一、chipotle tsv
数据集:chipotle.tsv-数据集
代码:https://download.csdn.net/download/Albert233333/88508819
1 导入数据,tab分割
有的数据文件是用tab来分开的,读取的时候用下面这个参数
# order_id这一列相同的数字表示 一个消费者同一次进行的交易
# 表格中的每一行表示 用户一次购买的某一个品类 购买的数量
# 消费者可能一次购买很多个不同种类的东西,所以你会发现有好几行的item_name不同,但是order_id完全相同。
# 这都是同一个用户在同一个时间购买的(所以order_id完全相同),只不过购买的物品的种类不同(item_name不同)
import pandas as pd
d = pd.read_csv("chipotle.tsv",delimiter="\t")
d
2 找出下单数最多的 item
降序排列用sort_values
# 这里仅仅统计的是单个
d.sort_values('quantity',ascending=False)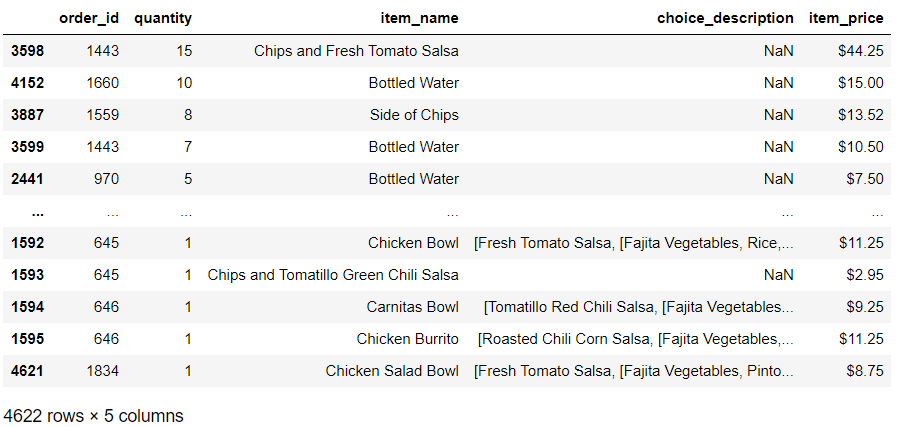
如果你要按照某一列为合并的标准,自行选择合并的方式(求和、均值、max,min)用groupby
你要按照某一列的类别(比如这一列了有薯片、瓶装水、火鸡、沙拉等等商品类别,很多个用户有的买了这个,有的买了那个,你想算出火鸡一共卖了多少件,瓶装水一共卖了多少件),求每个类别的 求和、均值、max,min,用groupby
d.groupby("item_name").sum()[["quantity"]].head()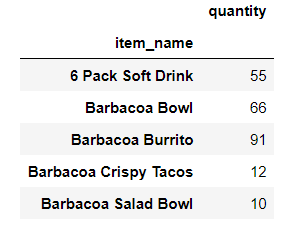
# 按照销售量最高排序
d.groupby("item_name").sum()[["quantity"]].sort_values(by="quantity", ascending=False)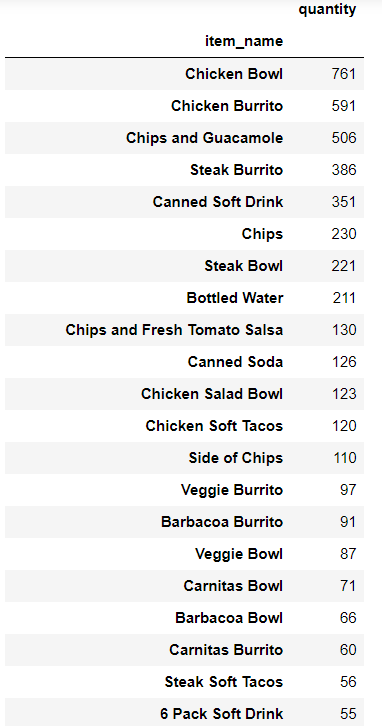
3 将字符串的某一列移除开头的字符,整列从str转float
打印出在该数据集对应的时期内的收入(revenue)数额
收入=销量*价格

item_price这一列,每个数字钱都有 $ 这个符号,要去掉。然后把整列从str转成float,方便后面的计算。
# 第一部分“.str.lstrip("$")”,是将这一列字符串中所有的第一个元素删掉
# 具体来说是删掉左边的 “$”字符
# 第二部分 “.astype(float)”将这一列所有的元素都转成浮点数
d["item_price"].str.lstrip("$").astype(float)
销量与价格相乘再求和,就是总收入
sum(d["quantity"]*d["item_price"].str.lstrip("$").astype(float))二、Titanic
数据集:https://download.csdn.net/download/alienwh329/16680606
代码:https://download.csdn.net/download/Albert233333/88509830
1 将某列设置为索引
df.set_index("PassengerId")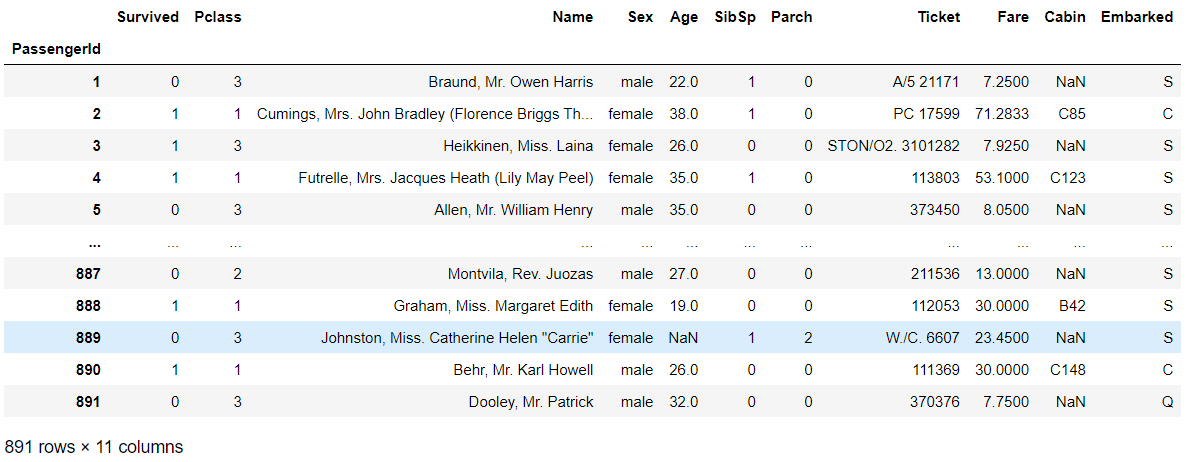
2 绘制扇形图
绘制一个展示男女乘客比例的扇形图
得出男女的具体数字
sex_per = df["Sex"].value_counts()
sex_per
# 把画图的包导入进来
import matplotlib.pyplot as plt
# 这种绘图方式主要用于有多个子图以及复杂的图形布局的时候。
fig,ax = plt.subplots()
# plt.subplots() 会创建一个新的图形(figure)和对应的轴(axes)对象。
# 这个函数返回一个元组,第一个元素是图(figure),第二个元素是轴(axes)。
# fig 是用来设置图形的一些全局属性,比如标题、坐标轴范围等。
# ax 是一个包含两个轴的子图对象,可以用于绘制图形。
ax.pie(sex_per, labels=sex_per.index)
#
# 第一个参数是,绘图的数据
# 第二个参数是图中的标签,这句话亦可 ax.pie(sex_per, labels=["male","female"])
ax.set_title("Pie Chart")
plt.show()
# 用于在用户界面中打开一个窗口来显示绘制的图形。
# 如果你在绘图过程中省略了plt.show(),那么图形可能不会以预期的方式显示出来。
# 这是因为plt.show()会触发图形的渲染和显示过程。
# 在一些情况下,例如在Jupyter Notebook或IPython中,plt.show()可能不是必需的,
# 因为图形会自动显示。但在其他环境中,例如在脚本或Python交互式解释器中,使用plt.show()是必要的,否则图形将不会显示。
# 因此,虽然plt.show()不是绝对必需的,但在绘图过程中通常建议使用它以确保图形正确显示。 
# 没有多个子图的时候直接用plt绘图即可
plt.pie(sex_per, labels=sex_per.index)
ax.set_title("Pie Chart")
plt.show() 
3 绘制散点图
绘制一个展示票价 Fare, 与乘客年龄和性别的散点图
# 票价与年龄 的散点图
# 用ax绘图,把横纵坐标的数据输入进去
plt.scatter(df["Fare"],df["Age"])
# 添加标题
plt.title(" Fare vs Age")
# 横坐标的标签
plt.xlabel("Fare")
plt.ylabel("Age")
# 纵坐标的标签
plt.show()
将文字的某一列(“男”和“女”)转成数字
# 使用map,用一个函数进行映射,将字符串转成数字
Sex = df.Sex.map(lambda x: 0 if x=='male' else 1)
Sex
4 绘制直方图
plt.hist(df.Fare)
plt.title("The histogram of Fare")
plt.xlabel("Fare")
plt.ylabel("Frequency") 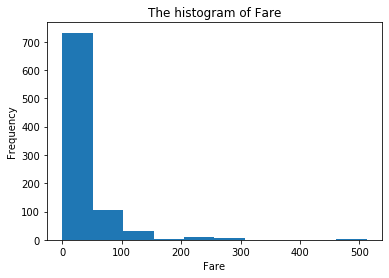
5 柱状图
import matplotlib.pyplot as plt
# 数据
# 每一个柱子的名字
bars = ('A', 'B', 'C', 'D', 'E')
# 横坐标每一个数字,实际的数字
x_pos = range(len(bars))
# 柱子的高度
height = [3, 7, 2, 5, 6]
# 创建柱状图
# 第一个参数写横坐标的真实数字,第二个参数写柱子的高度
plt.bar(x_pos, height)
# x轴上 每个真实的数字,对应的替换的字母名字
plt.xticks(x_pos, bars)
# 显示图像
plt.show()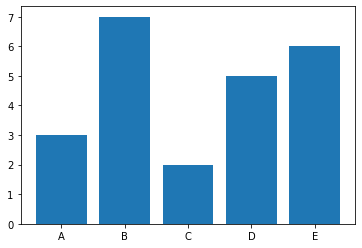
三、wind.data
1 导入数据间距不同的数据集
数据集:https://download.csdn.net/download/Albert233333/88509854
代码:https://download.csdn.net/download/Albert233333/88509873
数据集每一行,列与列之间的的空格数量都不同,
像下面,表头有得间距1个空格,有的间距3个
后面的数据,他为了对齐,有得间距3个空格,有得间距1个空格
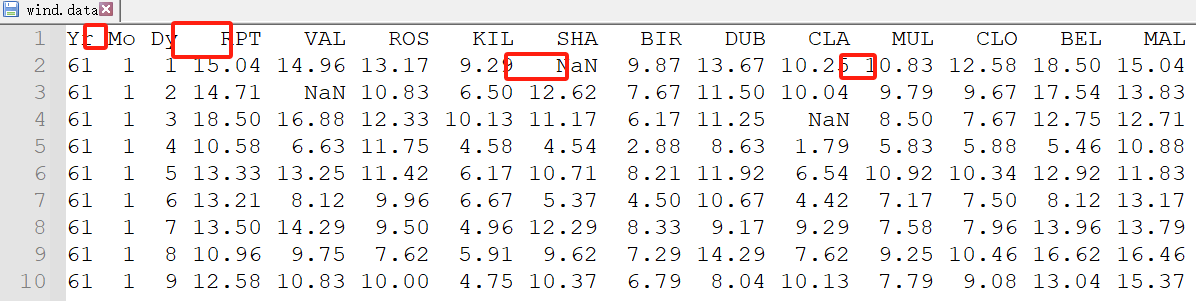
如果强行导入是这样,所有的标题是在一格里,所有的数据都在一格里
df = pd.read_csv("wind.data")
df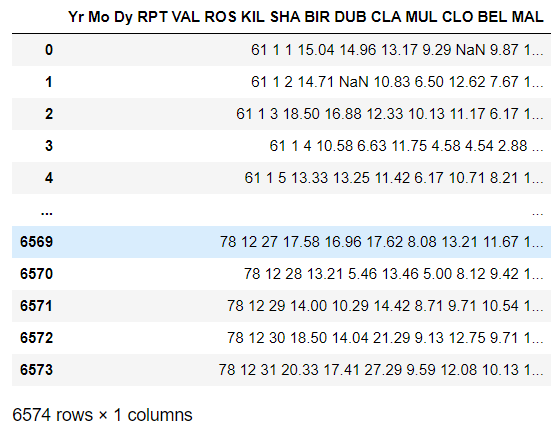
这个时候你发现每一行,每一个格的内容是一个超级长的字符串,字符串里 数据集用 不确定的多个空格分割,长下面这样

先使用pd.Series下面的str的功能把字符串 以 一个空格 来分割 成一个列表
d = df["Yr Mo Dy RPT VAL ROS KIL SHA BIR DUB CLA MUL CLO BEL MAL"].str.split(pat=" ")
d
每一行都是下面这样的列表
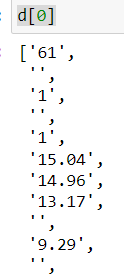
我们可以发现,拆分成的列表,里面有很多个空的字符串。这是因为前面说的 数字和数字之间有时候有1个空格,有时候有2个空格,有的时候3个空格。按照空格拆分,就会拆分出空格和空格之间的 空字符串。
所以需要通过apply函数,对pd.Series中每一个都是用lambda函数,如果不是空格才保留
d = d.apply(lambda x:[i for i in x if i!= ""])
d拆分以后,果真空的的字符串在列表里消失了

这个时候我们发现,d就是一个pd.Series(),每个元素都是一个列表。
我们的目的是希望把数据集转成一个多列多行的DataFrame。像下面这样。每一列表示数据的一个维度
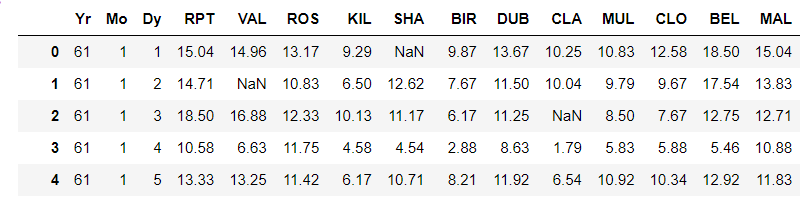
为了实现这个目的,先把这个pd.Series转成一个多维列表,然后再转成DataFrame
# 将一列DataFrame变成多列最好的方式,先转列表,再转DataFrmae
d = pd.DataFrame(list(d))
d
改好column name
# 在Python中,字符串对象的strip()方法是用于删除字符串
# 开头和结尾的空白字符(包括空格、换行符\n、制表符\t等)。
# 具体来说,strip()方法会返回一个新字符串,其中已删除给
# 定字符串的开头和结尾的空白字符。如果字符串中没有空白字符,则返回原始字符串。
col = df.columns[0].split(" ")
# 在Python中,字符串类型的值""(空字符串),被视为布尔类型的False。
# 当使用if语句进行条件判断时,如果条件为False,则不会执行if下面的命令。
# 因此,当i = ""时,i.strip()的结果仍然为"",即布尔类型的False。
# 在if语句中,由于条件为False,因此不会执行if下面的命令。
# 空字符串就删掉了
col = [i for i in col if i.strip()]
col
d.columns = col
d
2 在日期每个数字前,加上19,变成1961
原来的日期是这样的,在前面加上19,变成1961
在字符串“61”前面加上字符串“19”,然后把字符串“1961”转成数字1961
d["Yr"] = d["Yr"].apply(lambda x:int("19"+x))
d
3 将字符串的日期 改为 datetime64类型,并设为索引
将Yr Mo Dy这三列合并成 有年月日 的一列
# 将三列拼接成一列的最好方法
# 这里astype()是把表格中数据转换类型
d["date"] = d["Yr"].astype(str) + "-" + d["Mo"].astype(str) + "-" + d["Dy"].astype(str)
d
# 将date这一列转成datetime64的类型,再替换回去
d["date"] = pd.to_datetime(d["date"])
d
验证是否转成功了
d["date"] # 果然数据类型变成的datetime64的数据类型 
# 将date 这一列设定为index
d.set_index("date") 
4 将数据中字符串的NaN转成np.nan
d = d.set_index("date")
# DataFrame里面所有的数字都是字符串类型,并且有些还是字符串类型的“NaN”,如何迅速将DataFrame中所有的东西的类型转成float类型
d = d.apply(pd.to_numeric, errors='coerce')
d
# 这里apply表示对于DataFrame中每一个元素都执行后面函数里的操作
# pd.to_numeric这个是函数的名字,函数里面对于一个参数的定义写在后面了,“errors='coerce'”
# 正常这个函数是这样用,pd.to_numeric(errors='coerce')
# 在 pd.to_numeric 函数中,参数 errors 可以控制当转换失败时该如何处理。
# 当 errors='coerce' 时,无法成功转换的值会被设置为 NaN(Not a Number)。
# 这是一种比较强硬的错误处理方式,它会直接将无法转换的值从数据集中移除。
# 当 errors='raise' 时,如果遇到无法转换的值,函数会抛出一个错误,并停止执行。
# 这是一种比较保守的处理方式,可以防止错误值污染整个数据集。
5 删除某几列
# axis=1删除一列
d = d.drop(['Yr', 'Mo','Dy'], axis=1)
d 
6 计算每一列的平均值
# 每一个地区这6500天的平均风值
d.mean(axis=0)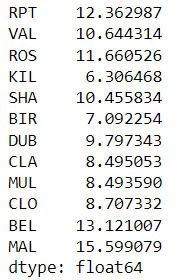
7 有1961-1978年每天的风速数据,要求你计算这18年每年1月的平均风速
先把1月份的数据从这18年的数据总表中取出来
pd.Series自带识别每个日期是几月的功能
pd.Series(d.index).dt.month
先把1月的数据取出来
# 先把date这一列恢复
d = d.reset_index()
# 把第一个月的数据取出来
jan = d[d["date"].dt.month==1]
jan 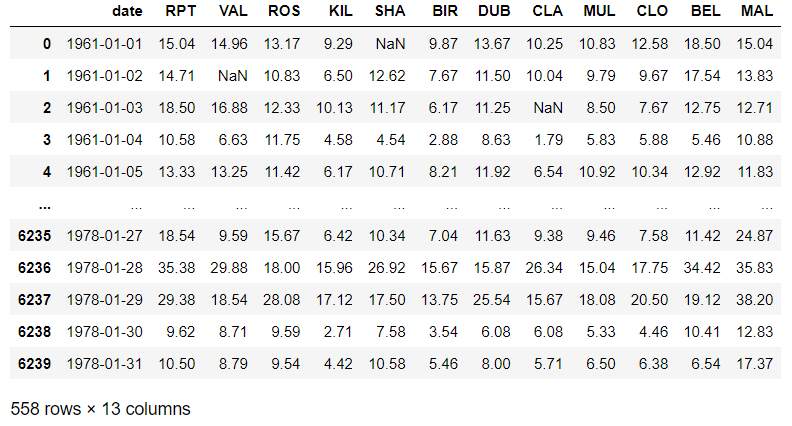
然后再使用groupby按照年来分组,然后按年取平均
jan.groupby(pd.Grouper(key="date",freq="Y")).mean()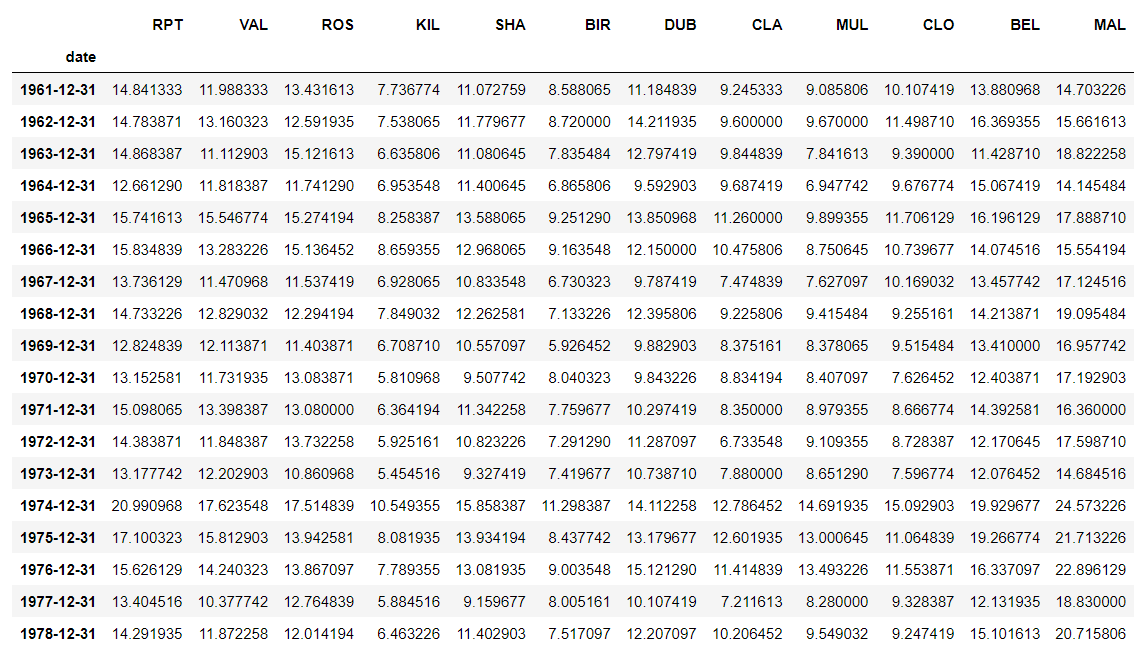
上面这个结果的index我只想显示年份,不想显示月和日,采用下面的操作
pd.Series里面有dt这个功能可以自动提取年份
# 以年份为分组的标准,按年取平均
jan_mean = jan.groupby(pd.Grouper(key="date",freq="Y")).mean()
# 只保留日期中的年 这个数据,月和日移除掉
jan_mean.index = pd.Series(jan_mean.index).dt.year
jan_mean
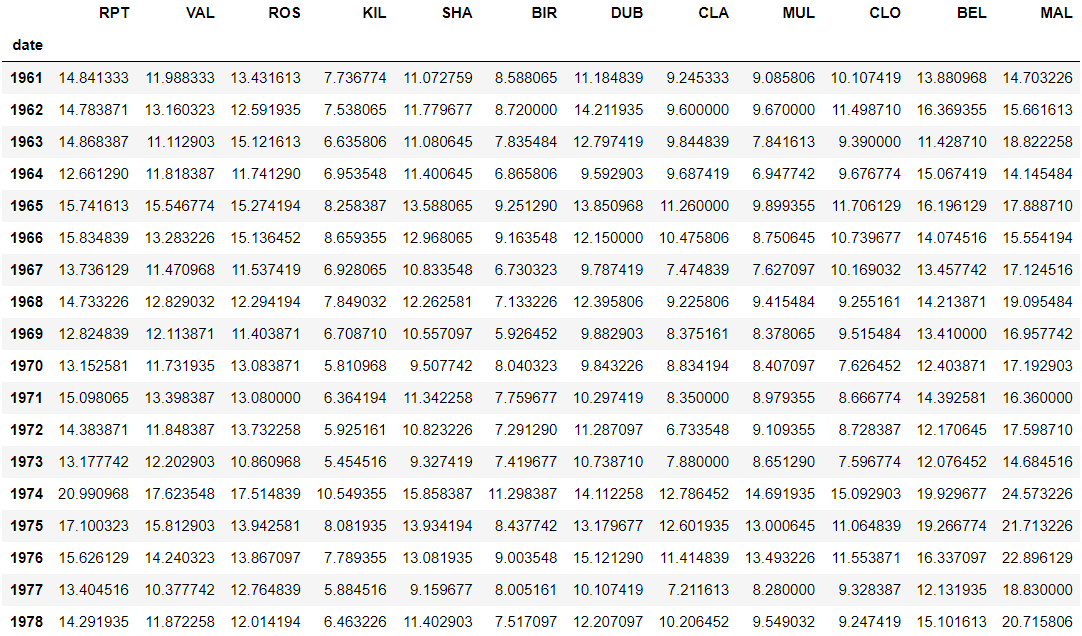
验证一下上面计算的对不对,求一下1961年所有地方的平均风速
可以通过pd.Series.dt来指定年份
jan[jan[["date","RPT"]]["date"].dt.year==1961].mean(axis=0)
# 经过计算上面的结果一样。说明上面计算的结果是对的 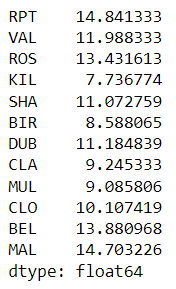
8 对于数据,分别以年、月为频率取样resample
d.resample("M").mean()上面计算一月份平均风速用这个更简便,计算出每个月的平均风速以后,再把一月的取出来即可
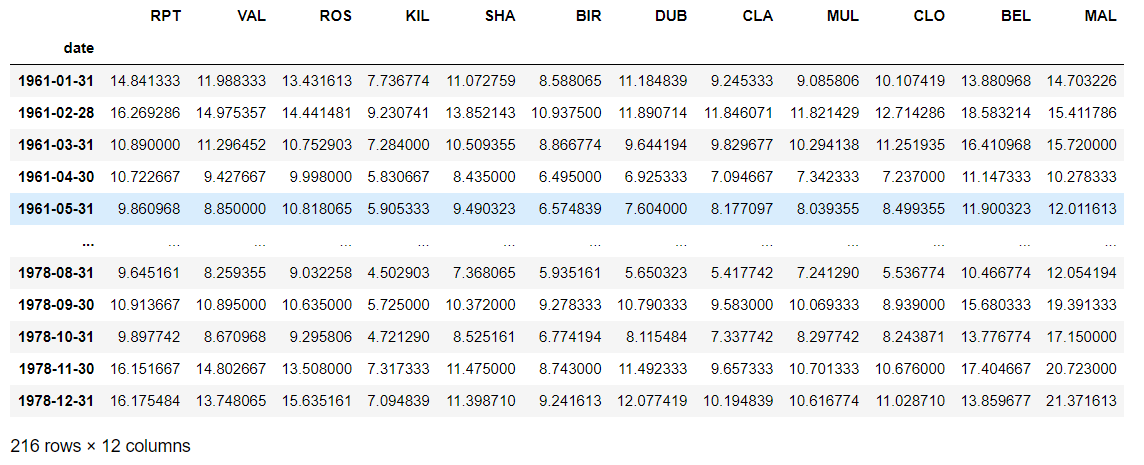
d.resample("Y").mean()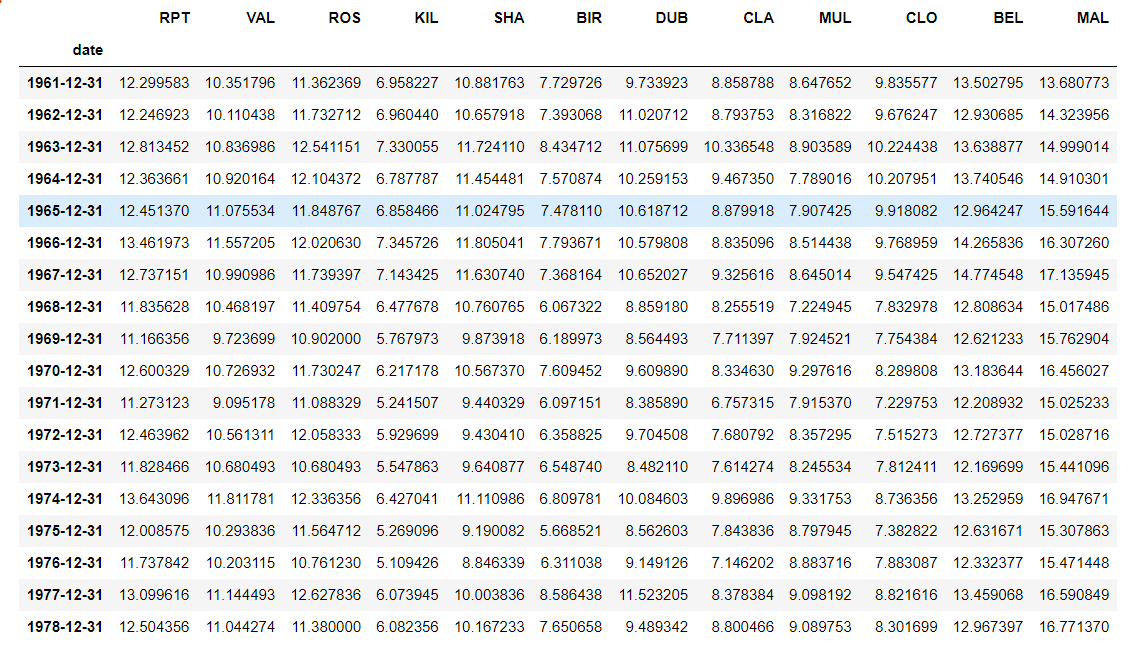
四、 second_cars_info.csv
数据集:https://download.csdn.net/download/Albert233333/88510316
代码:https://download.csdn.net/download/Albert233333/88510323
数据集长这样
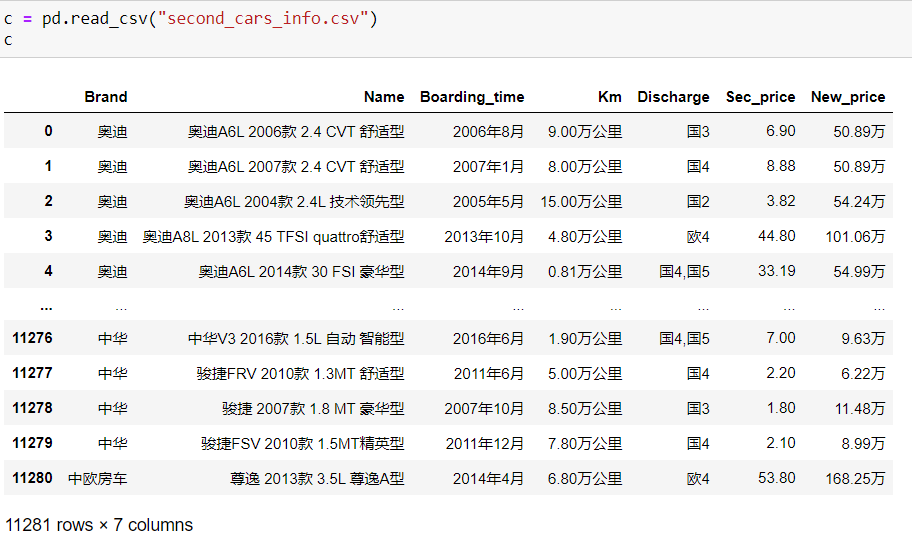
1 选取上牌日期在2015年1月1日到2016年1月1日的数据
Boarding_time本来是这样,string类型的
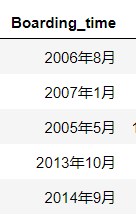
按照字符串的年和月解析,把年和月的数字解析出来,转成datetime64格式
未上牌的,先转成np.nan
# 用replace函数将前面的替换成后面的
c["Boarding_time"]= c["Boarding_time"].replace("未上牌",np.nan)转datetime64
# 因为“Boarding_time”中
# 将Boarding_time这一列从“2011年5月”这种带汉字的文字格式转换成datetime64
# 第一个参数是被转换的原始数据,第二个参数是这一列里面日期的格式。代码会根据这个格式自动转换
c["Boarding_time"] = pd.to_datetime(c["Boarding_time"],format="%Y年%m月")
# 你也可以直接用下面这句话,就不需要做前面replace这一步了。直接将不可转换的东西替换成np.nan
# c["Boarding_time"] = pd.to_datetime(c["Boarding_time"],format="%Y年%m月", errors="coerce")选取上牌日期在2015年1月1日到2016年1月1日的数据
c[(c["Boarding_time"]>"2015-01-01") & (c["Boarding_time"]<"2016-01-01")]
# 你注意上面的运算符不能使用and,因为这样Python会试图对整个表达式进行求值,继而引发报错
# 你应该使用为DataFrame和Series是自己的逻辑运算方法 &
# 更便捷的是使用pandas内置的方法来实现.一句话搞定
# df_filtered = c[c['Boarding_time'].between(pd.to_datetime('2014-01-01'), pd.to_datetime('2015-01-01'))] 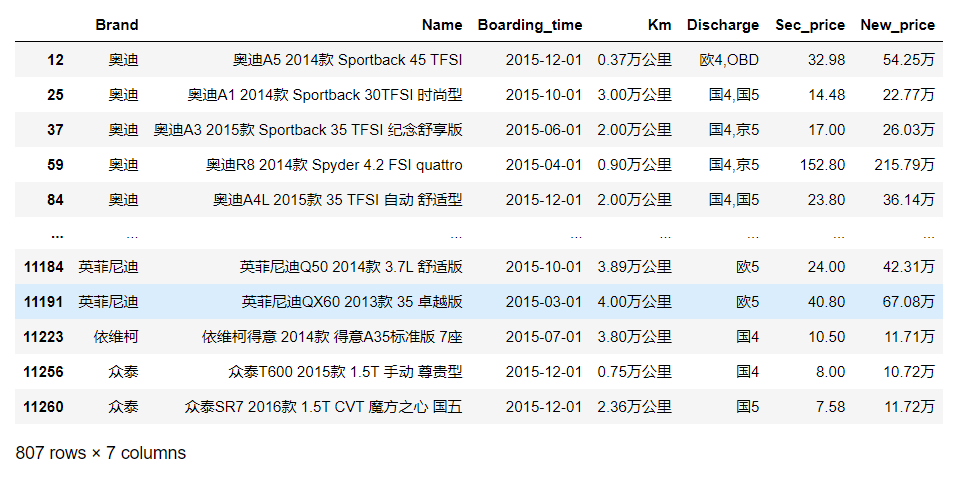
2 写个函数构建查询引擎,收入对于每个维度的条件,把符合条件的dataframe筛选出来
这函数用于将你输入的 >=某个条件 转化成有True和False的掩码表
def parse_operator(oprt,col,num):
if oprt == '>=':
# return lambda x, y: col >= num
return col >= num
elif oprt == '<=':
# return lambda x, y: col <= num
return col <= num
# 添加其他运算符...
else:
raise ValueError('Invalid operator.\n大小一律只许 >= 和 <= 不允许有其他的符号\n两个条件之间用 " and "连接,\n大于号或小于号在左边,数字在右边')
# 如果你只想有一个条件,请写两个完全相同条件进去,比如Km=">=5 and >=5"即可')
根据你的两个条件输出 最终的 mask掩码表
# c是原始数据
# oprt_s是进来的那个运算符的字符串
# col_name 是要按照条件去的那一列的 列名
#
def mask_gen(c, oprt_s,col_name,if_date=False):
# 注意这里不可以使用if Km != no_rq:,因为no_rq是一个pd.Series,
# 不能用python的运算符,判断与这个类型是否相等应该用equals,也就是下面这句话
if not no_rq.equals(oprt_s): # 判断Km不是全是True的一个Series,也就是有一些条件在里面
# 上面这句话也可以用if isinstance(Km, str),效果一样
# print("1"*100)
# 默认的格式是要求填入两个条件,拆分成两个字符串
s1, s2= oprt_s.split(" and ")
# 将每一个条件,拆分成 >= 和 数字
# print(s1[2:])
# print(s2[2:])
oprt1, oprt2 = s1[0:2], s2[0:2]
# 如果说不是日期,正常转float即可
if not if_date:
num1, num2 = float(s1[2:]), float(s2[2:])
# 如果是日期,就直接用原始的字符串即可
else:
num1, num2 = s1[2:], s2[2:]
# 分别得到两个条件的mask表
mask1 = parse_operator(oprt1, c[col_name], num1)
mask2 = parse_operator(oprt2, c[col_name], num2)
# print(mask1)
# print(mask2)
mask= (mask1 & mask2)
# print(mask)
return mask最终写好的engine函数
# 第一个参数表示输入进去的数据,全是True
# 第二个参数用index来调整整个Series的大小
# c.shape[0] 表示True的行数
no_rq = pd.Series(True, index=range(c.shape[0]))
# 如果你默认不输入这个条件,就获取到这个条件所有的数据,变成一个全是True的Series即可
def engine(c,Brand=no_rq, Name=no_rq, Boarding_time=no_rq, Km=no_rq, Discharge=no_rq, Sec_price=no_rq, New_price=no_rq):
# 直接按字符匹配的有Brand,Name,Discharge
# 如果这项条件你都定义了才做条件筛选
if isinstance(Brand,str):
Brand = c["Brand"]==Brand
if isinstance(Name,str):
Name = c["Name"]==Name
if isinstance(Discharge, str):
Discharge = c["Discharge"]==Discharge
# 其他需要匹配大小和区间的变量:Km,Sec_price,New_price
# print(Km)
if isinstance(Km, str):
Km = mask_gen(c,Km,"Km")
if isinstance(Sec_price,str):
Sec_price = mask_gen(c, Sec_price,"Sec_price")
if isinstance(New_price,str):
New_price = mask_gen(c, New_price,"New_price")
if isinstance(Boarding_time,str):
Boarding_time = mask_gen(c,Boarding_time,"Boarding_time",if_date=True)
# 每个变量的两个条件和一个条件的情况,首先识别,其次两个条件的要合并
# 最后,不同的条件,如何同时起作用。 把这些条件的掩码表,& 在一起,即可
# results = c[Brand & Name & Discharge & Boarding_time & Km & Discharge & Sec_price & New_price]
results = c[Brand & Name & Discharge & Km & Sec_price & New_price & Boarding_time]
return(results)
# engine(c,Brand="奥迪",
# Name="奥迪A6L 2014款 30 FSI 豪华型",
# Discharge="国4,国5",
# Km=">=0.01 and <=1"
# )
#
engine这样使用,使用的规则写在下面的注释里面了
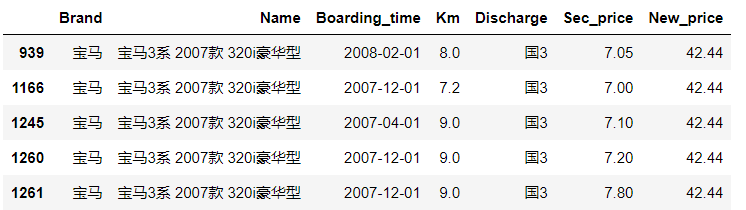
engine(c,
Name="宝马3系 2007款 320i豪华型",
Km=">=7 and <=9",
Sec_price=">=7 and <=9",
New_price=">=40 and <=50",
Boarding_time=">=2007-01-01 and <=2008-08-31")
# 大小一律只许 >= 和 <= 不允许有其他的符号,两个条件之间用 " and "连接, 大于号或小于号在左边,数字在右边
# 如果你只想有一个条件,请写两个完全相同条件进去,比如Km=">=5 and >=5"即可
# 注意关于日期,必须按照这个日期的格式进行输入"2015-01-01"按照上面写的条件,识别出来的复合条件的数据如下