概述
语义 SLAM 是指通过物体识别、目标识别、语义分割等技术手段,把所谓的语义特征,即局部地图特征进行归纳组织,提炼出人所理解的语义信息。语义SLAM 相对于传统 SLAM 方法来说其对动态环境的鲁棒性更好、通过添加语义约束获取地图的先验信息,得到更高精度、通过语义约束实现更好地回环检测。(参考《语义地图及其关键技术研究》)

2019
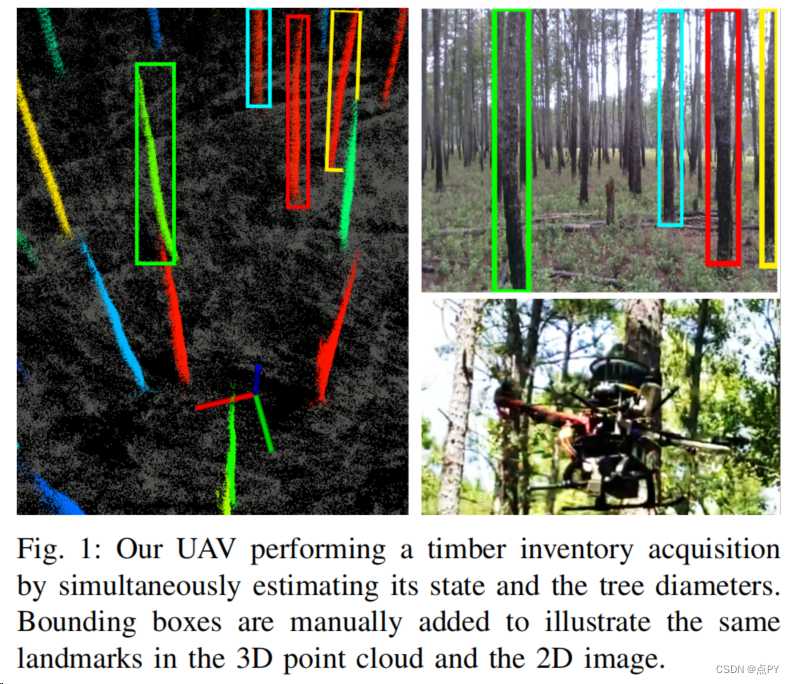
SLOAM: Semantic Lidar Odometry and Mapping for Forest Inventory
code: https://github.com/KumarRobotics/sloam
摘要: 本文介绍了一种基于语义分割和激光雷达测程和映射的端到端树直径估计管道。这种类型的环境的精确映射是具有挑战性的,因为地面和树木被树叶、荆棘和藤蔓所包围,而传感器通常会经历极端的运动。我们提出了一种基于语义特征的姿态优化方法,在估计机器人姿态的同时同时改进树模型。该管道利用一个自定义的虚拟现实工具来标记三维扫描,用于训练语义分割网络。掩蔽点云用于计算一个网格图,该网格图识别单个实例并提取SLAM模块使用的相关特征。我们表明,传统的激光雷达和基于图像的方法在无人机和手携带系统中都失败了,而我们的方法更鲁棒、可扩展,并自动生成树直径估计。
2020
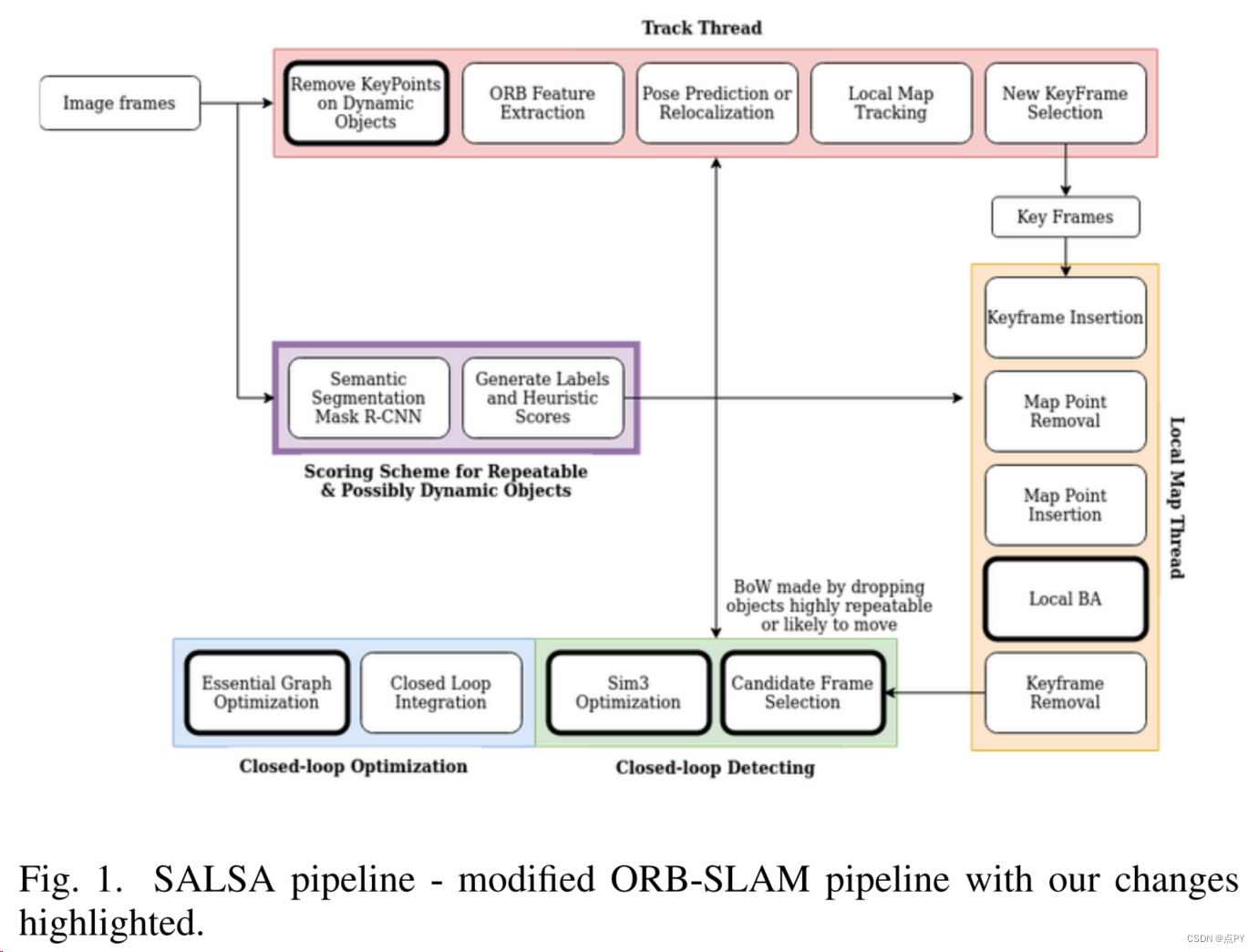
SALSA: Semantic Assisted Lifelong SLAM for Indoor Environments
code: https://github.com/heethesh/SALSA-Semantic-Assisted-SLAM/tree/master
摘要: 我们提出了一种针对室内环境的学习增强终身SLAM方法。大多数现有的SLAM方法都假设是一个静态环境,而忽略了动态对象。另一个问题是,大多数基于特性和语义的SLAM方法在重复的环境中都失败了。周围环境的意外变化破坏了跟踪的质量,导致系统故障。该项目旨在使用学习方法将地标和对象分类为动态的和/或可重复的,以更好地处理优化,在不断变化的环境中实现健壮的性能,并在终身环境中重新定位。我们建议使用语义信息,并根据对象特征点的动态和/或可重复的概率为其分配分数。
语义地图及其关键技术研究(博士论文)
摘要:在深度学习快速发展的背景下,语义地图成为了 SLAM (Simultaneous Localization and Mapping) 领域研究的热点,并得到大量研究人员的关注。语义地图通过基于神经网络的语义分割、物体检测、实例分割等技术应用于 SLAM 建图方法中来实现对周围环境及物体的理解。该方与主流的视觉 SLAM 方法的不同之处在于其不是通过对基于底层像素层级的特征点来估计相机的运动姿势及环境建图,而是通过利用环境物体中的语义信息来辅助建图。这种方式相对于传统的 SLAM 建图方法而言更符合人类视觉系统的原理。此外,随着产品级深度采集设备的普及,为在可见光环境条件下的物体检测及物体语义分割算法ᨀ供了物理上的技术支持,为构建环境语义地图及物体识别的算法ᨀ供了性能优势。
本文针对如何构建稳定有效的环境语义地图这一研究课题,从理解环境语义信息,识别环境物体信息,构建鲁棒的动态语义地图三个层面的问题进行分析,分别对环境语义信息识别、拓扑节点识别,小样本物体识别、动态环境下语义地图构建,环境物体数据库构建等多个方面进行研究。
2021
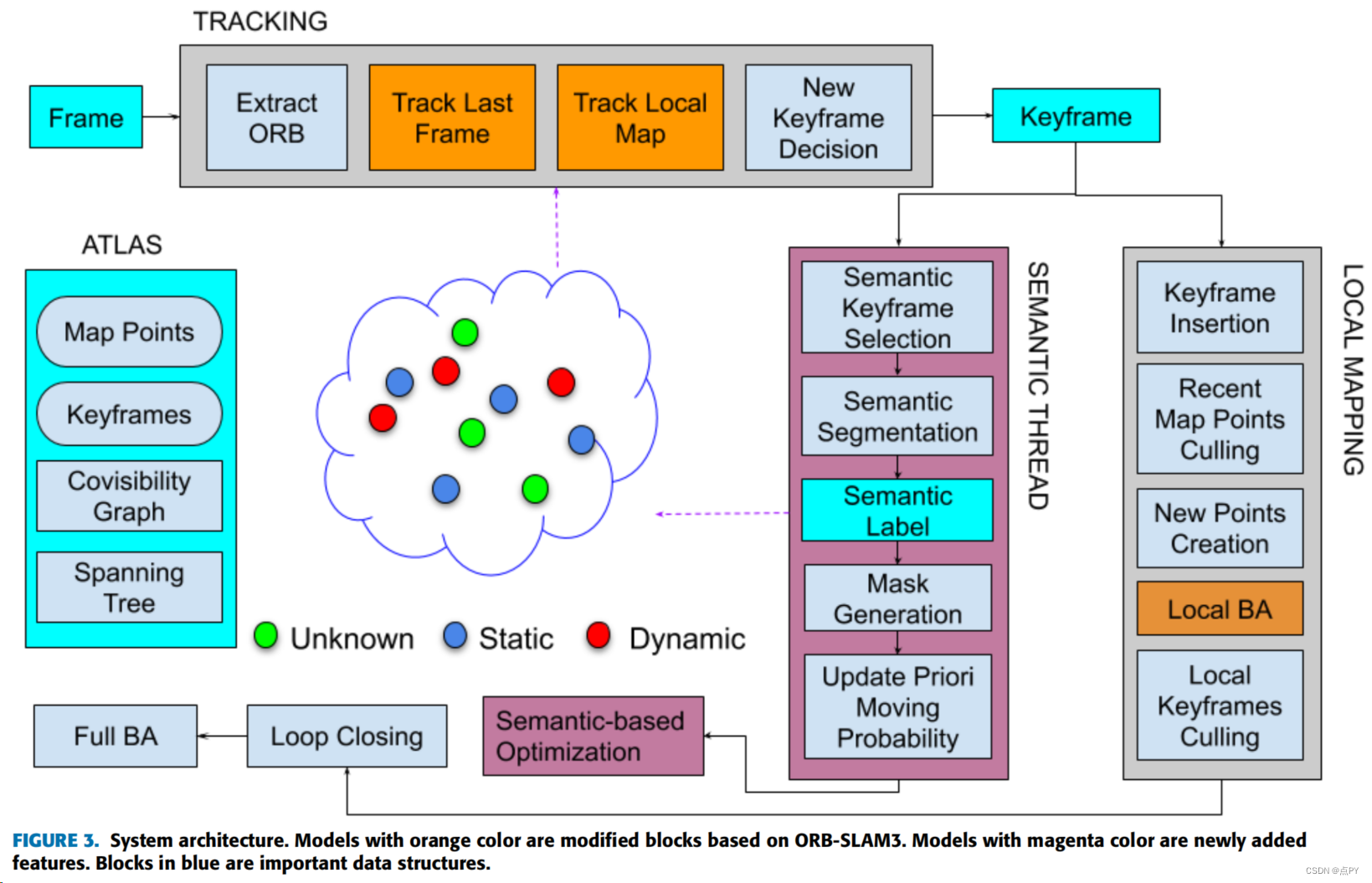
RDS-SLAM: Real-Time Dynamic SLAM Using Semantic Segmentation Methods
code: https://github.com/yubaoliu/RDS-SLAM
摘要: 场景刚性是典型的视觉同时定位和映射(vSLAM)算法中的一个很强的假设。这种强有力的假设限制了大多数vSLAM在动态现实环境中的使用,这些环境是一些相关应用的目标,如增强现实、语义映射、无人自动驾驶汽车和服务机器人。提出了许多使用不同类型的语义分割方法(如掩码R-CNN,SegNet)来检测动态对象和去除异常值的解决方案。然而,据我们所知,这类方法在其架构中等待跟踪线程中的语义结果,而处理时间取决于所使用的分割方法。在本文中,我们提出了一种基于ORB-SLAM3的实时可视化动态SLAM算法RDS-SLAM算法,并添加了语义线程和基于语义的优化线程,用于动态环境中的鲁棒跟踪和映射。这些新线程与其他线程并行运行,因此跟踪线程不再需要等待语义信息。此外,我们还提出了一种尽可能获取最新语义信息的算法,从而使统一使用不同速度的分割方法成为可能。我们使用移动概率来更新和传播语义信息,该移动概率保存在地图中,并使用数据关联算法来去除跟踪中的异常值。最后,我们利用公共TUM RGB-D数据集和Kinect摄像机在室内动态室内场景下的跟踪精度和实时性能。
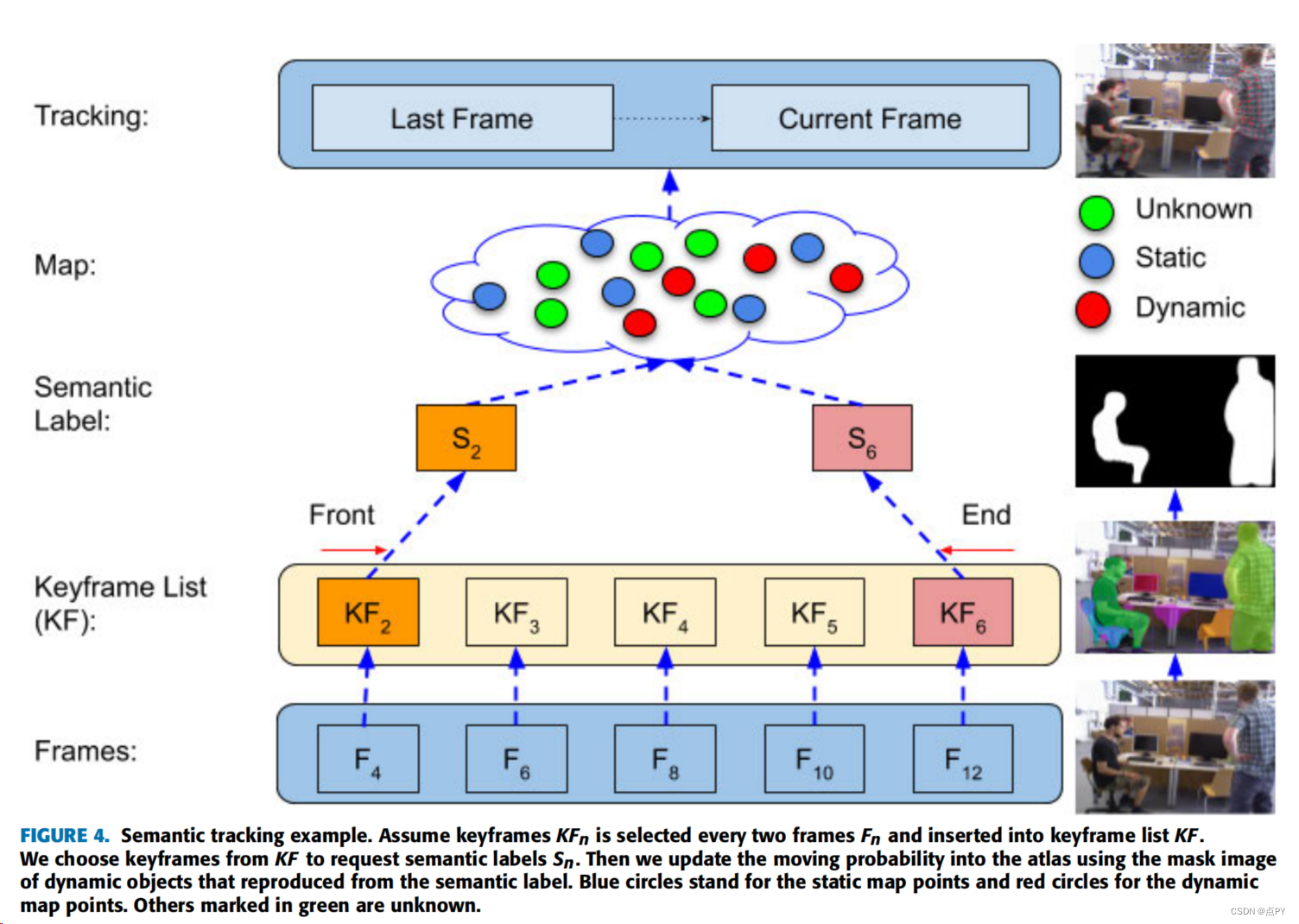
Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems
code: https://paperswithcode.com/paper/kimera-multi-robust-distributed-dense-metric
摘要:多机器人同步定位和映射(SLAM)是在大区域内获得及时态势感知的关键能力。现实世界的应用要求多机器人SLAM系统对感知混叠具有鲁棒性,并在有限的通信带宽下运行;此外,这些系统还希望捕获语义信息,以实现高级决策和空间人工智能。本文提出了Kimera-Multi多机器人系统,(i)健壮,能够识别和拒绝不正确的机器人内部和机器人内部循环闭包,(ii)完全分布,仅依赖局部(点对点)通信来实现分布式定位和映射,以及(iii)建立一个全局一致的实时度量语义环境三维网格模型,其中网格的面用语义标签标注。Kimera-Multi是由一群配备了视觉惯性传感器的机器人实现的。每个机器人使用Kimera构建一个局部轨迹估计和一个局部网格。当通信可用时,机器人启动了一个基于分布式分级非凸性算法的分布式位置识别和鲁棒位姿图优化协议。该协议允许机器人通过利用机器人间的环路闭包来改进它们的局部轨迹估计,同时对异常值具有鲁棒性。最后,每个机器人利用其改进的轨迹估计,利用网格变形技术对局部网格进行校正。我们演示了Kimera-多在照片逼真的模拟,SLAM基准数据集,和具有挑战性的户外数据集收集使用地面机器人。真实的和模拟的实验都涉及长轨迹(例如,每个机器人高达800米)。实验表明,Kimera-Multi (i)在鲁棒性和准确性方面优于现有技术,(ii)在完全分布的情况下实现了与集中式SLAM系统相当的估计误差,(iii)在通信带宽方面很吝啬,(iv)产生精确的元语义三维网格,(v)是模块化的,也可以用于标准的3D重建(即不带语义标签)或轨迹估计(即不重建3D网格)。
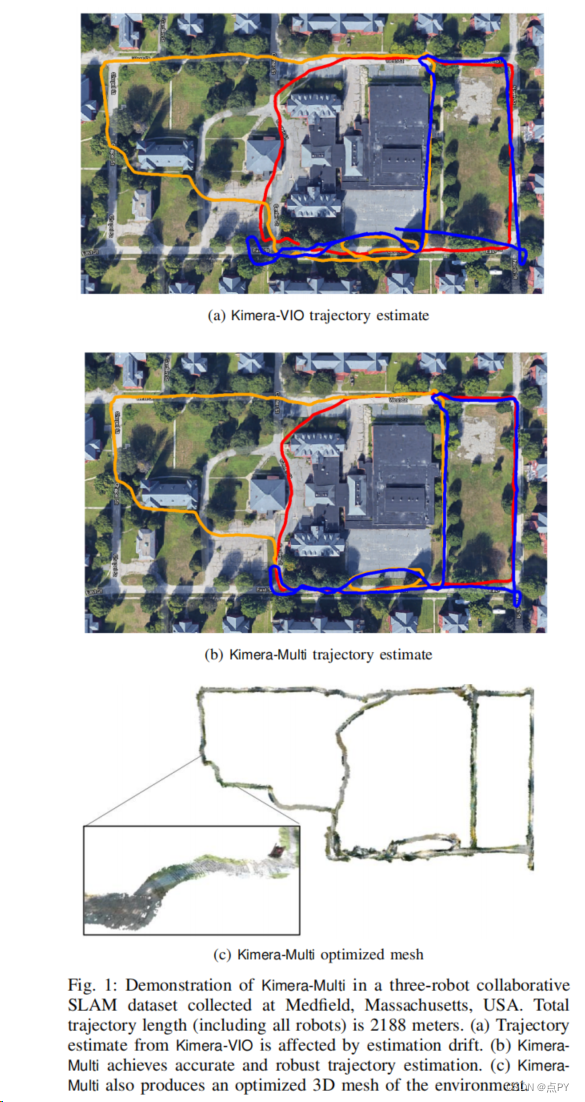
DSP-SLAM: Object Oriented SLAM with Deep Shape Priors
code: https://paperswithcode.com/paper/dsp-slam-object-oriented-slam-with-deep-shape
摘要: 我们提出了DSP-SLAM,一个面向对象的SLAM系统,它为前景对象建立了一个丰富而准确的密集三维模型的联合地图,以及稀疏的地标点来表示背景。DSP-SLAM以基于特征的SLAM系统重建的三维点云作为输入,使其具有通过对检测对象的密集重建来增强其稀疏映射的能力。通过语义实例分割来检测对象,并通过一种新的二阶优化方法,利用类别特定的深度形状嵌入作为先验来估计对象的形状和姿态。我们的对象感知束调整构建了一个姿态图,以联合优化相机姿态,对象位置和特征点。DSP-SLAM可以在3种不同的输入模式下以每秒10帧的速度运行:单目、立体声或立体声+激光雷达。我们在弗里伯格和雷德伍德数据集的单目rgb序列上以几乎帧率运行,以及在KITTI测程数据集上的立体+激光雷达序列上,表明它实现了高质量的全目标重建,即使是部分观测,同时保持一致的全局地图。我们的评估显示,与最近的基于深度先验的重建方法相比,物体姿态和形状重建有所改进,并减少了KITTI数据集上的摄像机跟踪漂移。
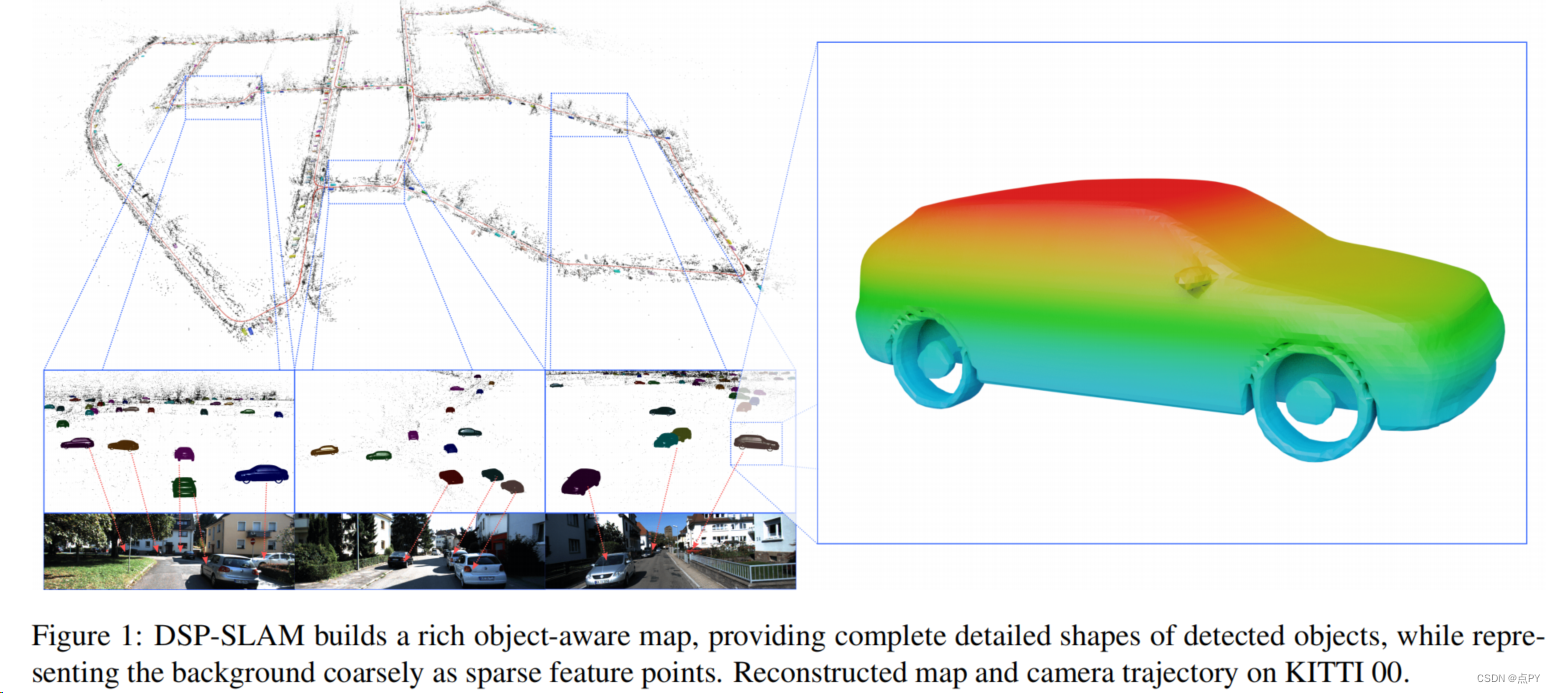
Large-scale Autonomous Flight with Real-time Semantic SLAM under Dense Forest Canopy
code: https://github.com/KumarRobotics/kr autonomous flight https://github.com/KumarRobotics/sloam
摘要:语义地图使用一组语义上有意义的对象来表示环境。这种表示具有存储效率、更模糊、信息更丰富,从而促进了在高度非结构化、被gps拒绝的环境中大规模自主和获取可操作信息。在这封信中,我们提出了一个集成的系统,它可以在具有挑战性的冠层下环境中执行大规模的自主飞行和实时语义映射。我们从激光雷达数据中检测和建模树干和地面平面,这些数据通过扫描相关联,并用于约束机器人的姿态和树干模型。自主导航模块利用多层规划和映射框架,并计算动态可行的轨迹,引导无人机以计算和存储高效的方式构建用户定义的感兴趣区域的语义地图。设计了一种漂移补偿机制,利用语义SLAM输出实时最小化测程漂移,同时保持规划器的最优性和控制器的稳定性。这导致无人机准确和安全地执行其任务。
2022
Object Structural Points Representation for Graph-based Semantic Monocular Localization and Mapping
code: https://paperswithcode.com/paper/object-structural-points-representation-for
摘要:单目语义同时定位和映射(SLAM)的高效对象级表示仍缺乏一种被广泛接受的解决方案。在本文中,我们提出了一种基于结构点的有效表示方法,在基于姿态图公式的单目语义SLAM系统中作为地标的物体几何。特别地,对姿态图中的地标节点提出了一种反深度参数化的方法来存储对象的位置、方向和大小/尺度。所提出的公式是通用的,可以应用于不同的几何形状;在本文中,我们关注室内环境,其中人工制品通常共享一个平面矩形形状,如窗户、门、橱柜等。这种方法可以很容易地扩展到同样存在相似形状的城市场景中。仿真实验显示了良好的性能,特别是在物体几何重建方面。

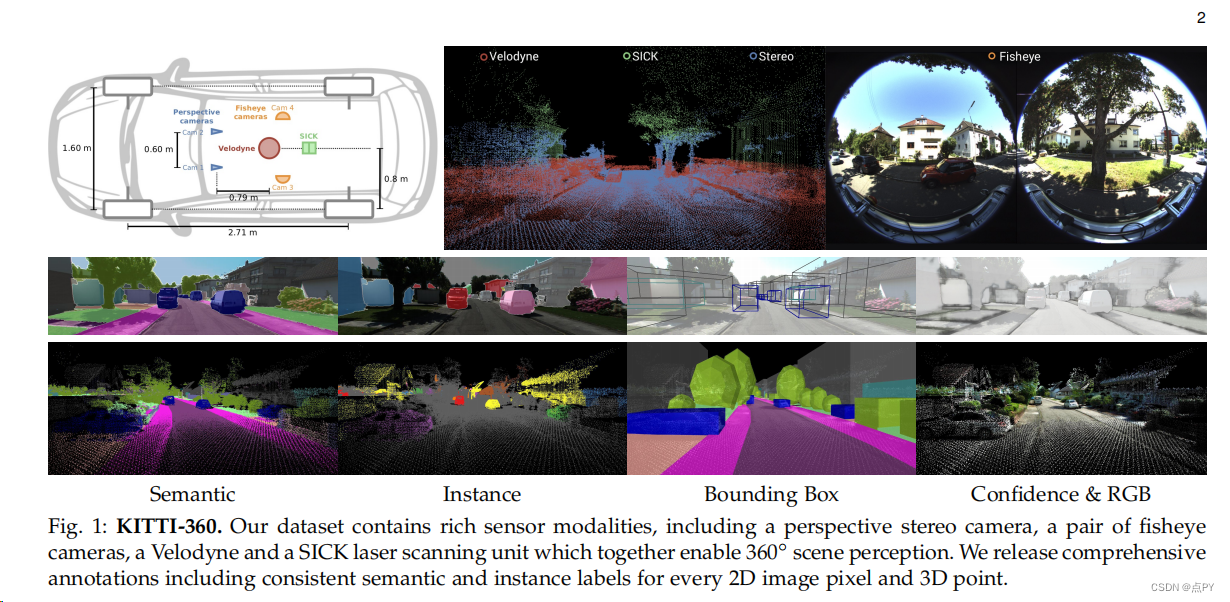
KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D
code: https://paperswithcode.com/paper/kitti-360-a-novel-dataset-and-benchmarks-for
摘要: 在过去的几十年里,人工智能的几个主要子领域,包括计算机视觉、图形学和机器人技术,在很大程度上是相互独立发展的。然而,最近,社区已经意识到,向自动驾驶汽车等强大的智能系统的发展需要不同领域的共同努力。这促使我们开发KITTI-360,即流行的KITTI数据集的继承者。KITTI-360是一个郊区驾驶数据集,它包含更丰富的输入模式、全面的语义实例注释和准确的定位,以促进视觉、图形和机器人技术的交叉研究。为了进行有效的注释,我们创建了一个工具,用边界原语标记3D场景,并开发了一个模型,将这些信息传输到2D图像域,得到超过150k的图像和1个B3D点,在2D和3D上具有一致的语义实例注释。此外,我们还为与移动感知相关的几个任务建立了基准和基线,包括在同一数据集上出现的来自计算机视觉、图形和机器人技术的问题,例如,语义场景理解、新视图合成和语义SLAM。KITTI-360将使这些研究领域的交叉点取得进展,从而有助于解决当今的一个重大挑战:全自动自动驾驶系统的发展。
2023
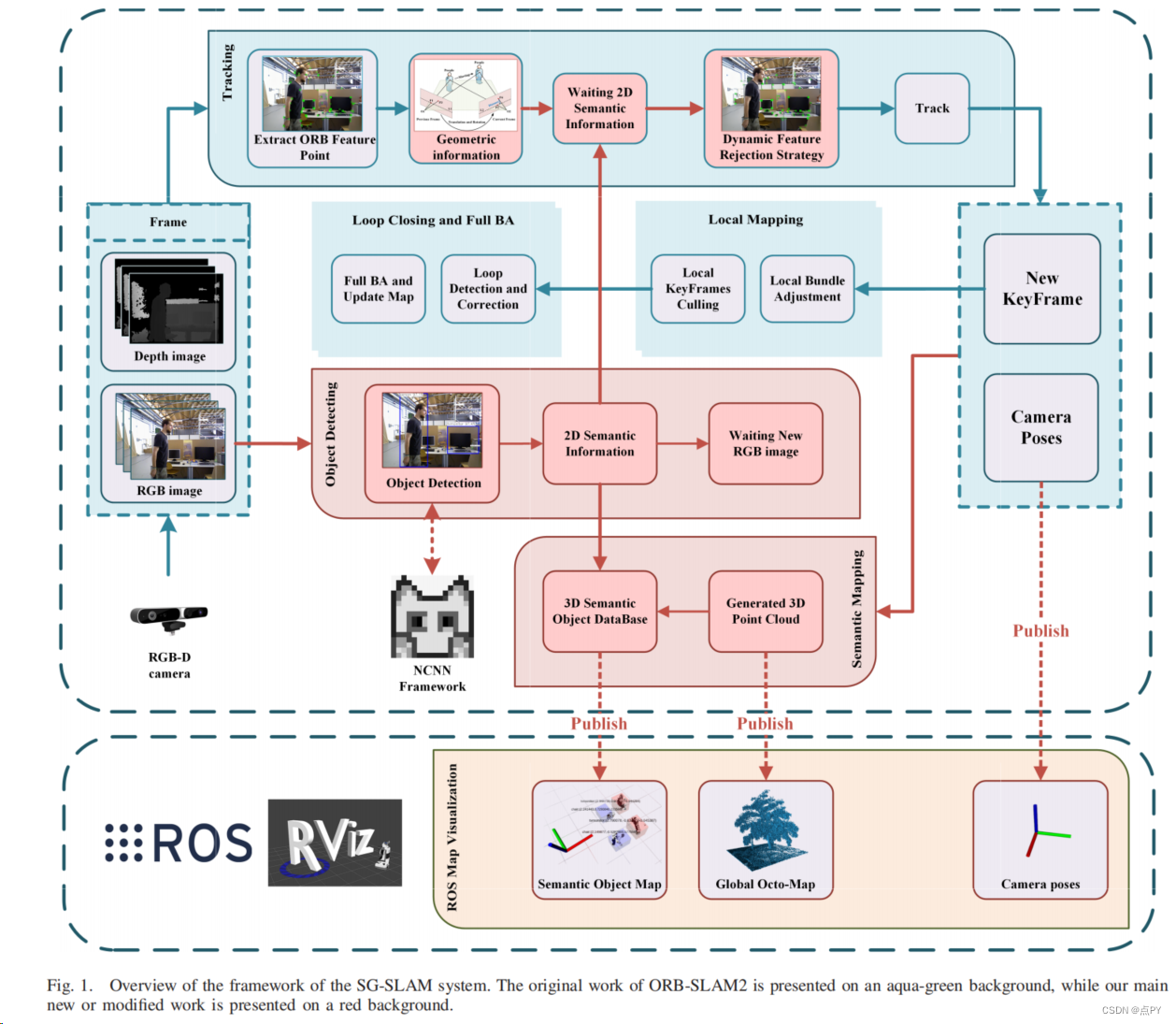
SG-SLAM: A Real-Time RGB-D Visual SLAM Toward Dynamic Scenes With Semantic and Geometric Information
code: https://github.com/silencht/SG-SLAM
摘要:同步定位和映射(SLAM)是智能移动机器人在未知环境下进行状态估计的基本能力之一。然而,大多数视觉SLAM系统依赖于静态场景假设,因此严重降低了动态场景中的准确性和鲁棒性。此外,许多系统构建的度量图缺乏语义信息,因此机器人无法在人类认知水平上理解周围环境。在本文中,我们提出了SG-SLAM,这是一个基于ORB-SLAM2框架的实时RGB-D语义可视化SLAM系统。首先,SG-SLAM添加了两个新的并行线程:一个是对象检测线程来获取二维语义信息,另一个是语义映射线程。然后,在跟踪线程中添加了一种结合语义信息和几何信息的快速动态特征拒绝算法。最后,在语义映射线程中生成三维点云和三维语义对象后,将其发布到机器人操作系统(ROS)系统中进行可视化。我们对TUM数据集、波恩数据集和OpenLORIS-Scene数据集进行了实验评估。结果表明,SG-SLAM不仅是动态场景中最实时、最准确、最鲁棒的系统之一,而且可以创建直观的语义度量映射。