堆排序算法及其稳定性分析
什么是堆排序?
堆排序是利用数据结构堆而设计的一种排序算法。
堆分为两种,大顶堆和小顶堆。
所谓大顶堆就是每个节点的值都大于或者等于其左右孩子节点的值。
小顶堆则是相反的,每个节点的值都小于或者等于其左右孩子节点的值。
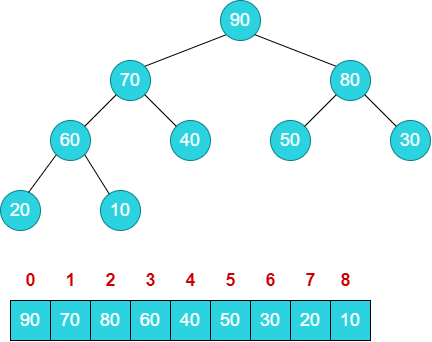
下面是一个大顶堆的示例,其拥有下面的性质:
arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
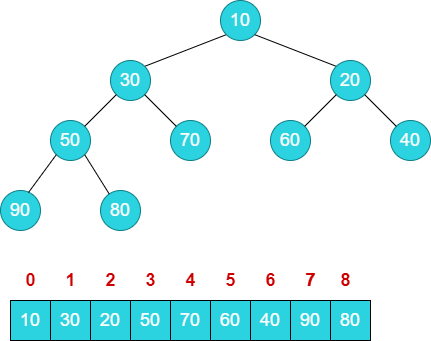
下面是一个小顶堆的实例,其拥有下面的性质:
arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
大顶堆和小顶堆数据结构是堆排序的基础,下面就看堆排序是如何利用堆来进行排序的。
堆排序的步骤如下:
- 1.将原始数组转换成一个大顶堆(如果要求升序)或者小顶堆(如果要求降序)。
- 2.将大顶堆或者小顶堆的首元素与最后一个元素交换
- 3.剔除尾部元素,将剩下的元素重新构成一个大顶堆或者小顶堆,重复2。
以一个例子来看一下上述过程是怎样的。
原始数组arr = [3,1,4,5,2], 对其进行升序。
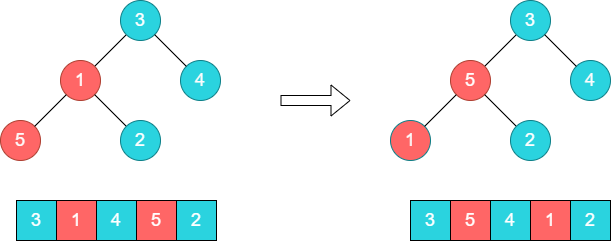
步骤1:首先将原数组构建成一个大顶堆。首先从叶子节点开始,将1和5进行对调。
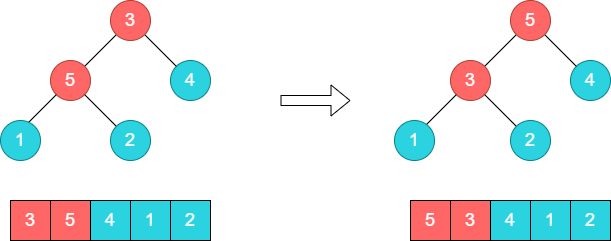
步骤2:继续进行调整,将5和3进行对调,此时已经成为了一个大顶堆。
步骤3:将堆顶元素5和尾部元素2进行对调。
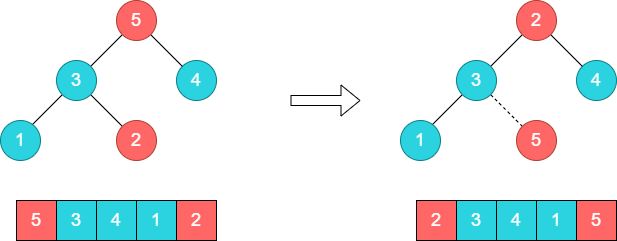
步骤4:重新构建一个大顶堆。将2和4进行对调。
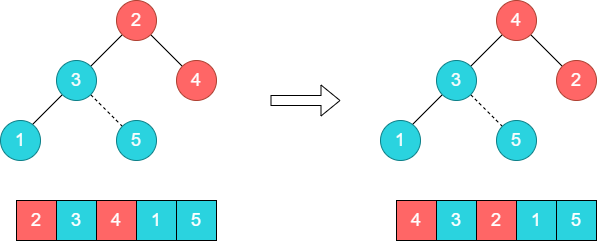
步骤5:将堆顶元素4和尾部元素1进行对调。
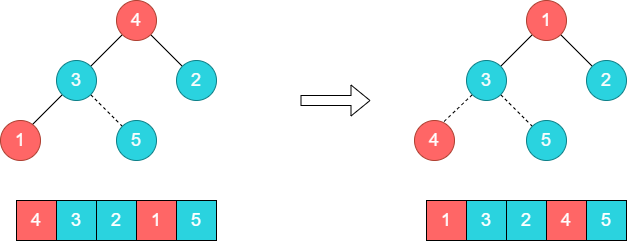
步骤6:重新构建一个大顶堆。将元素1和3进行对调。
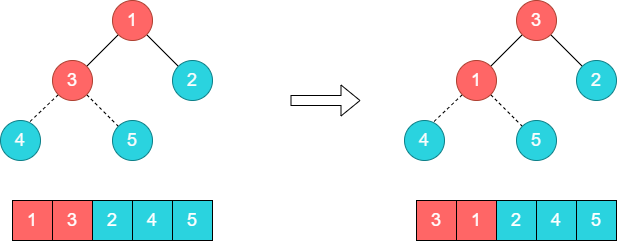
步骤7:将堆顶元素3和尾部元素2进行对调。
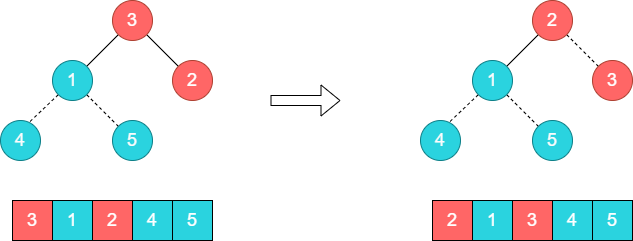
步骤8:将堆顶元素2和尾部元素1进行对调。

复杂度:
时间复杂度: O ( n l o g n ) O(nlogn) O(nlogn)
空间复杂度为: O ( 1 ) O(1) O(1)。没有使用额外的存储空间。
堆排序的代码实现
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
typedef int Status;
#define MAXSIZE 10000 /* 用于要排序数组个数最大值,可根据需要修改 */
typedef struct
{
int r[MAXSIZE+1]; /* 用于存储要排序数组,r[0]用作哨兵或临时变量 */
int length; /* 用于记录顺序表的长度 */
}SqList;
/* 交换L中数组r的下标为i和j的值 */
void swap(SqList *L,int i,int j)
{
int temp=L->r[i];
L->r[i]=L->r[j];
L->r[j]=temp;
}
void print(SqList L)
{
int i;
for(i=1;i<L.length;i++)
printf("%d,",L.r[i]);
printf("%d",L.r[i]);
printf("\n");
}
/* 已知L->r[s..m]中记录的关键字除L->r[s]之外均满足堆的定义, */
/* 本函数调整L->r[s]的关键字,使L->r[s..m]成为一个大顶堆 */
void HeapAdjust(SqList *L,int s,int m)
{
int temp,j;
temp=L->r[s];
for(j=2*s;j<=m;j*=2) /* 沿关键字较大的孩子结点向下筛选 */
{
if(j<m && L->r[j]<L->r[j+1])
++j; /* j为关键字中较大的记录的下标 */
if(temp>=L->r[j])
break; /* rc应插入在位置s上 */
L->r[s]=L->r[j];
s=j;
}
L->r[s]=temp; /* 插入 */
}
/* 对顺序表L进行堆排序 */
void HeapSort(SqList *L)
{
int i;
for(i=L->length/2;i>0;i--) /* 把L中的r构建成一个大根堆 */
HeapAdjust(L,i,L->length);
for(i=L->length;i>1;i--)
{
swap(L,1,i); /* 将堆顶记录和当前未经排序子序列的最后一个记录交换 */
HeapAdjust(L,1,i-1); /* 将L->r[1..i-1]重新调整为大根堆 */
}
}
/* **************************************** */
#define N 9
int main()
{
int i;
/* int d[N]={9,1,5,8,3,7,4,6,2}; */
int d[N]={
50,10,90,30,70,40,80,60,20};
/* int d[N]={9,8,7,6,5,4,3,2,1}; */
SqList l0,l1,l2,l3,l4,l5,l6,l7,l8,l9,l10;
for(i=0;i<N;i++)
l0.r[i+1]=d[i];
l0.length=N;
l1=l2=l3=l4=l5=l6=l7=l8=l9=l10=l0;
printf("排序前:\n");
print(l0);
printf("堆排序:\n");
HeapSort(&l6);
print(l6);
return 0;
}
稳定性分析
稳定性就是指对于两个关键字相等的记录,它们在序列中的相对位置,在排序之前和排序之后没有发生改变。通俗地讲就是有两个关键字相等的数据A、B,排序前,A的位置是 i ,B的位置是 j,此时 i < j,则如果在排序后A的位置还是在B之前,那么称它是稳定的。
那么堆排序是一个稳定排序吗?
堆排序的稳定性分析
直接上答案堆排序并不是一个稳定排序。
堆排序的会将原始的数组转化成一个大顶堆或一个小顶堆,在输出堆顶后,此时需要维护堆,操作如下:
(1)堆顶与堆尾交换并删除堆尾,被删除的堆尾的元素就是输出过的元素
(2)把当前堆顶向下调整,直到满足构成堆的条件,重复(1)步骤
在堆顶与堆尾交换的时候两个相等的记录在序列中的相对位置就可能发生改变,这就影响其稳定性了。
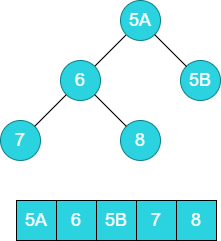
下面看一个实际的例子, [5A,6,5B,7,8] ,A和B用于区分相同元素。
数组的原始的状态如下所示:
首先调整下方的子树[6,7,8],将8和6的位置调换。
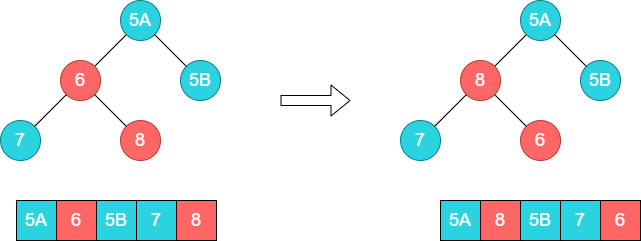
接着调整下方的子树[5A,8,5B],将8和5A的位置调换。
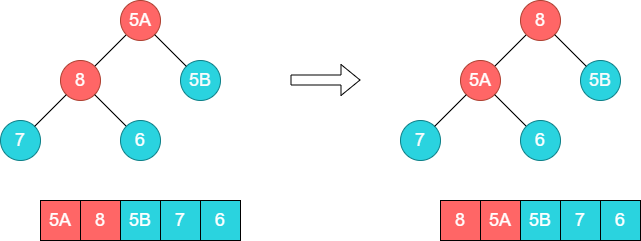
由于5A和8位置的调换,需要重新调整下方的子树[5A,7,6],将5A和7的位置调换。这个时候5A和5B的顺序就出现了一次乱序。
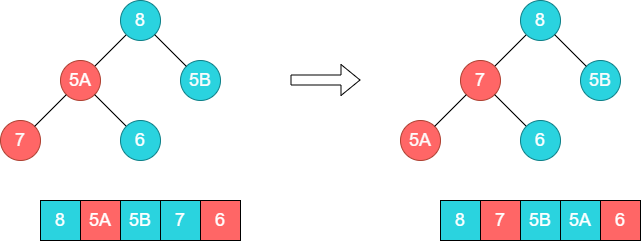
至此,第一轮排序完毕,将8和数组尾部元素6交换。
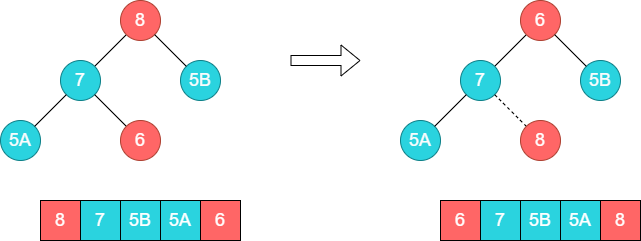
接着调整顶部的子树[6,7,5B],将7和6的位置调换。
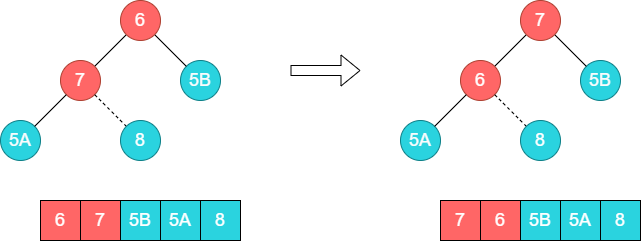
这个时候第二轮排序已经结束,此时可以将7和数组尾部元素5A进行调整。
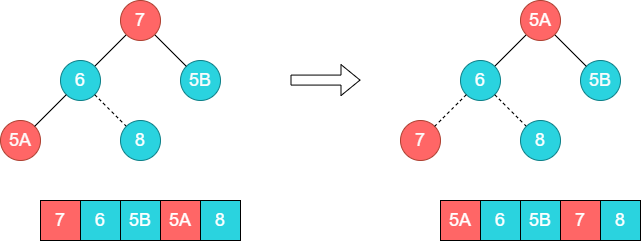
接着调整顶部的子树[5A,6,5B],将6和5A的位置调换。
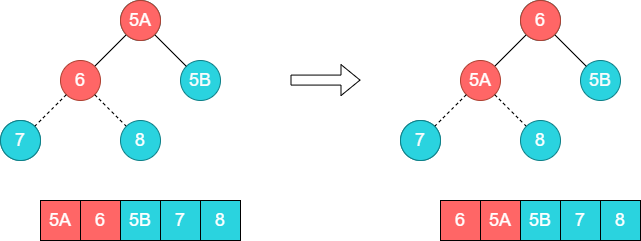
这个时候第三轮排序已经结束,此时可以将6和数组尾部元素5B进行调整。

剩下的元素已经满足了排序的要求,于是直接输出结果。
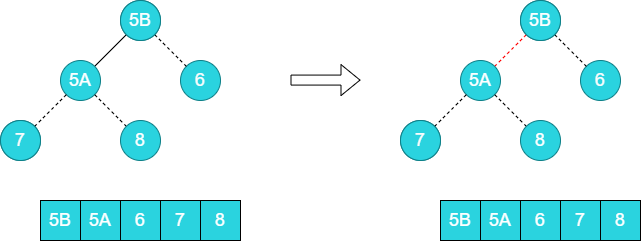
至此[5A,6,5B,7,8] 排序为 [5B,5A,6,7,8]。可以看到5A和5B的关系发生了变化。
通过这个例子也证明了堆排序不是一个稳定排序。