1、基本模块
urllib库是Python内置的HTTP请求库。无需额外安装,可以直接使用。urllib库包含以下四个模块。
- request:最基本的HTTP请求模块,可以模拟请求的发送。只需给该库方法传入URL以及对应的参数,就可以模拟浏览器发送请求了。
- error:异常处理模块。如果出现请求异常,我们可以捕获这些异常,然后进行重试或其他操作保证程序运行不会意外终止。
- parse:一个工具模块。提供了许多URL的处理方法,如拆分、解析、合并等。
- robotparser:主要用来识别网站的robot.txt文件,判断哪些网站可以爬,哪些网站不可以,一般使用较少。
2、发送请求(request)
urlopen
request提供了构造HTTP请求的最基本方法,我们可以利用urlopen模拟浏览器发起请求的过程。
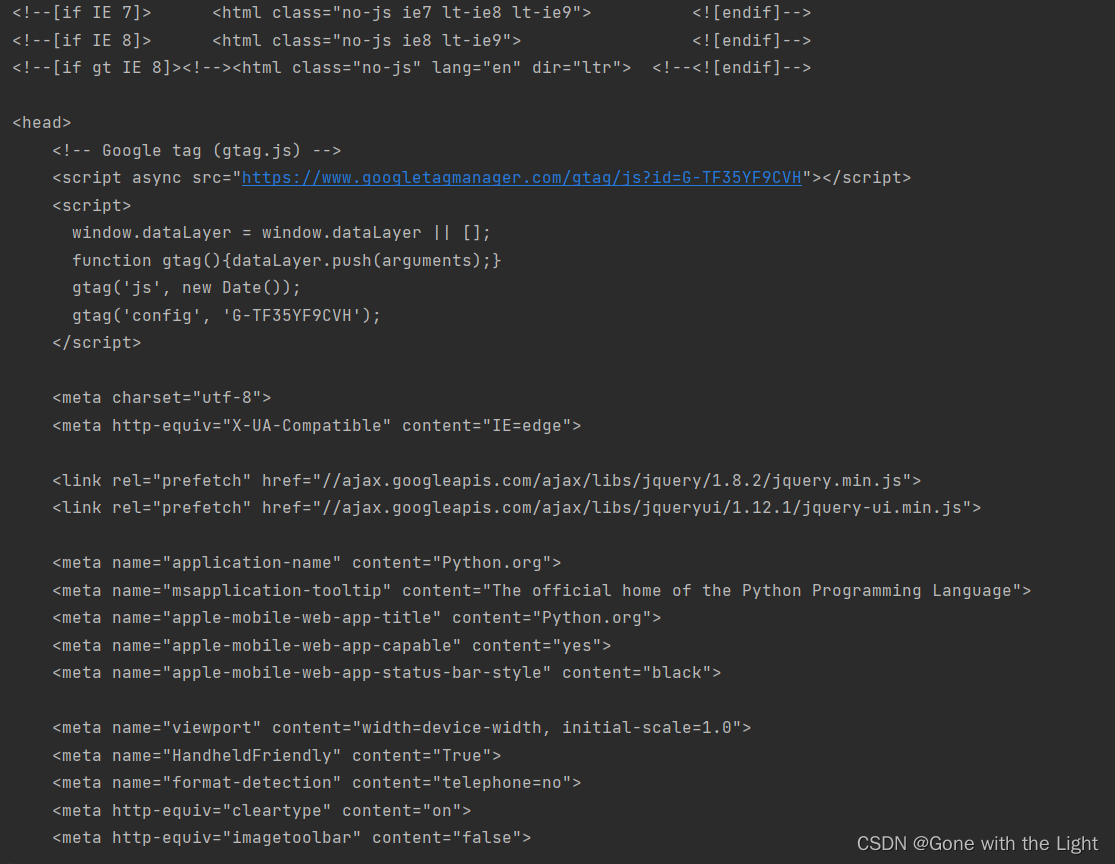
from urllib import request
response = request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))
运行结果如下
我们可以利用type方法查看响应的类型
from urllib import request
response = request.urlopen('https://www.python.org')
print(type(response))
输出结果为:
<class ‘http.client.HTTPResponse’>
由此可知,响应是一个HTTPResponse类型的对象。
HTTPResponse主要包含read、readinto、getheader、getheaders、fileno等方法,以及msg、version、status、reason、debuglevel、closed等属性,下面取部分举例说明。
from urllib import request
response = request.urlopen('https://www.python.org')
print(response.status)#status属性,输出响应状态码
print(response.getheaders())#调用getheaders方法,输出响应头信息
输出结果为:
200
[(‘Connection’, ‘close’), (‘Content-Length’, ‘49948’), (‘Server’, ‘nginx’), (‘Content-Type’, ‘text/html; charset=utf-8’), (‘X-Frame-Options’, ‘SAMEORIGIN’), (‘Via’, ‘1.1 vegur, 1.1 varnish, 1.1 varnish’), (‘Accept-Ranges’, ‘bytes’), (‘Date’, ‘Tue, 27 Jun 2023 13:08:24 GMT’), (‘Age’, ‘3329’), (‘X-Served-By’, ‘cache-iad-kiad7000025-IAD, cache-nrt-rjtf7700041-NRT’), (‘X-Cache’, ‘HIT, HIT’), (‘X-Cache-Hits’, ‘57, 1722’), (‘X-Timer’, ‘S1687871304.488935,VS0,VE0’), (‘Vary’, ‘Cookie’), (‘Strict-Transport-Security’, ‘max-age=63072000; includeSubDomains; preload’)]
我们还可以给urlopen方法传递其他的参数,urlopen方法的API如下:
request.urlopen( url , data=None , [timeout]* , cafile=None , capath=None , cadefault=False , context=None)
- data参数
使用data参数时,需要使用bytes方法将参数转化为字节流编码格式的内容(即bytes类型)。如果传递了该参数,则它的请求方式将由GET转为POST。下面举例说明。
from urllib import request, parse
data = bytes(parse.urlencode({
'name': 'python'}), encoding='utf-8')
#使用bytes方法将参数转化为字节流编码格式的内容(即bytes类型)
#传入第一个参数name,值为python,用urlencode方法将字典参数转换为符合URL规范的查询字符串
#第二个参数encoding用于指定编码格式
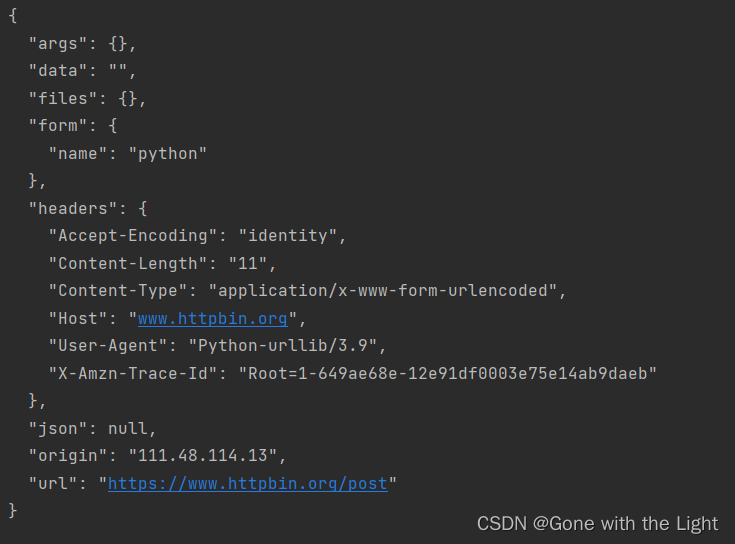
response = request.urlopen('https://www.httpbin.org/post', data=data)
print(response.read().decode('utf-8'))
我们此次的请求站点为www.httpbin.org,它可以提供HTTP请求测试。在后面加上/post则可以用来测试post请求。输出的信息中就包含我们传递的data参数。
运行结果如下:
- timeout参数
timeout参数用于设置超时时间,单位为秒,当请求超出了设定的时间,还没有得到响应,就会抛出异常。如果不指定参数,则会使用全局默认时间。我们可以利用timeout实现当一个网页长时间未响应时,就跳过对它的抓取。
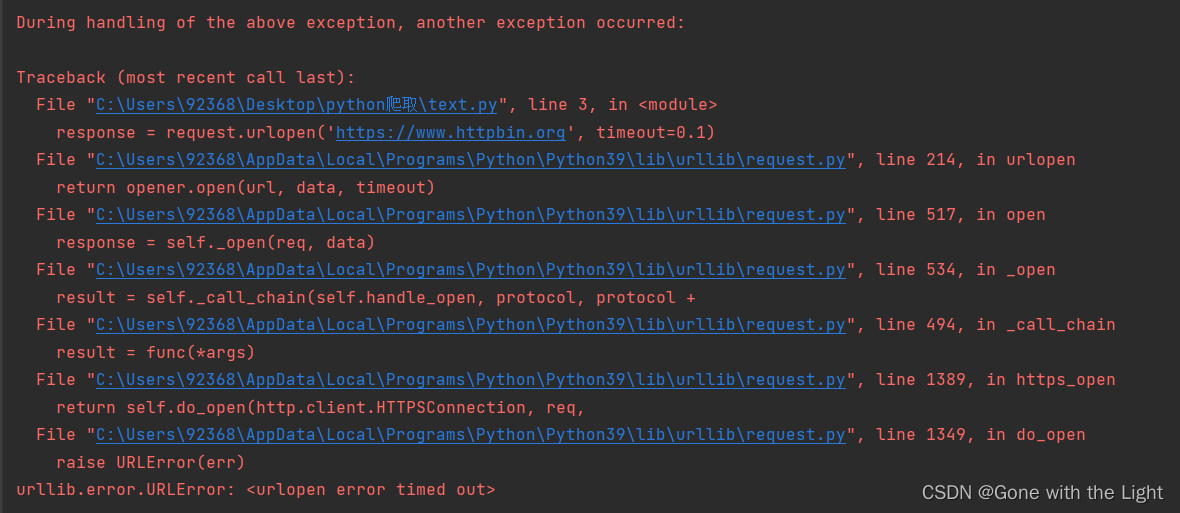
from urllib import request
response = request.urlopen('https://www.httpbin.org', timeout=0.1)
#0.1秒几乎不可能得到服务器的响应
print(response.read())
运行错误,原因为超时:
- 其他参数
cafile和capath分别用来指定CA证书及其路径。cadefault现在已弃用,其默认值为False。context参数必须是ssl.SSLContext类型,用来指定SSL的设置。
Request
我们可以通过Request创建一个Request类型的对象,再将该对象作为参数传入urlopen方法,这样urlopen方法的参数就可以灵活地配置参数了。Request类的构造方法如下:
class request.Request(url , data = None , headers = { } , origin_req_host = None , unverifiable = False , method = None)
-
url
用于请求的URL,为必传参数,其他的均为选传参数。 -
data
需要转换为bytes类型。如果数据是字典,可用urllib.parse模块里的urlencode方法将字典参数转换为符合URL规范的查询字符串。 -
headers
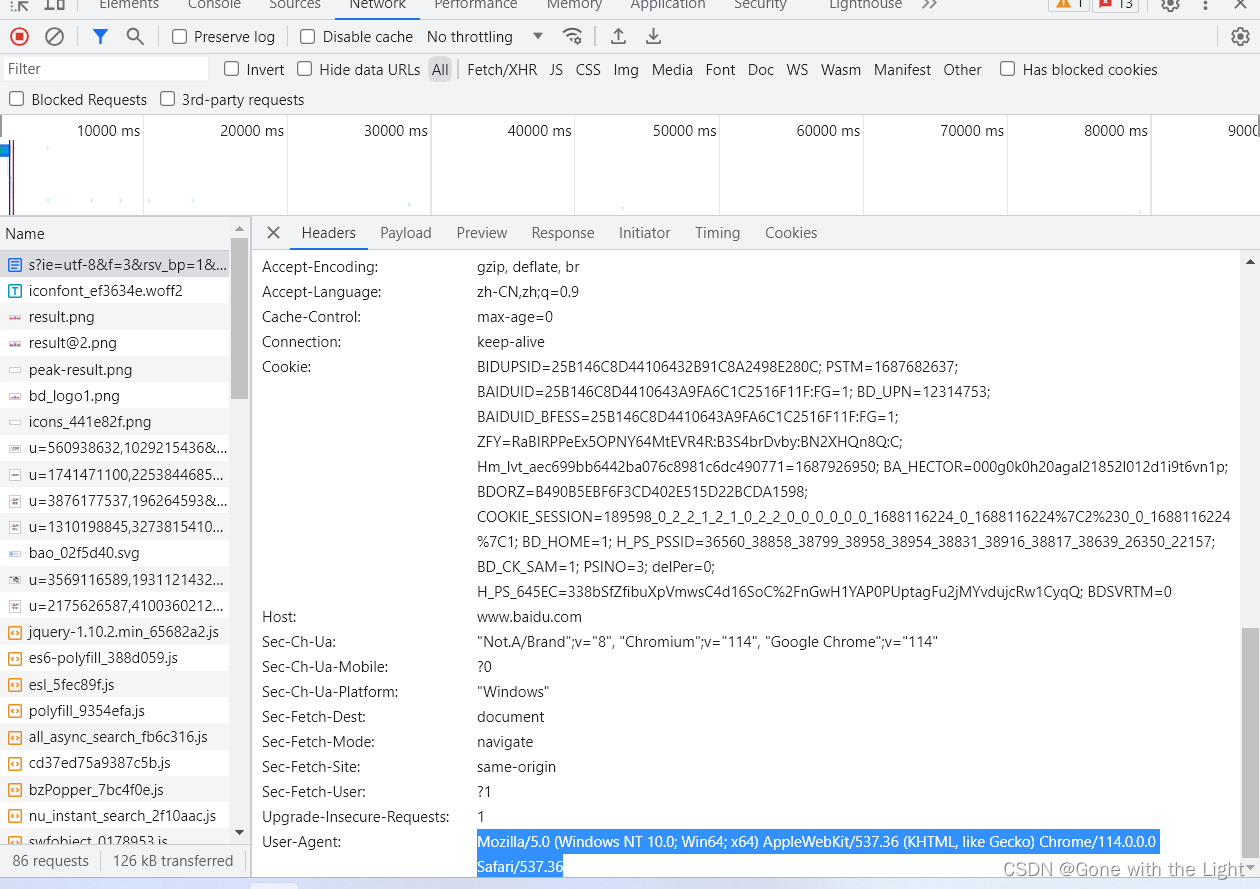
请求头,为字典。我们构造请求头是,既可以通过headers参数直接构造,也可以通过调用请求实例的add_headers方法添加。添加请求头的最常用方法就是通过修改User_Agent来伪装浏览器。默认的User_Agent为Python-urllib。例如我们想要伪装成谷歌浏览器,就可以把User_Agent设置为:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36
我们可用通过开发者工具中的Network面板中的Headers选项查看浏览器的User_Agent。
-
origin_req_host
请求方的host名称或者IP地址。 -
unverifiable
用于表示用户是否有足够的权限来接收这个请求的结果,默认取值是False。 -
method
指示请求使用的方法,例如GET、POST等。
下面通过具体的参数构建Request类。
from urllib import request, parse
url = 'https://www.httpbin.org/post'
data = bytes(parse.urlencode({
'name': 'python'}), encoding='utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 '
'Safari/537.36'
}
method = 'POST'
req = request.Request(url=url, data=data, headers=headers, method=method)
response = request.urlopen(req)
print(response.read().decode('utf-8'))
运行结果如下:
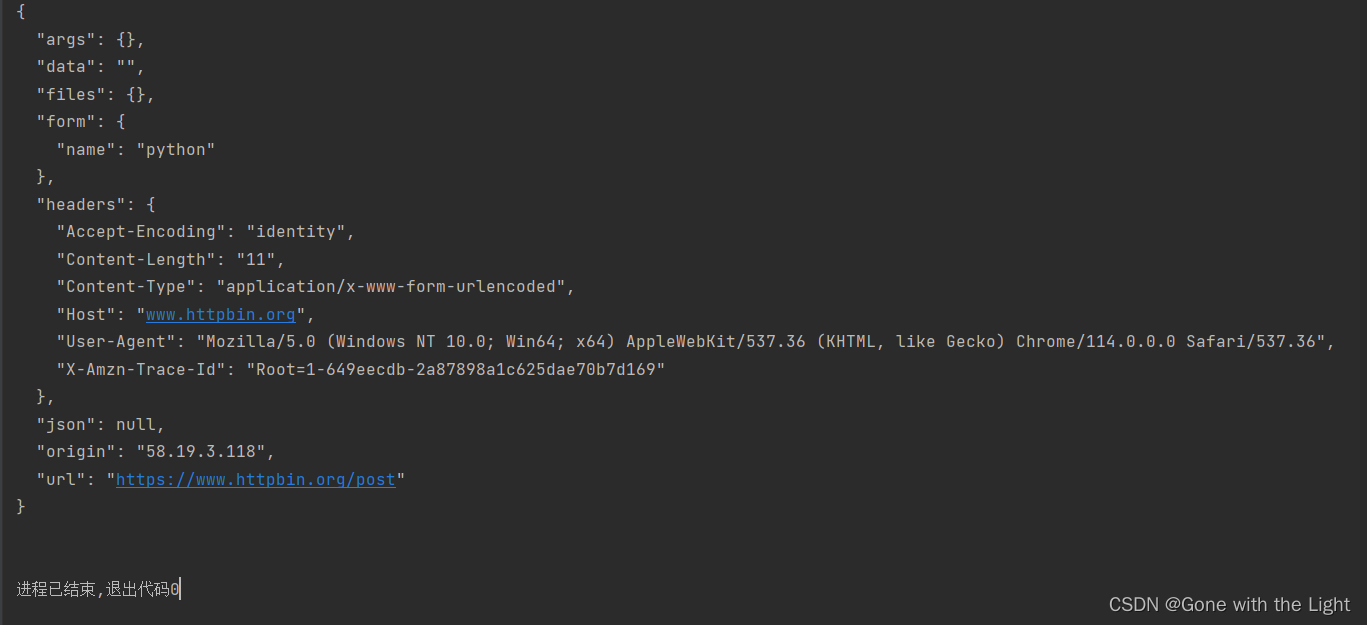
3、异常处理(error)
当我们发送请求时,可能会出现异常,如果不进行处理,程序就可能会因为报错而停止运行。urllib库中的error模块定义了由request模块产生的异常。当出现问题时,request模块便会抛出error模块中定义的异常。
URLError
由request模块产生的异常都可以通过捕获这个类来处理。它的属性reason可用返回错误的原因。下面举例说明:
from urllib import request, error
try:
res = request.urlopen('https://xiaohui.com/403')
except error.URLError as e:
print(e.reason)
运行结果如下:
Not Found
HTTPError
HTTPError是URLError的子类,专门用来请求HTTP错误请求,例如认证请求失败等。它有以下三个属性:
- code:返回HTTP状态码。
- reason:返回错误原因。
- headers:返回请求头。
下面举例说明:
from urllib import request, error
try:
res = request.urlopen('https://helloword.com/404')
except error.HTTPError as e:
print(e.code, e.reason, e.headers, sep='\n')
运行结果如下:
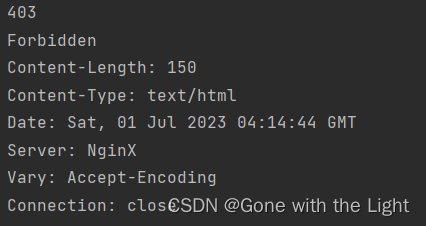
4、解析链接(parse)
urlparse
该方法可以实现URL的识别和分段。实例如下:
from urllib.parse import urlparse
res = urlparse('https://editor.csdn.net/md?articleId=131423019')
print(type(res))
print(res)
运行结果如下:
<class ‘urllib.parse.ParseResult’>
ParseResult(scheme=‘https’, netloc=‘editor.csdn.net’, path=‘/md’, params=‘’, query=‘articleId=131423019’, fragment=‘’)
由运行结果可知,解析结果是一个ParseResult类型的对象,包括6部分,分别是scheme、netloc、path、params、query、fragment。
返回的ParseResult其实是一个元组,可以用其属性名称或其索引顺序来获取其内容。示例如下:
from urllib.parse import urlparse
res = urlparse('https://editor.csdn.net/md?articleId=131423019')
print(res.scheme, res[0], res.netloc, res[-1], sep='\n')
运行结果如下:
https
https
editor.csdn.net
urlunparse
可以理解为urlparse的对立方法,用于构造URL。该方法接收的参数长度必须为6,否则会报错。示例如下:
from urllib.parse import urlunparse
data = ['https', 'www.baidu.com', 'index.html', 'user', 'id=8', 'comment ']
print(urlunparse(data))
运行结果如下:
https://www.baidu.com/index.html;user?id=8#comment
urlsplit
该方法与urlparse相似,只不过urlsplit方法不再单独解析params这一部分,而是将该部分合并到path中,因此只会返回5个结果。示例如下:
from urllib.parse import urlsplit
res = urlsplit('https://www.baidu.com/index.html;user?id=8#comment')
print(type(res))
print(res)
运行结果如下:
<class ‘urllib.parse.SplitResult’>
SplitResult(scheme=‘https’, netloc=‘www.baidu.com’, path=‘/index.html;user’, query=‘id=8’, fragment=‘comment’)
urlunsplit
类似地,该方法与urlunparse类似,唯一区别是此方法参数长度为5。
urljoin
urljoin用于将一个基础 URL 和一个相对 URL 进行拼接,生成一个完整的 URL。
具体用法如下:
- 拼接绝对 URL:如果传入的相对 URL 是一个绝对 URL(例如以 “http” 或 “https” 开头),则 urljoin() 函数会直接返回相对 URL,而不是将其与基础 URL 进行拼接。示例如下:
from urllib.parse import urljoin
base_url = 'https://baidu.com'
relative_url = 'https://www.python.org'
print(urljoin(base_url, relative_url))
运行结果:https://www.python.org
- 解析相对路径:如果传入的相对 URL 是一个相对路径(不是绝对 URL),则 urljoin() 函数会将它与基础 URL 进行拼接,生成一个完整的 URL。
from urllib.parse import urljoin
base_url = 'https://baidu.com'
relative_url = '/about.html'
print(urljoin(base_url, relative_url))
运行结果:https://baidu.com/about.html
- 解析路径符号:urljoin() 函数会解析相对 URL 中的路径符号(如 “…” 和 “.”),并根据基础 URL 的路径进行合理的拼接。这样可以确保生成的完整 URL 是正确的。
from urllib.parse import urljoin
base_url = 'https://baidu.com/default/html/'
relative_url_1 = '../about.html'#返回上一级目录
relative_url_2 = './about.html'#当前目录
print(urljoin(base_url, relative_url_1))
print(urljoin(base_url, relative_url_2))
运行结果:
https://baidu.com/default/about.html
https://baidu.com/default/html/about.html
- 合并查询参数:如果基础 URL 和相对 URL 都包含查询参数(query parameters),则 urljoin() 函数会将相对 URL 中的查询参数与基础 URL 中的查询参数合并。如果有重复的查询参数名,相对 URL 中的查询参数会覆盖基础 URL 中的查询参数。
from urllib.parse import urljoin
base_url_1 = 'https://baidu.com/default/html/'
relative_url_1 = '?id=8'
base_url_2='https://baidu.com/default/html/?catagorg=2'
relative_url_2 = '?id=6'
print(urljoin(base_url_1, relative_url_1))
print(urljoin(base_url_2, relative_url_2))
运行结果:
https://baidu.com/default/html/?id=8
https://baidu.com/default/html/?id=6
这些特性使得 urljoin() 函数在处理 URL 拼接时非常方便和可靠。它可以正确处理各种不同类型的 URL,确保生成的完整 URL 是符合预期的。
urlencode
urlencode方法可以将params序列转化为GET请求的参数。示例如下:
from urllib.parse import urlencode
params = {
'name': 'xiaohui',
'age': 19
}
base_url = 'https://www.vonphy.love?'
url = base_url + urlencode(params)
print(url)
运行结果:https://www.vonphy.love?name=xiaohui&age=19
parse_qs
parse_qs方法与urlencode方法相反,用于将GET请求参数转换为字典。实例如下:
from urllib.parse import parse_qs
query = 'name=xiaohui&age=19'
print(parse_qs(query))
运行结果:{‘name’: [‘xiaohui’], ‘age’: [‘19’]}
parse_qsl
parse_qsl用于将参数转化为由元组组成的列表,示例如下:
from urllib.parse import parse_qsl
query = 'name=xiaohui&age=19'
print(parse_qsl(query))
运行结果:[(‘name’, ‘xiaohui’), (‘age’, ‘19’)]
quote
该方法可以将内容转换为URL编码的格式。当URL中带有中文参数时,可能导致乱码问题。为避免这种问题可用quote方法将中文字符转换为URL编码。示例如下:
from urllib.parse import quote
keyword = '你好'
url = 'https://www.baidu.com' + quote(keyword)
print(url)
运行结果:https://www.baidu.com%E4%BD%A0%E5%A5%BD
unquote
与quote方法相反,该方法用于URL解码。实例如下:
from urllib.parse import unquote
url = 'https://www.baidu.com?wd=%E4%BD%A0%E5%A5%BD'
print(unquote(url))
运行结果:https://www.baidu.com?wd=你好