如果不懂爬虫,请看链接
爬虫第一课:爬虫的基本原理
什么是Urllib
Urllib是python 内置的http的请求库。包含四个模块
- urllib.request 请求模块
- urllib.error 异常处理模块
- urllib.parse url解析模块
- urllib.robotparser robots.txt解析模块(识别哪些网站可以爬)
本文主要讲解前面三个模块
和python2中urlib模块区别
Python2
import urllib2
response = urllib2.urlopen(‘http://www.baidu.com’)
Python3
import urllib.request
response = urllib.request.urlopen(‘http://www.baidu.com’)
用法讲解
请求urlopen
urlopen
第一个参数URL请求网站,第二个参数data,post请求时需要,第三参数timeout限时设置,后面暂时用不到
#%% raw
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
get请求网页打开
import urllib.request
response = urllib.request.urlopen('https://www.baidu.com/')
print(response.read().decode('utf-8'))#解码
post请求网页打开
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({
'word': 'hello'}), encoding='utf8')#编码
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())

timeout
设置一个超时时间,如果在规定时间没有完成请求,会报错
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
print(response.read())

import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')
响应

响应类型
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(type(response))

状态码和响应头
响应里面,包括两个重要信息:状态码和响应头
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.status)#状态码
print(response.getheaders())#响应头
print(response.getheader('Server'))#查看响应头具体某一项

读取响应read
#读取的响应为字节流型数据,需要解码为utf-8
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))
Request
通过前面urlopen 我们可以请求一个网页并获取响应,但urlopen没法添加额外信息,如请求头,所以需要更高级的请求,Request
读取网页
import urllib.request
request = urllib.request.Request('https://python.org')#声明一个request对象
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
添加请求头,同时post方式读取网页
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host': 'httpbin.org'
}
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')#编码
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))

前面添加请求头是通过参数,还可以通过add_header方法
from urllib import request, parse
url = 'http://httpbin.org/post'
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
Handler代理
import urllib.request
proxy_handler = urllib.request.ProxyHandler({
'http': 'http://127.0.0.1:9743',#服务器网址
'https': 'https://127.0.0.1:9743'
})
opener = urllib.request.build_opener(proxy_handler)
response = opener.open('http://httpbin.org/get')
print(response.read())
Cookie
Cookie是在客户端保存的,用来记录用户身份的文本文件
如我们打开淘宝网页,左上角显示着用户名信息

审查元素,找到淘宝cookie,右键clear


刷新网页 用户登录信息消失

cookie如果有,可以维持用户登录信息,在做爬虫时,可以爬取一些登录后的信息。
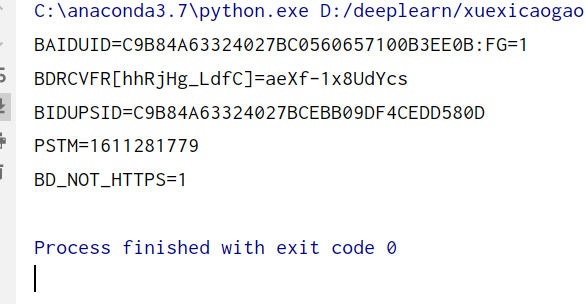
1.打印cookie
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()#声明cookie对象
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com/')#百度,我登录了百度账号
for item in cookie:
print(item.name+"="+item.value)
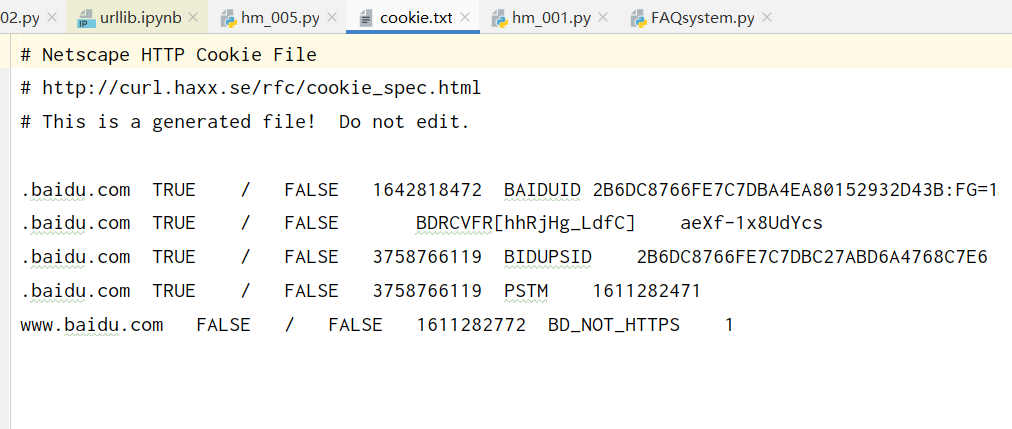
 2.保存cookie为文本文件
2.保存cookie为文本文件
方式1
import http.cookiejar, urllib.request
filename = "cookie.txt"
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com/')
cookie.save(ignore_discard=True, ignore_expires=True)
方式2
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.LWPCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com/')
cookie.save(ignore_discard=True, ignore_expires=True)
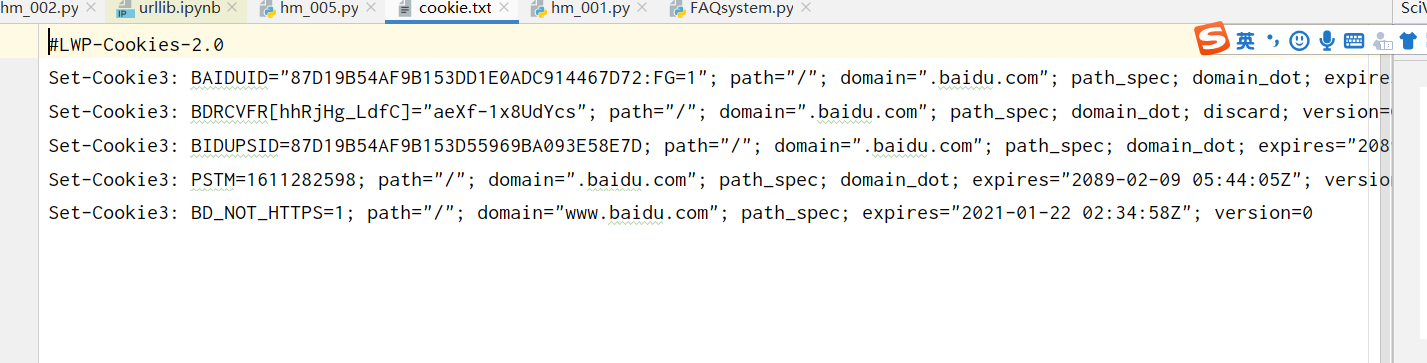
3.带cookie读取网页
import http.cookiejar, urllib.request
cookie = http.cookiejar.LWPCookieJar()#要和前面保存方式一样
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com/')
print(response.read().decode('utf-8'))
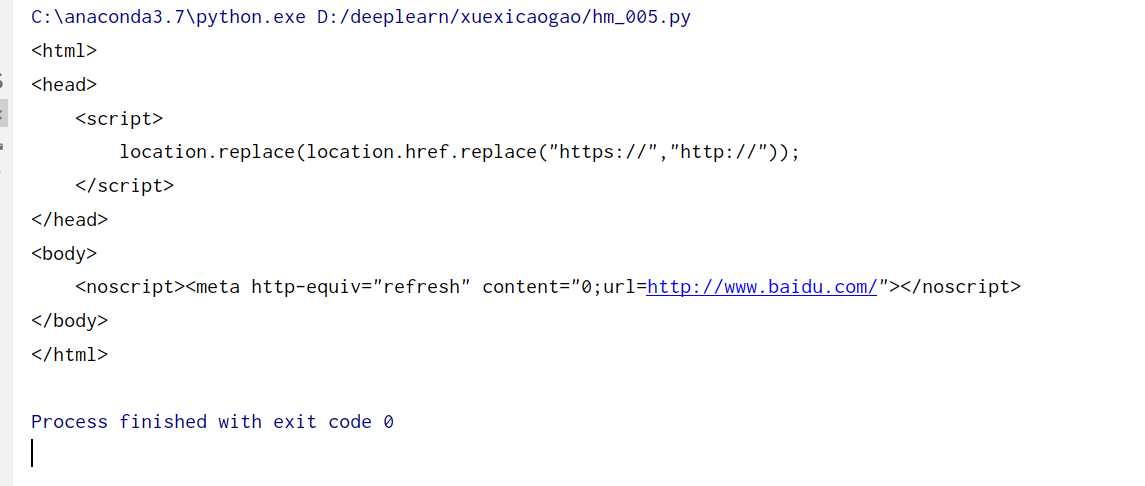
异常处理
from urllib import request, error
try:
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.URLError as e:
print(e.reason)
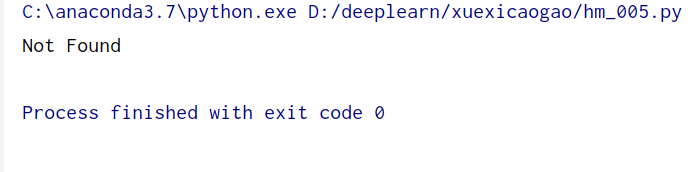
from urllib import request, error
try:
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
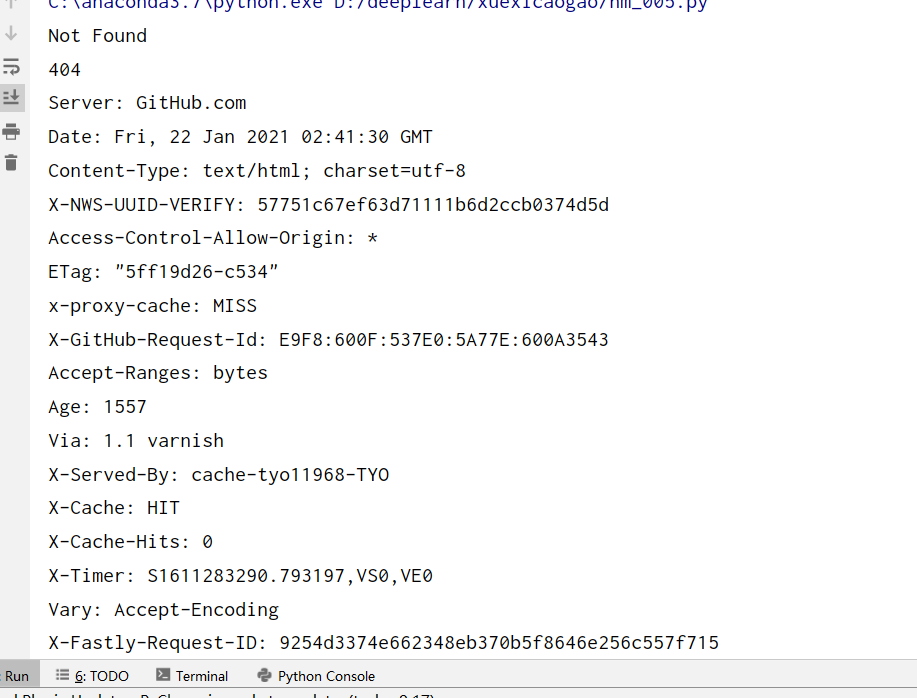
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('https://www.baidu.com', timeout=0.01)
except urllib.error.URLError as e:
print(type(e.reason))
if isinstance(e.reason, socket.timeout):
print('TIME OUT')

URL解析
urlparse
传入一个url,然后把一个url分割成几个部分。协议,域名,参数等
urllib.parse.urlparse(urlstring, scheme=’’, allow_fragments=True)
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result), result)

指定协议类型,传入的ur无协议
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result)
指定默认协议为ihttps,如果传入的url无协议就会被指定为https
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result)
锚点拼接allow_fragments
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False)#allow_fragments锚点
print(result)
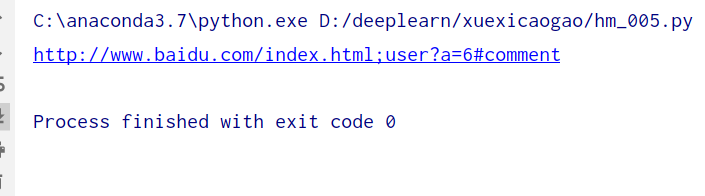
urlunparse:拼接URL
from urllib.parse import urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))
urljoin
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com', 'FAQ.html'))
print(urljoin('http://www.baidu.com', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html?question=2'))
print(urljoin('http://www.baidu.com?wd=abc', 'https://cuiqingcai.com/index.php'))
print(urljoin('http://www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com#comment', '?category=2'))

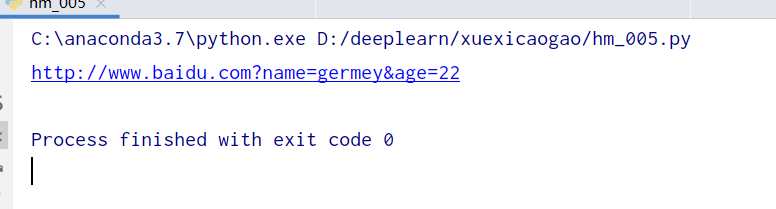
urlencode
把字典对象转换为get请求参数
from urllib.parse import urlencode
params = {
'name': 'germey',
'age': 22
}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)

作者:电气-余登武。
创作不易,大佬请留步… 来个赞再走呗 (๑◕ܫ←๑)