首先呢,剪枝这个东西我理解的还比较浅显,只是有了一个大概的了解,想把这点理解记录一下,以后随着对它了解的深入,慢慢再丰富这篇文章。纯粹个人理解,可能会有偏差。
1. 什么是剪枝以及剪枝的目的
剪枝这个词,很形象,第一反应想到的是剪树枝,剪葡萄枝。在机器学习中,让人很快想到决策树,避免过拟合的方法之一,就是剪枝,也就是决策树不要太深,不然分得太细,模型变得复杂容易过拟合。而把深度学习中神经网络的参数,早先Transformer就有5000万个参数,YOLOv5s有700万个参数,到现在GPT有上千亿个参数。这些参数就像超大型乐团一样,总有东郭先生的存在,在那儿滥竽充数。具体体现在,参数的权重值很低,使得整个模型又大又慢,是不是又像极了一个行将末落的庞大帝国,一堆尸位素餐的公务员,上传下达又慢,慢是慢了点儿,但又还是能够起到职能作用。
怎么样才能够让模型又快又小呢?毕竟显存是很贵的,而时间更宝贵。
裁员!没错,就是把不干活的家伙都给裁掉。而这,就是剪枝。
2. 剪枝的方法
裁员讲究方法,裁过头了,活没法干了,而这就是剪枝要考虑的方法。
2.1 填0剪枝与Removing剪枝
对于权重参数而言,它不存在或者为0,都是可以起到剪枝的效果的。不同之处在于,参数置为0,则那个位置还在,那么便不会影响整体网络的骨架,对于用深度学习框架而言,就变得容易多了。另一方面,如果是把这个参数删除,那么意味着对应的神经元结构要改变,与之相连的其它网络层也会发生改变,改变会像多米诺骨牌一直延续下去。
下面重点讲讲填0的剪枝方法。
2.2 非结构化剪枝
非结构化区分于结构化剪枝,可以理解为瞎JB剪(开玩笑),可以理解为零散的一种剪法。
2.2.1 细粒度剪枝
我们可以手动设定一个参数阈值,或者是比例,好比是裁员时按能力裁或者是按比例裁员。
还有一种阈值,可以选择权重与梯度乘积作为综合值。
比如我们设定阈值为0.05,那么所有绝对值小于是0.05的参数都置为0;又比如,我们设定剪枝比例为0.2,那么我们可以利用Numpy的一些函数来获得参数绝对值大小二八分的位置的值,然后小于这个值(也就是在20%以内)的权重都置为0,剪枝掉。
这样下来,如果权重形象地理解为一个方块的话,剪枝后的权重方块就像是被打了一梭子弹,打成马蜂窝了。
2.2.2 向量剪枝
我们可以手动的去选择一些权重方块的行或者列来进行剪枝。
2.3 结构化剪枝
如果我们选择性地将权重中的某一个维度作为一个整体来考虑的话,那么剪枝的标准就发生了变化 ,不再是单个权重参数与阈值进行对比。之前听说鹅厂疫情期间裁了许多人,后来听说不少是按项目组来裁的,也就不是不赚钱的项目组就给裁掉,这里差不多就是这样的思路。
我比如某个权重参数的维度是[3, 10, 4, 3],这里可以看出输出通道数为3,输入通道数为10,所以是3个[10, 4, 3]卷积核。
2.3.1 Vector Level
如果是axis=3的维度进行结构化剪枝,那么就要对于最里层维度计算L2或者L1范数,得到[3, 10, 4, 1]。为什么是L2或者L1范数呢?如果把某一维度的参数比作是向量点,那么这就是在比较向量的长度,L2是绝对值长度,L1是曼哈顿长度。然后再用该维度的L2或L1去与阈值进行比较,低于阈值(可以是指定的值,也可以是通过剪枝比例得到的值,同非结构化剪枝)的整个aixs=3的维度剪掉。
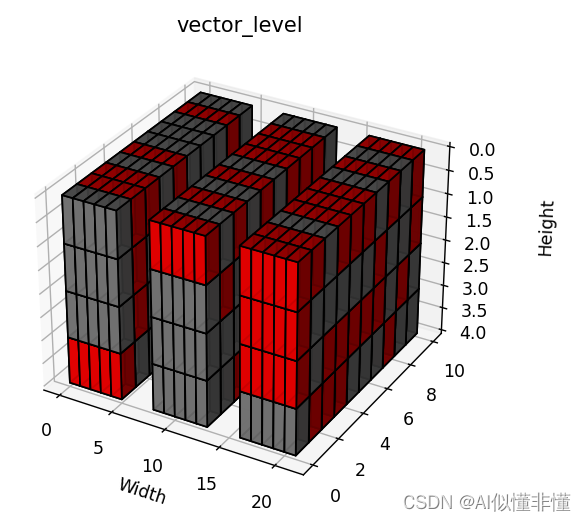
图中是个维度为[3, 10, 4, 3]的权重,红色表示剪枝掉的参数
2.3.2 Kernel Level
如果是axis=(2, 3)维度呢,也就是轴2和轴3一起,那么同样就是一起计算这两个维度的L2或者L1范数,得到[3, 10, 1],同样与阈值进行比较,低于阈值的裁剪掉。
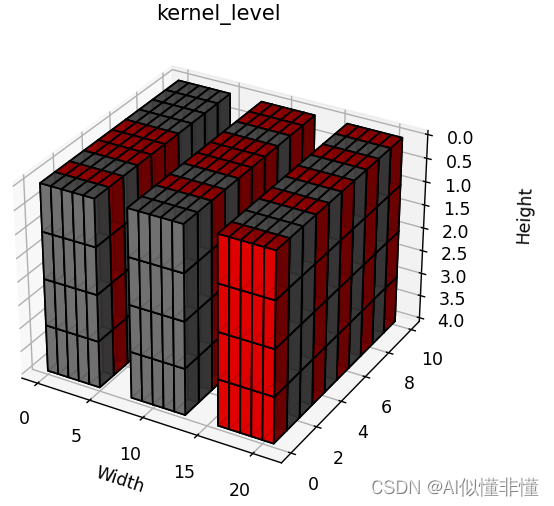
2.3.3 Channel Level
如果是axis=(1, 2, 3)呢,同理计算范数,得到[3, 1],同样与阈值进行比较,低于阈值的裁剪掉。
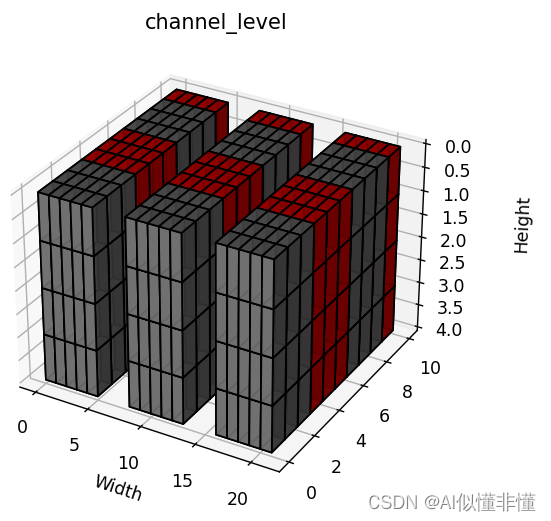
2.3.4 Filter Level
如果是axis=(0, 1, 2, 3)呢,同理计算范数,得到[3],同样与阈值进行比较,低于阈值的裁剪掉。
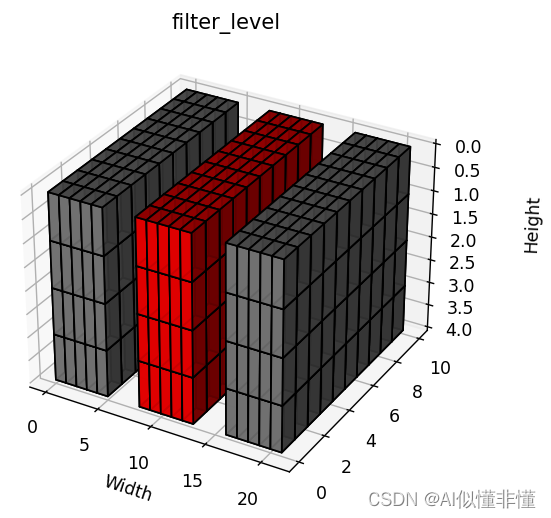
3. 剪枝的训练方法
3.1 训练-->剪枝-->精调(fine-tune)
这种思路比较清晰,就是我先去把模型训练好,然后再对参数进行剪枝,剪枝完之后吧,精度肯定会有所下降,好比是裁员后人少了,那么留下来的人就不能只是做原来那些活了,肯定要进行调整的。这又像是结构力学当中,对于一个自由度冗余的结构,如果拿掉一个柱子或者一个梁,那么应力肯定要是重新分布的。
剪枝后,对模型进行fine-tune, 要以一个更小一点儿的学习率,因为本身已经收敛了,再训练学习率用大了可能就跳出损失最小值的波谷了。
3.2 训练-->剪枝-->训练-->剪枝...
这种思路它比较啰嗦,训练的过程中,不停地去做剪枝,再训练再剪枝,直到模型收敛。具体哪个好,要自己试一试才行。
4. Removing剪枝
前面提到了Removing剪枝会删除掉权重与对应的神经元,改变了该层以及与该层有依赖的神经元/层。
这里推荐一个大佬开发剪枝工具,可以对任意网络进行傻瓜似的结构化剪枝。大概是通过一种叫“非深度图”的方式,找到网络各层的依赖关系,然后进行剪枝。