文本检测和一般目标检测的不同——文本线是一个sequence(字符、字符的一部分、多字符组成的一个sequence),而不是一般目标检测中只有一个独立的目标。这既是优势,也是难点。优势体现在同一文本线上不同字符可以互相利用上下文,可以用sequence的方法比如RNN来表示。难点体现在要检测出一个完整的文本线,同一文本线上不同字符可能差异大,距离远,要作为一个整体检测出来难度比单个目标更大——因此,作者认为预测文本的竖直位置(文本bounding box的上下边界)比水平位置(文本bounding box的左右边界)更容易。
环境:
- pytorch最新版
- ubunt18.05
- opencv
- pillow
- numpy
前言
前期数据的准备,需要大家自己去爬取或者下载
GitHub上面很多,国外的网站有很多开源的;
提示:以下是本篇文章正文内容,下面案例可供参考
一、数据集准备
在这里我使用了600张图片来训练模型,由于数据集不是很好,模型的泛化能力较差(鲁棒性差),大家可以使用更多的数据来训练模型。
样本数据集
 在这里大家爱还可以使用自己准备的数据集,来训练模型。
在这里大家爱还可以使用自己准备的数据集,来训练模型。
二、数据标签准备
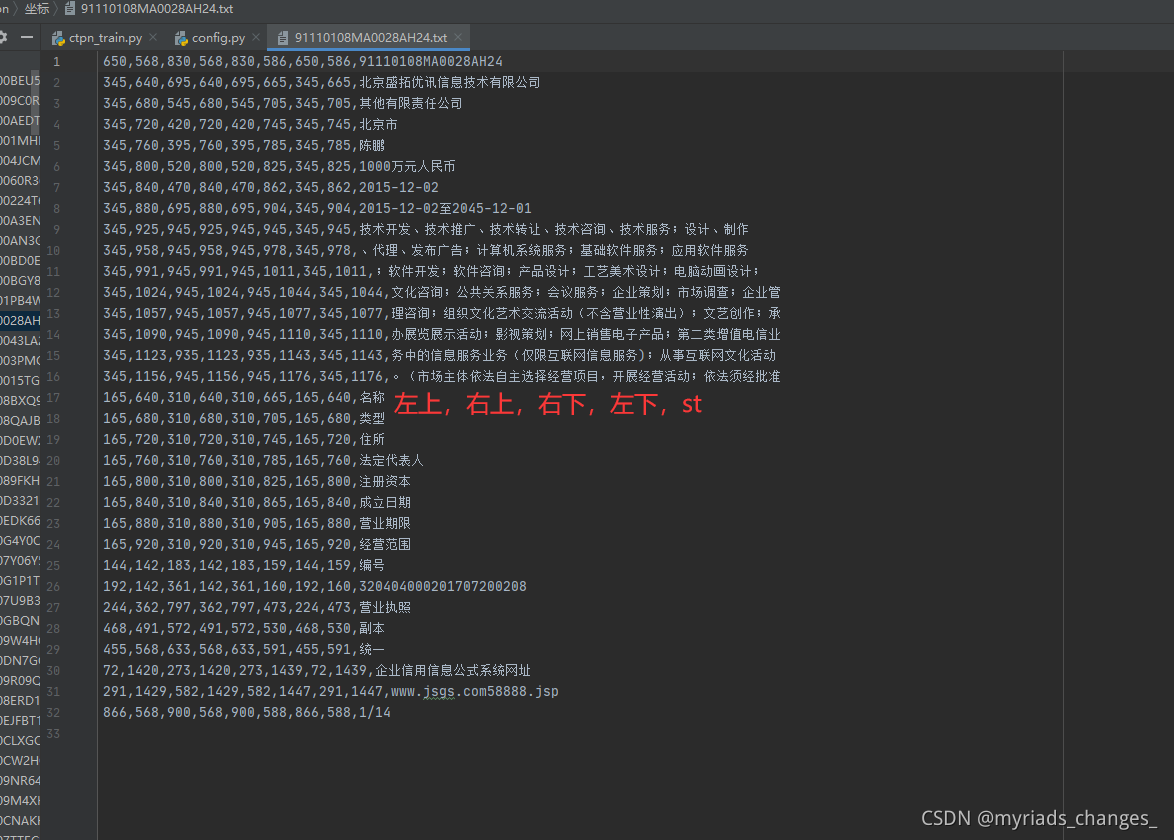
在这里的标签就更简单了,大家可以使用labelimg标签工具来打标签,得到的XML文件可以提取其中的坐标信息;
在这里就需要注意的是,我们的每张图片的标签文件(xxxx.txt)必须是一张图一个标签文件,名字必须是一一对应
左上,右上,右下,左下,str
三、模型训练
源代码链接:
https://pan.baidu.com/s/1RNRaObQBnWaM_Rwd4KYQYg
链接: https://pan.baidu.com/s/1RNRaObQBnWaM_Rwd4KYQYg
提取码: 4s6s
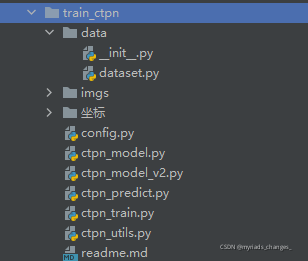
大家可以下载下来,目录结构就是大概这样,ctpn_train.py是训练文件,其他的文件都是配置文件。
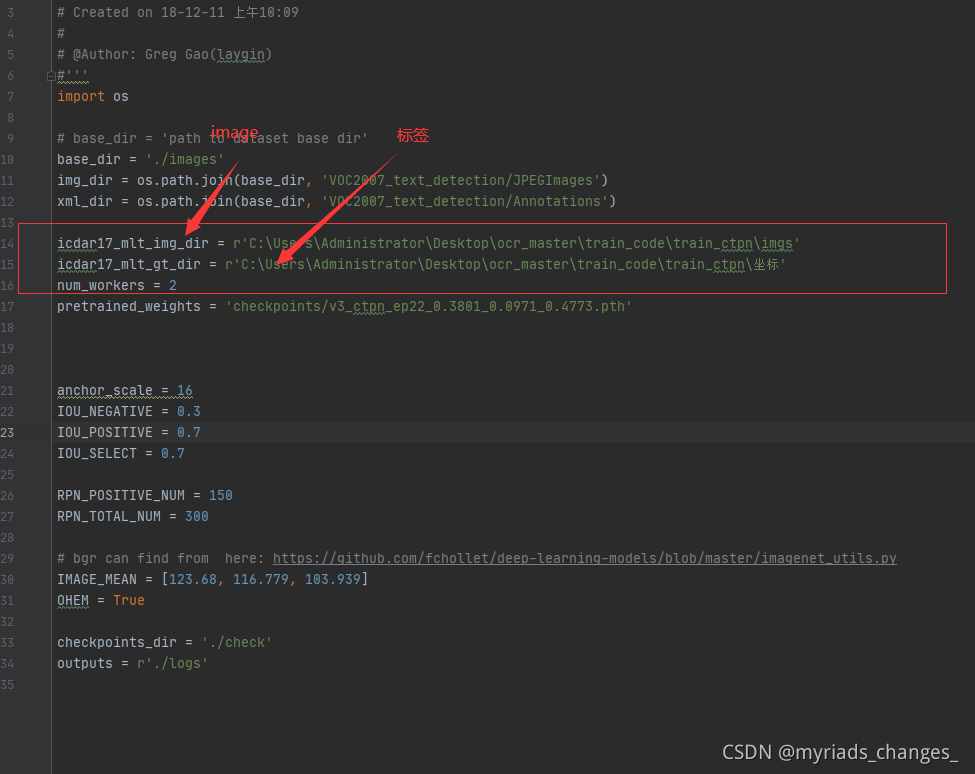
大家吧config.py文件里面的数据 集路径配置好就行
数据集链接:
百度网盘
链接: https://pan.baidu.com/s/1dOscxy1fkobW_g3VOM2qcQ 提取码: win6
针对这个数据集(1.6G),为天池开源数据集,如果大家有感兴趣的,可以下载下来训练模型; 如果要是大家觉得时间有限的话,可以不去训练模型,可以直接加载大家下载那个**CTPN.path**那个模型,玩玩就可以。注意注意:此为开源项目

四、文字检测(CTPN)完整代码
代码:
链接:https://pan.baidu.com/s/1VGQM3vh3zletMy3Vi94DrA
提取码:8888
数据集+模型:
链接: https://pan.baidu.com/s/1dOscxy1fkobW_g3VOM2qcQ
提取码: win6
五、训练结果展示
六、加载CTPN文字检测模型,验证
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
import numpy as np
from PIL import Image
from PIL import Image
"""
GPU加载
"""
prob_thresh = 0.5
gpu = True
if not torch.cuda.is_available():
gpu = False
device = torch.device('cuda:0' if gpu else 'cpu')
print("能够使用GPU"+str(gpu))
"""
模型加载
"""
class basic_conv(nn.Module):
def __init__(self,
in_planes,
out_planes,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
relu=True,
bn=True,
bias=True):
super(basic_conv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding,
dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU(inplace=True) if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class CTPN_Model(nn.Module):
def __init__(self):
super().__init__()
base_model = models.vgg16(pretrained=False)
layers = list(base_model.features)[:-1]
self.base_layers = nn.Sequential(*layers) # block5_conv3 output
self.rpn = basic_conv(512, 512, 3, 1, 1, bn=False)
self.brnn = nn.GRU(512, 128, bidirectional=True, batch_first=True)
self.lstm_fc = basic_conv(256, 512, 1, 1, relu=True, bn=False)
self.rpn_class = basic_conv(512, 10 * 2, 1, 1, relu=False, bn=False)
self.rpn_regress = basic_conv(512, 10 * 2, 1, 1, relu=False, bn=False)
def forward(self, x):
x = self.base_layers(x)
# rpn
x = self.rpn(x) # [b, c, h, w]
x1 = x.permute(0, 2, 3, 1).contiguous() # channels last [b, h, w, c]
b = x1.size() # b, h, w, c
x1 = x1.view(b[0] * b[1], b[2], b[3])
x2, _ = self.brnn(x1)
xsz = x.size()
x3 = x2.view(xsz[0], xsz[2], xsz[3], 256) # torch.Size([4, 20, 20, 256])
x3 = x3.permute(0, 3, 1, 2).contiguous() # channels first [b, c, h, w]
x3 = self.lstm_fc(x3)
x = x3
cls = self.rpn_class(x)
regr = self.rpn_regress(x)
cls = cls.permute(0, 2, 3, 1).contiguous()
regr = regr.permute(0, 2, 3, 1).contiguous()
cls = cls.view(cls.size(0), cls.size(1) * cls.size(2) * 10, 2)
regr = regr.view(regr.size(0), regr.size(1) * regr.size(2) * 10, 2)
return cls, regr
weights = '/home/zc/桌面/pythonProject2/ocr_master/checkpoints/CTPN.pth' # CTPN模型路径
model = CTPN_Model()
model.load_state_dict(torch.load(weights, map_location=device)['model_state_dict'])
model.to(device)
model.eval()
"""
配置信息
"""
IMAGE_MEAN = [123.68, 116.779, 103.939]
def gen_anchor(featuresize, scale):
"""
gen base anchor from feature map [HXW][9][4]
reshape [HXW][9][4] to [HXWX9][4]
"""
heights = [11, 16, 23, 33, 48, 68, 97, 139, 198, 283]
widths = [16, 16, 16, 16, 16, 16, 16, 16, 16, 16]
# gen k=9 anchor size (h,w)
heights = np.array(heights).reshape(len(heights), 1)
widths = np.array(widths).reshape(len(widths), 1)
base_anchor = np.array([0, 0, 15, 15])
# center x,y
xt = (base_anchor[0] + base_anchor[2]) * 0.5
yt = (base_anchor[1] + base_anchor[3]) * 0.5
# x1 y1 x2 y2
x1 = xt - widths * 0.5
y1 = yt - heights * 0.5
x2 = xt + widths * 0.5
y2 = yt + heights * 0.5
base_anchor = np.hstack((x1, y1, x2, y2))
h, w = featuresize
shift_x = np.arange(0, w) * scale
shift_y = np.arange(0, h) * scale
# apply shift
anchor = []
for i in shift_y:
for j in shift_x:
anchor.append(base_anchor + [j, i, j, i])
return np.array(anchor).reshape((-1, 4))
def bbox_transfor_inv(anchor, regr):
"""
return predict bbox
"""
Cya = (anchor[:, 1] + anchor[:, 3]) * 0.5
ha = anchor[:, 3] - anchor[:, 1] + 1
Vcx = regr[0, :, 0]
Vhx = regr[0, :, 1]
Cyx = Vcx * ha + Cya
hx = np.exp(Vhx) * ha
xt = (anchor[:, 0] + anchor[:, 2]) * 0.5
x1 = xt - 16 * 0.5
y1 = Cyx - hx * 0.5
x2 = xt + 16 * 0.5
y2 = Cyx + hx * 0.5
bbox = np.vstack((x1, y1, x2, y2)).transpose()
return bbox
def clip_box(bbox, im_shape):
# x1 >= 0
bbox[:, 0] = np.maximum(np.minimum(bbox[:, 0], im_shape[1] - 1), 0)
# y1 >= 0
bbox[:, 1] = np.maximum(np.minimum(bbox[:, 1], im_shape[0] - 1), 0)
# x2 < im_shape[1]
bbox[:, 2] = np.maximum(np.minimum(bbox[:, 2], im_shape[1] - 1), 0)
# y2 < im_shape[0]
bbox[:, 3] = np.maximum(np.minimum(bbox[:, 3], im_shape[0] - 1), 0)
return bbox
def filter_bbox(bbox, minsize):
ws = bbox[:, 2] - bbox[:, 0] + 1
hs = bbox[:, 3] - bbox[:, 1] + 1
keep = np.where((ws >= minsize) & (hs >= minsize))[0]
return keep
def nms(dets, thresh):
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep
class Graph:
def __init__(self, graph):
self.graph = graph
def sub_graphs_connected(self):
sub_graphs = []
for index in range(self.graph.shape[0]):
if not self.graph[:, index].any() and self.graph[index, :].any():
v = index
sub_graphs.append([v])
while self.graph[v, :].any():
v = np.where(self.graph[v, :])[0][0]
sub_graphs[-1].append(v)
return sub_graphs
class TextLineCfg:
SCALE = 600
MAX_SCALE = 1200
TEXT_PROPOSALS_WIDTH = 16
MIN_NUM_PROPOSALS = 2
MIN_RATIO = 0.5
LINE_MIN_SCORE = 0.9
MAX_HORIZONTAL_GAP = 60
TEXT_PROPOSALS_MIN_SCORE = 0.7
TEXT_PROPOSALS_NMS_THRESH = 0.3
MIN_V_OVERLAPS = 0.6
MIN_SIZE_SIM = 0.6
class Graph:
def __init__(self, graph):
self.graph = graph
def sub_graphs_connected(self):
sub_graphs = []
for index in range(self.graph.shape[0]):
if not self.graph[:, index].any() and self.graph[index, :].any():
v = index
sub_graphs.append([v])
while self.graph[v, :].any():
v = np.where(self.graph[v, :])[0][0]
sub_graphs[-1].append(v)
return sub_graphs
class TextProposalGraphBuilder:
"""
Build Text proposals into a graph.
"""
def get_successions(self, index):
box = self.text_proposals[index]
results = []
for left in range(int(box[0]) + 1, min(int(box[0]) + TextLineCfg.MAX_HORIZONTAL_GAP + 1, self.im_size[1])):
adj_box_indices = self.boxes_table[left]
for adj_box_index in adj_box_indices:
if self.meet_v_iou(adj_box_index, index):
results.append(adj_box_index)
if len(results) != 0:
return results
return results
def get_precursors(self, index):
box = self.text_proposals[index]
results = []
for left in range(int(box[0]) - 1, max(int(box[0] - TextLineCfg.MAX_HORIZONTAL_GAP), 0) - 1, -1):
adj_box_indices = self.boxes_table[left]
for adj_box_index in adj_box_indices:
if self.meet_v_iou(adj_box_index, index):
results.append(adj_box_index)
if len(results) != 0:
return results
return results
def is_succession_node(self, index, succession_index):
precursors = self.get_precursors(succession_index)
if self.scores[index] >= np.max(self.scores[precursors]):
return True
return False
def meet_v_iou(self, index1, index2):
def overlaps_v(index1, index2):
h1 = self.heights[index1]
h2 = self.heights[index2]
y0 = max(self.text_proposals[index2][1], self.text_proposals[index1][1])
y1 = min(self.text_proposals[index2][3], self.text_proposals[index1][3])
return max(0, y1 - y0 + 1) / min(h1, h2)
def size_similarity(index1, index2):
h1 = self.heights[index1]
h2 = self.heights[index2]
return min(h1, h2) / max(h1, h2)
return overlaps_v(index1, index2) >= TextLineCfg.MIN_V_OVERLAPS and \
size_similarity(index1, index2) >= TextLineCfg.MIN_SIZE_SIM
def build_graph(self, text_proposals, scores, im_size):
self.text_proposals = text_proposals
self.scores = scores
self.im_size = im_size
self.heights = text_proposals[:, 3] - text_proposals[:, 1] + 1
boxes_table = [[] for _ in range(self.im_size[1])]
for index, box in enumerate(text_proposals):
boxes_table[int(box[0])].append(index)
self.boxes_table = boxes_table
graph = np.zeros((text_proposals.shape[0], text_proposals.shape[0]), np.bool)
for index, box in enumerate(text_proposals):
successions = self.get_successions(index)
if len(successions) == 0:
continue
succession_index = successions[np.argmax(scores[successions])]
if self.is_succession_node(index, succession_index):
# NOTE: a box can have multiple successions(precursors) if multiple successions(precursors)
# have equal scores.
graph[index, succession_index] = True
return Graph(graph)
class TextProposalConnectorOriented:
"""
Connect text proposals into text lines
"""
def __init__(self):
self.graph_builder = TextProposalGraphBuilder()
def group_text_proposals(self, text_proposals, scores, im_size):
graph = self.graph_builder.build_graph(text_proposals, scores, im_size)
return graph.sub_graphs_connected()
def fit_y(self, X, Y, x1, x2):
# len(X) != 0
# if X only include one point, the function will get line y=Y[0]
if np.sum(X == X[0]) == len(X):
return Y[0], Y[0]
p = np.poly1d(np.polyfit(X, Y, 1))
return p(x1), p(x2)
def get_text_lines(self, text_proposals, scores, im_size):
"""
text_proposals:boxes
"""
# tp=text proposal
tp_groups = self.group_text_proposals(text_proposals, scores, im_size) # 首先还是建图,获取到文本行由哪几个小框构成
text_lines = np.zeros((len(tp_groups), 8), np.float32)
for index, tp_indices in enumerate(tp_groups):
text_line_boxes = text_proposals[list(tp_indices)] # 每个文本行的全部小框
X = (text_line_boxes[:, 0] + text_line_boxes[:, 2]) / 2 # 求每一个小框的中心x,y坐标
Y = (text_line_boxes[:, 1] + text_line_boxes[:, 3]) / 2
z1 = np.polyfit(X, Y, 1) # 多项式拟合,根据之前求的中心店拟合一条直线(最小二乘)
x0 = np.min(text_line_boxes[:, 0]) # 文本行x坐标最小值
x1 = np.max(text_line_boxes[:, 2]) # 文本行x坐标最大值
offset = (text_line_boxes[0, 2] - text_line_boxes[0, 0]) * 0.5 # 小框宽度的一半
# 以全部小框的左上角这个点去拟合一条直线,然后计算一下文本行x坐标的极左极右对应的y坐标
lt_y, rt_y = self.fit_y(text_line_boxes[:, 0], text_line_boxes[:, 1], x0 + offset, x1 - offset)
# 以全部小框的左下角这个点去拟合一条直线,然后计算一下文本行x坐标的极左极右对应的y坐标
lb_y, rb_y = self.fit_y(text_line_boxes[:, 0], text_line_boxes[:, 3], x0 + offset, x1 - offset)
score = scores[list(tp_indices)].sum() / float(len(tp_indices)) # 求全部小框得分的均值作为文本行的均值
text_lines[index, 0] = x0
text_lines[index, 1] = min(lt_y, rt_y) # 文本行上端 线段 的y坐标的小值
text_lines[index, 2] = x1
text_lines[index, 3] = max(lb_y, rb_y) # 文本行下端 线段 的y坐标的大值
text_lines[index, 4] = score # 文本行得分
text_lines[index, 5] = z1[0] # 根据中心点拟合的直线的k,b
text_lines[index, 6] = z1[1]
height = np.mean((text_line_boxes[:, 3] - text_line_boxes[:, 1])) # 小框平均高度
text_lines[index, 7] = height + 2.5
text_recs = np.zeros((len(text_lines), 9), np.float)
index = 0
for line in text_lines:
b1 = line[6] - line[7] / 2 # 根据高度和文本行中心线,求取文本行上下两条线的b值
b2 = line[6] + line[7] / 2
x1 = line[0]
y1 = line[5] * line[0] + b1 # 左上
x2 = line[2]
y2 = line[5] * line[2] + b1 # 右上
x3 = line[0]
y3 = line[5] * line[0] + b2 # 左下
x4 = line[2]
y4 = line[5] * line[2] + b2 # 右下
disX = x2 - x1
disY = y2 - y1
width = np.sqrt(disX * disX + disY * disY) # 文本行宽度
fTmp0 = y3 - y1 # 文本行高度
fTmp1 = fTmp0 * disY / width
x = np.fabs(fTmp1 * disX / width) # 做补偿
y = np.fabs(fTmp1 * disY / width)
if line[5] < 0:
x1 -= x
y1 += y
x4 += x
y4 -= y
else:
x2 += x
y2 += y
x3 -= x
y3 -= y
text_recs[index, 0] = x1
text_recs[index, 1] = y1
text_recs[index, 2] = x2
text_recs[index, 3] = y2
text_recs[index, 4] = x3
text_recs[index, 5] = y3
text_recs[index, 6] = x4
text_recs[index, 7] = y4
text_recs[index, 8] = line[4]
index = index + 1
return text_recs
"""
调用
"""
def get_det_boxes(image,display = True, expand = True):
# image = resize(image, height=height)
image_r = image.copy()
image_c = image.copy()
h, w = image.shape[:2]
image = image.astype(np.float32) - IMAGE_MEAN
image = torch.from_numpy(image.transpose(2, 0, 1)).unsqueeze(0).float()
with torch.no_grad():
image = image.to(device)
cls, regr = model(image)
cls_prob = F.softmax(cls, dim=-1).cpu().numpy()
regr = regr.cpu().numpy()
anchor = gen_anchor((int(h / 16), int(w / 16)), 16)
bbox = bbox_transfor_inv(anchor, regr)
bbox = clip_box(bbox, [h, w])
# print(bbox.shape)
fg = np.where(cls_prob[0, :, 1] > prob_thresh)[0]
# print(np.max(cls_prob[0, :, 1]))
select_anchor = bbox[fg, :]
select_score = cls_prob[0, fg, 1]
select_anchor = select_anchor.astype(np.int32)
# print(select_anchor.shape)
keep_index = filter_bbox(select_anchor, 16)
# nms
select_anchor = select_anchor[keep_index]
select_score = select_score[keep_index]
select_score = np.reshape(select_score, (select_score.shape[0], 1))
nmsbox = np.hstack((select_anchor, select_score))
keep = nms(nmsbox, 0.3)
# print(keep)
select_anchor = select_anchor[keep]
select_score = select_score[keep]
# text line-
textConn = TextProposalConnectorOriented()
text = textConn.get_text_lines(select_anchor, select_score, [h, w])
# expand text
if expand:
for idx in range(len(text)):
text[idx][0] = max(text[idx][0] - 10, 0)
text[idx][2] = min(text[idx][2] + 10, w - 1)
text[idx][4] = max(text[idx][4] - 10, 0)
text[idx][6] = min(text[idx][6] + 10, w - 1)
if display:
blank = np.zeros(image_c.shape,dtype=np.uint8)
for box in select_anchor:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
print(pt1, pt2)
cv2.rectangle(image_c,pt1, pt2, (0, 0, 0))
return [pt1, pt2],image_c #返回检测框,画框图片
def single_pic_proc(image_file):
image = np.array(Image.open(image_file).convert('RGB'))
_, img = get_det_boxes(image)
return img
if __name__ == '__main__':
"""
上传图片路径
返回图片和坐标
"""
url = '/home/zc/桌面/pythonProject2/imgs/91110101MA00BEU57K.jpg'
img = single_pic_proc(url)
Image.fromarray(img).save('./op.jpg')

希望这篇文章对你有用!
谢谢点赞评论!