关于MTCNN,看别人的解释,总说很简单,但我还是没有get到它的点。
现在我自己梳理一下对它的理解。
1. 算法的思路
首先,谈一下我对CNN卷积网络的理解,像下面的MTCNN级联网络中的PNet, 我可以理解它是一个区域特征提取器。
单个的CNN是卷积,通过滑动扫描图片(或者特征图)中的某个区域内的特征,会得到一个融合局部特征的特征图;
多个这样的CNN卷积,就延伸出一个感受野的概念,就是一层层地提取,特征图越来越小,可以理解为最后的特征图浓缩了最开始输入图片(或者特征图)的整体信息;
这个整体信息可以是一个向量用于分类,也可以是一个回归任务的结果;
至于为什么就能得到这样的结果,其实卷积像水流一样,又像是一个DJ的操作面板一样,非常多的可调节的开关,这些开关就是卷积的参数;
为什么可以调成我们想要的样子呢?靠我们耳朵来判断,不断地接受于我们感觉喜欢的调调,神经网络的调整方法就是靠损失函数;
我要是不停地逼近Groud Truth,那你就得像水或者像DJ面板一样,不停地像这里靠,至于输出结果的具体含意,计算机是不懂的,它就知道去调罢了;
那么针对于MTCNN网络中的第一级PNet,就把它当成一个手电筒,一个小工具包,就是拿去照输出图片,我照一照,你给我一个结果,判断一下我照12x12的区域得到的人脸回归及检测分类的值;
那问题来了,照一照,毕竟只能照到12x12的区域,那一张图可能很大,人脸也很大,就有可能总是提取不到一张脸的全部区域信息,又怎么能得到我们想要的结果呢?这不是盲人摸象吗?
有个办法可以解决这个问题,那就把大像缩小不可以吗?这就是我对为什么MTCNN的输入要做图像金字塔的理解,就是绽放图像,我变,变,变,继续变到不要小于12就行,因为再小就没有意义了;
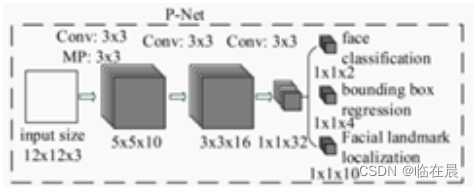
然后这还没完,因为我们这个手电筒还是有点简单,提取出来的结果就不太靠谱,但是它要尽可能去做好它自己流水线上的事情,就是粗提取;
经过PNet后会得到非常多的预测框,如果输入刚好是12x12的图片,那输出就是一个框,如果输入是大于12x12的,那输出就有mxn个框(m,n 就是最后输出的特征图大小,一个像素点就是一个框,对应的通道就是相应的face classification, bouding box regression, facial landmark localization);
问题来了,得到的这些结果,尤其是bouding box regression, facial landmark的位置,它是相对于输入的尺寸的,还是相对于原图的?
我理解应该是相对于输入图像的,这些个框框点点要映射到原图上,还得转换一下尺寸。
得到了这些乱七八糟的结果之后,数量庞大,想想应该是要做一下筛选的;
问题来了,怎么筛?
两个框太近应该要筛掉个,离真实框太远的也筛掉;
这么说,就是做个NMS的吧,首先找到与真实框IOU大的,拿出来,然后找与拿出来的框IOU大于阈值的,比如0.8(瞎说的),筛掉,然后再找下一个与真实框IOU大于阈值的拿出来,再重复上面的过程;
最后得到了一些个框(附带对应的landmark),它位与真实框IOU是大的,然后和这个框相近的也没了;
然后得到的框,也就是相对于原图的局部位置,再传到RNet中,进行精调,这个逻辑感觉上和PNet有一些不一样,因为PNet是从无到有,RNet是有了之后再精调,后面的ONet也是一样;
哎,不懂的太多,感觉有点玄幻;