如果初始化的锚框尺寸较理想的话,模型学习速度也会更快,效果应该也会更好。
YOLOv5代码中是有内置自动计算新数据集锚框大小的代码的,位置在utils/autoanchor.py。
如果在运行训练代码是没有指定--noautoanchor True,那么就会自动执行检测并判断是否重新聚类计算新的锚框尺寸。
核心函数是def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True)
dataset是数据配置文件,如果要单独运行这个kmean_anchors,需要将yaml文件里的数据路径都改为绝对路径(自己亲身跑了一下,相对路径会出错,单独跑kmean_anchors没有执行对yaml文件里相对路径处理的代码);
n=9表示的是锚框的个数;
img_size=640,是模型输入图片尺寸,这里就不要改了,特别是如果做了迁移训练的话,因为输入尺寸影响着卷积过程中特征图的尺寸,而且也影响着数据集中标注框的大小。我们需要根据图片缩放后的标注框(groud truth)的尺寸来聚类出我们需要的初始锚框尺寸;
thr=4.0,这是一个阈值,对于这个阈值我的理解是这样的: 它是用来计算bpr(best possible recall即最佳可能召回)的阈值,网上没有找到解释这个bpr的。
我的理解是,所谓召回依然是说对一个真实标签而言,它是否被成功识别出来(或者分辨出来)。而判断是否识别成功,分类任务我们用的是标签,回归任务我们需要给它定一个阈值(比如标签是1, 我们预测是0.8,误差在20%就算成功)。这里我们就是要计算的就是我们给定的初始锚框的尺寸与groud truth的边框尺寸的比值是否在阈值内。
说具体点,就是计算groud truth 的[N, W, H]与初始锚框[9, W, H]的比值,N表示有N个真实框。
比如现在计算其中某一个真实框[1, W, H]与我们设定的9个锚框[9, W, H]的比值,结果shape就是[9, Rw, Rh]。 因为Rw, Rh比值可能大可能1也可能小于1,都理解为相对缩放值,我们统一都转换成0-1范围内,也即是如果比值为3,那就记为1/3(简单的min(r, 1/r))就可以了。
然后Rw, Rh取个最小值,shape就成了[9, r]。我们就得到了真实框与9个锚框的长宽比值最小值。
其实我们希望什么?
我们希望,我们的模型能够在初始锚框尺寸的基础上快速学习得到结果,如果能够一次学习到最终结果就更好了。
也就是一次更新,我们就可以通过9个锚框中的某一个得到我们的ground truth的边框尺寸。
在YOLOv5中,预测框的中心坐标更新以及边框大小更新都有了改变;
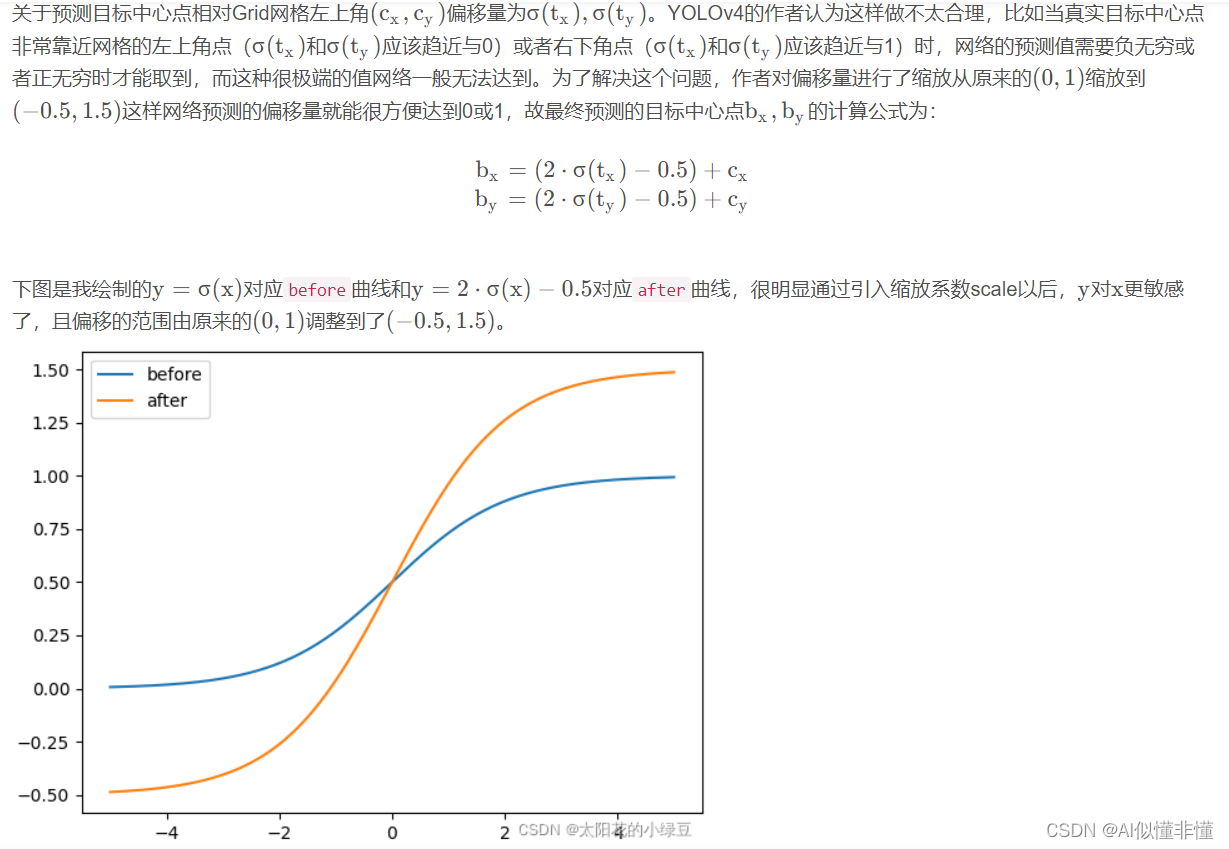
bx=(2⋅σ(tx)−0.5)+cx
by=(2⋅σ(ty)−0.5)+cy
y = σ ( x ) y = \sigma(x)y=σ(x)对应before曲线和y = 2 ⋅ σ ( x ) − 0.5 y = 2 \cdot \sigma(x) - 0.5y=2⋅σ(x)−0.5对应after曲线,很明显通过引入缩放系数scale以后,y yy对x xx更敏感了,且偏移的范围由原来的( 0 , 1 ) (0, 1)(0,1)调整到了( − 0.5 , 1.5 ) (-0.5, 1.5)(−0.5,1.5)。

这样对于pw, ph而言每次更新范围就成了[0, 4),所以我理解如果anchor box尺寸和ground truth尺寸相差在4倍之间,那么这个anchor box在YOLOv5模型中就会负责预测这个ground truth。
回到我们的初始化的锚框(anchor box)尺寸,那么如果ground truth与它宽度比最小值大于0.25,那么我理解这个ground truth就是可以计入召回率(TP/ TP + FN,当然这里没有FN,成了TP/T,T就是全部ground truth数量)的TP。
在YOLOv5中如果不指定--noautoanchor,则会自动去计算bpr, 如果小于0.98,则会运行kmean_anchor计算初始锚框尺寸。否则则认为原始coco数据集的锚框尺寸是可用的。