收藏关注不迷路
文章目录
前言
本文将logistic回归、K近邻以及决策树算法应用于银行客户失信问题的分析之中,并用python语言编程实现。首先利用随机森林算法得到各特征与目标列之间的相关性系数,选取银行客户数据特征的10个重要特征;采取上述三种方法建立银行客户失信的预测模型,发现只有K近邻的F1-score指标最低,未失信的F1-score为0.98,失信的F1-score为0.72,其他两种模型的F1-score均为1,说明logistic回归以及决策树算法两种模型的预测效果最好。最后针对性的对银行服务项目改进给出建议,从而有效减少银行客户失信率。
关键词:数据挖掘;logistic回归;k-近邻;决策树
一、 研究路线图

图1.1 研究路线图
相关理论:logistic回归,K近邻方法,决策树。
数据预处理:处理数据中的缺失值以及参数变量。
模型训练:三种模型分别训练。
参数对比:对比三种模型之间的结果参数,分析三种模型的优越性。
二、开发环境
2.1 数据挖掘的基本方法
在分析和挖掘过程中,本文主要采用logistic回归,K近邻,以及决策树三种方法进行数据挖掘。下面将依次介绍这三种方法的原理以及优缺点。
2.1.1 logistic回归
(一) logistic回归原理
Logistic回归分析与线性回归分析类似,不同之处在于结果是二分法的(例如,成功/失败,是/否或死亡/存活)。回归分析的流行病学模块简要介绍了逻辑回归的原理以及它是多元线性回归的扩展。本质上,我们检查了结果发生(或不发生)的几率,并且通过使用结果的几率的自然对数作为因变量,可以将关系线性化,并且可以像对待多元线性回归一样对待。简单的逻辑回归分析是指具有一个二分结果和一个独立变量的回归应用程序;当存在一个二分变量和多个独立变量时,将应用多重逻辑回归分析。
三、数据预处理
删除空值,重复值,对数据进行预处理,将None值换成0,只保留中文字符,将标题分割成一个个短词,同理处理标签,设置一个四舍五入代码,计算三连等比率:点赞率=点赞/播放量100%;硬币率=硬币/播放量100%;收藏率=收藏/播放量100%;转发率=转发/播放量100%;弹幕率=弹幕/播放量100%;评论率=评论/播放量100%
本文所用数据样本集来源于银行客户数据集,将进行以下工作:数据的探索性分析、数据清洗、特征工程。并在此过程中,进行必要的描述性统计,为下文的模型建立提供所需的数据支持。
3.1 数据的探索性分析
3.1.1 查看数据类型以及数据大小
信贷数据中蕴含中客户个人贷款信息与客户信用的关系规律,而本文是通过模型的建立对其进行挖掘,因此本文以LendingClub信贷平台2016年数据为原始样本数据均来源于LendingClub公司网站[8]。
本章选取的数据来源于某银行公司,含有105个特征列,以及一个反映客户是否失信的标签列。根据课题研究要求,整理出表格3-1,但是数据太大,只整理了数据的总体描述。
通过随机森林,选取9各重要特征,验证集达到了0.867,显示这9个重要特征以及目标列,得到如下列表,并附上解释,我们在下面将主要关注这9个重要特征。
3.1.2 数据探索
查看缺失值:调用‘isnull’函数查看数据是否存在缺失值,发现有的特征缺失值过多。
观察数据分布:查看失信客户和未失信客户的样本分布,并做可视化显示。
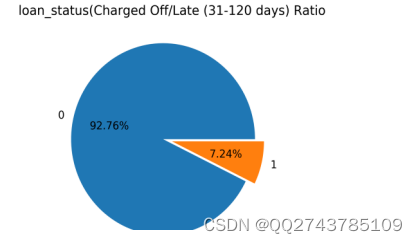
图3-1 样本分布饼图
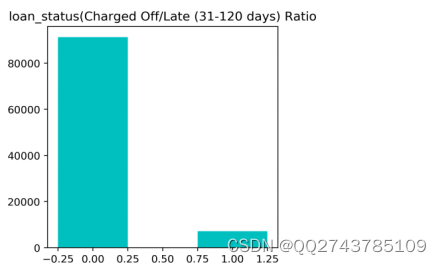
图3-2 样本分布柱状图
四、结论
本文以银行客户失信问题为研究背景,利用数据挖掘中logistics回归,K近邻,决策树算法,以python作为计算工具,不仅建立了银行客户失信预测模型来预测客户失信的可能性,而且还通过随机森林算法筛选出对客户失信影响比较大的因素,从而为电信公司有针对性的改进并提供服务,来提高银行贷款上的效率。
本文的主要成果有:
(1) 针对原始数据中存在的无用特征或影响较小的情况,使用随机森林算法计算各个特征对用户流失的重要性系数并以此为依据进行特征选择,提高了测试集的准确率。
(2) 针对原数据失信与不失信之间的数据不平衡情况,因为三个模型的建立准确率都非常高,所以就不进行抽样处理。
(3) 本文的决策树模型训练集和测试集准确率达到了惊人的0.99,可以非常完美的预测银行客户是否失信,效果显著。虽然本文在银行客户失信预测上很有成果,但是仍有方面需要改进:
(1) 在数据集采取方面,本文的数据量非常大,面对缺失值问题时,我们只是单纯的删除缺失值过多的列以及缺失值非常少的行,没有进行缺失值的填充。
(2) 本文在做相关性分析时,只是单纯的选取了相关性系数大于0.1的特征,那些相对相关性系数比较小的值,我们没有过多的去研究,没有更加精细,希望下次的研究能更加的细致准确
目录
目 录
第1章 绪论1
1.1 研究背景及意义1
1.2 国内外研究现状1
1.3 本文主要研究内容2
1.4 研究路线图2
第2章 相关理论与算法3
2.1 数据挖掘的基本方法3
2.2 本章小结6
第3章 数据预处理7
3.1 数据的探索性分析7
3.2 数据清洗10
3.3 查看特征变量的相关性11
3.4 现实应用分析13
3.5 本章小结13
第4章 模型评估和预测14
4.1 模型评估14
4.2 模型训练结果15
4.3 模型对比16
4.4 本章小结17
结 论18
参考文献19
致 谢20