
手把手在自己的数据集cityscapes上训练FCN

在CV中挣扎的飞行员
关注她
12 人赞了该文章
版权声明:本文为原创文章,未经允许不得转载。
关于FCN是什么: 请移步FCN学习:Semantic Segmentation
1 你需要准备的
- 数据集(RGB + Label Mask) 在本文中以Cityscapes Fine Dataset为例
- Caffe/GPU/...
2 训练思路
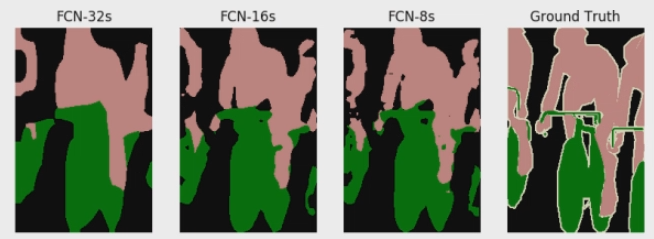
根据FCN skip Architecture,最佳训练的流程是 FCN-32s -> FCN-16s -> FCN 8s,FCN-32s我们用VGG16-fcn从头训练,收敛后Copy weights训练FCN-16s ..至 FCN-8s. 如果一步到FCN-8s也是可以的。。按fcn的对比最后效果是一样的,但我实际train过程中感觉第一个流程训练更稳

3 训练FCN-32s
参考官方github:shelhamer/fcn.berkeleyvision.org
训练FCN-32s你需要准备:
net.py用于生成trainl.prototxt 和 val.prototxt;solve.py作为训练脚本;此外对于你的dataset你还需要准备一个cityscapes_layer.py用于读取data. train.txt/val.txt用于指train data和label的位置,放在dataset根目录下(位置也可以在cityscapes_layer.py中修改):(train.txt范例)
第一行指RGB image 第二行指对应的label
/raid/Dataset/cityscapes/leftImg8bit/train/
/raid/Dataset/cityscapes/gtFine/train/
- 修改net.py:创建网络结构
import caffe
from caffe import layers as L, params as P
from caffe.coord_map import crop
def conv_relu(bottom, nout, ks=3, stride=1, pad=1):
conv = L.Convolution(bottom, kernel_size=ks, stride=stride,
num_output=nout, pad=pad,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
return conv, L.ReLU(conv, in_place=True)
def max_pool(bottom, ks=2, stride=2):
return L.Pooling(bottom, pool=P.Pooling.MAX, kernel_size=ks, stride=stride)
def fcn(split):
n = caffe.NetSpec()
pydata_params = dict(split=split, mean=(71.60167789, 82.09696889, 72.30608881)【3】,
seed=1337)
if split == 'train':
pydata_params['cityscapes_dir'] = '/raid/Dataset/cityscapes【1】'
pylayer = 'CityscapesSegDataLayer【2】'
else:
pydata_params['cityscapes_dir'] = '/raid/Dataset/cityscapes【1】'
pylayer = 'CityscapesSegDataLayer'【2】'
n.data, n.label = L.Python(module='cityscapes_layers【2】', layer=pylayer,
ntop=2, param_str=str(pydata_params))
# the base net
n.conv1_1, n.relu1_1 = conv_relu(n.data, 64, pad=100)
n.conv1_2, n.relu1_2 = conv_relu(n.relu1_1, 64)
n.pool1 = max_pool(n.relu1_2)
n.conv2_1, n.relu2_1 = conv_relu(n.pool1, 128)
n.conv2_2, n.relu2_2 = conv_relu(n.relu2_1, 128)
n.pool2 = max_pool(n.relu2_2)
n.conv3_1, n.relu3_1 = conv_relu(n.pool2, 256)
n.conv3_2, n.relu3_2 = conv_relu(n.relu3_1, 256)
n.conv3_3, n.relu3_3 = conv_relu(n.relu3_2, 256)
n.pool3 = max_pool(n.relu3_3)
n.conv4_1, n.relu4_1 = conv_relu(n.pool3, 512)
n.conv4_2, n.relu4_2 = conv_relu(n.relu4_1, 512)
n.conv4_3, n.relu4_3 = conv_relu(n.relu4_2, 512)
n.pool4 = max_pool(n.relu4_3)
n.conv5_1, n.relu5_1 = conv_relu(n.pool4, 512)
n.conv5_2, n.relu5_2 = conv_relu(n.relu5_1, 512)
n.conv5_3, n.relu5_3 = conv_relu(n.relu5_2, 512)
n.pool5 = max_pool(n.relu5_3)
# fully conv
n.fc6, n.relu6 = conv_relu(n.pool5, 4096, ks=7, pad=0)
n.drop6 = L.Dropout(n.relu6, dropout_ratio=0.5, in_place=True)
n.fc7, n.relu7 = conv_relu(n.drop6, 4096, ks=1, pad=0)
n.drop7 = L.Dropout(n.relu7, dropout_ratio=0.5, in_place=True)
n.score_fr = L.Convolution(n.drop7, num_output=19, kernel_size=1, pad=0,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
n.upscore = L.Deconvolution(n.score_fr,
convolution_param=dict(num_output=19【4】, kernel_size=64, stride=32,
bias_term=False),
param=[dict(lr_mult=0)])
n.score = crop(n.upscore, n.data)
n.loss = L.SoftmaxWithLoss(n.score, n.label,
loss_param=dict(normalize=False, ignore_label=255【5】))
# n.accuracy = L.Accuracy(n.score, n.label, loss_param=dict(normalize=False, ignore_label=255))
return n.to_proto()
def make_net():
with open('train.prototxt', 'w') as f:
f.write(str(fcn('train')))
with open('val.prototxt', 'w') as f:
f.write(str(fcn('val')))
if __name__ == '__main__':
make_net()
在这里你需要改的地方:
【1】指向你数据集的位置
【2】在cityscapes_layer.py中的命名(在后面会提到)
【3】数据集的mean: 根据你dataset RGB值平均算出
【4】num_output改为你预测的class数量
【5】一般忽略的label设置为255 那么你在自己写datalayer.py的时候可以将不想要的类设置255
运行后你将得到train.prototxt和val.prototxt(下面为train.prototxt示例)
layer {
name: "data"
type: "Python"
top: "data"
top: "label"
python_param {
module: "cityscapes_layers"
layer: "CityscapesSegDataLayer"
param_str: "{\'cityscapes_dir\': \'/raid/Dataset/cityscape\', \'seed\': 1337, \'split\': \'train\', \'mean\': (71.60167789, 82.09696889, 72.30608881)}"
}
}
layer {
name: "conv1_1"
type: "Convolution"
bottom: "data"
top: "conv1_1"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 100
kernel_size: 3
stride: 1
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
stride: 1
}
...
2.修改cityscapes.py :读入Data
import caffe
import numpy as np
from PIL import Image
import os
import random
class CityscapesSegDataLayer(caffe.Layer):
"""
Load (input image, label image) pairs from the SBDD extended labeling
of PASCAL VOC for semantic segmentation
one-at-a-time while reshaping the net to preserve dimensions.
Use this to feed data to a fully convolutional network.
"""
def setup(self, bottom, top):
# config
params = eval(self.param_str)
self.cityscapes_dir = params['cityscapes_dir']
self.split = params['split']
self.mean = np.array(params['mean'])
self.random = params.get('randomize', True)
self.seed = params.get('seed', None)
# two tops: data and label
if len(top) != 2:
raise Exception("Need to define two tops: data and label.")
# data layers have no bottoms
if len(bottom) != 0:
raise Exception("Do not define a bottom.")
# load indices for images and labels
split_f = '{}/{}.txt'.format(self.cityscapes_dir,
self.split)
self.folders = open(split_f, 'r').read().splitlines()
print(self.folders)
self.indices=[]
path_imgs=self.folders[0];
for root, dirs, files in os.walk(path_imgs):
for name in files:
if ('leftImg8bit' in name) and ('resized_2' in name): #modify this line to control which images are found
name_label=name.replace('leftImg8bit', 'gtFine_labelTrainIds')
root_label=root.replace(self.folders[0], self.folders[1])
self.indices.append((root+'/'+name, root_label+'/'+name_label))
self.idx = 0
# make eval deterministic
if 'train' not in self.split:
self.random = False
# randomization: seed and pick
if self.random:
random.seed(self.seed)
self.idx = random.randint(0, len(self.indices)-1)
先编写一个set up,设置好dataset的路径后walk所有的图片: if语句开始筛选哪些图片用于训练:由于cityscapes图片太大(1024*2048这里我resize了所有的原图片 又cut了一下 所以这里读入的图片大概是512*512大小)
然后我们继续编写data_layer中Reshape部分:
def reshape(self, bottom, top):
# load image + label image pair
self.data = self.load_image(self.indices[self.idx])
self.label = self.load_label(self.indices[self.idx])
# reshape tops to fit (leading 1 is for batch dimension)
top[0].reshape(1, *self.data.shape)
top[1].reshape(1, *self.label.shape)
def forward(self, bottom, top):
# assign output
top[0].data[...] = self.data
top[1].data[...] = self.label
# pick next input
if self.random:
self.idx = random.randint(0, len(self.indices)-1)
else:
self.idx += 1
if self.idx == len(self.indices):
self.idx = 0
def backward(self, top, propagate_down, bottom):
pass
def load_image(self, idx):
"""
Load input image and preprocess for Caffe:
- cast to float
- switch channels RGB -> BGR
- subtract mean
- transpose to channel x height x width order
"""
im = Image.open(idx[0])
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= self.mean
in_ = in_.transpose((2,0,1))
return in_
def load_label(self, idx):
"""
Load label image as 1 x height x width integer array of label indices.
The leading singleton dimension is required by the loss.
"""
im = Image.open(idx[1])
label = np.array(im, dtype=np.uint8)
label = label[np.newaxis, ...]
return label
这里读入Image和label pair,事故高发区在于这个Label...例如你在net.py中设置num_out = 19.那么读入的label图片只能是灰度图,且value只能在0-18区间外带一个255.而cityscapes的label非常坑:

你读入的label是左边这行(Id)而实际训练的是TrainId所以记得一定做个映射,不然会出现
Check failed: status == CUBLAS_STATUS_SUCCESS (14 vs. 0) CUBLAS_STATUS_INTERNAL_ERROR
3. 修改solver.prototxt
train_net: "train.prototxt"
test_net: "test.prototxt"
test_iter: 200
# make test net, but don't invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
base_lr: 1e-10
# high momentum
momentum: 0.99
# no gradient accumulation
iter_size: 8
max_iter: 300000
weight_decay: 0.0005
test_initialization: false
snapshot: 4000
snapshot_prefix: "snapshot/train"
如果我们训练过程中不需要做test我们就将test_interval设置很高。由于我们的fcn最后的softmax是unormalized,所以loss一开始会非常高,base_lr这里设置得很小甚至到微调的时候1e-12.snapshot到4000的时候会保存一下。在这里batch_size = 1 * iter_size,所以我设置iter_size去改变batch-size.由于gradient跳幅有时候仍然很大,所以我在训练的时候又添加了:
clip_gradients: 1e4
加一个scale factor可以限制gradient变动范围
4. 修改solve.py:training script
import caffe
import surgery, score
import numpy as np
import os
import sys
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
# init
caffe.set_device(0)
caffe.set_mode_gpu()
solver = caffe.SGDSolver('solver.prototxt')
solver.net.copy_from(weights)
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
solver.step(2000)
一开始官方版本就长这个样,但可能我们需要:
(1)绘制loss的图
(2)能收敛《详见为什么要用transplant而不用copy_weights》
修改后solve.py:
import caffe
import surgery, score
import numpy as np
import os
import sys
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
vgg_weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt'
final_model_name = 'cityscapes_32s_20000'
n_steps = 20000
# init
caffe.set_device(0)
caffe.set_mode_gpu()
solver = caffe.SGDSolver('solver.prototxt')
vgg_net = caffe.Net(vgg_proto, vgg_weights, caffe.TRAIN)
surgery.transplant(solver.net, vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
solver.step(1)
_train_loss = 0
for it in range(n_steps):
solver.step(1)
_train_loss += solver.net.blobs['loss'].data
if it % display == 1:
train_loss[it // display] = _train_loss / display
_train_loss = 0
print '\n plot the train loss'
plt.plot(display * numpy.arange(len(train_loss)), train_loss)
plt.ylabel('Average Loss')
plt.xlabel('Iterations')
savefig('loss_32s_coarse.png')
print "finished!"
solver.net.save(final_model_name)
当然这也不是最优的写法,如果有多GPU可参考这里写成并行的Script
4 后记
训练好fcn-32s好后步骤就都类似啦。关于Evaluation(infer.py)的部分可参考这里。