深度学习库能做什么?
import torch
import time
print(torch.__version__)
print(torch.cuda.is_available())
a = torch.randn(10000, 1000) # 随机生成服从正态分布10000行x1000列的张量
b = torch.randn(1000, 2000)
t0 = time.time()
c = torch.matmul(a, b)
t1 = time.time()
print(a.device, t1 - t0, c.norm(2)) # cpu 0.41573262214660645 tensor(140925.6406)
# device = torch.device('cuda')
# a = a.to(device)
# b = b.to(device)
a = a.cuda()
b = b.cuda()
t0 = time.time()
c = torch.matmul(a, b)
t2 = time.time()
print(a.device, t2 - t0, c.norm(2))
t0 = time.time()
c = torch.matmul(a, b)
t2 = time.time()
print(a.device, t2 - t0, c.norm(2)) # cuda:0 0.006535530090332031 tensor(141469.8906, device='cuda:0')
1.torch.rand() 和 torch.randn() 有什么区别?
torch.randn(*sizes, out=None)
randn是随机生成服从正态分布的数据,返回值为张量。
参数:
sizes (int...) - 整数序列,定义了输出张量的形状
out (Tensor, optinal) - 结果张量
torch.rand(*sizes, out=None)
rand是随机生成服从均匀分布的数据,返回值为张量。
参数:
sizes (int...) - 整数序列,定义了输出张量的形状
out (Tensor, optinal) - 结果张量
torch.norm(input, p=‘fro’, dim=None, keepdim=False, out=None, dtype=None)
返回所给tensor的矩阵范数或向量范数
3.pytorch中.cuda()和.to(device)有区别吗
.cuda()就等同于.to(device)
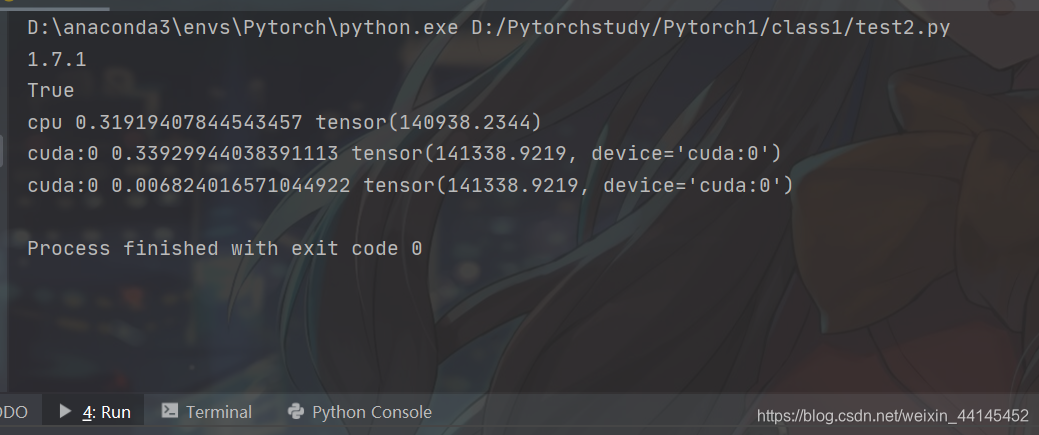
运行截图:
求y分别对a b c的偏导:

import torch
from torch import autograd
x = torch.tensor(1.)
a = torch.tensor(1., requires_grad=True) # requires_grad=True 是告诉pytorch我们是对a b c求导
b = torch.tensor(2., requires_grad=True)
c = torch.tensor(3., requires_grad=True)
y = a**2 * x + b * x + c
print('\nbefore: ', a.grad, b.grad, c.grad)
grads = autograd.grad(y, [a, b, c])
print('\nafter: ', grads[0], grads[1], grads[2])
Pytorch中torch.autograd.grad()函数用法示例
autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None,
create_graph=False, only_inputs=True, allow_unused=False)
outputs: 求导的因变量(需要求导的函数)
inputs: 求导的自变量
grad_outputs: 如果 outputs为标量,则grad_outputs=None,也就是说,可以不用写; 如果outputs 是向量,则此参数必须写,不写将会报错
