器故障或定期维护导致的。在图1中可以看到,传感器层面和网络层面上的RM和NM。相比之下,非随机缺失比随机缺失更具挑战性,因为道路网络中的一些传感器可能会长时间没有数据,这会扰乱时空相关性并降低补全性能。
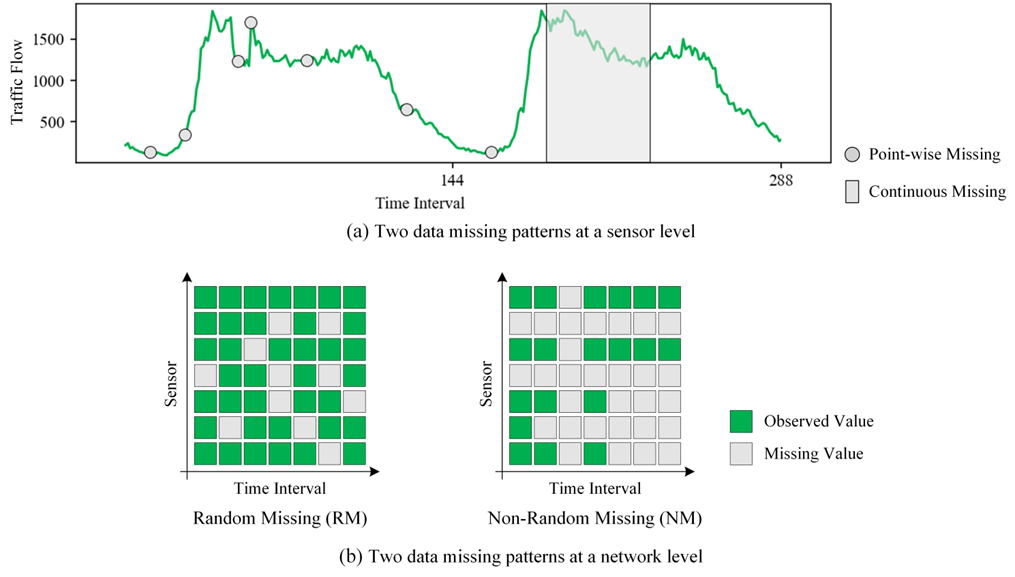
图1 两种数据缺失模式
尽管现有的方法模拟了网络级的时空相关性,但它们经常忽略了道路网络中固有的丰富语义信息,如道路基础设施和传感器位置。为了解决这个问题,作者引入了基于图变换器的交通数据补全(GT-TDI)方法。此外,该研究还介绍了如何利用提示工程技术将提示融入交通数据补全中,从而弥合了大型语言模型(LLM)和智能交通系统(Intelligent Transportation System, ITS)之间的鸿沟。
该文主要通过以下步骤解决智能交通系统中数据补全的挑战:
l 通过引入语义描述为交通数据补全提供了一个新的视角。通过捕捉道路网络中固有的丰富语义信息,如道路基础设施和传感器位置等,可以帮助补全模型以适当的粒度捕获时空相关性。
l 将提示工程技术应用到ITS中。通过将提示融入交通数据补全的技术,可以架起大型语言模型(LLM)和智能交通系统(ITS)之间的桥梁。这种技术可以帮助补全模型更好地理解用户的查询和请求,从而提供更准确、更实用的补全结果。
l 基于真实的大规模交通数据进行了广泛的补全实验。实验结果表明,所提出的GT-TDI比最先进的模型提供了更精确的补全。
模型框架
该文提出使用基于Transformer的文本模型对路网的语义描述和自然语言提示语进行匹配。通过这种匹配,可以驱动GT-TDI模型来完成数据补全。具体的流程参见图2。
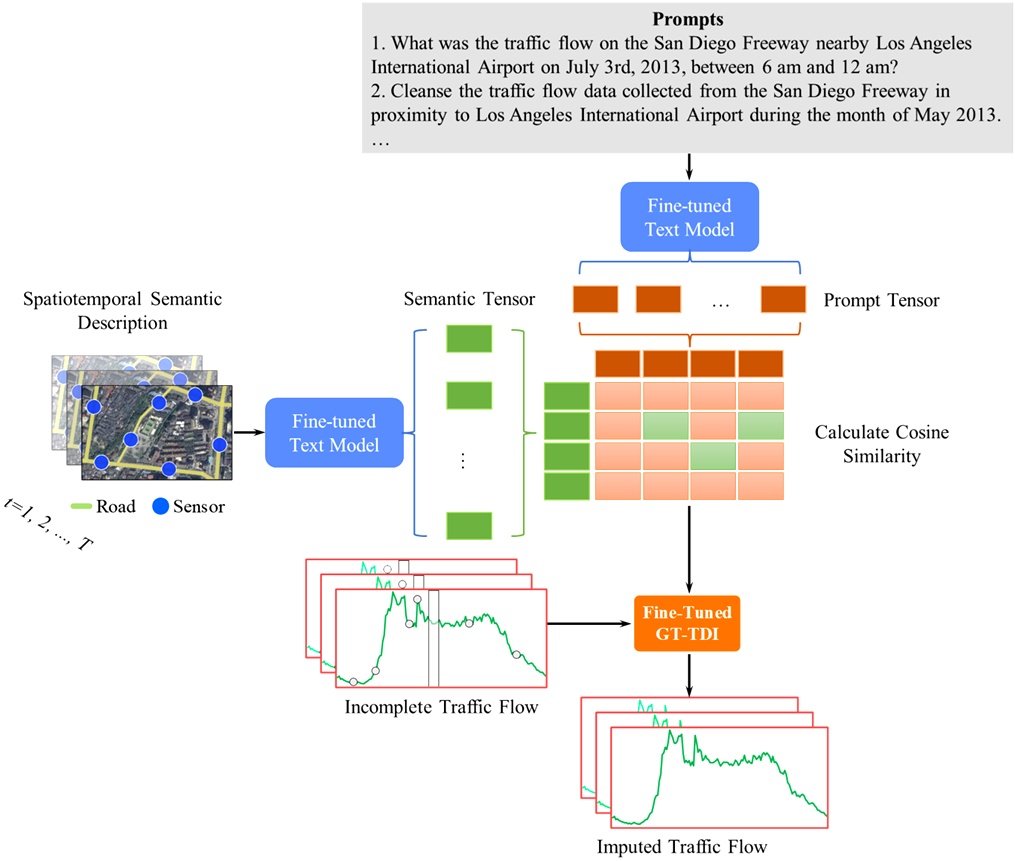
图2 通过提示语进行交通数据补全
1. 文本模型
利用文本模型,可以桥接领域专家与普通用户之间的差异,让他们更直观地与交通数据补全系统互动。该文采用了基于BERT的模型。BERT,基于Transformer编码器架构,专为处理自然语言文本而设计。其预训练是在大规模文本语料库上进行的,随后针对特定任务进行微调。BERT的核心创新是双向编码机制,允许在双向上捕捉上下文信息,捉到传统模型可能遗漏的微妙语言差异。
文本模型的品质对于语义匹配至关重要。该文选择了预训练的BERT作为核心模型。但需注意,由于预训练模型常基于大型、多样化的语料库,它可能不会完全适应特定的数据集特征。为解决这一问题,该文对BERT进行了微调,以更好地适应用于补充不完整交通数据的目标数据集。这样的微调不仅增强了模型与特定问题领域的紧密度,而且提高了其准确性。该文使用时空语义描述作为关键词,通过与ChatGPT 3.5进行交互,获取相关语料,再利用句子-关键词对文本模型进行微调,确保生成的句子与关键词之间的余弦相似度得到优化。
2. 语义描述
论文中采用的语义描述旨在记录道路网络每一段或"切片"的空时信息。具体细节如下:
组成部分:如图3所示,语义描述由多个标签组成,包括道路名称、传感器ID、兴趣点(Point of Interest, POI)、传感器位置、交通流方向、月份、日期及切片ID等。
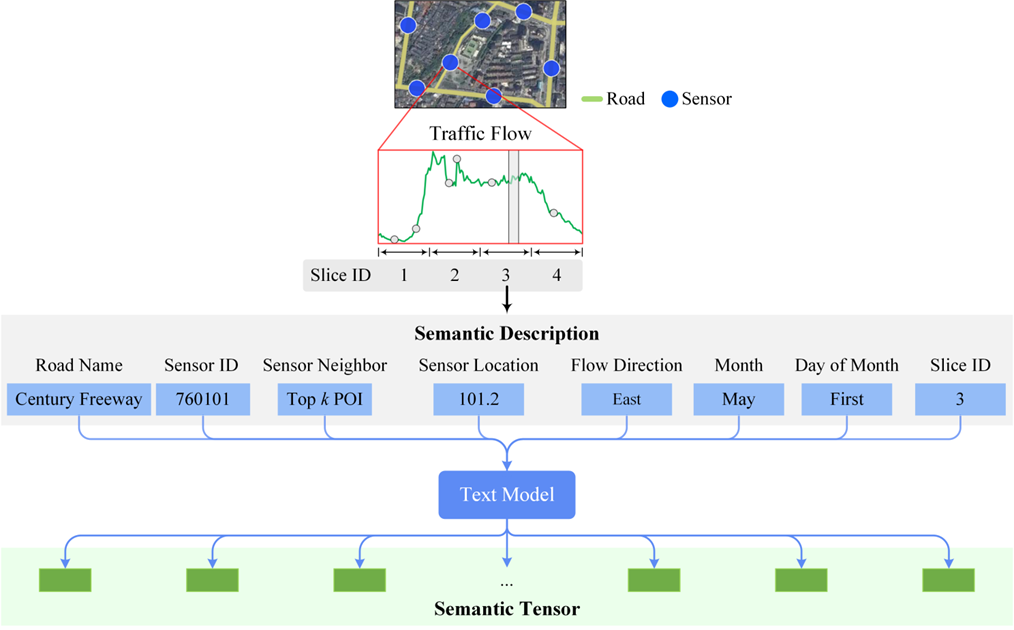
图3 语义描述
功能和优势:
编码空间和时间信息:语义描述以不同的粒度编码空间和时间信息,这有助于补全模型理解道路网络的时空语义。
知识转移:它使得从一个交通数据切片到另一个切片的有用知识在网络级别通过全局的空间和时间信息进行转移。这些优点提高了补全模型准确捕获时空相关性的能力,并增强了补全性能。
文本描述:它由文本描述组成,人类可以轻松理解这些描述,这可以为人类提供一个有效的界面,与自然语义处理模型(例如LLMs)进行交互,从而提高ITS的能力,实现更好的通信、数据集成、分析、预测和个性化服务。
此外,该论文还强调了语义描述的三个优点:编码了具有不同粒度的空间和时间信息;使得从一个交通数据切片到另一个切片的有用知识在网络级别进行转移;由文本描述组成,可以被人类轻松理解。
3.数据补全模型GT-TDI
如图4所示,GT-TDI (Graph Transformer-based Traffic Data Imputation) 的流程图描述了如何使用Graph Transformer进行交通数据补全。以下是关于GT-TDI流程的详细介绍:
(1)交通网络模型:
交通网络可以被建模为一个加权有向图 G = (V, E),其中V是图中连接的节点(即传感器)的集合,E为边(传感器之间的关系)。
(2)数据准备:数据来自传感器的原始数据,包括道路结构和观测到的交通数据。尽管一些道路是有方向的,但考虑交通的双向影响,该文选择了无向图。
(3)语义描述:
所有的交通数据都带有语义描述,包括8个标签。其中,道路名称和传感器位置信息在日常查询中至关重要。
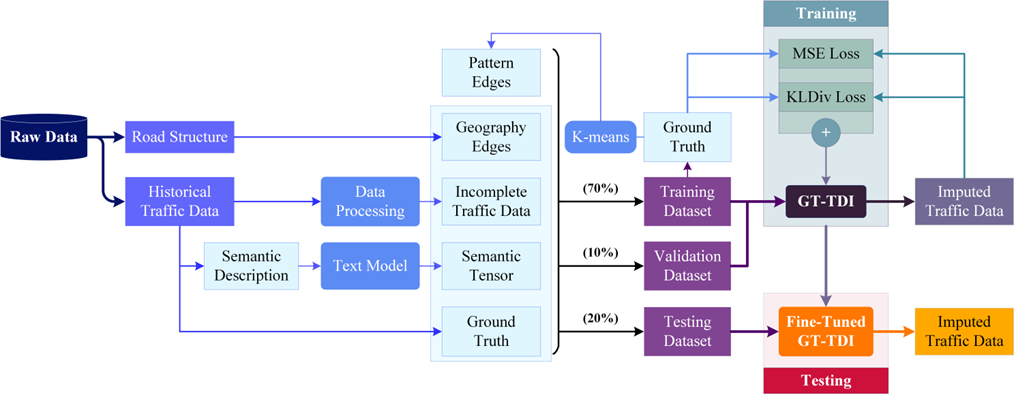
图4 GT-TDI训练流程图
GT-TDI模型的框架如图5所示,模型输入包括不完整的交通数据YI、相应的边E和来自文本模型的语义张量P。GT-TDI模型包括图模块 (Graph Module)、语义模块 (Semantic Module)和补全模块 (Imputation Module)。图模块的输入是不完整的交通数据YI和相应的边E。这些数据被输入到Graph Transformer中,使用多头注意力来执行带有边特征的图学习。语义模块的输入是语义张量P,由两个Conv1d层、一个LeakyReLU层和一个带有dropout的残差连接,以减少过拟合并提高泛化能力。补全模块被引入来执行补全,它由一个BatchNorm1D层、一个Transformer编码器、两个线性层和一个LeakyReLU层组成。
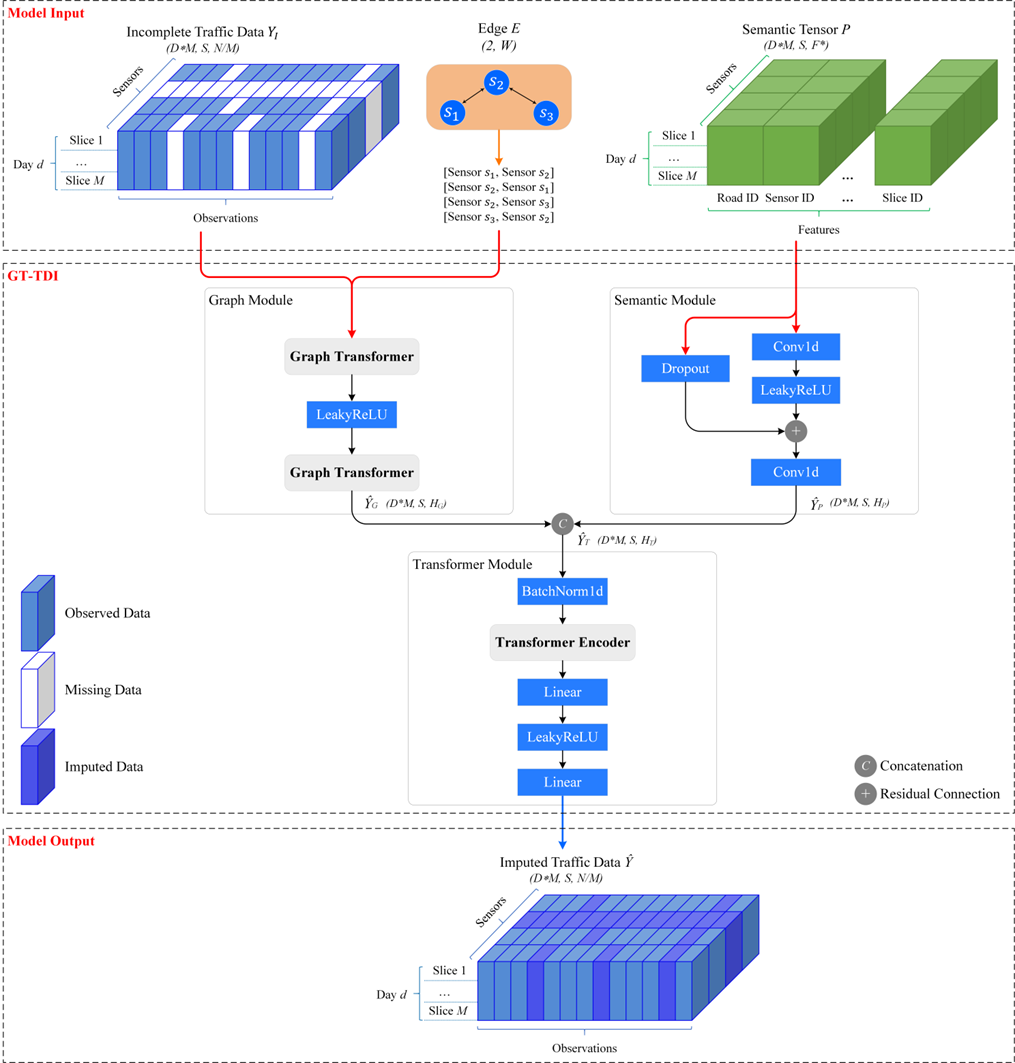
图5 GT-TDI模型框架
实验结果
该文采用PeMS数据集,以验证GT-TDI模型的交通数据补全能力。此数据集涵盖了1740个交通监测点。图6展示了研究区域,并以红色节点标明了监测点的位置。
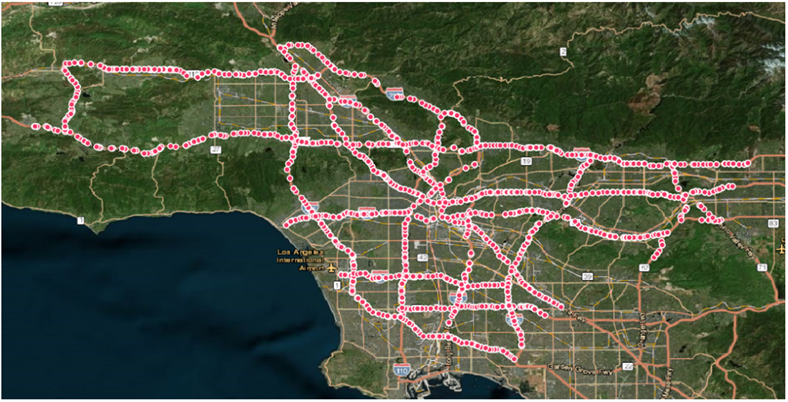
图6 数据监测点位置
1. 模型比较
该文对GT-TDI模型进行了详细评估,并将其与多种其他方法对比。以下是对比的方法:
KNN (K-Nearest Neighbors):一种实例化学习方法,通过最近邻观测值来预测缺失值。
PPCA (Probabilistic Principal Component Analysis):统计方法,旨在估计缺失数据并降低数据维度。
LSTC-Tubal 和 LRTC-TNN:这两种方法都是基于张量分解的方法,用于处理多维数据。
DAE (Deep AutoEncoder):基于深度学习,用于获取数据的低维表示和重构。
GCN-GRU:结合了图卷积网络和门控循环单元,专为时空数据设计。
该文使用的性能指标包括对称平均反正切绝对百分比误差(Mean Arctangent Absolute Percentage Error, MAAPE)和均方根误差(Root Mean Squared Error, RMSE)。
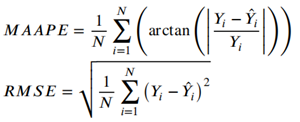
以交通流预测为例,各模型在不同缺失类型、不同数据缺失率(Missing Rate,MR)情况下的预测结果如下表所示。传统方法往往忽略了道路网络的时空信息,导致补全不准确。虽然两种张量分解方法在随机缺失下有出色表现,但在非随机缺失模式下并不理想。而基于深度学习的DAE和GCN-GRU,虽在随机缺失下不及张量分解方法,但GCN-GRU在非随机缺失模式下达到了令人满意的效果。而GT-TDI模型凭借其特有的网络结构和语义张量,显示出最佳的补全效果。图7和图8进一步展示了其在50%和70%缺失率下的优异表现。
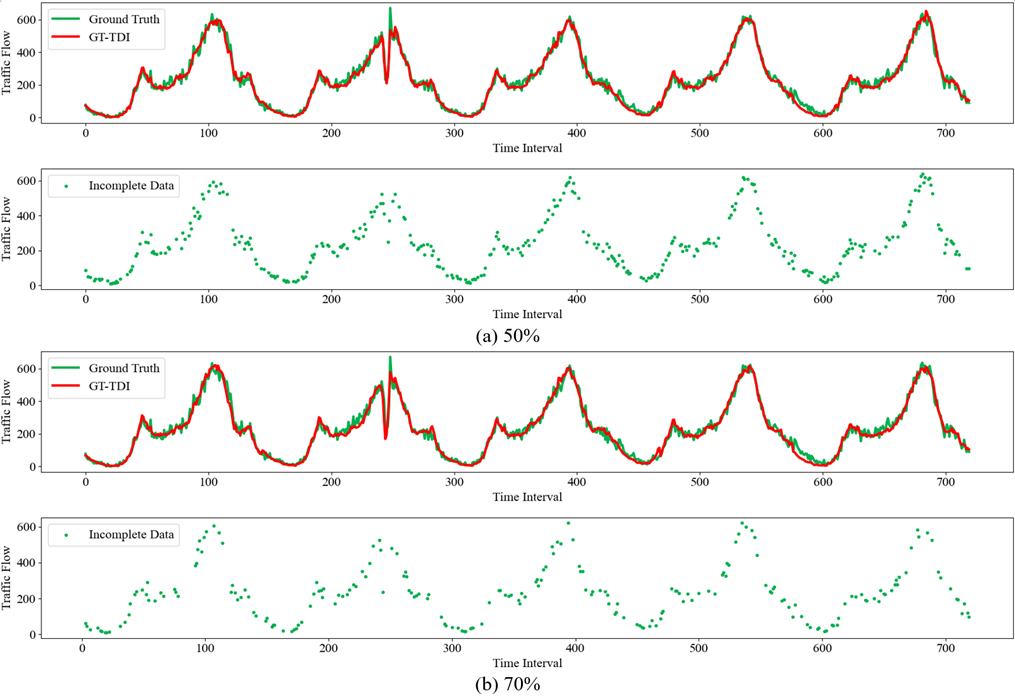
图7 GT-TDI模型对随机缺失模式下的两种缺失率进行交通流补全
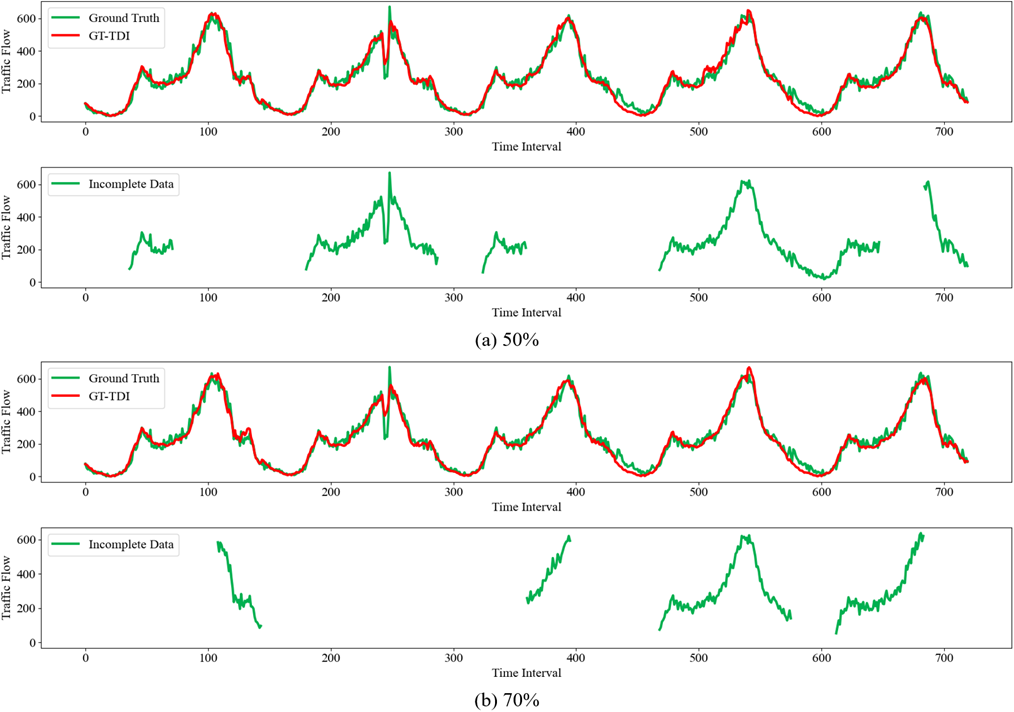
图8 GT-TDI模型对非随机缺失模式下的两种缺失率进行交通流补全
2. 预训练与微调文本模型
为了评估GT-TDI与预训练和微调文本模型的协同效果,随机生成了1000个提示语来补全交通流量。图9显示,微调后的文本模型能显著提升GT-TDI的效能,强调了在交通数据补全时微调文本模型的重要性。
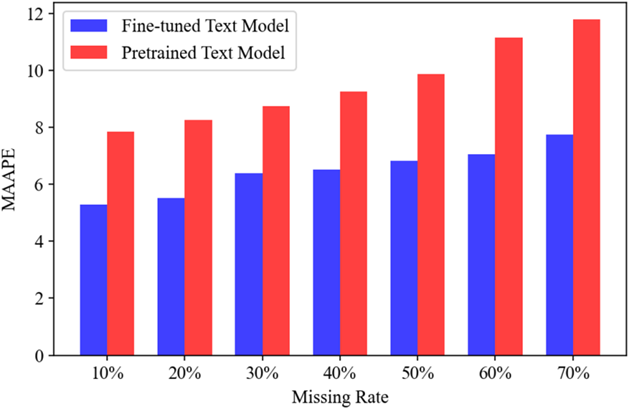
图9 具有预训练文本模型和微调文本模型的GT-TDI模型的性能
3. 提示语模板
本部分对比了使用和不使用提示模板下的GT-TDI模型效果。表5列出了部分模板,其中包括补全任务必要的信息。图10显示,使用提示模板的GT-TDI模型表现更佳,这可能归因于模板使提示更标准化、简洁。

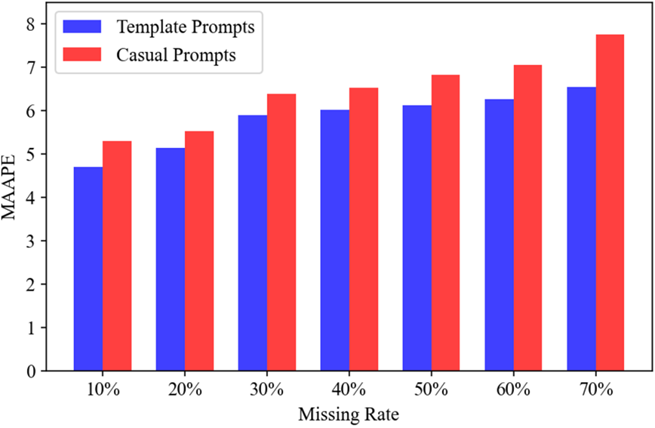
图10 提示语模板对GT-TDI模型性能的影响
4. 提示语长度影响
本部分探讨了提示语长度如何影响GT-TDI模型在补全任务中的性能,特别关注提示语的字数与30%的数据缺失率下的MAAPE的关系。如图11所示,随着提示长度的逐渐增加,MAAPE的值呈现先下降后上升的趋势。这表明更长的提示能够为模型提供更丰富的上下文或与标记示例相关的信息,尤其在处理复杂或与特定上下文相关的任务时。这有助于消除不确定性,增加明确性,从而提高模型性能。然而,太长的提示可能带来无关的信息或冗余,这可能导致模型偏离其核心任务。这种情况会增加计算复杂性,并可能降低模型的准确性。

图11 具有不同单词数量的提示语对GT-TDI模型性能的影响
结论
该文提出了GT-TDI模型,该模型独特地融合了图神经网络、Transformer和提示工程,专门针对交通流数据的补全任务。为了进一步强化模型的性能,还引入了语义描述,使GT-TDI模型能更加准确地理解道路网络中的时空关系。在PeMS数据集的验证下,相较于传统方法(如KNN和PPCA)、张量分解技术(如LSTC-Tubal和LRTC-TNN)以及其他深度学习策略(如DAE和GCN-GRU),GT-TDI模型展现出了卓越的补全准确性,特别是在数据缺失率较高的场景中。
该文的主要贡献总结如下:(1)在语义描述的辅助下,GT-TDI模型可以捕获交通数据补全中的时空相关性;(2)通过提示工程,交通数据补全系统实现了与用户的自然、直观的交互,使得用户无需依赖专业背景或复杂数学模型,仅通过自然语言就能进行查询和请求;(3)众多补全实验证明,GT-TDI模型在准确性上超越了目前的先进技术,尤其在数据严重缺失的情境中表现尤为突出。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!