目录
前言
多线程一直以来都知识点比较多,让人难以理解,网上的文章大多也是长篇大论。最近有空所以将平时接触到的多线程知识由浅入深的以代码示例形式整理出来,希望为后来者解惑,快速的了解多线程相关的知识,减少踩坑。
一、初识多线程
多线程最基本的两种实现方式
方式一
继承Thread类并并重写run方法
public class MyThread extends Thread {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.println("线程名:" + Thread.currentThread().getName() + " i是:" + i);
}
}
}
测试:
public class Test {
public static void main(String[] args) {
MyThread myThread1 = new MyThread();
MyThread myThread2 = new MyThread();
myThread1.start();
myThread2.start();
}
}
输出:
线程名:Thread-0 i是:1
线程名:Thread-1 i是:1
线程名:Thread-0 i是:2
线程名:Thread-1 i是:2
线程名:Thread-0 i是:3
线程名:Thread-1 i是:3
线程名:Thread-1 i是:4
线程名:Thread-1 i是:5
线程名:Thread-0 i是:4
线程名:Thread-0 i是:5
方式二
实现Runnable接口,并用其初始化Thread
public class MyThread implements Runnable {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.println("线程名:" + Thread.currentThread().getName() + " i是:" + i);
}
}
}
测试:
public class Test {
public static void main(String[] args) {
Thread myThread1 = new Thread(new MyThread());
Thread myThread2 = new Thread(new MyThread());
myThread1.start();
myThread2.start();
}
}
输出:
线程名:Thread-0 i是:1
线程名:Thread-1 i是:1
线程名:Thread-1 i是:2
线程名:Thread-0 i是:2
线程名:Thread-1 i是:3
线程名:Thread-1 i是:4
线程名:Thread-1 i是:5
线程名:Thread-0 i是:3
线程名:Thread-0 i是:4
线程名:Thread-0 i是:5
说明: 两种方式的测试代码里分别开了myThread1 和myThread2 两个线程,调用 start 方法便会开始执行run 方法中的循环打印1到5。
你会发现输出结果并不是先执行完Thread-0 再执行 Thread-1的,而且每次执行输出顺序可能都不一样,这就是多线程。
平时我们写的代码都是线性的,代码会按照顺序执行完这一行再执行下一行,而多线程你可以理解为多条车道,cup是驱动着你写的程序这辆车在多车道上飞驰,它一下在这条车道上开,一下在另一台车道上开,由于cup实在是太快了,让你看起来好像有多张车在多车道上开,就好像武林高手出拳速度太快产生残影让你以为他有很多手,实际上在某一时刻上只有一张车在其中的一条车道上开。
多线程优点
1.采用多线程技术的应用程序可以更好地利用系统资源。主要优势在于充分利用了CPU的空闲时间片,用尽可能少的时间来对用户的要求做出响应,使得进程的整体运行效率得到较大提高,同时增强了应用程序的灵活性。
2.异步,当你想执行多个耗时的复杂运算,可以考虑多线程。
比如:你想做一道菜,你需要烧水、买菜、切菜、煮饭,你可以多开几个线程,一个线程烧水,一个线程去买菜、一个线程去煮饭,同时进行,等最后再把几个线程的结果合起来就把一道菜做好了。
二、匿名函数实现无返回值的多线程异步调用
public class Test {
public static void main(String[] args) {
System.out.println("准备一个新线程");
//Thread newThread = new Thread(new Runnable() {
// @Override
// public void run() {
// printA();
// }
//});
//上面被注释的代码是原始写法代码,下面是使用lambda简化写法
Thread newThread = new Thread(() -> {
printA();
});
newThread.start();//开始执行线程
System.out.println("主线程完成");
}
public static void printA() {
for (int i = 0; i < 5; i++) {
System.out.println("线程执行中:"+i);
}
}
}
jdk8 中上面代码使用 lambda 进一步简化可如下:
public class Test {
public static void main(String[] args) {
System.out.println("准备一个新线程");
new Thread(() -> {
printA();
}).start();
System.out.println("主线程完成");
}
public static void printA() {
for (int i = 0; i < 5; i++) {
System.out.println("线程执行中:" + i);
}
}
}
输出结果:
准备一个新线程
主线程完成
线程执行中:0
线程执行中:1
线程执行中:2
线程执行中:3
线程执行中:4
三、CompletableFuture实现多线程异步调用
Java 8中的 java.util.concurrent.CompletableFuture 提供了CompletableFuture,可用于进行简单的新开一个线程进行异步操作。
无返回值的异步调用
CompletableFuture.runAsync(() -> {
// 要执行的异步方法逻辑
});
示例:
使用CompletableFuture.runAsync异步的计算1到100的和
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
System.out.println("准备开始一个新线程");
CompletableFuture.runAsync(() -> {
int mumber = 0;
for (int i = 0; i <= 100; i++) {
mumber += i;
}
System.out.println("0到100的和是:" + mumber);
});
System.out.println("主线程完成");
}
}
结果:
准备开始一个新线程
主线程完成
0到100的和是:5050
有返回值的异步调用
有时候我们主线程需要用到子线程返回结果,可以使用CompletableFuture.supplyAsync
CompletableFuture<T> future =CompletableFuture.supplyAsync(() -> {
///要执行的异步方法逻辑
});
示例:
子线程计算1到100的和,计算完后子线程将结果返回到 future 中,主线程通过get()来获取子线程的值。
future.get()是阻塞的,也就是说如果主线程执行到 future.get()子线程还没返回值,主线程会一直等待不再往下执行,直到子线程执行完主线程通过 future.get() 获取到了子线程的值才会往下运行。
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
System.out.println("准备开始一个新线程");
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
Integer number = 0;
for (int i = 0; i <= 100; i++) {
number += i;
}
return number;
});
try {
System.out.println(future.get());
System.out.println("完成");
System.out.println("主线程完成");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
结果:
准备开始一个新线程
5050
完成
主线程完成
什么是 Callable 和 Future?
关于线程的有返回值和无返回值其实就是实现了Callable接口的call方法和Runnable接口的run方法。(本文实例基本都用了lambda简化代码,下面的定长线程池部分你可以看到是怎么简化的)
Callable接口类似于 Runnable,从名字就可以看出来了,但是Runnable不会返回结果,并且无法抛出返回结果的异常,而 Callable功能更强大一些,被线程执行后,可以返回值,这个返回值可以被Future拿到,也就是说,Future 可以拿到异步执行任务的返回值。可以认为是带有回调的 Runnable。
Future接口表示异步任务,是还没有完成的任务给出的未来结果。所以说 Callable 用于产生结果,Future 用于获取结果。
四、四种线程池的使用
上面讲的是通过new Thread等方式创建线程,这种方式的弊端是:
-
a. 每次new Thread新建对象性能差。
-
b. 线程缺乏统一管理,可能无限制新建线程,相互之间竞争,及可能占用过多系统资源导致死机或oom。
-
c. 缺乏更多功能,如定时执行、定期执行、线程中断。
下面将要介绍的是Jdk提供的四种线程池的好处在于:
-
a. 重用存在的线程,减少对象创建、消亡的开销,性能佳。
-
b. 可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
-
c. 提供定时执行、定期执行、单线程、并发数控制等功能。
1.newFixedThreadPool定长线程池
public class MyRunable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 2; i++) {
System.out.println("线程名:" + Thread.currentThread().getName() + " i是:" + i);
}
}
}
import thread.MyRunable;
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
for (int i = 0; i < 3; i++) {
fixedThreadPool.execute(new MyRunable());
}
fixedThreadPool.shutdown();//关闭线程池
}
}
上面代码可用lambda表达式简化如下:
(为方便讲解,后面的几种线程池都将采用lambda简化形式)
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
for (int j = 0; j < 3; j++) {
fixedThreadPool.execute(() -> {
for (int i = 0; i < 2; i++) {
System.out.println("线程名:" + Thread.currentThread().getName() + " i是:" + i);
}
});
}
fixedThreadPool.shutdown();//关闭线程池
}
}
输出:
线程名:pool-1-thread-1 i是:0
线程名:pool-1-thread-1 i是:1
线程名:pool-1-thread-2 i是:0
线程名:pool-1-thread-1 i是:0
线程名:pool-1-thread-1 i是:1
线程名:pool-1-thread-2 i是:1
说明:
Executors.newFixedThreadPool(2)里我们声明只能创建2个线程,即使我们循环了3次,也只有两个线程创建出来,超出的一个线程会在队列中等待最后用第二个线程执行,所以出现了thread-1有4次,thread-2两次的情况。
关闭线程池有两种关闭方式:
shutdown()://停止接收新任务,不会立即关闭,直到当前所有线程执行完成才会关闭
shutdownNow();//停止接收新任务,原来的任务停止执行,但是它并不对正在执行的任务做任何保证,有可能它们都会停止,也有可能执行完成。
2.CachedThreadPool可缓存线程池
可缓存线程池为无限大,当执行第二个任务时第一个任务已经完成,会回收复用第一个任务的线程,而不用每次新建线程,可灵活回收空闲线程,若无可回收,则新建线程。
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int j = 0; j < 3; j++) {
cachedThreadPool.execute(() -> {
for (int i = 0; i < 2; i++) {
System.out.println("线程名:" + Thread.currentThread().getName() + " i是:" + i);
}
});
}
cachedThreadPool.shutdown();//关闭线程池
}
}
输出:
线程名:pool-1-thread-1 i是:0
线程名:pool-1-thread-1 i是:1
线程名:pool-1-thread-3 i是:0
线程名:pool-1-thread-2 i是:0
线程名:pool-1-thread-2 i是:1
线程名:pool-1-thread-3 i是:1
3.newSingleThreadExecutor单线程化线程池
newSingleThreadExecutor线程池你可以理解为特殊的newFixedThreadPool线程池,它只会创建一个线程,并且所有任务按照指定顺序。如果你创建了多个任务,因为只会有一个线程,多余的任务会被阻塞到队列里依次执行。
下面的示例循环3次,每次都是用的一个线程,这个线程会先执行第一个循环的任务,在执行第二个循环的任务,再执行第三个循环的任务,所以输出的 i 是有序的。
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
ExecutorService singleThreadPool = Executors.newSingleThreadExecutor();
for (int j = 0; j < 3; j++) {
singleThreadPool.execute(() -> {
for (int i = 0; i < 3; i++) {
System.out.println("线程名:" + Thread.currentThread().getName() + " i是:" + i);
}
});
}
System.out.println("准备关闭线程池");
singleThreadPool.shutdown();//关闭线程池
}
}
输出:
准备关闭线程池
线程名:pool-1-thread-1 i是:0
线程名:pool-1-thread-1 i是:1
线程名:pool-1-thread-1 i是:2
线程名:pool-1-thread-1 i是:0
线程名:pool-1-thread-1 i是:1
线程名:pool-1-thread-1 i是:2
线程名:pool-1-thread-1 i是:0
线程名:pool-1-thread-1 i是:1
线程名:pool-1-thread-1 i是:2
4. newScheduledThreadPool周期性线程池
newScheduledThreadPool周期性线程池用来处理延时任务或定时任务。
无返回值的延时线程示例
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
ScheduledExecutorService scheduleThreadPool = Executors.newScheduledThreadPool(3);
System.out.println("测试1");
for (int i = 0; i < 5; i++) {
scheduleThreadPool.schedule(() -> {
System.out.println("线程名:" + Thread.currentThread().getName() + "已经过了3秒");
}, 3, TimeUnit.SECONDS);
}
System.out.println("测试2");
scheduleThreadPool.shutdown();//关闭线程池
}
}
说明:我们声明了3个线程,创建的时候用循环创建了5个,多出来的2个会阻塞直到前3个线程有执行完的再复用他们的线程;因为采用了延时3秒输出,所以会先输出测试1、测试2,然后等待3秒后再执行输出线程的内容。
输出:
测试1
测试2
线程名:pool-1-thread-2已经过了3秒
线程名:pool-1-thread-3已经过了3秒
线程名:pool-1-thread-1已经过了3秒
线程名:pool-1-thread-3已经过了3秒
线程名:pool-1-thread-2已经过了3秒
有返回值的延时线程示例
public class Test {
public static void main(String[] args) {
ScheduledExecutorService scheduleThreadPool = Executors.newScheduledThreadPool(3);
System.out.println("测试1");
ScheduledFuture<String> scheduledFuture = scheduleThreadPool.schedule(() -> {
return "线程名:" + Thread.currentThread().getName() + "已经过了3秒";
}, 3, TimeUnit.SECONDS);
System.out.println("测试2");
try {
//获取线程返回的值并输出
System.out.println(scheduledFuture.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
scheduleThreadPool.shutdown();//关闭线程池
}
}
输出:
测试1
测试2
线程名:pool-1-thread-1已经过了3秒
定时线程执行
定时执行可以用scheduleAtFixedRate方法进行操作,里面的参数4表示代码或启动运行后第4秒开始执行,3表示每3秒执行一次。因为我们设置了3个线程,所以运行后线程会在第4秒开始用3个线程每3秒执行一次。
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
ScheduledExecutorService scheduleThreadPool = Executors.newScheduledThreadPool(3);
System.out.println("测试1");
scheduleThreadPool.scheduleAtFixedRate(() -> {
System.out.println("线程名:" + Thread.currentThread().getName() + "已经过了3秒");
}, 4, 1, TimeUnit.SECONDS);
System.out.println("测试2");
}
}
输出:
测试1
测试2
线程名:pool-1-thread-1已经过了3秒
线程名:pool-1-thread-1已经过了3秒
线程名:pool-1-thread-2已经过了3秒
线程名:pool-1-thread-3已经过了3秒
......
五、使用guava库的线程池创建线程(推荐)
上面我们介绍了四种jdk自带的线程池,但是平常不推荐使用。在《阿里巴巴java开发手册》中指出了线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程,并且线程池不允许使用Executors去创建,要通过ThreadPoolExecutor方式创建。
这一方面是由于jdk中自带的线程池,都有其局限性,不够灵活;另外使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险。
因此下面介绍更为推荐的使用guava库的线程池创建线程。
使用的依赖maven如下
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
在开始前需要注意线程池的几个参数:
(在下面代码的ThreadPoolExecutor里你会看到这些参数):
corePoolSize=> 线程池里的核心线程数量
maximumPoolSize=> 线程池里允许有的最大线程数量
keepAliveTime=> 空闲线程存活时间
unit=> keepAliveTime的时间单位,比如分钟,小时等
workQueue=> 缓冲队列
threadFactory=> 线程工厂用来创建新的线程放入线程池
handler=> 线程池拒绝任务的处理策略,比如抛出异常等策略
线程池按以下行为执行任务
1. 当线程数小于核心线程数时,创建线程。
2. 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
3. 当线程数大于等于核心线程数,且任务队列已满
-1 若线程数小于最大线程数,创建线程
-2 若线程数等于最大线程数,抛出异常,拒绝任务
无返回值的线程创建
下面代码初始化了线程池并用 executorService.execute 分别创建了两个线程,一个用来输出本线程的名字,另一个用来异步调用 printA() 方法。
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
System.out.println("开始");
//线程池的初始化
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(60, 100,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingDeque<>(1024), namedThreadFactory,
new ThreadPoolExecutor.AbortPolicy());
//开启一个新线程用来输出线程的名字
executorService.execute(() -> System.out.println("第1个线程名字" + Thread.currentThread().getName()));
//再开启一个新线执行printA()
executorService.execute(() -> {
System.out.println("第2个线程名字" +Thread.currentThread().getName());
printA();
});
System.out.println("完成");
executorService.shutdown();
}
public static void printA() {
for (int i = 0; i < 3; i++) {
System.out.println("打印:aaaaaaaaaaaaa");
}
}
}
输出:
开始
完成
第1个线程名字demo-pool-0
第2个线程名字demo-pool-1
打印:aaaaaaaaaaaaa
打印:aaaaaaaaaaaaa
打印:aaaaaaaaaaaaa
有返回值的多线程调用
使用submit
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
System.out.println("开始");
//线程池的初始化
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(5, 10,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingDeque<>(1024), namedThreadFactory,
new ThreadPoolExecutor.AbortPolicy());
//异步调用对象integerCallableTask中的call()计算1-100的和
Future<Integer> future = executorService.submit(() -> {
int nummber = 100;
int sum = 0;
for (int i = 0; i <= nummber; i++) {
sum += i;
}
return sum;
});
try {
//获取计算的结果
Integer result = future.get();
System.out.println("和是:" + result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println("完成");
//shutdown():停止接收新任务,原来的任务继续执行
//shutdownNow():停止接收新任务,原来的任务停止执行
executorService.shutdown();
}
}
线程池的submit和execute方法区别
1、接收的参数不一样
execute接收的参数是new Runnable(),重写run()方法,是没有返回值的:
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println("第1个线程名字" + Thread.currentThread().getName());
}
});
可用lambda表达式简化如下:
executorService.execute(() -> System.out.println("第1个线程名字" + Thread.currentThread().getName()));
submit接收的参数是Callable<Object>,重写call()方法,是有返回值的:
Future<Integer> future = executorService.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int nummber = 100;
int sum = 0;
for (int i = 0; i <= nummber; i++) {
sum += i;
}
return sum;
}
});
可用lambda表达式简化如下:
Future<Integer> future = executorService.submit(() -> {
int nummber = 100;
int sum = 0;
for (int i = 0; i <= nummber; i++) {
sum += i;
}
return sum;
});
2、submit有返回值用于返回多线程计算后的值,而execute没有返回值
有返回值的批量多线程调用
开三个线程计算0-3000的和,第一个任务计算0-1000,第二个任务计算1001-2000,第三个任务计算2001-3000。用invokeAll方法一次性把三个任务进行提交执行,提交后每个任务开始分别计算,最后使用futu.get()分别获取三个结果相加得到总的结果。
用于每个任务的类IntegerCallableTask :
import java.util.concurrent.Callable;
public class IntegerCallableTask implements Callable<Integer> {
int start;
int end;
public int getStart() {
return start;
}
public void setStart(int start) {
this.start = start;
}
public int getEnd() {
return end;
}
public void setEnd(int end) {
this.end = end;
}
public IntegerCallableTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
public Integer call() throws Exception {
System.out.println("正在执行call方法");
int sum = 0;
for (int i = start; i <= end; i++) {
sum += i;
}
return sum;
}
}
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import utils.IntegerCallableTask;
import java.util.*;
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
System.out.println("开始");
//线程池的初始化
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(5, 10,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingDeque<Runnable>(1024), namedThreadFactory,
new ThreadPoolExecutor.AbortPolicy());
//三个多线程异步批量调用对象integerCallableTask中的call()计算0-3000的和
List<IntegerCallableTask> list = new ArrayList<>();
list.add(new IntegerCallableTask(0, 1000));
list.add(new IntegerCallableTask(1001, 2000));
list.add(new IntegerCallableTask(2001, 3000));
List<Future<Integer>> future = null;
Integer result = 0;
try {
System.out.println("准备提交三个任务");
//invokeAll方法提交批量任务,提价后每个任务才会开始执行call方法
future = executorService.invokeAll(list);
//遍历取出三个结果相加得到0-3000的和
for (Future<Integer> futu : future) {
result += futu.get();
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println("0-3000的和是:" + result);
System.out.println("完成");
executorService.shutdown();
}
结果:
开始
准备提交三个任务
正在执行call方法
正在执行call方法
正在执行call方法
0-3000的和是:4501500
完成
多任务其中一个执行完其余都停止
有时候我们需要开多个线程执行多个一样的任务,谁先计算出结果就返回谁的结果,其余线程全部停止结束。比如,开两个线程查找一个txt文件,A线程查找电脑C盘,B线程查找D盘,哪一个线程先找到就返回谁的,并且另一个停止不再继续查找。
采用invokeAny方法。
示例:
import java.util.concurrent.Callable;
import java.util.concurrent.TimeUnit;
public class StringCallableTask implements Callable<String> {
private String taskName;
private int seconds;
public StringCallableTask(String taskName, int seconds) {
this.taskName = taskName;
this.seconds = seconds;
}
@Override
public String call() throws Exception {
System.out.println("正在执行" + taskName);
//模拟耗时操作
TimeUnit.SECONDS.sleep(seconds);
System.out.println(taskName + "执行完成!");
return taskName + "执行完成";
}
}
import utils.StringCallableTask;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) throws InterruptedException, ExecutionException {
//线程池的初始化
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(6, 10, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
//分别创建两个任务
List<StringCallableTask> taskList = new ArrayList<>();
taskList.add(new StringCallableTask("任务1", 2));
taskList.add(new StringCallableTask("任务2", 1));
//使用invokeAny提交两个任务,谁先执行完返回谁,另一个没执行完的结束不再执行
String result = executorService.invokeAny(taskList);
executorService.shutdown();
System.out.println("----------------");
System.out.println("结果:" + result);
}
}
结果:
正在执行任务2
正在执行任务1
任务2执行完成!
----------------
结果:任务2执行完成
invokeAny()与invokeAll()区别:
在上面的示例中我们使用了invokeAny(),而在上一标题有返回值的批量多线程调用中我们使用了invokeAll()。
invokeAny(): 取得第一个完成任务的结果值,当第一个任务执行完成后,会调用interrupt()方法将其他任务中断,也就是结束其他线程的执行。
invokeAll(): 等全部线程任务执行完毕后,取得每一个线程的结果然后返回。
六、线程间的数据同步
有时候我们需要让数据在多个线程间共享,在一个线程上数据改变后,在另一个线程上该数据也要跟着同步。
举个例子,你创建了两个线程,分别用来对课间进出教室的人进行计数,假设有学生n个,一个线程用来计数出教室的人出去一个就n-1,另一个线程用来对进教室的人计数进一个就n+1,两个线程间的n要同步一致。
多线程间的数据一致性——原子操作
下面的代码开启30个线程,每个线程执行1000次num加一操作最后输出结果。
(1). 为确保num在30个线程间的同步,使用了AtomicInteger原子类;
(2) .为确保30个线程都执行完再输出,使用了CountDownLatch来对线程计数,每执行完一个线程则countDownLatch.countDown()线程计数器减一,最后用countDownLatch.await()让程序等着,直到countDownLatch为0了才往下执行输出结果。
:
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class Test {
public static void main(String[] args) {
//使用AtomicInteger来保证不同线程进行加1后,num都能保持一致,num初始化为0
AtomicInteger num = new AtomicInteger(0);
//使用CountDownLatch来等待所有30个计算线程执行完,计数器初始化为30
CountDownLatch countDownLatch = new CountDownLatch(30);
//线程池初始化
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(60, 100, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
//开启30个新线程进行累加操作,每个线程进行10000次对num加1
for (int i = 0; i < 30; i++) {
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName());
for (int j = 0; j < 10000; j++) {
num.incrementAndGet();//num加1,原子性的num++,通过循环CAS方式
}
//当此线程执行完,线程计数器减1
countDownLatch.countDown();
});
//返回当前线程执行到第几个
System.out.println("剩余线程数量:" + countDownLatch.getCount());
}
//等到线程计数器变为0,也就是确保30个线程都执行完
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
//输出最终的num
System.out.println("结果:" + num);
executorService.shutdown();
}
}
输出:
......
demo-pool-27
demo-pool-25
demo-pool-20
demo-pool-28
demo-pool-29
结果:300000
补充:
常用的是原子类:AtomicInteger、AtomicLong、AtomicBoolean、AtomicReference;并且AtomicInteger、AtomicLong还支持算数运算。其中AtomicReference用于对象。
还有原子数组类:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray;原子数组中的每个元素都可以实现原子更新。
线程间变量同步——synchronized关键字
使用synchronized作用在代码块上或方法上对变量进行同步操作。
用synchronized关键字修饰的方法叫同步方法,虽然 synchronized关键字加在代码块上但它锁定的是调用当前方法的对象。
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
import java.util.stream.IntStream;
public class AddNumber {
private int number = 0;
static CountDownLatch countDownLatch = new CountDownLatch(7);
//synchronized作用在方法上, 循环100次对number加1
public synchronized void addNumber() {
IntStream.range(0, 100).forEach(i -> number += 1);
//线程减1
countDownLatch.countDown();
}
//或者synchronized作用在方法块上,循环100次对number加1
/* public void addNumber() {
synchronized (this) {
IntStream.range(0, 100).forEach(i -> number += 1);
}
//线程减1
countDownLatch.countDown();
}*/
public int count() {
//线程池初始化
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(60, 100, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
//创建7个线程,每个线程循环100次对number加1
IntStream.range(0, 7).forEach(i -> executorService.execute(() -> addNumber()));
try {
//等待所有线程执行完成
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("完成");
executorService.shutdown();
return number;
}
}
测试:
import utils.AddNumber;
public class Test {
public static void main(String[] args) {
AddNumber addNumber = new AddNumber();
System.out.println("结果是:" + addNumber.count());
}
}
输出:
完成
结果是:700
拓展:
synchronize 关键字可以与 wait() 和 nitify() 方法相结合实现实现等待/通知模式,除了synchronized外。其他方式也能实现等待/通知,如:
- ReentrantLock 类 和condition 对象也可以实现同样的功能,因此你还可以了解下可重入锁 ReentrantLock 锁详解
- LockSupport 类的 park 和 unpark 操作,可参考JUC锁: LockSupport详解
线程间通信——管道通信
线程间的数据传递可以使用管道输入流 PipedInputStream 和管道输出流 PipedOutputStream 来实现。多线程管道通信的主要流程是在一个线程中向PipedOutputStream写入数据,这些数据会自动传送到对应的管道输入流PipedInputStream中,其他线程通过读取PipeInputStream中缓冲的数据实现多线程间通信。
示例一:
三个线程将按顺序输出A、B、C
public static void main(String[] args) throws Exception {
//创建输入管道和输出管道流并连接它们
PipedOutputStream pout = new PipedOutputStream();
PipedInputStream pin = new PipedInputStream();
pout.connect(pin);
//此线程输出A,然后通过管道把B传到下一个线程
new Thread(() -> {
try {
System.out.println("A");
pout.write("B".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}).start();
//此线程从管道获取B输出,然后通过管道把c传到下一个线程
new Thread(() -> {
try {
byte[] b = new byte[1];
pin.read(b);
String s = new String(b);
System.out.println(s);
pout.write("C".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}).start();
//此线程从管道获取C输出
new Thread(() -> {
try {
byte[] b = new byte[1];
pin.read(b);
String s = new String(b);
System.out.println(s);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
输出:
A
B
C
示例二:
public static void main(String[] args) throws Exception {
//创建输入管道和输出管道流并连接它们
PipedOutputStream pout = new PipedOutputStream();
PipedInputStream pin = new PipedInputStream();
pout.connect(pin);
//此线程用于往输出管道写入1到3
new Thread(() -> {
for (int i = 1; i <= 3; i++) {
try {
pout.write(i);
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
//此线程读取管道里的1到3并输出
new Thread(() -> {
for (int i = 1; i <= 3; i++) {
try {
System.out.println(pin.read());
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
输出:
1
2
3
线程间变量隔离独立——ThreadLocal
ThreadLocal是一个线程内部的存储类,可以在指定线程内存储数据,数据存储以后,只有指定线程可以得到存储数据。
ThreadLocal提供了线程内存储变量的能力,这些变量不同之处在于每一个线程读取的变量是对应的互相独立的。通过get和set方法就可以得到当前线程对应的值。
下面的代创建了两个线程,每个线程向localVar 存储一个值,第一个线程存储了“localVar1”,第二个线程存储了localVar2“”,各现场存储的值只能在各自的线程里设置、读写、删除,各不影响。
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
public class Test {
static ThreadLocal<String> localVar = new ThreadLocal<>();
public static void main(String[] args) {
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(60, 100, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
executorService.execute(()->{
//设置线程1中本地变量的值为localVar1
localVar.set("localVar1");
//打印当前线程中本地内存中本地变量的值
System.out.println("thread1" + " :" + localVar.get());
//清除本地内存中本线程创建的的本地变量
localVar.remove();
//打印清除后的本地变量
System.out.println("thread1 after remove : " + localVar.get());
});
executorService.execute(()->{
//设置线程2中本地变量的值
localVar.set("localVar2");
//打印当前线程中本地内存中本地变量的值
System.out.println("thread2" + " :" + localVar.get());
//清除本地内存中本线程创建的的本地变量
localVar.remove();
//打印清除后的本地变量
System.out.println("thread2 after remove : " + localVar.get());
});
}
}
输出:
thread1 :localVar1
thread2 :localVar2
thread1 after remove : null
thread2 after remove : null
ConcurrentHashMap的使用
一般我们在开发中会使用HashMap,但是HashMap是线程不安全的不能在多线程中使用,一般在多线程中我们使用ConcurrentHashMap来确保线程安全。
ConcurrentHashMap使用示例:
开启三个线程,两个put数据,一个get数据
注意:ConcurrentHashMap的key和value不能为null,否则会报空指针异常。
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap();
System.out.println("开始");
//线程池的初始化
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(60, 100,0L,TimeUnit.MILLISECONDS,new LinkedBlockingDeque<>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
executorService.execute(() -> {
for (int i = 0; i < 10; i++) {
map.put(i,String.valueOf(i));
}
});
executorService.execute(() -> {
for (int i = 10; i < 20; i++) {
map.put(i,String.valueOf(i));
}
});
executorService.execute(() -> {
for (int i = 0; i < 20; i++) {
System.out.println(map.get(i));
}
});
System.out.println("完成");
executorService.shutdown();
System.out.println(map.size());
}
}
输出:
开始
完成
0
1
2
3
......
扩展:
HashMap、HashTable、ConcurrentHashMap的区别:
HashTable: 线程安全,采用synchronized实现,效率低,key和value不能为空
HashMap: 线程不安全,key和value能为空(key只能有一个为null,value可以有多个为null),初始化容量为16,负载因子0.75
ConcurrentHashMap: 线程安全,用于多线程,采用分段锁,比HashTable效率更高,key和value不能为空,,初始化容量为16,负载因子0.75
七、Semaphore信号
Semaphore 是一种并发编程中常用的同步机制,它提供了一种简单而有效的方法来控制多个线程之间的并发访问。Semaphore 可以用于限制同时访问某个共享资源的线程数量,或者在多个线程之间协调执行顺序。
Semaphore是计数信号量。Semaphore管理一系列许可。每个acquire方法阻塞,直到有一个许可证可以获得然后拿走一个许可证;每个release方法增加一个许可,这可能会释放一个阻塞的acquire方法。然而,其实并没有实际的许可这个对象,Semaphore只是维持了一个可获得许可证的数量。
Semaphore常用方法如下:
(1) acquire(int permits): 获取 permits 个许可,如果没有足够的许可,当前线程会被阻塞,直到有足够的许可。该方法会对许可数量进行减少。如果调用该方法时许可数量为0,则当前线程会一直被阻塞,直到有另一个线程释放了许可。
(2) release(int permits): 释放permits个许可,使得其他被阻塞的线程可以获取许可。该方法会对许可数量进行增加。如果释放许可后,有被阻塞的线程可以获取许可,则会唤醒这些线程。
(3) tryAcquire(int permits, long timeout, TimeUnit unit): 尝试获取permits个许可,在timeout时间内等待获取许可,如果在timeout时间内获取不到足够的许可,则返回false。该方法会对许可数量进行减少。如果调用该方法时许可数量为0,则会等待timeout时间,如果在timeout时间内有许可可用,则获取许可,返回true;否则返回false。
(4) availablePermits(): 获取Semaphore对象当前可用的许可数量。
示例:
//初始化 5 个许可
Semaphore semaphore = new Semaphore(5);
//占用 2 个许可后,semaphore中许可将会减少2个,只有3个许可
semaphore.acquire(2);
//释放 4 个许可,semaphore中将增加4个许可,变成 7 个许可
semaphore.release(3);
// 获取Semaphore对象当前可用的许可数量,将返回 7
int permits = semaphore.availablePermits();
在多线程中的运用:
以力扣第 1115. 交替打印 FooBar 题为例,题目如下:
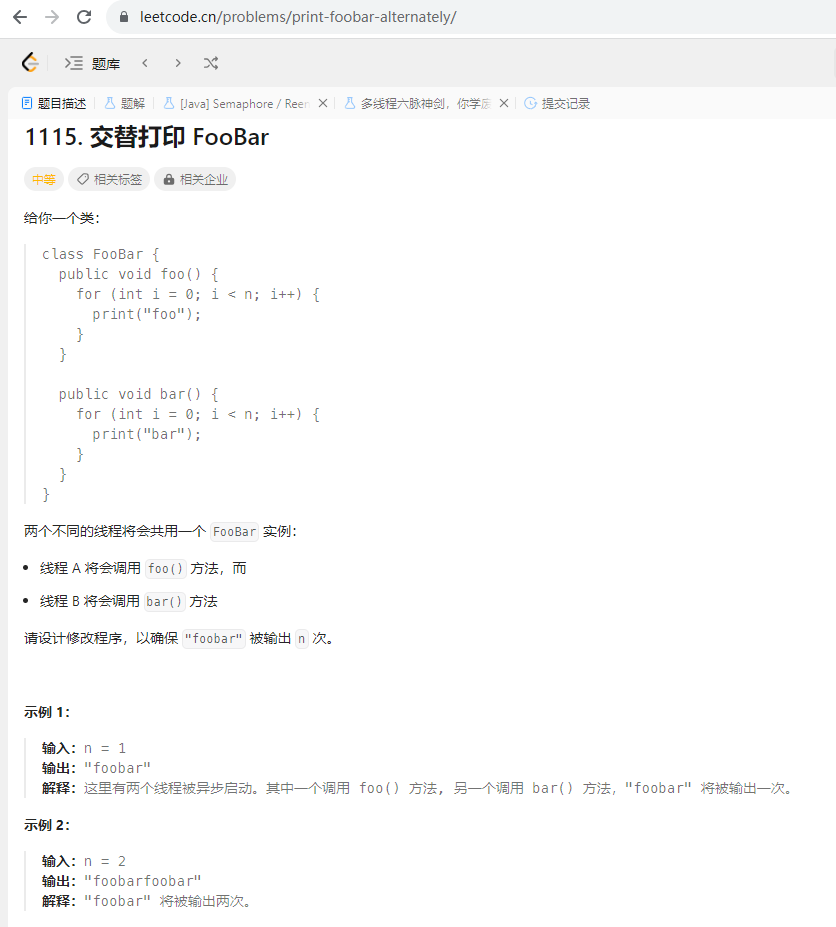
代码如下:
import java.util.concurrent.Semaphore;
public class FooBar {
Semaphore foo = new Semaphore(1);
Semaphore bar = new Semaphore(0);
private int n;
public FooBar(int n) {
this.n = n;
}
//foo方法打印 n 次"foo"
public void foo() throws InterruptedException {
for (int i = 0; i < n; i++) {
//从foo里获取1个许可,若没有则阻塞等待直到有许可
foo.acquire();
System.out.print("foo");
//bar释放1个许可
bar.release();
}
}
//foo方法打印 n 次"bar"
public void bar() throws InterruptedException {
for (int i = 0; i < n; i++) {
//从bar里获取1个许可,若没有则阻塞等待直到有许可
bar.acquire();
System.out.print("bar");
//foo释放1个许可
foo.release();
}
}
}
测试:
public static void main(String[] args) {
FooBar fooBar = new FooBar(10);
//新开线程执行foo()方法
Thread fooThread = new Thread(() -> {
try {
fooBar.foo();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
//新开线程执行bar()方法
Thread barThread = new Thread(() -> {
try {
fooBar.bar();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
fooThread.start();
barThread.start();
}
输出结果:
foobarfoobarfoobarfoobarfoobarfoobarfoobarfoobarfoobarfoobar
八、简单练习
考虑用多线程做个简单的多文件搜索字符串的程序:
假设有三个参数folderPath、searchStr、containsSubFolder ,其分别代表文件夹路径、要搜索的字符串、是否搜索子目录。
如果 containsSubFolder 为 false 就只搜索 folderPath 文件夹下(不包含其子目录)所有可读文件中哪几行包含 searchStr 关键字符串,并输出该行内容;
如果 containsSubFolder 为 true 就搜索 folderPath 文件夹下包含其子目录的所有可读文件中哪几行包含 searchStr 关键字符串,并输出该行内容。
需要考虑的点:
1.采用2个线程:
- 线程 A 扫描文件夹下所有的可读文件的路径然后放到队列里;
- 线程 B 去不断从队列里取文件路径数据然后去文件中搜索;
2. 线程 B 何时结束:
- 线程 A 扫描结束后,应该返回一个标识给线程 B 告诉它 A 线程已经结束了;
- 当 B 线程得知 A 线程结束后 B 线程要判断队列里还有没有数据,没有的话说明全部的文件都搜索完了,就结束搜索;
3.考虑线程间的通信,即共享变量
4.考虑使用使用什么队列来存放 A 线程给的数据,以及给 B 线程提供数据
5.考虑只有A、B两个线程都执行完后才输出结果。
下面的代码将使用定长线程池创建两个线程,然后使用 LinkedBlockingQueue 无界阻塞队列接收 A 线程数据以及为 B 线程提供数据,使用 AtomicBoolean 来线程间共享变量,使用CountDownLatch来等待两个线程执行完再输出结果。
工具类SearchUtils 如下:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.atomic.AtomicBoolean;
public class SearchUtils {
//当在文件夹中搜索时,遇到以下常见的非文本文件则跳过
public static List<String> excludeFileType = Arrays.asList(
"jar", "zip", "rar", "7z", "tar", "gz", "xz", "bz2", "doc", "class", "pak",
"xls", "ppt", "pdf", "docx", "xlsx", "pptx", "jpg", "jpge", "gif", "png",
"xltd", "war", "hprof", "m4a", "swf", "mobi", "jpeg", "tiff", "svg", "psd",
"mp3", "aac", "mp4", "avi", "flv", "mkv", "mkv", "mpeg", "msi", "tgz",
"rmvb", "apk", "ts", "map", "car", "mov", "wav", "raw", "dll", "woff",
"eot", "otf", "ico", "ttf", "ttc", "fon", "dl_", "pd_", "ex_", "etl",
"sys", "iso", "isz", "esd", "wim", "gho", "dmg", "mpf", "exe", "ldf", "mdf");
/**
* 获取 folderPath 文件夹下的所有的可读文件的路径,并将 路径存入 allFilesPath 里
*
* @param folderPath 要搜索的文件夹路径
* @param allFilesPath 可读文件的路径存放进allFilesPath
* @param containsSubFolder 是否搜索子文件夹
*/
public static void getAllReadFilessPath(String folderPath, BlockingQueue<String> allFilesPath, boolean containsSubFolder) {
File file = new File(folderPath);
File[] tempList = file.listFiles();
//System.out.println("正在扫描文件夹:" + dirPath);
if (null == tempList) {
return;
}
for (int i = 0; i < tempList.length; i++) {
String filePath = tempList[i].toString();
String file_Type = filePath.substring(filePath.lastIndexOf(".") + 1).toLowerCase();;
if (tempList[i].isFile()) {
//如果是文件并且是可读的文本文件
if (!excludeFileType.contains(file_Type)) {
try {
allFilesPath.put(filePath);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} else {
//如果是文件夹且要读取子文件夹
if (containsSubFolder) {
getAllReadFilessPath(filePath, allFilesPath, containsSubFolder);
}
}
}
}
/**
* 不断从 allFilesPath 里取文件路径然后搜索文件中是否含有关键字,把结果存到 searchResult 里
*
* @param allFilesPath 用于从该队列中获取文件路径
* @param searchStr 要搜索的关键字
* @param searchResult 存放最终的结果
* @param scanFinish 要搜索的关键字
*/
public static void searchAllFiles(BlockingQueue<String> allFilesPath, String searchStr, Map<String, Map<Integer, String>> searchResult, AtomicBoolean scanFinish) {
while (true) {
String filePath = null;
try {
filePath = allFilesPath.poll(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
//在 filePath 文件中搜索 searchStr 关键字
Map<Integer, String> map = scanFile(filePath, searchStr);
if (map.size() != 0) {
searchResult.put(filePath, map);
}
if (allFilesPath.size() == 0 && scanFinish.get()) {
//若队列中的数据已经取完并且扫描线程也已经扫描完就跳出循环
break;
}
}
}
/**
* 搜索指定文件中的关键字
*
* @param filePath 要搜索的文件路径
* @param searchStr 要搜索的关键字
* @return 返回的 map<行数, 该行内容>
*/
public static Map<Integer, String> scanFile(String filePath, String searchStr) {
Map<Integer, String> map = new LinkedHashMap<>();
if (filePath == null) {
return map;
}
FileInputStream file = null; //读取文件为字节流
try {
file = new FileInputStream(filePath);
InputStreamReader in = new InputStreamReader(file, StandardCharsets.UTF_8); //字节流转化为字符流,以UTF-8读取防止中文乱码
BufferedReader buf = new BufferedReader(in); //加入到缓存区
String str = "";
int row = 1;
while ((str = buf.readLine()) != null) {
//按行读取,到达最后一行返回null
if (str.contains(searchStr)) {
map.put(row, str);
}
row++;
}
buf.close();
file.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return map;
}
}
线程相关代码:
public static void main(String[] args) throws Exception {
//搜索 F 盘及其子文件夹下所有可读文件中那些文件包含 "g789d" 关键字
Map<String, Map<Integer, String>> searchResult = search("F:\\", "g789d", true);
StringBuffer result = new StringBuffer();
for (Map.Entry<String, Map<Integer, String>> m : searchResult.entrySet()) {
result.append(" 文件: " + m.getKey());
result.append("\n");
for (Map.Entry<Integer, String> n : m.getValue().entrySet()) {
result.append("\t第 " + n.getKey() + " 行:" + n.getValue() + "\n");
}
result.append("\n\n ");
}
System.out.println(result.toString());
}
public static Map<String, Map<Integer, String>> search( String folderPath, String searchStr, boolean containsSubFolder){
//存储所有的扫描的可读文件的路径
BlockingQueue<String> allFilesPath = new LinkedBlockingQueue<>();
//用于判断扫描线程是否已扫描完成
AtomicBoolean scanFinish = new AtomicBoolean(false);
//存储所有搜索的结果<文件名,<行数,内容>>
Map<String, Map<Integer, String>> searchResult = new LinkedHashMap<>();
//线程计数器
CountDownLatch countDownLatch = new CountDownLatch(2);
//创建一个定长线程池,初始化为2
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
//创建一个线程用于扫描所有的可读文件路径,然后存放到 allFilesPath 里,扫描完将 scanFinish 设为 true
fixedThreadPool.execute(() -> {
SearchUtils.getAllReadFilessPath(folderPath, allFilesPath, containsSubFolder);
scanFinish.set(true);//当此线程扫描完所有线程后将scanFinish设置为true
countDownLatch.countDown();//线程计数器减一
});
//创建一个线程不断从 allFilesPath 里取文件路径然后搜索文件中是否含有关键字,把结果存到 searchResult 里,
// 当 allFilesPath 为空并且 scanFinish 为true (即上面的线程扫描完了,此线程也把 allFilesPath 里的所有的文件扫描完了),就跳出searchAllFiles方法
fixedThreadPool.execute(() -> {
SearchUtils.searchAllFiles(allFilesPath, searchStr, searchResult, scanFinish);
countDownLatch.countDown();
});
try {
//等待上面两个线程执行完
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
//关闭线程池
fixedThreadPool.shutdown();
return searchResult;
}
结果:
文件: F:\asposeHtml\aa_files\we.txt
第 4 行:fhfg789dfrh
文件: F:\fileTypeTest\havaAttachFile\we.txt
第 4 行:fhfg789dfrh
文件: F:\spireHtml\myExcel_files\we.txt
第 4 行:fhfg789dfrh
文件: F:\we.txt
第 4 行:fhfg789dfrh
第 8 行:fhfg789dfrh
第 12 行:fhfg789dfrh
文件: F:\ydz\test\新建文件夹\we.txt
第 4 行:fhfg789dfrh
本例只是一个简单的生产者和消费者问题,且生产者和消费者都只有一个,如果有多个生产者和消费者可以参考:
Producer Consumer Solution using BlockingQueue in Java Thread
Producer-Consumer Problem With Example in Java