
论文代码地址:动态蛇形卷积官方代码下载地址
论文地址:【免费】动态蛇形卷积(DynamicSnakeConvolution)资源-CSDN文库

本文介绍
动态蛇形卷积的灵感来源于对管状结构的特殊性的观察和理解,在分割拓扑管状结构、血管和道路等类型的管状结构时,任务的复杂性增加,因为这些结构的局部结构可能非常细长和迂回,而整体形态也可能多变。
因此为了应对这个挑战,作者研究团队注意到了管状结构的特殊性,并提出了动态蛇形卷积(Dynamic Snake Convolution)这个方法。动态蛇形卷积通过自适应地聚焦于细长和迂回的局部结构,准确地捕捉管状结构的特征。这种卷积方法的核心思想是,通过动态形状的卷积核来增强感知能力,针对管状结构的特征提取进行优化。
总之动态蛇形卷积是一种针对管状结构分割任务的创新方法,在许多模型上添加针对一些数据集都能够有效的涨点,其具有重要性和广泛的应用领域。
动态蛇形卷积(Dynamic Snake Convolution)适用于多种模型,可以在多种模型上添加或替换该卷积,本文主要针对的改进模型是YOLOv8模型,并修复动态蛇形卷积官方代码中存在的BUG例如: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!修复,同时以此来进行示例帮助大家理解和掌握动态蛇形卷积和YOLOv8模型。
PS->如果你只想学会如何修改如何在yolov8中添加动态蛇形卷积而不想学习其原理则可以直接忽略此下大部分,直接跳读到官方代码Bug修复的章节阅读该章节和之后的章节即可。
YOLOv8介绍
YOLO(You Only Look Once)系列算法因其高效、准确等特点而备受瞩目。由2023年Ultralytics公司发布了YOLO的最新版本YOLOv8是结合前几代YOLO的基础上的一个融合改进版,进行了深度优化,使得其在速度和准确率方面更出色。
如果想要深入了解和学习YOLOv8建议大家阅读以下文章,本文主要是如何改进动态蛇形卷积(Dynamic Snake Convolution)。
详解YOLOv8网络结构/环境搭建/数据集获取/训练/推理/验证/导出/部署全程干货
动态蛇形卷积背景和原理
背景->动态蛇形卷积(Dynamic Snake Convolution)来源于临床医学,清晰勾画血管是计算流体力学研究的关键前提,并能协助放射科医师进行诊断和定位病变。在遥感应用中,完整的道路分割为路径规划提供了坚实的基础。无论是哪个领域,这些结构都具有细长和曲折的共同特征,使得它们很难在图像中捕捉到,因为它们在图像中的比例很小。因此,迫切需要提升对细长管状结构的感知能力,所以在这一背景下作者提出了动态蛇形卷积(Dynamic Snake Convolution)。

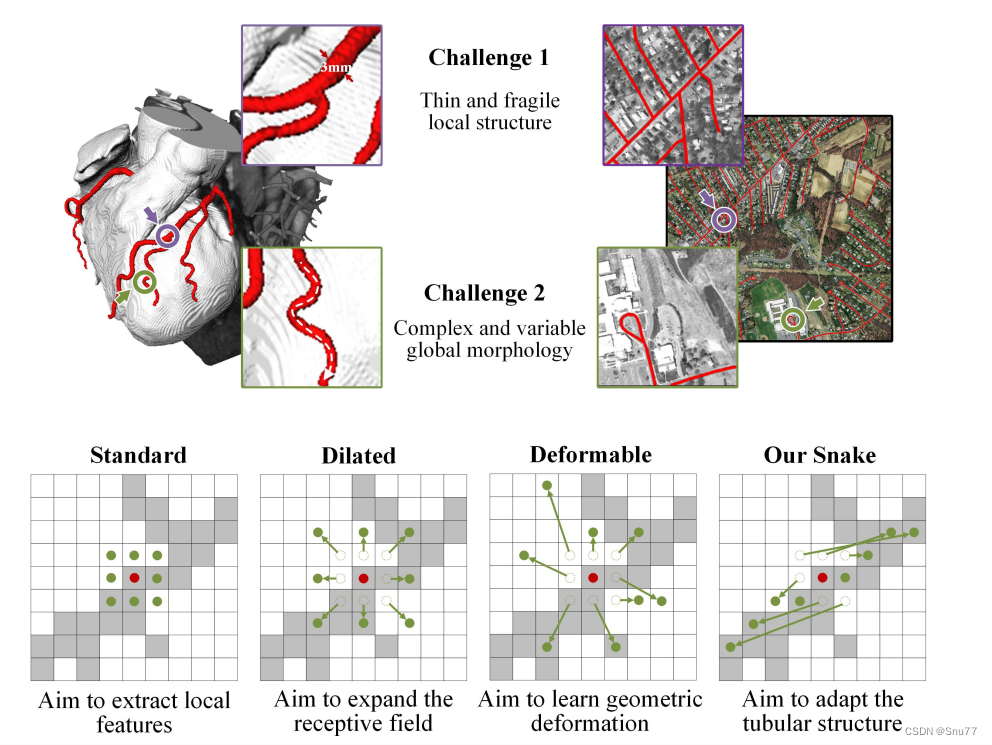
原理->上图展示了一个三维心脏血管数据集和一个二维远程道路数据集。这两个数据集旨在提取管状结构,但由于脆弱的局部结构和复杂的整体形态,这个任务面临着挑战。标准的卷积核旨在提取局部特征。基于此,设计了可变形卷积核以丰富它们的应用,并适应不同目标的几何变形。然而,由于前面提到的挑战,有效地聚焦于细小的管状结构是困难的。
由于以下困难,这仍然是一个具有挑战性的任务:
-
细小而脆弱的局部结构:如上面的图所示,细小的结构仅占整体图像的一小部分,并且由于像素组成有限,这些结构容易受到复杂背景的干扰,使模型难以精确地区分目标的细微变化。因此,模型可能难以区分这些结构,导致分割结果出现断裂。
-
复杂而多变的整体形态:上面的图片展示了细小管状结构的复杂和多变形态,即使在同一图像中也如此。不同区域中的目标呈现出形态上的变化,包括分支数量、分叉位置和路径长度等。当数据呈现出前所未见的形态结构时,模型可能会过度拟合已经见过的特征,导致在新的形态结构下泛化能力较弱。
为了应对上述障碍,提出了如下解决方案,其中包括管状感知卷积核、多视角特征融合策略和拓扑连续性约束损失函数。具体如下:
1. 针对细小且脆弱的局部结构所占比例小且难以聚焦的挑战,提出了动态蛇形卷积,通过自适应地聚焦于管状结构的细长曲线局部特征,增强对几何结构的感知。与可变形卷积不同,DSConv考虑到管状结构的蛇形形态,并通过约束补充自由学习过程,有针对性地增强对管状结构的感知。
2. 针对复杂和多变的整体形态的挑战,提出了一种多视角特征融合策略。在该方法中,基于DSConv生成多个形态学卷积核模板,从不同角度观察目标的结构特征,并通过总结典型的重要特征实现高效的特征融合。
3. 针对管状结构分割容易出现断裂的问题,提出了基于持久同调(Persistent Homology,PH)的拓扑连续性约束损失函数(TCLoss)。PH是一种从出现到消失的拓扑特征响应过程,能够从嘈杂的高维数据中获取足够的拓扑信息。相关的贝蒂数是描述拓扑空间连通性的一种方式。与其他方法不同,TCLoss将PH与点集相似性相结合,引导网络关注具有异常像素/体素分布的断裂区域,从拓扑角度实现连续性约束。
总结:为了克服挑战,提出了DSCNet框架,包括管状感知卷积核、多视角特征融合策略和拓扑连续性约束损失函数。DSConv增强了对细长曲线特征的感知,多视角特征融合策略提高了对复杂整体形态的处理能力,而TCLoss基于持久同调实现了从拓扑角度的连续性约束。
动态蛇形卷积的优势
为了提高对管状结构的性能,已经提出了各种方法,根据管状结构的形态设计了特定的网络架构和模块。具体如下:
1. 基于卷积核设计的方法:著名的扩张卷积(dilated convolution)和可变形卷积(deformable convolution)等方法被提出来处理卷积神经网络中固有的几何变换限制,并在复杂的检测和分割任务中取得了出色的表现。这些方法还被设计用于动态感知对象的几何特征,以适应具有可变形态的结构。例如,DUNet。
2. 基于形态学的方法:一些方法专注于利用形态学信息来处理管状结构。例如,形态学重建网络(Morphological Reconstruction Network)利用形态学重建操作来重建管状结构,从而实现更准确的分割。另外,形态学操作如开运算和闭运算也被广泛应用于处理管状结构。
3. 基于拓扑学的方法:拓扑学方法被用来处理管状结构的拓扑特征。例如,基于持久同调(Persistent Homology)的方法可以从高维数据中获取拓扑信息,并用于分析管状结构的连通性和形态特征。
总结:为了处理管状结构,已经提出了多种方法。这些方法包括基于卷积核设计的方法、基于形态学的方法和基于拓扑学的方法。这些方法的目标是通过设计适应管状结构形态的网络架构和模块,提高对管状结构的检测和分割性能。
优势->以上所述的方法都只是从单一的角度去分析,DSConv提出了一种多角度特征融合策略,从多个角度补充对重要特征的关注。在这个策略中,基于动态蛇形卷积(DSConv)生成多个形态学卷积核模板,从多个角度观察目标的结构特征,并通过总结关键的标准特征实现特征融合,从而提高我们模型的性能。
实验和结果
数据集
使用了三个数据集来验证我们的框架,其中包括两个公开数据集和一个内部数据集。在2D方面,评估了DRIVE视网膜数据集和马萨诸塞道路数据集。在3D方面,使用了一个名为Cardiac CCTA Data的数据集。
实验
进行了比较实验和消融研究,以证明DSCN的优势。与经典的分割网络U-Net 和2021年提出的用于血管分割的CS2-Net 进行比较,以验证准确性。为了验证网络设计性能,将2022年提出的用于视网膜血管分割的DCU-Net 进行了比较。为了验证特征融合的优势,将2021年提出的用于医学图像分割的Transunet 进行了比较。为了验证损失函数约束,将2021年提出的clDice和基于Wasserstein距离的TCLoss LWTC进行了比较。这些模型在相同的数据集上进行训练,并进行了精确的实现,通过以下指标进行评估。所有指标都是针对每个图像进行计算并求平均。
1. 体积得分:使用平均Dice系数(Dice)、相对Dice系数(RDice)、中心线Dice(clDice)、准确度(ACC)和AUC来评估结果的性能。
2. 拓扑错误:计算基于拓扑的得分,包括Betti数β0和β1的Betti错误。同时,为了客观验证冠状动脉分割的连续性,使用直到第一个错误的重叠(OF)来评估提取的中心线的完整性。
3. 距离错误:Hausdorff距离(HD)也被广泛用于描述两组点之间的相似性,推荐用于评估薄管状结构的相似性。
实验结果
在下面的表格中展示了DSCNet方法在每个指标上的优势,结果表明提出的DSCNet在2D和3D数据集上取得了更好的结果。
在DRIVE数据集上的评估中,DSCNet在分割准确性和拓扑连续性方面均优于其他模型。在下面的表格中,与其他方法相比,DSCNet在体积准确性方面取得了最佳的分割结果,Dice系数为82.06%,RDice系数为90.17%,clDice系数为82.07%,准确度为96.87%,AUC为90.27%。同时,从拓扑的角度来看,与其他方法相比,DSCNet在拓扑连续性上取得了最好的结果,β0错误为0.998,β1错误为0.803。结果显示,DSCNet方法更好地捕捉了薄管状结构的特征,并展现出更准确的分割性能和更连续的拓扑结构。正如表格1中第6行到第12行所示,在引入TCLoss后,不同的模型在分割的拓扑连续性方面均有所改善。结果表明,TCLoss能够准确地约束模型关注失去拓扑连续性的薄管状结构。在ROADS数据集上的评估中,DSCNet同样取得了最佳结果。如表格1所示,与其他方法相比,提出的带有TCLoss的DSCNet在分割结果上取得了最佳的效果,Dice系数为78.21%,RDice系数为85.85%,clDice系数为87.64%。与经典的分割网络UNet的结果相比,DSCNet的方法在Dice系数、RDice系数和clDice系数上分别改善了最多1.31%、1.78%和0.77%。结果显示,与其他模型相比,DSCNet的模型在结构复杂且形态多变的道路数据集上也表现良好。
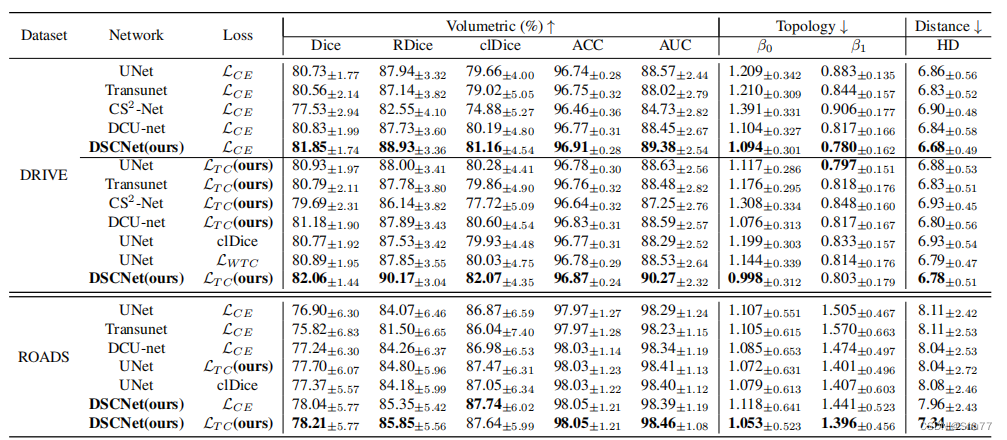
在CORONARY数据集上的评估中,验证了DSCNet在3D薄管状结构分割任务上仍然取得了最佳结果。如下面的表格所示,与其他方法相比,提出的DSCNet在分割结果上取得了最佳的效果,Dice系数为80.27%,RDice系数为86.37%,clDice系数为85.26%。与经典的分割网络UNet的结果相比,DSCNet方法在Dice系数、RDice系数和clDice系数上分别改善了最多3.40%、1.89%和3.83%。同时,使用OF指标来评估分割的连续性。使用DSCNet的方法,LAD的OF指标提升了6.00%,LCX的OF指标提升了3.78%,而RCA的OF指标提升了3.30%
 有效性展示
有效性展示
DSCNet和TCLoss在各个方面都具有决定性的视觉优势。
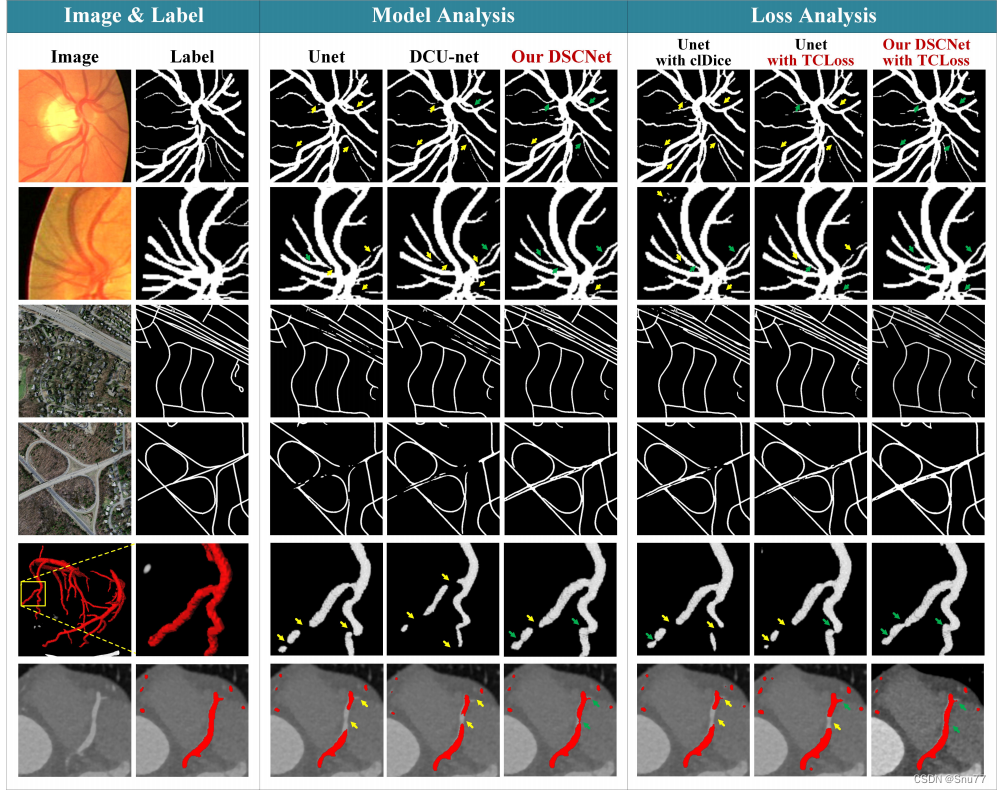
(1) 为了展示DSCNet的有效性下面的图片中。从左到右,第三到第五列展示了不同网络在分割准确性方面的表现。由于DSConv能够自适应地感知关键特征,DSCNet的方法在分割结果上表现出色。与其他方法相比,DSCNet的方法能够更好地捕捉和保留薄管状结构的细节。
(2) 为了验证DSCNet的TCLoss的有效性,第六列展示了在没有使用TCLoss的情况下的分割结果。可以看出,没有TCLoss的方法在拓扑连续性方面存在明显的问题,而DSCNet的方法能够通过TCLoss准确地约束分割结果的拓扑结构,使得分割结果更加连续。
(3) 在第七列和第八列中,展示了DSCNet在不同数据集上的分割结果。可以看到,DSCNet在DRIVE和ROADS数据集上都能取得准确且连续的分割结果,进一步证明了DSCNet的通用性和鲁棒性。
总的来说,从图6可以清楚地看到我们的DSCNet和TCLoss在分割准确性和拓扑连续性方面的显著优势,这进一步证明了我们方法的有效性和优越性。
DSConv能够动态地适应管状结构的形状,并且注意力能够很好地适配目标。
(1) 适应管状结构的形状。下面的图片中的顶部显示了卷积核的位置和形状。可视化结果显示,DSConv能够很好地适应管状结构并保持形状,而可变形卷积则在目标外部游走。
(2) 关注管状结构的位置。下面的图片的底部显示了给定点的注意力热力图。结果显示,DSConv最亮的区域集中在管状结构上,这表示DSConv对管状结构更加敏感。
这些结果表明,我们的DSConv能够有效地适应和关注管状结构,从而使得DSCNet能够更好地捕捉和分割这些结构。

应用和未来展望
DSCNet的框架很好地处理了薄管状结构的分割,并成功地将形态特征与拓扑知识相结合,引导模型适应分割任务。然而,其他形态目标是否能够以类似的范式取得更好的性能仍然是一个令人激动的课题。同时,更多的研究将探索在其他形态目标上应用类似范式的可能性。
DSCNet方法着眼于薄管状结构的分割,但是类似的思想和技术可能也适用于其他形态目标,如细长线条、细胞细长伸展等。通过将形态特征和拓扑知识结合起来,DSCNet的能够引导模型更好地适应不同形态目标的分割任务。
未来的研究可以探索如何将类似的范式应用于其他形态目标,并进一步改进和优化分割算法。这可能涉及设计更适合特定目标的网络结构、引入更丰富的先验知识以及开发更有效的训练策略等方面的工作。通过这些努力,有望实现在不同形态目标上更准确和鲁棒的分割结果。
在YOLOv8中添加动态蛇形卷积(Dynamic Snake Convolution)
上面的一系列只是介绍动态蛇形卷积(Dynamic Snake Convolution),如果大家只是为了给自己的模型涨点,而不想去知道什么原理其实直接看这一段即可。
我的环境和版本
因为不同版本的yolov8可能代码的目录格式不太一样,下面是我用的版本介绍,基本上都是最新版本所以很适合大家进行更新和修改。
python=3.9.7
torch=2.1
cuda=11.8
我的yolov8版本是8.0.203版本
官方代码bug修复
官方的代码如果你自己进行添加之后可能会有如下报错,我们进行了修改以后成功的解决了该问题的出现
y_new_ = y_new_.add(y_offset_new_.mul(extend_scope))
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!

修改后的代码如下大家直接复制即可!修改该问题的出现 !
# -*- coding: utf-8 -*-
from __future__ import annotations
import os
import numpy as np
import torch
from torch import nn
import einops
"""Dynamic Snake Convolution Module"""
class DSConv_pro(nn.Module):
def __init__(
self,
in_channels: int = 1,
out_channels: int = 1,
kernel_size: int = 9,
extend_scope: float = 1.0,
morph: int = 0,
if_offset: bool = True,
device: str | torch.device = "cpu",
):
"""
A Dynamic Snake Convolution Implementation
Based on:
TODO
Args:
in_ch: number of input channels. Defaults to 1.
out_ch: number of output channels. Defaults to 1.
kernel_size: the size of kernel. Defaults to 9.
extend_scope: the range to expand. Defaults to 1 for this method.
morph: the morphology of the convolution kernel is mainly divided into two types along the x-axis (0) and the y-axis (1) (see the paper for details).
if_offset: whether deformation is required, if it is False, it is the standard convolution kernel. Defaults to True.
"""
super().__init__()
if morph not in (0, 1):
raise ValueError("morph should be 0 or 1.")
self.kernel_size = kernel_size
self.extend_scope = extend_scope
self.morph = morph
self.if_offset = if_offset
self.device = torch.device(device)
self.to(device)
# self.bn = nn.BatchNorm2d(2 * kernel_size)
self.gn_offset = nn.GroupNorm(kernel_size, 2 * kernel_size)
self.gn = nn.GroupNorm(out_channels // 4, out_channels)
self.relu = nn.ReLU(inplace=True)
self.tanh = nn.Tanh()
self.offset_conv = nn.Conv2d(in_channels, 2 * kernel_size, 3, padding=1)
self.dsc_conv_x = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(kernel_size, 1),
stride=(kernel_size, 1),
padding=0,
)
self.dsc_conv_y = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(1, kernel_size),
stride=(1, kernel_size),
padding=0,
)
def forward(self, input: torch.Tensor):
# Predict offset map between [-1, 1]
offset = self.offset_conv(input)
# offset = self.bn(offset)
offset = self.gn_offset(offset)
offset = self.tanh(offset)
# Run deformative conv
y_coordinate_map, x_coordinate_map = get_coordinate_map_2D(
offset=offset,
morph=self.morph,
extend_scope=self.extend_scope,
device=self.device,
)
deformed_feature = get_interpolated_feature(
input,
y_coordinate_map,
x_coordinate_map,
)
if self.morph == 0:
output = self.dsc_conv_x(deformed_feature)
elif self.morph == 1:
output = self.dsc_conv_y(deformed_feature)
# Groupnorm & ReLU
output = self.gn(output)
output = self.relu(output)
return output
def get_coordinate_map_2D(
offset: torch.Tensor,
morph: int,
extend_scope: float = 1.0,
device: str | torch.device = "cpu",
):
"""Computing 2D coordinate map of DSCNet based on: TODO
Args:
offset: offset predict by network with shape [B, 2*K, W, H]. Here K refers to kernel size.
morph: the morphology of the convolution kernel is mainly divided into two types along the x-axis (0) and the y-axis (1) (see the paper for details).
extend_scope: the range to expand. Defaults to 1 for this method.
device: location of data. Defaults to 'cuda'.
Return:
y_coordinate_map: coordinate map along y-axis with shape [B, K_H * H, K_W * W]
x_coordinate_map: coordinate map along x-axis with shape [B, K_H * H, K_W * W]
"""
if morph not in (0, 1):
raise ValueError("morph should be 0 or 1.")
batch_size, _, width, height = offset.shape
kernel_size = offset.shape[1] // 2
center = kernel_size // 2
device = torch.device(device)
y_offset_, x_offset_ = torch.split(offset, kernel_size, dim=1)
y_center_ = torch.arange(0, width, dtype=torch.float32, device=device)
y_center_ = einops.repeat(y_center_, "w -> k w h", k=kernel_size, h=height)
x_center_ = torch.arange(0, height, dtype=torch.float32, device=device)
x_center_ = einops.repeat(x_center_, "h -> k w h", k=kernel_size, w=width)
if morph == 0:
"""
Initialize the kernel and flatten the kernel
y: only need 0
x: -num_points//2 ~ num_points//2 (Determined by the kernel size)
"""
y_spread_ = torch.zeros([kernel_size], device=device)
x_spread_ = torch.linspace(-center, center, kernel_size, device=device)
y_grid_ = einops.repeat(y_spread_, "k -> k w h", w=width, h=height)
x_grid_ = einops.repeat(x_spread_, "k -> k w h", w=width, h=height)
y_new_ = y_center_ + y_grid_
x_new_ = x_center_ + x_grid_
y_new_ = einops.repeat(y_new_, "k w h -> b k w h", b=batch_size)
x_new_ = einops.repeat(x_new_, "k w h -> b k w h", b=batch_size)
y_offset_ = einops.rearrange(y_offset_, "b k w h -> k b w h")
y_offset_new_ = y_offset_.detach().clone()
# The center position remains unchanged and the rest of the positions begin to swing
# This part is quite simple. The main idea is that "offset is an iterative process"
y_offset_new_[center] = 0
for index in range(1, center + 1):
y_offset_new_[center + index] = (
y_offset_new_[center + index - 1] + y_offset_[center + index]
)
y_offset_new_[center - index] = (
y_offset_new_[center - index + 1] + y_offset_[center - index]
)
y_offset_new_ = einops.rearrange(y_offset_new_, "k b w h -> b k w h")
y_new_ = y_new_.add(y_offset_new_.mul(extend_scope))
y_coordinate_map = einops.rearrange(y_new_, "b k w h -> b (w k) h")
x_coordinate_map = einops.rearrange(x_new_, "b k w h -> b (w k) h")
elif morph == 1:
"""
Initialize the kernel and flatten the kernel
y: -num_points//2 ~ num_points//2 (Determined by the kernel size)
x: only need 0
"""
y_spread_ = torch.linspace(-center, center, kernel_size, device=device)
x_spread_ = torch.zeros([kernel_size], device=device)
y_grid_ = einops.repeat(y_spread_, "k -> k w h", w=width, h=height)
x_grid_ = einops.repeat(x_spread_, "k -> k w h", w=width, h=height)
y_new_ = y_center_ + y_grid_
x_new_ = x_center_ + x_grid_
y_new_ = einops.repeat(y_new_, "k w h -> b k w h", b=batch_size)
x_new_ = einops.repeat(x_new_, "k w h -> b k w h", b=batch_size)
x_offset_ = einops.rearrange(x_offset_, "b k w h -> k b w h")
x_offset_new_ = x_offset_.detach().clone()
# The center position remains unchanged and the rest of the positions begin to swing
# This part is quite simple. The main idea is that "offset is an iterative process"
x_offset_new_[center] = 0
for index in range(1, center + 1):
x_offset_new_[center + index] = (
x_offset_new_[center + index - 1] + x_offset_[center + index]
)
x_offset_new_[center - index] = (
x_offset_new_[center - index + 1] + x_offset_[center - index]
)
x_offset_new_ = einops.rearrange(x_offset_new_, "k b w h -> b k w h")
x_new_ = x_new_.add(x_offset_new_.mul(extend_scope))
y_coordinate_map = einops.rearrange(y_new_, "b k w h -> b w (h k)")
x_coordinate_map = einops.rearrange(x_new_, "b k w h -> b w (h k)")
return y_coordinate_map, x_coordinate_map
def get_interpolated_feature(
input_feature: torch.Tensor,
y_coordinate_map: torch.Tensor,
x_coordinate_map: torch.Tensor,
interpolate_mode: str = "bilinear",
):
"""From coordinate map interpolate feature of DSCNet based on: TODO
Args:
input_feature: feature that to be interpolated with shape [B, C, H, W]
y_coordinate_map: coordinate map along y-axis with shape [B, K_H * H, K_W * W]
x_coordinate_map: coordinate map along x-axis with shape [B, K_H * H, K_W * W]
interpolate_mode: the arg 'mode' of nn.functional.grid_sample, can be 'bilinear' or 'bicubic' . Defaults to 'bilinear'.
Return:
interpolated_feature: interpolated feature with shape [B, C, K_H * H, K_W * W]
"""
if interpolate_mode not in ("bilinear", "bicubic"):
raise ValueError("interpolate_mode should be 'bilinear' or 'bicubic'.")
y_max = input_feature.shape[-2] - 1
x_max = input_feature.shape[-1] - 1
y_coordinate_map_ = _coordinate_map_scaling(y_coordinate_map, origin=[0, y_max])
x_coordinate_map_ = _coordinate_map_scaling(x_coordinate_map, origin=[0, x_max])
y_coordinate_map_ = torch.unsqueeze(y_coordinate_map_, dim=-1)
x_coordinate_map_ = torch.unsqueeze(x_coordinate_map_, dim=-1)
# Note here grid with shape [B, H, W, 2]
# Where [:, :, :, 2] refers to [x ,y]
grid = torch.cat([x_coordinate_map_, y_coordinate_map_], dim=-1)
interpolated_feature = nn.functional.grid_sample(
input=input_feature,
grid=grid,
mode=interpolate_mode,
padding_mode="zeros",
align_corners=True,
)
return interpolated_feature
def _coordinate_map_scaling(
coordinate_map: torch.Tensor,
origin: list,
target: list = [-1, 1],
):
"""Map the value of coordinate_map from origin=[min, max] to target=[a,b] for DSCNet based on: TODO
Args:
coordinate_map: the coordinate map to be scaled
origin: original value range of coordinate map, e.g. [coordinate_map.min(), coordinate_map.max()]
target: target value range of coordinate map,Defaults to [-1, 1]
Return:
coordinate_map_scaled: the coordinate map after scaling
"""
min, max = origin
a, b = target
coordinate_map_scaled = torch.clamp(coordinate_map, min, max)
scale_factor = (b - a) / (max - min)
coordinate_map_scaled = a + scale_factor * (coordinate_map_scaled - min)
return coordinate_map_scaled
需要改动代码的地方
我们需要改动的地方有五处,在我们的代码中添加该卷积!
修改一
首先复制上面进行了BUG修复的代码,到如下目录下的最后面,ultralytics/nn/modules/conv.py文件。
修改之后应该如下所示,因为文件代码太长了我没办法全部复制进来,我后面会把修改之后的代码上传到CSDN上供大家下载。

PS:需要注意的是大家需要把所需库的导入如下面的代码框,移动到该文件的最前端,否则会报错。
# -*- coding: utf-8 -*-
from __future__ import annotations
import os
import numpy as np
import torch
from torch import nn
import einops不移动到最前端会报错如下!

修改二
需要修改的第二处是和上面同一个文件的最前面,我们定义的类名添加到这里。

修改三
我们移动到该文件下ultralytics/nn/modules/__init__.py对该文件进行修改,我们同样将类名加入到这个地方即可。

修改四
我们移动到该文件下ultralytics/nn/tasks.py对该文件进行修改,我们先修改文件的最前端的模块导入地方,如下所示,同样将类名添加到这里。
 修改五
修改五
修改同样的文件,找到定义的方法
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)按照如下进行修改,添加类名即可。

修改模型配置文件
到此,你已经可以在模型里面添加该卷积了,我们需要找到如下目录进行修改"ultralytics/cfg/models/v8/yolov8.yaml",找到这个文件之后初始如下所示,
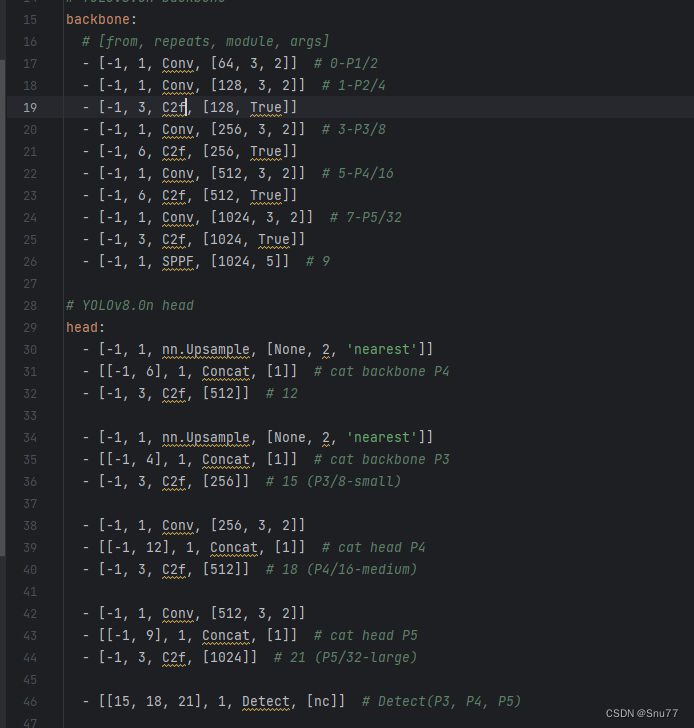
需要注意的是,动态蛇形卷积并不会改变输入图像的宽和高,我们可以将其添加到Backbone骨干网络上,也可以添加到Neck部分进行辅助特征融合,具体来看你自己的需要,进行改进。我这里将其添加到Backbone层替换第一个C2f和最后一个C2f实现了有效涨点修改后如下所示。
开始训练
我这里是通过创建py文件来进行训练,我创建了一个名字为run的文件放在根目录下,
内容如下
from ultralytics import YOLO
model = YOLO("ultralytics/cfg/models/v8/yolov8.yaml").train(**{'cfg':'ultralytics/cfg/default.yaml'}) # pass any model type
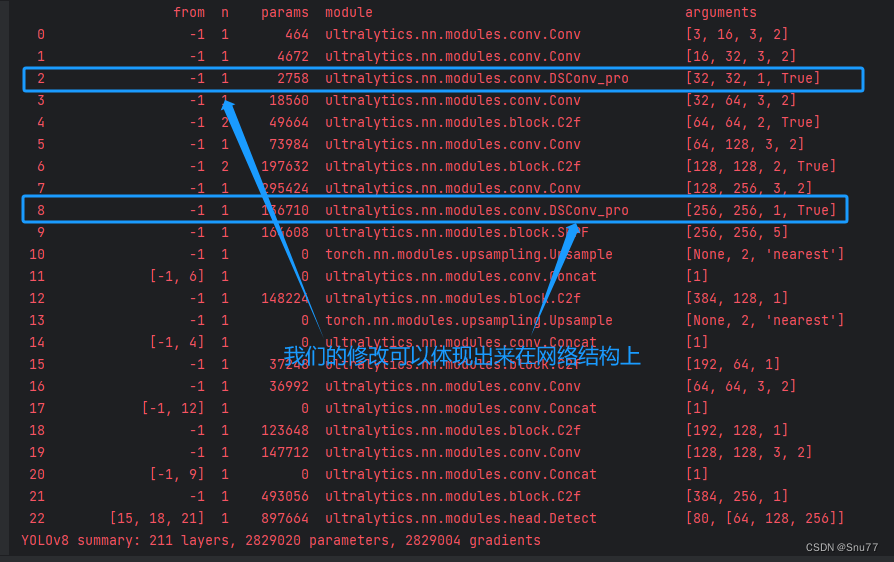
运行该文件 ,控制台开始输出检验我们的模型,可以在输出的网络结构上体现我们的输出了,
结果对比
训练完毕,

我们可以看一下检测的效果图,可以看出来大部分的物体还是都可以检测出来,看一下mAP也有略微的提升,这里我就不给大家放了,因为我的数据集为了写博客是网上随便找的一个只有几百张图片,后期我在拿个大的数据集测试一下给大家补上精度图。

修改完成的文件
最后给大家提供修改完成后的文件下载地址,帮大家都修改好了,大家只需要在想要添加DSCN的地方添加即可!
最后希望这边文章能够帮助到你。
