
引言
目前智慧城市的发展,人们生活处处有科技,比如人脸识别,智慧交通,无人驾驶等前沿的科技产品也都融入了人们生活中;
智慧交通的发展也越来越成熟,车辆识别,车辆跟踪,车辆分析,行人跟踪检测与行为分析,这些都越来越成熟,但是都是建立在斑马线的基础上来实现的。
智慧斑马线,严格地说,是用于(单条或区域多条)人行横道(斑马线)上,人、车、路、环境协同的一整套软硬件产品与服务,主要通过提高斑马线标线的清晰度和醒目度,以及智能网联控制,实现智能的斑马线通行的警示、调度、控制、多点联动。
智慧斑马线首先是斑马线。斑马线是一条线,对行人来说是保护道路通行安全的生命线;对城市交通管理来说,是对人、车、路进行协同工作的一条协同线,只有人和车、路都是按规则有秩序地协同,才能达到交通文明有序。智慧斑马线就是以技术为出发点,帮助行人和城市交管做到斑马线生命线和协同线的一种智能产品和服务。
神经网络的结构
神经网络模型包含三个部分:input layer(输入层)、hidden layer(中间层或隐藏层)、output layer(输出层)。其中,hidden layer的层数不固定,在某些简单问题中,hidden layer的层数可能为0,仅有input layer和output layer;在复杂问题中,hidden layer的层数也可能成百上千。

模型中每一层的节点称为“神经元”。位于input layer的神经元对应着训练数据的特征。hidden layer和output layer中的神经元由activation function(激活函数)表达,我们用字母 g g g表示。Activation function有很多种类型,最常用是sigmoid函数,它的表达式如下:
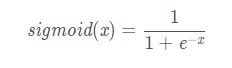
sigmoid函数图像如下图所示。当 x > > 0 x>>0 x>>0时, f ( x ) f(x) f(x)无限逼近于1;当 x < < 0 x<<0 x<<0时, f ( x ) f(x) f(x)无限逼近于0;当 x = 0 x=0 x=0时, f ( x ) = 0.5 f(x)=0.5 f(x)=0.5。
搭建模型
一、引入基本库
环境配置:
- Windows10系统
- Python–3.7.3
- tensorflow–2.3
- OpenCV–4.5.1
import tensorflow as tf
import matplotlib.pyplot as plt
import cv2 as cv
import pandas as pd
import numpy as np
import os
import shutil
from keras.models import Sequential, load_model
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
Conv2D :卷积
MaxPooling2D: 最大池化
Flatten: 从卷积层到全连接层的过渡(卷积),扁平数据
Dense: 全连接
二、数据集准备

数据集来源:斑马线数据集
在这里我们使用Keras自带的图像生成器ImageDataGenerator,在这里下载下来的数据集并不需要我们去处理,我们只需要下载,解压就行;

ImageDataGenerator图像生成器他会根据train和test的子文件信息来给予标签;
#简单的二分类
train_dir = 'G:\\深度学习\\Zebra\\Zebra\\train'#训练集文件
val_dir = 'G:\\深度学习\\Zebra\\Zebra\\test' #验证集文件
train_datagen = ImageDataGenerator(rescale=1/255)
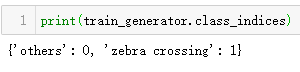
train_generator = train_datagen.flow_from_directory(train_dir, (50, 50), batch_size=20, class_mode='binary', shuffle=True)
validation_datagen = ImageDataGenerator(rescale=1/255)
validation_generator = validation_datagen.flow_from_directory(val_dir, (50, 50), batch_size=20, class_mode='binary')
三、模型搭建
在这里我们使用的是sigmoid函数作为输出层的激活函数,二分类
model = Sequential()
model.add(Conv2D(32, (3, 3),activation='relu', input_shape=(50, 50, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
四、模型训练
model.compile(loss='binary_crossentropy',#二分类,使用binary_crossentropy损失函数
optimizer=optimizers.Adam(), #Adam优化器
metrics=['acc']
)
history = model.fit_generator(train_generator,
steps_per_epoch=17,
epochs=25,
validation_data=validation_generator,
validation_steps=6)

五、总结
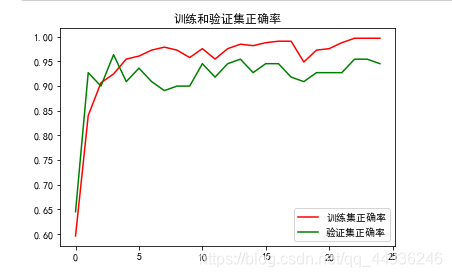
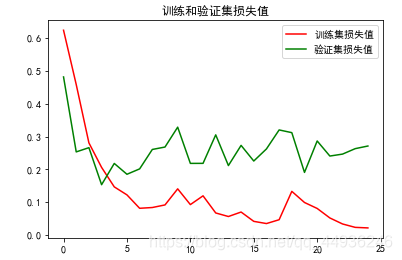
我们根据模型训练过程当中的损失值和正确率可以看出模型的训练集acc达到了99.7%,而验证集达到95.45%,学习遇到了瓶颈;
train loss 不断下降,test loss趋于不变,说明网络过拟合;
这里我们就需要来调整参数:
- 改变模型,模型太大,太深,参数太多难以收敛,建议使用简单的模型
- 增加数据集
- 增大batch_size
- 添加正则
- dropsort 减少参数
这些方法都可以在抑制模型过拟合,但是最好的方法是改变模型和增加数据集
希望本博文对正在学习的你有用!
谢谢点赞评论!