谷歌旗下的AI研究机构DeepMind在全球顶级学术期刊《Nature》上发布了一篇论文,通过深度学习、计算机视觉、大数据等,开发了一个名为GNoME的图神经网络模型,主要用于材料发现。
研究团队通过GnoME便快速发现了220万个新的材料晶体结构,其中很多结构是人类预测和公式难以发现的,相较于传统的材料开发方法效率提升了10倍。
论文地址:https://www.nature.com/articles/s41586-023-06735-9
长期以来,研发新材料一直面临高成本、低效率的难题。实验合成法费时费力,成功率低下;
第一性原理计算指导的材料发现也受限于算力问题,难以做到全面高效的材料空间遍历。
谷歌DeepMind开发的深度学习模型AlphaFold在蛋白质结构预测领域,已经展现出了巨大应用潜力并已经获得全球多家著名实验室的应用。
因此,研究人员希望可以借助深度学习,处理复杂的材料结构数据,开发一个像“AlphaFold”一样的高效开发系统。
简单来说,可以把GNoME看成材料发现界的“AlphaFold”模型,同时证明了海量的第一性原理计算为模型学习原子间势提供了支持,并实现了之前从未有过的精度和泛化能力。
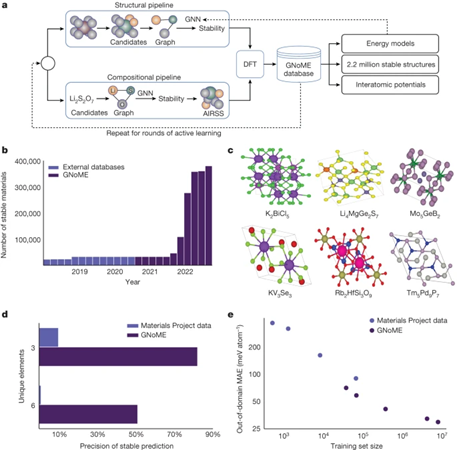
GNoME是一个图神经网络,通过表示晶体的拓扑连接、消息传递等机制,实现结构到能量的映射。该系统集成了多个模块,实现从候选结构的生成到深度学习预测的全流程自动化。
GNoME的主要技术创新点在于构建了一个 Flywheel主动学习循环系统:模型过滤得到的候选材料用第一性原理计算验证,新数据反过来提升模型性能,二者之间形成闭环互补不断地提升能力。
也就是说,GNoME发现的材料越多,整个模型的能力也就越强,而整个训练流程全部由AI自动完成。
发现方式流程是,研究团队首先基于公开材料数据库训练出初始的结构评价模型,然后利用该模型对数十亿候选结构进行快速过滤,选择特定数量送入第一性原理计算。
计算所得精确能量既验证了模型预测,也为进一步增强模型提供了丰富数据。新一轮使用数据库和计算数据重新训练的模型则可实现更高效更准确的材料发现。
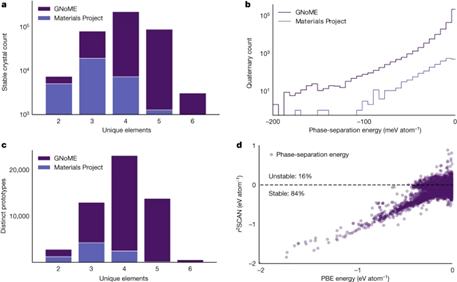
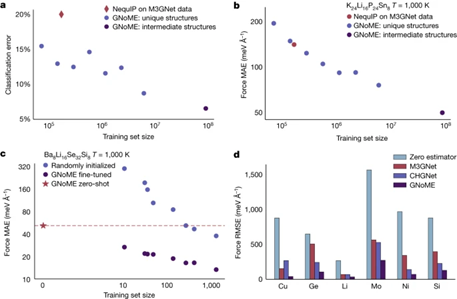
数据显示,随着每轮训练数据量的积累,模型预测性能持续改善,材料发现效率也呈指数级提高。6轮迭代后,模型精度达到每个原子11meV,稳定结构筛选精确率超过80%。
超大规模的训练数据集也是训练GNoME的关键。GNoME所用的数据规模也刷新了计算材料领域的记录。
包括公开数据库、迭代计算以及模型生成,GNoME的训练数据总量超过1亿组,涵盖100多万种组成,是目前最大的计算材料数据集。
海量数据使得深度学习模型可以不断调优提升,尤其是对发现人类难以预测的新奇材料发挥了巨大作用。
本文素材来源谷歌GNoME论文,如有侵权请联系删除