收藏关注不迷路
文章目录
前言
本文前面半部分提到了数据挖掘中的一些比较基本的理论,之后通过这些理论算法来验证航空公司乘客满意度数据集这个例子。其第一步先是阐述了所使用的满意度数据集的来源,然后将该数据集的一些字段转换成所需要的因子类型,进而进行数据的探索性分析,再对探索性分析所得到的结果显示的某个属性列中的缺失值进行处理。最后通过逻辑回归和CART这两种算法分别建立模型,对比其评估指标的结果发现,CART算法构建的决策树在此数据集的各个指标更胜一筹。
对乘客满意度状况进行分析,是为了让航空公司能够更加熟知乘客的特点,促进彼此之间的交流,为了对其提供相对应的服务更加便利,从而尽所能的满足乘客的要求,提高其满意度,并可依据效果研究出对应的营销方案。
关键词:数据挖掘 航空公司乘客满意度 Logistic回归 CART
一、 数据预处理
1数据预处理的重要性
在实际应用中,我们收集而来用于数据挖掘的原始数据通常与可用于分析的实验数据相去甚远,这些数据无序
且质量差。所以对于我们收集而来原始数据,第一步就应该要进行简单预处理,以便于之后数据的使用。数据预处
理能最大化地处理来自存储数据的错误和人工记录数据的错误众多情形下所带来的这些噪声,并且能最大化地消除
由于数据的质量问题给结果分析带来的影响,它是数据挖掘过程中至关重要的一步[10]。预处理应满足实际情况且
有逻辑的流程,这样可以充分利用到原始客户数据,留下更完善、更好的客户数据,为后续工作提供理想的基础。
2数据清理
数据清理就是要求以保证数据的一致性为第一要务来对数据中存在的错误进行修正或清理[11]。以下讲述了如
何解决数据中存在缺失错误几种办法的主要内容:
(1)删除缺失记录:当数据集中的一条记录缺少一个值时,我们可以选择把该条记录进行删除。这种方法很容
易,但我们通常不使用这种方法。因为这种方法遇到某个输入变量对输出变量有较大影响或者属性缺失记录占比较
大时,数据会严重缺失,失去了数据本身的意义。
(2)人工填补缺失值:当我们面对太多的数据时,通过人工来进行填补耗费时间精力,要是遇到非常大的数据
量,单凭人力根本不可能完成,所以一般不推荐使用此方法。
(3)用平均值填补缺失值:此方法较为常用,也是本事所使用的清理办法,其是通过利用数据集中数据样本缺失
所在位置的那个属性列的平均值来填补该属性列所有存在数据样本缺失的地方[12]。
3数据转换
数据转换是将上一步清理完成后的数据集进行我们所需要的整合和转换。以下简要概述了清理完成后几种经常
遇见的数据转换内容:
(1)类型转换
由于收集者记录数据时为了方便,使用数字来代替,致使软件识别数据集时,将原本属性样本的离散值识别成
了连续值,此时就需要进行数据类型的转换。
(2)数据离散化为了限制这些连续属性值的个数,一些简单的数字被用来代替连续属性值划分的一些区间。
(3)数据标准化属性的业务含义各不相同,属性之间的数值差异过大,使其无法正常的进行数据分析。所以应该将这些差异过
大的数据经由缩放,使之落在一个小区间中,降低数据之间的差异度。此外,还可利用数据标准化来解决个别数值
高的属性对聚类结果的影响[13]。
二、logistic回归和CART算法理论
4.1logistic回归理论
实际分析数据集中的输出变量往往不是所期待的连续型,而是离散型的类别型变量,这时千万不能胡乱使用多
元线性回归,不然会导致分析结果的错误。通过观察本文所使用的乘客满意度数据集,发现该数据集中的标签变量
列是类别型的数据且该列的值被归为两类。对于此类状况,要让它的输出只有两类,就必须调用一个Sigmoid函数来
进行转换。
4.1.1Sigmoid回归函数
Sigmoid回归函数形式为:
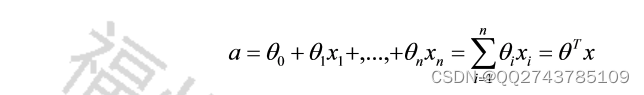
图4-1Sigmoid函数
由图4-1中可以看到该函数图像是以点(0,0.5)为中心的中心对称曲线。当a取得原点左侧的值时,函数f(a)
的值只会在0到0.5之间,这就可以更好的说明其属于0类;当a取得原点右侧的值时,函数f(a)的值只会在0.5到1之
间,这就可以更好的说明其属于1类。
在Sigmoid回归函数中:

公式(4-4)和公式(4-5)分别代表结果为1和结果为0的概率。
三、数据来源及背景
5.1数据来源及背景
本文所用数据集是采自kaggle上关于航空公司乘客满意度的调查。该数据集一共有129880条记录,有客户类
型、旅行类型等25个属性。标签属性为满意度,我将其划分为两类,一类是满意,一类是中立或不满意。
数据集的部分展示如图5-1:
图5-1部分数据
5.2数据的探索性分析
5.2.1数据探索
(1)通过str()展示该数据集的内部结构
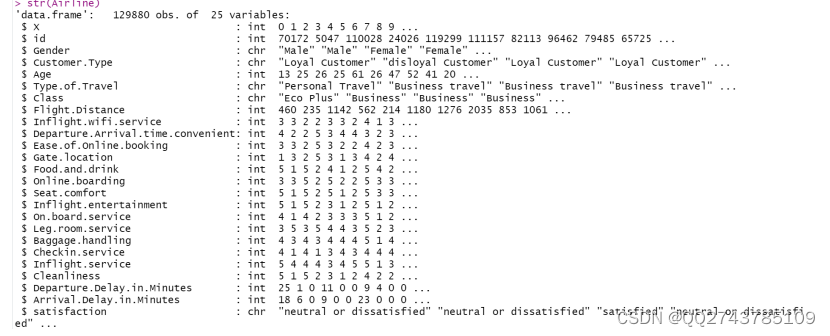
图5-2数据集的内部结构
由图5-2可以看出Gender、Customer.Type、Type.of.Travel、Class和satisfaction为chr类型,从Inflight.
wifi.service到Cleanliness为int类型,通过观察,显然其不是我们所需要的数据类型,我们将其转化为因子类
型。
(2)通过as.factor()进行数据类型转换
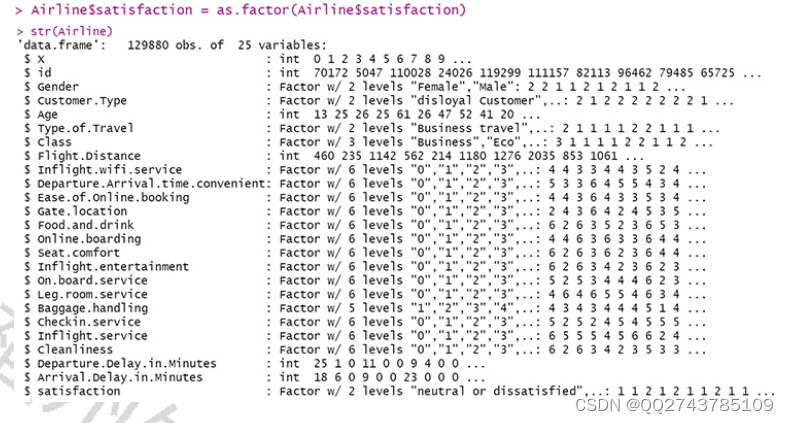
图5-3转换后的内部结构
5.2.2数据可视化分析
利用R的综合档案CRAN中的可视化工具rattle包进行可视化分析,通过调出rattle界面可以看到其提供的数据挖
掘的整个流程,包括数据导入、可视化等功能。
(1)数据导入
通过数据选项卡可选择导入数据的来源,此数据集在Rstudio当中已经导入完成,所以在rattle中只需点击R
Dataset从中选择Airline数据集。
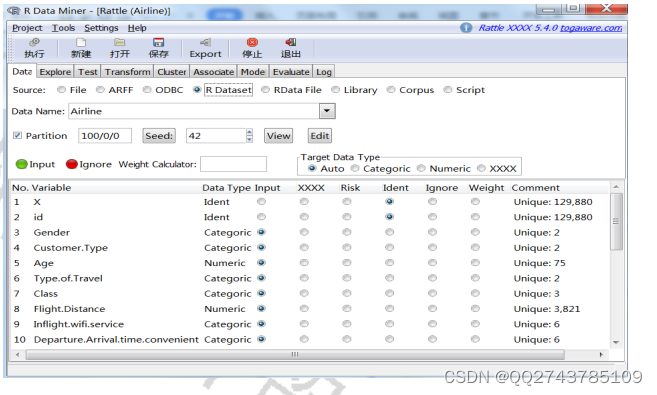
图5-5rattle-数据导入
(2)可视化分析
通过Explore选项卡中的Distributions可以画出各个输入变量与输出变量之间的箱线图、柱状图等。
图5-6rattle-可视化分析
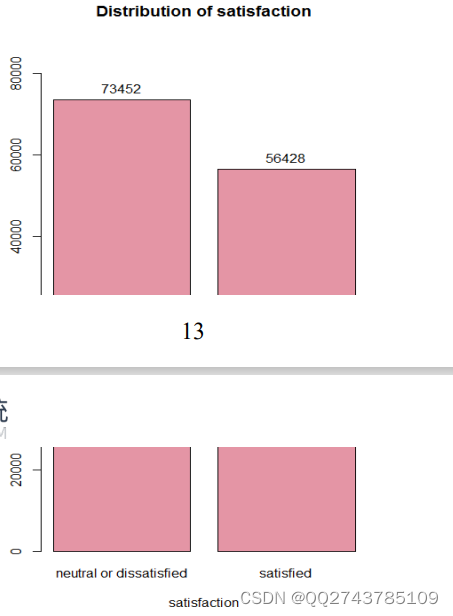
图5-7整体满意度
由图5-7可以看出本次航空公司乘客满意度的调查的129880名乘客当中,一半以上的乘客对此次航班的整体服务
处于中立或不满意状态,仅有5万多名乘客感觉到满意。
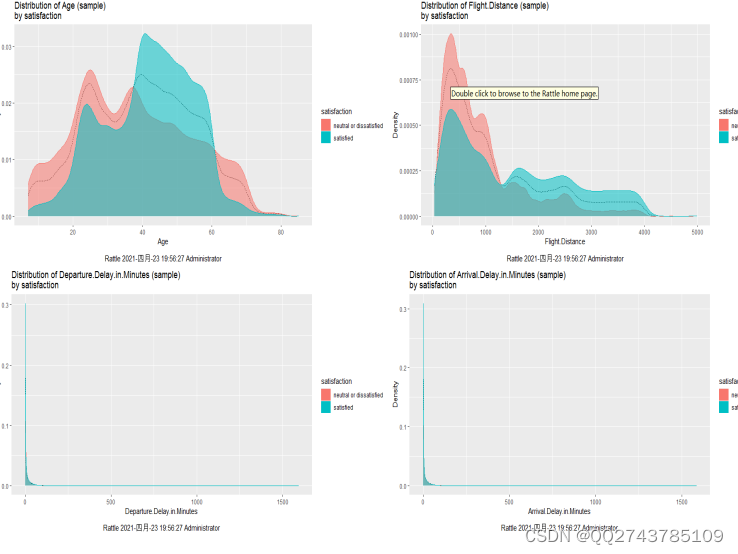
图5-8连续型变量满意度情况
由图5-8可以看出旅客年龄范围大致在7岁到85岁之间,通过比较各个年龄分段的满意度,我们发现在40岁到60
岁之间的乘客对服务满意的人数要比中立或不满意的人数高出很多,在7岁到39岁以及61岁到79岁之间的乘客中立或
不满意的人数多。
还可以看出几乎所有乘客此行程的飞行距离在4049公里之内,还可以看到很大比例的此行程的飞行距离在0到
1250公里之间。其中大多数中立的或不满意的在250公里到750公里之间。
还可以看出不论是出发的延迟时间,还是到达的延迟时间,两者的所有航班延误时间都在125分钟之内,乘客的
满意度没有出现随着延误时间的增加,满意度却下降的特征。
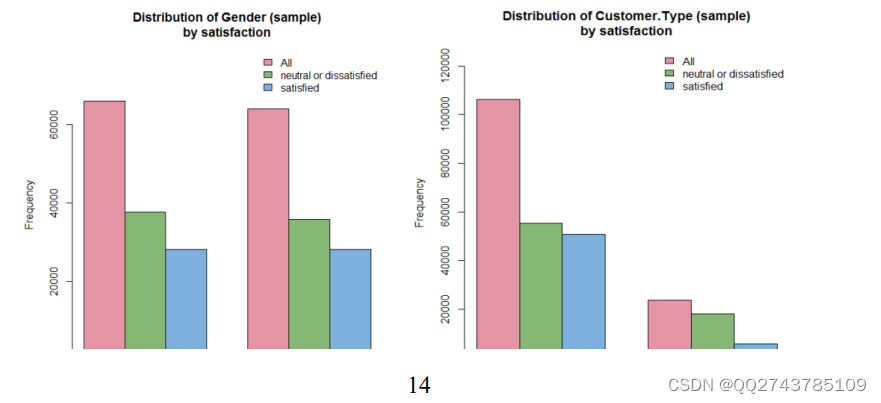
图5-9性别和客户类型
由图5-9可以看出乘客的男女比例接近1:1,通过比较,我们发现男性和女性中立或不满意的人数与满意的人数
几乎相同,但总的来说不满意客户的比例是高于满意的客户的。
通过比较不同旅客类型对航空的整体服务的满意度,我们发现忠实客户群体的人数是不忠实客户群体的4.5倍,
在忠实客户群体中,中立或不满意的略比满意的多,不忠实客户群体中立或不满意的是满意的三倍左右。总体来
说,忠实客户群体比不忠实客户群体更容易对航空的整体服务感到满意满意。
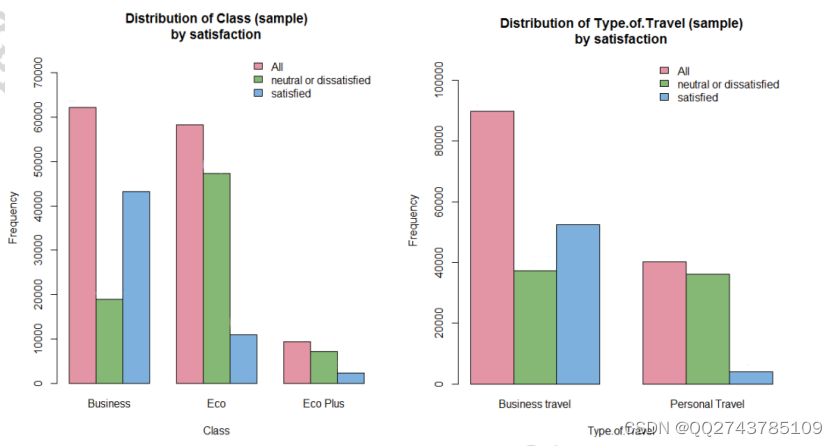
图5-10舱位和旅游类型
由图5-10可以看出选择商务舱和经济舱的乘客人数多。通过比较不同舱位的乘客满意度,我们发现舱位级别的
高低关系着乘客的满意程度,在经济舱中,更多的是中立和不满意的乘客,而在商务舱当中,满意的乘客占大部
分。这应该是与飞机舱内座椅舒适程度相关,商务舱的座椅相对于经济舱的座椅舒适程度肯定高。
还可以看出公事旅行的人数是个人旅行的认识的两倍,通过比较不同旅行类型的乘客满意度,我们发现公事旅
行的乘客对航空的整体服务更满意,但是,在比较中立或不满意的客户数量时,差异并不大。
四、结论
本文主要是利用数据挖掘技术对航空公司乘客满意度进行研究。本文针对乘客满意度数据集的特点,对数据集
进行清理、优化,并利用rattle包进行、可视化的分析。最后使用Rstudio软件实现逻辑回归以及CART的算法挖掘。
通过可视化分析可以发现,7岁-39岁以及61岁-79岁的乘客、飞行距离在250公里到750公里之间的乘客、不忠实
的乘客、舱位较低的乘客(座椅舒适度)、个人旅行的乘客大部分是处于中立或不满意,该公司通过此分析可以特
别关注这些类型的乘客,专项服务。
通过决策树可以看出其主要与在线登机、机上wifi服务、旅行类型、机上娱乐、签到服务这五个变量有重大关
联。还可以看出对于个人旅行的乘客,需要同时提高其在线登机与机上wifi服务的满意度;对于公事旅行的乘客,
可以同时提高在线登机与签到服务的满意度或在线登机与机上娱乐的满意度;对于公事旅行且机上娱乐不满意的乘
客,可以同时提高其在线登机与机上wifi服务的满意度;针对在线登机中立或不满意的乘客,可以通过提高其机上
wifi服务的满意度来使其改变态度。
由于使用的是经典算法,虽然应用广泛,实现简单,运行稳定,但相对一些改进或新晋的算法而言,该算法的
效率更低,并且由于其对大型数据集的处理能力有限,在将来大数据环境与高速化要求的实践领域中,需要不断改
进。
目录
目 录
1绪论1
1.1研究背景及意义1
1.2研究语言及研究工具1
1.3论文的研究内容2
1.4论文的结构3
2数据挖掘理论3
2.1数据挖掘的定义3
2.2数据挖掘的过程4
2.3数据挖掘的常用方法5
3数据预处理5
3.1数据预处理的重要性5
3.2数据清理6
3.3数据转换6
3.4数据降维7
4logistic回归和CART算法理论7
4.1logistic回归理论7
4.2 CART算法理论9
5实例验证13
5.1数据来源及背景13
5.2数据的探索性分析13
5.3数据处理22
5.4 logistic回归建立模型24
5.5 CART算法建立模型28
5.6logistic回归和CART算法的对比33
6总结与展望33
参考文献34