在这个深度学习项目中,我们将对人类面部表情进行分类,以过滤和映射相应的表情符号或头像。
数据集(面部表情识别)由48*48像素的灰度人脸图像组成。图像居中并占据相等的空间。该数据集由以下类别的面部情绪组成:
0:生气
1:厌恶
2:壮举
3:快乐
4:悲伤
5:惊喜
6:自然
下载项目代码:click or click
环境搭建
python版本我们选择3.9~3.11:python-3.11.5-amd64.exe
因为我们的tensorflow库需要与python版本相对应
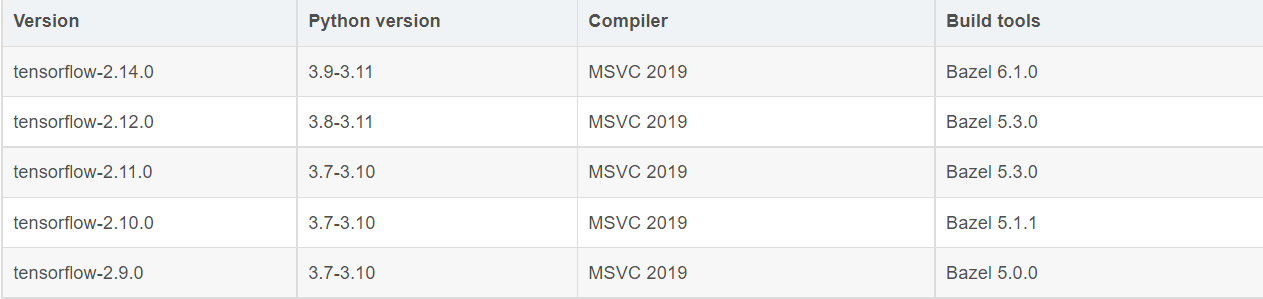
pycharm 我们选择专业版功能多:pycharm-professional-2023.2.3.exe
转载:具体安装详细教程:Python安装教程(新手)
我们将构建一个深度学习模型,从图像中对面部表情进行分类。然后,我们将分类的情感映射到表情符号或头像。
部署项目
没有相应的模块自己pip安装吧
1、首先运行train.py训练模型
等待训练完成生成emotion_model.h5

2、接下运行gui.py测试
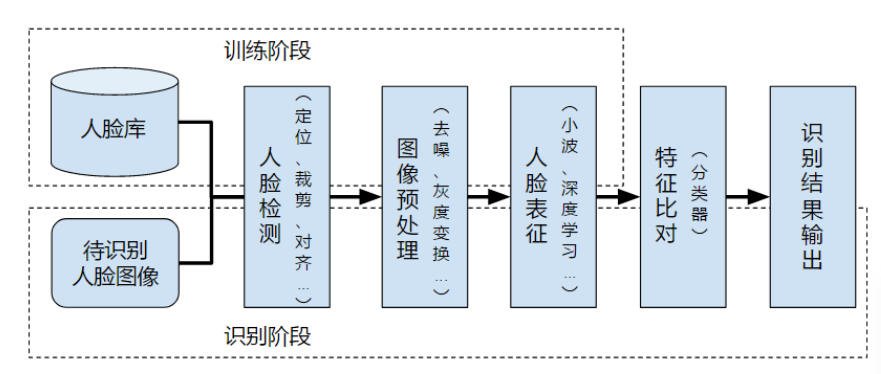
一、使用 CNN 进行面部情绪识别
在以下步骤中,将构建卷积神经网络架构,并在数据集上训练模型FER2013以便从图像中进行情感识别。从上面的链接下载数据集。将其提取到具有单独训练和测试目录的数据文件夹中。
1、import
import numpy as np
import cv2
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D
from keras.optimizers import Adam
from keras.layers import MaxPooling2D
from keras.preprocessing.image import ImageDataGenerator
- numpy: 用于在Python中进行数值计算的库。
- cv2: OpenCV库,用于计算机视觉任务,例如图像处理和人脸检测。
- Sequential, Dense, Dropout, Flatten, Conv2D, MaxPooling2D:
这些是Keras库中用于构建卷积神经网络(CNN)的类。 - Adam: 优化算法,用于训练神经网络。
- ImageDataGenerator: 用于在训练期间生成图像数据的类。
2、初始化训练
train_dir = 'train'
val_dir = 'test'
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)
- train_dir 训练集 val_dir验证集
- ImageDateGenerator:是Keras提供的用于图像数据生成的类,它允许你通过图像进行多种处理来增强数据集,同时也支持对数据进行标准化。
- rescale=1./255:图像标准化,将图像的每个像素除以255,将像素缩放到0,1范围内。标准化有助于保证神经网络的输入数据在一个相对较小的范围内,提高训练的稳定性。
3、验证生成器
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(48,48),
batch_size=64,
color_mode="grayscale",
class_mode='categorical')
validation_generator = val_datagen.flow_from_directory(
val_dir,
target_size=(48,48),
batch_size=64,
color_mode="grayscale",
class_mode='categorical')
- flow_from_directory:用于从目录中加载图像并生成批量的数据。该方法适用于处理大量图像数据,适用于计算机视觉任务
- train_dir:目标目录的路径,每一个类别一个字文件夹
- target_size=(48,48):将图像调整为48*48像素大小
- batch_size=64:每次生成器生成64个图像
- color_mode=“grayscale”:指定图像的颜色模式,采用灰度模式 ,表示图像是单通道的灰度图像。灰度图像只有亮度信息,不包括颜色信息,对于人脸表情识别,使用灰度图像足够,并且减少了计算的复杂度
- class_mode=‘categorical’:指定返回的标签组的类型。采用了categorical,表示返回的标签是one-hot编码的类别标签。这种编码方式适用于多类别分类任务。
3、构建卷积网络架构
emotion_model = Sequential()
emotion_model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(48,48,1)))
emotion_model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
emotion_model.add(MaxPooling2D(pool_size=(2, 2)))
emotion_model.add(Dropout(0.25))
emotion_model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
emotion_model.add(MaxPooling2D(pool_size=(2, 2)))
emotion_model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
emotion_model.add(MaxPooling2D(pool_size=(2, 2)))
emotion_model.add(Dropout(0.25))
emotion_model.add(Flatten())
emotion_model.add(Dense(1024, activation='relu'))
emotion_model.add(Dropout(0.5))
emotion_model.add(Dense(7, activation='softmax'))
# emotion_model.load_weights('emotion_model.h5')
- emotion_model = Sequential():定义了一个线性的层堆栈,适用于简单的层序列结构
- 第一个卷积层(Conv2D)——使用了32个卷积核,每个卷积核大小为(3,3)——激活函数使用了ReLU,这是一种常用于卷积神经函数的非线性激活函数——input_shape=(48, 48, 1):指定了输入图像的大小,并且是灰度图像
- 第二个卷积层(Conv2D)——使用了64个卷积核,每个卷积核大小为(3,3)——同样使用了ReLU激活函数
- 最大池化层(MaxPooling2D)——采用(2,2)池化窗口,将特征图的尺寸减小一半
- Dropout层——随机丢掉20%的神经元,有助于减少过拟合
4、编译和训练模型
cv2.ocl.setUseOpenCL(False)
emotion_dict = {
0: "Angry", 1: "Disgusted", 2: "Fearful", 3: "Happy", 4: "Neutral", 5: "Sad", 6: "Surprised"}
emotion_model.compile(loss='categorical_crossentropy',optimizer=Adam(learning_rate=0.0001),metrics=['accuracy'])
emotion_model_info = emotion_model.fit_generator(
train_generator,
steps_per_epoch=28709 // 64,
epochs=50,
validation_data=validation_generator,
validation_steps=7178 // 64)
- cv2.ocl.setUseOpenCL(False):禁用OpenCL加速,在OpenCV中,当OpenCL可用时,它会尝试使用GPU进行一些操作,以提高性能。然而在某些环境或硬件配置下,OpenCL会导致一些问题
- emotion_dict:定义了表情字典,上面我们说的6个表情+1自然
- compile:方法用于配置模型的学习过程——使用了交叉损失函数categorical_crossentropy作为损失函数——Adam优化器learning_rate=0.0001学习率较小,模型参数更新步幅越小——精度accuracy作为评估指标
- fit_generator:从生成器中获取批量数据进行训练——train_generator训练数据的生成器——steps_per_epoch:每个训练周期(epoch)中迭代的步数通常是训练集样本数除以批次大小——epochs训练的周期数,表示模型将遍历整个训练集的—— validation_data验证数据生成器——validation_steps验证周期的迭代次数
5、保存模型权重
emotion_model.save_weights('emotion_model.h5')
6、使用openCV haarcascade xml检测网络摄像头中面部的边界框并预测情绪
cap = cv2.VideoCapture(0)
while True:
# 查找haar级联以在面部周围绘制边界框
ret, frame = cap.read()
if not ret:
break
# 此处为自己文件夹下的haarcascade_frontalface_default.xml需要自己修改
bounding_box = cv2.CascadeClassifier('E:\pycharm_python\\venv\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2gray_frame)
num_faces = bounding_box.detectMultiScale(gray_frame,scaleFactor=1.3, minNeighbors=5)
for (x, y, w, h) in num_faces:
# 人脸周围绘制蓝色矩形框
cv2.rectangle(frame, (x, y-50), (x+w, y+h+10), (255, 0, 0), 2)
# 提取人脸区域
roi_gray_frame = gray_frame[y:y + h, x:x + w]
# 调整人脸图像大小
cropped_img = np.expand_dims(np.expand_dims(cv2.resize(roi_gray_frame, (48, 48)), -1), 0)
# 使用预先训练的 emotion_model 模型对提取的人脸进行情感预测
emotion_prediction = emotion_model.predict(cropped_img)
# 预测结果
maxindex = int(np.argmax(emotion_prediction))
# 绘制在图像上
cv2.putText(frame, emotion_dict[maxindex], (x+20, y-60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('Video', cv2.resize(frame,(1200,860),interpolation = cv2.INTER_CUBIC))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
- cap = cv2.VideoCapture(0):创建名为cap的OpenCV视频捕捉对象,用于从计算机摄像头获取视频流。参数0表示使用默认的摄像头设备
- ret, frame = cap.read():使用cap对象读取一帧图像数据,ret是一个布尔值,表示是否成功读取了一帧图像成功True失败False——frame标签当前帧的图像数据
- cv2.CascadeClassifier:加载Haar级联分类器用于人脸检测,haarcascade_frontalface_default.xml训练好的人脸检测模型
- cv2.cvtColor:将彩色图像frame(BGR格式)转换为灰度图像cv2.COLOR_BGR2GRAY
- detectMultiScale:在灰度图像(gray_frame)上检测人脸——scaleFactor图像缩放比例,控制了图像尺度的变化,用于检测不同大小的人脸——minNeighbors每个候选矩形框应该拥有的邻居数,可以过滤掉一些可能的噪声或有误检测。
- cv2.imshow:显示图像,Video窗口标题——(1200,800)图像大小——cv2.INTER_CUBIC 是插值方法,用于在调整大小时平滑图像。
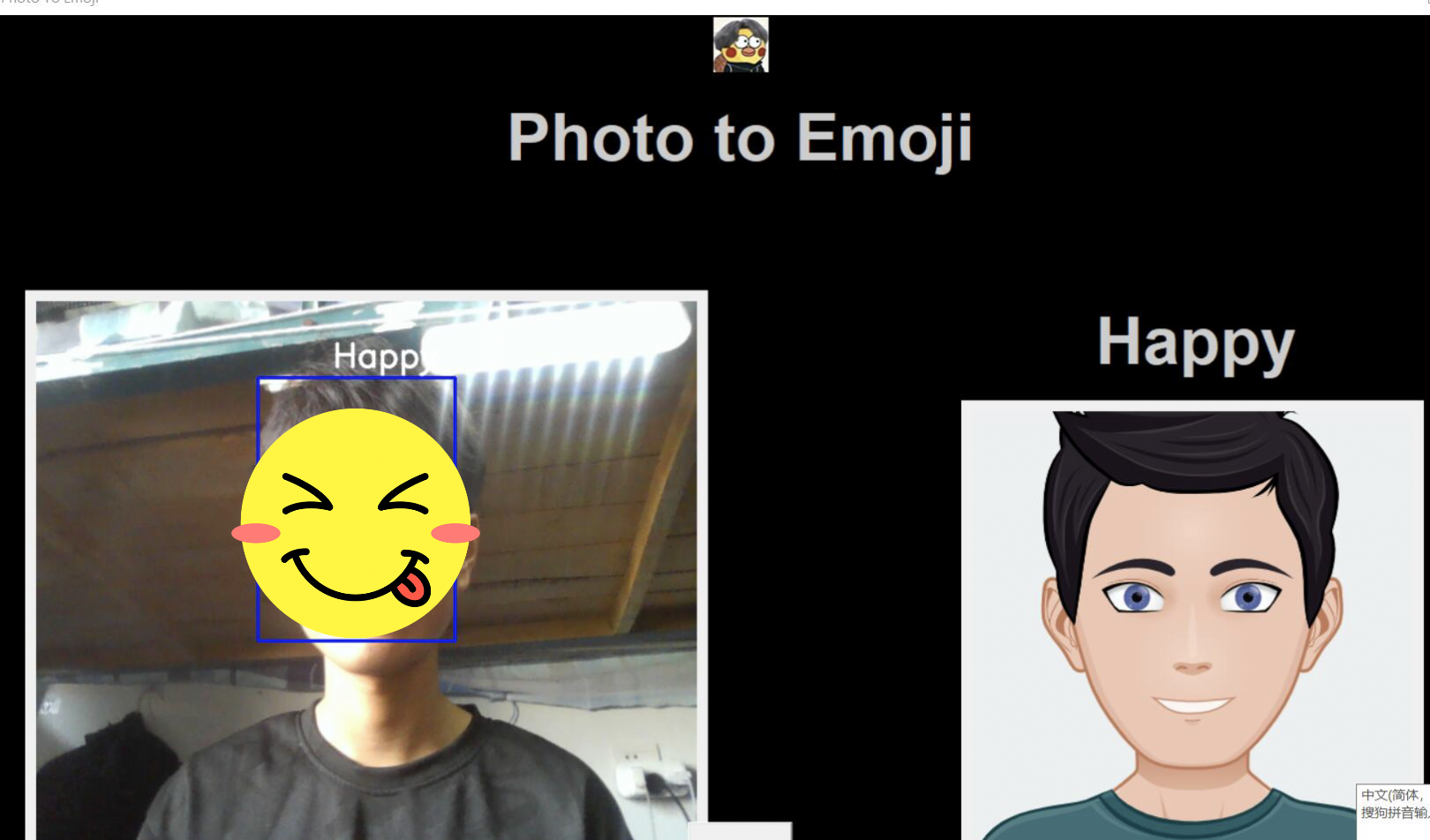
二、GUI 代码和表情符号映射
创建一个名为 emojis 的文件夹,并将与数据集中七种情绪中的每一种对应的表情符号保存在一起
将以下代码粘贴到 gui.py 中并运行该文件
1、导入库
import tkinter as tk
from tkinter import *
import cv2
from PIL import Image, ImageTk
import numpy as np
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Flatten
- thinker:模块(Tk 接口)是 Python 的标准 Tk GUI 工具包的接口 .Tk 和 Tkinter 可以在大多数的 Unix 平台下使用,同样可以应用在 Windows 和 Macintosh 系统里。Tk8.0 的后续版本可以实现本地窗口风格,并良好地运行在绝大多数平台中
- PIL:全称 Python Imaging Library,是 Python 平台一个功能非常强大而且简单易用的图像处理库。
- keras:深度学习框架
2、数据初始化
cv2.ocl.setUseOpenCL(False)
emotion_dict = {
0: " Angry ", 1: "Disgusted", 2: " Fearful ", 3: " Happy ", 4: " Neutral ",
5: " Sad ", 6: "Surprised"}
emoji_dist = {
0: "../emojis/angry.png", 1: "../emojis/disgusted.png",
2: "../emojis/fearful.png", 3: "../emojis/happy.png",
4: "../emojis/neutral.png", 5: "../emojis/sad.png",
6: "../emojis/surpriced.png"}
- 禁止OpenCL启动,用CPU计算
- 定义情绪字典
- 定义表情字典
3、定义一个层级架构
emotion_model = Sequential()
emotion_model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(48, 48, 1)))
emotion_model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
emotion_model.add(MaxPooling2D(pool_size=(2, 2)))
emotion_model.add(Dropout(0.25))
emotion_model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
emotion_model.add(MaxPooling2D(pool_size=(2, 2)))
emotion_model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
emotion_model.add(MaxPooling2D(pool_size=(2, 2)))
emotion_model.add(Dropout(0.25))
emotion_model.add(Flatten())
emotion_model.add(Dense(1024, activation='relu'))
emotion_model.add(Dropout(0.5))
emotion_model.add(Dense(7, activation='softmax'))
emotion_model.load_weights('emotion_model.h5')
4、全局变量
global last_frame1
last_frame1 = np.zeros((480, 640, 3), dtype=np.uint8)
global cap1
show_text = [0]
exit_flag = False # 退出标志
- np.zeros:创建多维数组来生成图像。特别对于空白、黑色、白色、随机等特殊图像,用 Numpy 创建图像非常方便。
5、人脸识别函数
def show_vid_combined():
global last_frame1, exit_flag
cap1 = cv2.VideoCapture(0)
if not cap1.isOpened():
print("摄像头没打开")
return
else:
print('摄像头已经打开')
while not exit_flag:
flag1, frame1 = cap1.read()
frame1 = cv2.resize(frame1, (600, 500))
bounding_box = cv2.CascadeClassifier(
'E:\\pycharm_python\\venv\\Lib\\site-packages\\cv2\\data\\haarcascade_frontalface_default.xml')
gray_frame = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
num_faces = bounding_box.detectMultiScale(gray_frame, scaleFactor=1.3, minNeighbors=5)
for (x, y, w, h) in num_faces:
# 人脸周围绘制蓝色矩形框
cv2.rectangle(frame1, (x, y - 50), (x + w, y + h + 10), (255, 0, 0), 2)
# 提取人脸区域
roi_gray_frame = gray_frame[y:y + h, x:x + w]
# 调整人脸图像大小
cropped_img = np.expand_dims(np.expand_dims(cv2.resize(roi_gray_frame, (48, 48)), -1), 0)
# 使用预先训练的 emotion_model 模型对提取的人脸进行情感预测
prediction = emotion_model.predict(cropped_img)
# 预测结果
maxindex = int(np.argmax(prediction))
cv2.putText(frame1, emotion_dict[maxindex], (x + 20, y - 60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255),2, cv2.LINE_AA)
show_text[0] = maxindex
if flag1 is not None:
# 当前捕获的帧 frame1 复制给 last_frame1
last_frame1 = frame1.copy()
# 将 last_frame1 从 BGR 格式转换为 RGB 格式
pic = cv2.cvtColor(last_frame1, cv2.COLOR_BGR2RGB)
# 将 NumPy 数组转换为图像对象
img = Image.fromarray(pic)
# 将 PIL 图像对象转换为 Tkinter 图像对象,以便在 Tkinter 窗口中显示
imgtk = ImageTk.PhotoImage(image=img)
# lmain(Tkinter 中的 Label 控件)的 imgtk 属性设置为新的 Tkinter 图像对象。
lmain.imgtk = imgtk
# 用 configure 方法更新 lmain 的图像,实现图像的实时显示
lmain.configure(image=imgtk)
cap1.release()
# 调度 show_vid_combined
# 周期性地调度执行 show_vid_combined 函数,实现了实时更新图像的效果。每隔 10 毫秒,就会调用一次函数
root.after(10, show_vid_combined)
6、表情显示函数
def show_vid2():
if show_text[0] in emoji_dist:
frame2 = cv2.imread(emoji_dist[show_text[0]])
if frame2 is not None:
pic2 = cv2.cvtColor(frame2, cv2.COLOR_BGR2RGB)
img2 = Image.fromarray(pic2)
imgtk2 = ImageTk.PhotoImage(image=img2)
lmain2.imgtk2 = imgtk2
lmain3.configure(text=emotion_dict[show_text[0]], font=('arial', 45, 'bold'))
lmain2.configure(image=imgtk2)
else:
print('无法加载图像')
else:
print('表情文件不存在')
# 调度 show_vid2
root.after(10, show_vid2)
7、主函数
if __name__ == '__main__':
root = tk.Tk()
img = ImageTk.PhotoImage(Image.open("logo.png"))
heading = Label(root, image=img, bg='black')
heading.pack()
heading2 = Label(root, text="Photo to Emoji", pady=20, font=('arial', 45, 'bold'), bg='black', fg='#CDCDCD')
heading2.pack()
lmain = tk.Label(master=root, padx=50, bd=10)
lmain2 = tk.Label(master=root, bd=10)
lmain3 = tk.Label(master=root, bd=10, fg="#CDCDCD", bg='black')
lmain.pack(side=LEFT)
lmain.place(x=50, y=250)
lmain3.pack()
lmain3.place(x=960, y=250)
lmain2.pack(side=RIGHT)
lmain2.place(x=900, y=350)
root.title("Photo To Emoji")
root.geometry("1400x800+100+10")
root['bg'] = 'black'
exitbutton = Button(root, text='Quit', fg="red", command=root.destroy, font=('arial', 25, 'bold')).pack(side=BOTTOM)
# 调度 show_vid_combined 和 show_vid2
root.after(10, show_vid_combined)
root.after(10, show_vid2)
root.mainloop()