
手写SE Layer
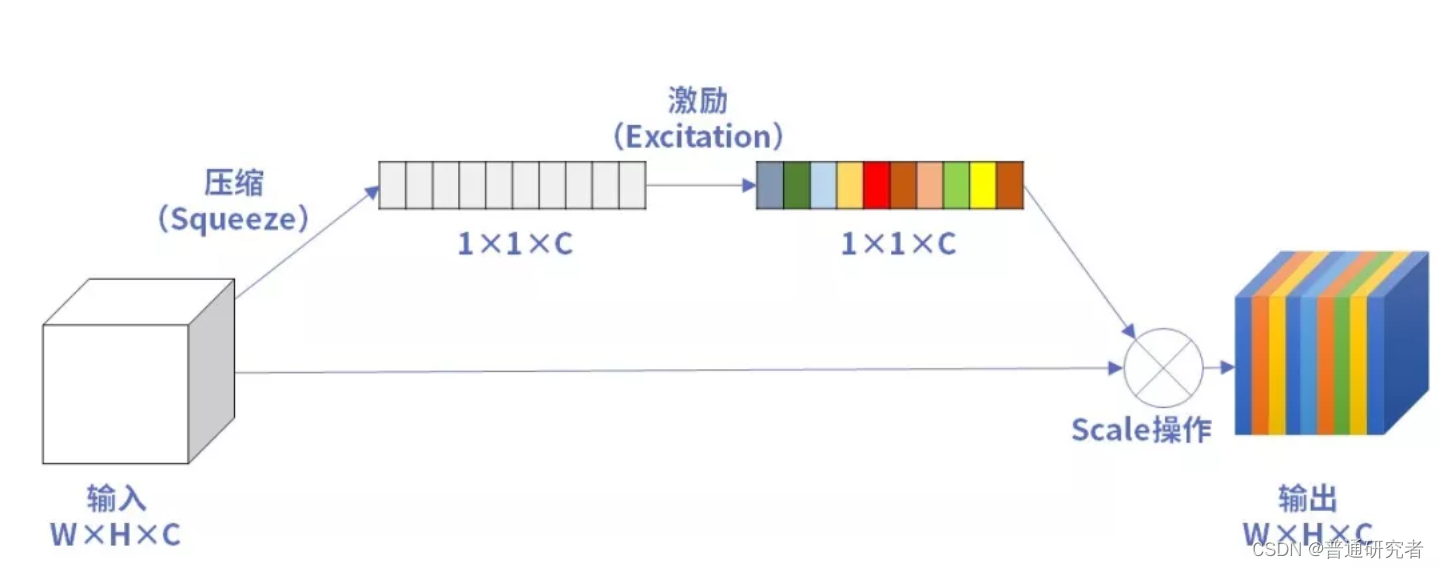
SE (Squeeze-and-Excitation) Layer是一种注意力机制,通常应用于深度神经网络的不同层次,以提高模型的表示能力。SE Layer主要包含两个步骤:Squeeze和Excitation。以下是一个简单的手写SE Layer的Python实现:
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SELayer(nn.Module):
def __init__(self, channels, reduction_ratio=16):
super(SELayer, self).__init__()
self.channels = channels
self.reduction_ratio = reduction_ratio
# Squeeze操作
self.squeeze = nn.AdaptiveAvgPool2d(1)
# Excitation操作
self.excitation = nn.Sequential(
nn.Linear(channels, channels // reduction_ratio),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction_ratio, channels),
nn.Sigmoid()
)
def forward(self, x):
# Squeeze
squeezed = self.squeeze(x)
squeezed = squeezed.view(-1, self.channels)
# Excitation
excitation = self.excitation(squeezed)
excitation = excitation.view(-1, self.channels, 1, 1)
# Scale输入特征
scaled_inputs = x * excitation
return scaled_inputs
# 使用例子
input_tensor = torch.randn((1, 64, 224, 224))
se_layer = SELayer(channels=64)
output = se_layer(input_tensor)
print(output.shape)
手写NMS
非极大值抑制(NMS)是一种常用于目标检测中的技术,用于筛选具有最高置信度的边界框,并抑制与其重叠较大的其他边界框。以下是一个简单的手写NMS的Python实现:
def non_max_suppression(boxes, scores, threshold):
"""
非极大值抑制
参数:
- boxes: 边界框列表,每个边界框表示为 [x1, y1, x2, y2]
- scores: 边界框对应的置信度列表
- threshold: 重叠阈值,大于该阈值的边界框将被抑制
返回:
- selected_indices: 选中的边界框的索引
"""
selected_indices = []
# 根据置信度排序
order = scores.argsort()[::-1]
while len(order) > 0:
# 选取置信度最高的边界框
i = order[0]
selected_indices.append(i)
# 计算当前边界框与其他边界框的IoU(交并比)
x1 = max(boxes[i][0], boxes[order[1:], 0])
y1 = max(boxes[i][1], boxes[order[1:], 1])
x2 = min(boxes[i][2], boxes[order[1:], 2])
y2 = min(boxes[i][3], boxes[order[1:], 3])
intersection = max(0, x2 - x1) * max(0, y2 - y1)
area_i = (boxes[i][2] - boxes[i][0]) * (boxes[i][3] - boxes[i][1])
area_others = (boxes[order[1:], 2] - boxes[order[1:], 0]) * (boxes[order[1:], 3] - boxes[order[1:], 1])
iou = intersection / (area_i + area_others - intersection)
# 保留IoU小于阈值的边界框
mask = iou <= threshold
order = order[1:][mask]
return selected_indices
# 使用例子
boxes = [[100, 100, 200, 200], [150, 150, 250, 250], [100, 120, 180, 200]]
scores = [0.9, 0.8, 0.75]
threshold = 0.5
selected_indices = non_max_suppression(boxes, scores, threshold)
print("Selected Indices:", selected_indices)
这个例子中,non_max_suppression函数接受边界框列表、对应的置信度列表以及重叠阈值作为输入,返回选中的边界框的索引。在函数内部,首先根据置信度对边界框进行降序排序,然后依次选取置信度最高的边界框,计算其与其他边界框的IoU,并保留IoU小于阈值的边界框。这个过程重复进行,直到所有边界框都被处理完毕。这样就得到了最终选中的边界框索引。
手写IoU
Intersection over Union(IoU),或称为交并比,是一种用于衡量两个边界框重叠程度的指标。以下是一个简单的手写IoU的Python实现:
def calculate_iou(box1, box2):
"""
计算两个边界框的IoU(交并比)
参数:
- box1: 第一个边界框,表示为 [x1, y1, x2, y2]
- box2: 第二个边界框,表示为 [x1, y1, x2, y2]
返回:
- iou: 交并比
"""
# 计算交集的坐标
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
# 计算交集的面积
intersection = max(0, x2 - x1) * max(0, y2 - y1)
# 计算并集的面积
area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
union = area_box1 + area_box2 - intersection
# 计算交并比
iou = intersection / union if union > 0 else 0.0
return iou
# 使用例子
box1 = [100, 100, 200, 200]
box2 = [150, 150, 250, 250]
iou = calculate_iou(box1, box2)
print("IoU:", iou)
在这个例子中,calculate_iou函数接受两个边界框作为输入,并计算它们的交并比。函数首先计算两个边界框的交集坐标和面积,然后计算它们的并集面积,最后通过交集和并集的比值得到交并比。这个函数返回一个在 [0, 1] 范围内的值,表示两个边界框的重叠程度。
对比YOLOv1与YOLOv3
YOLO(You Only Look Once)是一系列目标检测算法,其中YOLOv1(发布于2016年)和YOLOv3(发布于2018年)是其中的两个版本。以下是YOLOv1和YOLOv3之间的一些主要对比:
1. 网络结构和复杂性:
YOLOv1:
使用全连接层,没有使用卷积层,导致网络参数较多。
单一尺度的预测。
YOLOv3:
使用卷积层构建Darknet-53作为特征提取网络,提高了特征学习能力。
采用多尺度预测,利用不同层次的特征进行目标检测。
2. 多尺度预测:
YOLOv1:
仅在最后的输出层进行目标检测,对小目标检测效果不理想。
YOLOv3:
利用FPN(Feature Pyramid Network)结构,从不同层次的特征图中进行目标检测,有助于处理不同尺寸的目标。
3. 锚框(Anchor Boxes):
YOLOv1:
采用预定义的边界框,但没有使用锚框的概念。
YOLOv3:
引入锚框,允许模型学习不同目标形状的特征。每个尺度的特征图使用不同数量和大小的锚框。
4. 类别数和输出通道数:
YOLOv1:
针对20个类别进行训练。
YOLOv3:
通常在更大的数据集上进行训练,支持更多的类别。
5. 性能:
YOLOv1:
相对较慢,性能略低。
YOLOv3:
通过网络结构的改进和使用多尺度预测,实现了更高的检测精度和更好的泛化性能。
6. 技术创新:
YOLOv1:
第一个端到端的实时目标检测系统。
YOLOv3:
引入了多尺度预测、锚框等技术,提高了检测性能。
总体而言,YOLOv3在网络结构、性能和功能上都有显著的改进,尤其是引入了多尺度预测、锚框等机制,使得它更适用于不同尺寸和形状的目标检测任务。
过拟合除了正则化有哪些解决方案
过拟合是指机器学习模型在训练集上表现得过于优越,而在未见过的数据上表现较差的现象。这通常是由于模型过度学习训练数据中的噪声和特定样本的细节,而失去了对整体数据分布的泛化能力。除了正则化外,还存在多种解决方案用于缓解过拟合。
一种常见的方法是数据增强,通过对训练数据进行随机变换,生成新的训练样本,从而扩充训练集。这有助于模型学到更多的不变性,提高泛化能力。早停是另一种简单而有效的策略,通过监控验证集性能,在模型性能达到峰值后停止训练,以防止过度拟合。集成学习通过组合多个模型的预测结果来提高性能,减少单个模型的过拟合风险。Dropout是一种在训练中随机禁用神经网络中的一些单元的方法,有助于防止模型对某些特征的过度依赖。
其他策略包括权重衰减,通过在损失函数中添加权重的平方和或绝对值和对模型参数进行正则化;模型简化,即选择更简单的模型结构;特征选择,通过选择更具代表性的特征集;以及交叉验证,通过多次划分训练集和验证集来评估模型性能。这些方法可以单独或组合使用,具体选择取决于问题的性质和数据的特点。在实践中,通过综合考虑多种方法,可以找到最佳的缓解过拟合的策略,从而提高模型的泛化能力。
小目标如何去改进
解决小目标检测问题是目标检测领域中的一个重要挑战,因为小目标通常由于尺寸小、像素稀疏等原因而容易被忽略。为了提高对小目标的准确性,研究者们提出了一系列改进方法。首先,图像金字塔和特征金字塔的引入使得模型能够在不同尺度下进行检测,从而更全面地捕捉目标。通过在网络中加入对高分辨率特征的学习,有助于网络更好地捕捉小目标的细节信息。另外,对锚框的尺寸进行调整,使其更适合小目标,是一种常见的策略。IoU抑制阶段采用较小的IoU阈值,可以更容易保留多个小目标的检测框。正则化技术的加强,如Dropout或权重衰减,有助于防止网络过拟合训练数据中的大目标,使其更好地适应小目标。数据增强策略,如随机缩放、裁剪和旋转,有助于模型更好地理解小目标在不同场景下的变化。迁移学习和使用软标签也是提高小目标检测性能的有效手段。这些方法的组合和调整通常是实现更精准小目标检测的关键,需要结合具体问题和数据集的特征进行综合考虑。通过不断改进和调优这些方法,可以有效提高模型对小目标的检测精度和泛化能力。