机器学习知识点复习(上)
一
归纳
从特殊到一般,也就是从一些实例中总结规律–“指泛化能力”
演绎
从一般到特殊,从基础原理推演出具体情况-“特化能力”
过拟合
学习器把训练样本学习的”太好“,导致泛化性能下降。
- 解决办法:优化目标正则项、early stop(早停)
例如训练集中样本树叶有锯齿,过拟合模型分类新的没有锯齿的树叶样本,认为其不是树叶(误以为树叶必须有锯齿)
欠拟合
对训练样本的一般性质尚未学好
-
解决办法:
-
决策树:拓展分支
-
神经网络:增加训练轮次
-
例如,训练集为树叶样本,给出一棵树后,欠拟合模型分类结果为树叶,因为误以为绿色的都是树叶
自助采样
也称“有放回采样”、“可重复采样“。有一个m个样本的数据集,随机从其中取出一个样本放入采样集,再把样本放回原始的数据集,之后重复进行m次这样的随机采样操作,即可得到一个包含m个样本数据的集合。原始数据集中有的样本可能会被多次取出,但有的则可能从不被取到。样本在m次采样中始终不被采样的概率是(1-1/m)^m,取极限约等于0.368。
自助法即直接以自主采样为基础,其过程可以这样理解:
- 有一个数据集
D,它里面有m个样本,假设采样后生成的数据集为D'- 每次从D中随机选取一个样本,将其加入到
D'中,之后再将该样本放回D中,注意此时D中样本数量仍然不变,仍为m个样本- 重复执行第
2步m次- 最终得到包含
m个样本数据的集合D'。对于
D中的一部分数据,肯定会在D'中多次出现,但是也会有一部分数据在D'不出现。样本在
m次采样中始终不被采样的概率是(1-1/m)^m,取极限约等于0.368说明数据集
D中约有36.8%的样本不会出现在D'中,所以我们可以拿D'作为测试集,D\D'用作训练集优势:
- 训练集与原样本集同规模
- 使用数据集小,划分难
这种类型进行测试的结果叫做包外估计
信息熵
度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占的比例为p_k(K=1,2,...,|у|),则D的信息熵定义为:
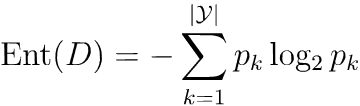
Ent(D)的值越小,则D的纯度越高。
- 规定:若
p = 0,则plog₂p = 0 Ent(D)的最小值为0 (即全部为同一类),最大值为log₂|y|(每一类发生的概率相同)。
例题:
一堆数据可分成两类,第一类占50%,第二类占50%,求信息熵是 ?
Ent(D) = (- 0.5*log₂0.5)+(-0.5*log₂0.5)= -log₂(1/2) = 1
一堆数据可分成两类,第一类占95%,第二类占5%,求信息熵是?
Ent(D) = (- 0.95*log₂0.95)+(-0.05*log₂0.05)
数据归一化
将不同变化范围的值映射到[0,1]中。
规范化:将不同变化范围的值映射到相同的固定范围中。常见的是[0,1],此时亦”归一化“。
泛化
学得模型适用于新样本的能力。
混淆矩阵
以矩阵形式总结分类模型预测结果的情形分析表

二
错误率
分类错误的样本数占样本总数的比例。m个样本里a个样本分类错误,则错误率E=a/m。
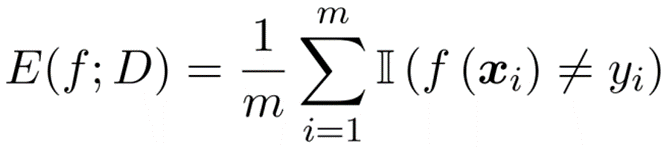
精度
分类正确的样本数占样本总数的比例。
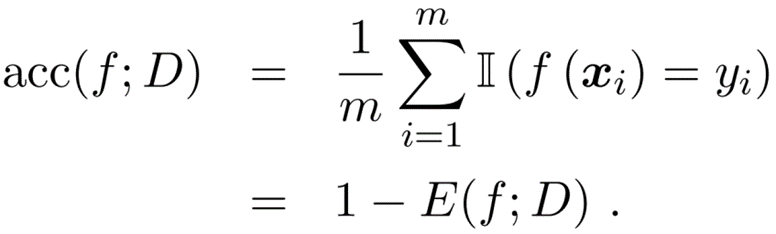
将预测对的样本数除以样本总数,也就等于1-E
查准率P

查准率 P = 真正例 ( 真正例 + 假正例 ) 查准率P=\frac{真正例}{(真正例+假正例)} 查准率P=(真正例+假正例)真正例
P = T P ( T P + F P ) P=\frac{TP}{(TP+FP)} P=(TP+FP)TP
查全率R

查全率 R = 真正例 ( 真正例 + 假反例 ) 查全率R=\frac{真正例}{(真正例+假反例)} 查全率R=(真正例+假反例)真正例
P = T P ( T P + F N ) P=\frac{TP}{(TP+FN)} P=(TP+FN)TP
测试集
学得模型后,拿一些确定得数据去测试模型,这些数据构成测试集。注意测试集中的测试例已知它的标签(结果)
训练集
训练过程中使用的数据称为训练数据,其中每个样本称为一个"训练样本",这些训练样本组成的集合成为"训练集"。
留出法
直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T
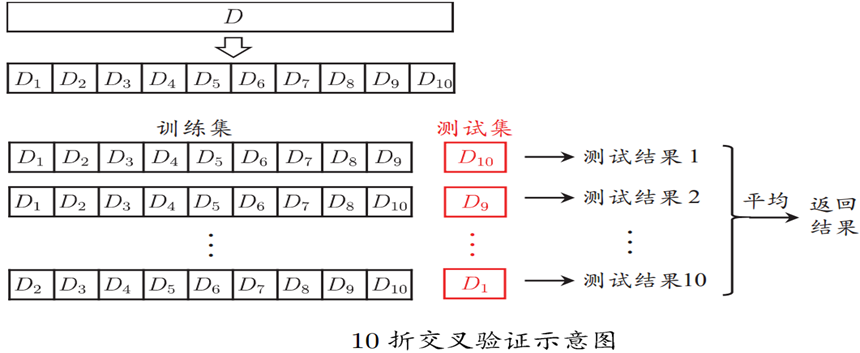
k折交叉验证法
将数据集分层采样划分为k个大小相似的互斥子集,即D=D_1∪D_2∪...∪D_k, D_i∩D_j=∅(i≠j)。且要求每个子集尽可能保证数据分布一致(D中分层采样得到)。
然后我们每次用k-1个子集的并集作为训练集,剩余子集作为测试集,最终返回k个测试结果的均值,k常用10
一般我们进行若干次随机划分,重复进行实验评估后取平均值(k=m留一法)
这种方法的评估结果被认为较为准确,但计算开销大
上述过程总体的思想就是,会选k次,最后训练出k个学习器,然后求平均,这样可以尽可能的利用数据集
好处:
- 解决数据量不够大的问题
- 解决参数调优问题
(下图展示10折交叉验证,图片来自西瓜书)
三
P-R曲线
以查准率P做纵轴,查全率R做横轴作图,得到的曲线即为查准率-查全率曲线(P-R曲线)。显示该曲线的图即为“P-R图”。若一个学习器的P-R曲线包住另一个学习器的P-R曲线,则断言前者性能优于后者。
- 平衡点BEP:一种综合查准率和查全率的度量方式,它是查准率=查全率时的取值。基于BEP进行比较时,认为BEP值大的学习器更优秀
ROC和AUC
ROC曲线:以“假正例率”为横轴,“真正例率”为纵轴可得到的曲线,全称“受试者工作特征”。
ROC曲线绘制方法:给定m^+个正例和m^-个负例,根据学习器预测结果对样例进行排序,将分类阈值设为每个样例的预测值,当前标记点坐标为(x,y),当前若为真正例,则对应标记点的坐标为(x,y+1/m^+ );当前若为假正例,则对应标记点的坐标为(x+1/m^- ,y),然后用线段连接相邻点.
ROC曲线衡量比较方式:
- 若某个学习器的ROC曲线被另一个学习器的曲线“包住”,则后者性能优于前者;
- 如果曲线交叉,可以根据ROC曲线下面积大小进行比较,这个面积也叫做AUC值
AUC衡量了样本预测的排序质量
AUC可估算为:
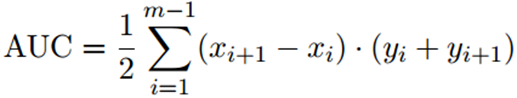
排序损失定义为:
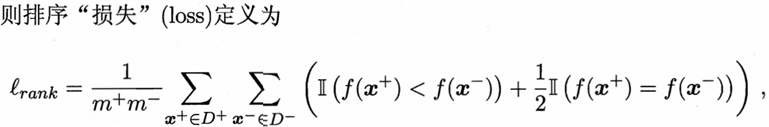
另外AUC = 1 - "损失",也就是说“损失” = 1 - AUC
余弦相似度
通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
若存在两个向量A和B; Ai,Bi为A和B的各分量,余弦相似度相似度为similarity
s i m i l a r t y = c o s ( θ ) = A ⋅ B ∣ ∣ A ∣ ∣ B ∣ ∣ = ∑ i = 1 n A i × B i ∑ i = 1 n ( A i ) 2 × ∑ i = 1 n ( B i ) 2 similarty = cos(θ) = \frac{A·B}{||A||B||} = \frac{\sum_{i=1}^nA_i×B_i}{\sqrt{\sum_{i=1}^n(A_i)^2} × \sqrt{\sum_{i=1}^n(B_i)^2}} similarty=cos(θ)=∣∣A∣∣B∣∣A⋅B=∑i=1n(Ai)2×∑i=1n(Bi)2∑i=1nAi×Bi
四
线性回归
线性模型
线性模型试图学得一个通过属性的线性组合来进行预测的函数,即
一般向量形式:
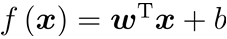
其中

w和b是模型参数,分别为权重、系数
注意,这里w和x都是d×1矩阵,把它俩想象成竖着的形式。
线性模型优点:
-
形式简单、易于建模
-
可解释性强
这里
w_1,w_2,...对应可理解为对某维属性的贡献度
线性回归
给定数据集
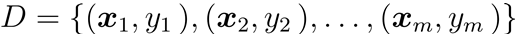
其中
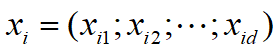
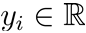
线性回归的目的: 学得一个线性模型以尽可能准确地预测实值输出标记
线性回归试图学得 f ( x i ) = w T x i + b ,使得 f ( x i ) ≃ y i 线性回归试图学得f(x_i)=w^Tx_i+b ,使得f(x_i)\simeq y_i 线性回归试图学得f(xi)=wTxi+b,使得f(xi)≃yi
分类
属于“监督学习”
模型输出的预测值为离散值,则此类学习任务称为分类
回归
属于“监督学习”
模型输出的预测值为连续值,则此类学习任务称为分类
对数几率回归
实质:用线性回归模型的预测结果去逼近真实标记的对数几率,这样子对应的模型就是对数几率回归。
运用对数几率函数
y = 1 1 + e − z y = \frac{1}{1+e^{-z}} y=1+e−z1
变为
y = 1 1 + e − ( w T x + b ) y = \frac{1}{1+e^{-(w^Tx+b)}} y=1+e−(wTx+b)1
变为
l n y 1 − y = w T x + b ln\frac{y}{1-y}=w^Tx+b ln1−yy=wTx+b
对数几率(log odds)
- 约定y为样本x作为正例的可能性,则1-y为样本x作为负例的可能性
- 对数几率:样本作为正例的相对可能性的对数
l n y ( 1 − y ) ln\frac{y}{(1−y)} ln(1−y)y
对数几率回归(主要针对二分类问题)优点
- 无需事先假设数据分布
- 可得到“类别”的近似概率预测
- 有良好的数学性质,可直接应用现有数值优化算法求取最优解
多分类问题分解策略
多分类学习方法:
- 二分类学习方法推广到多类
- 利用二分类学习器解决多分类问题**(常用)**
- 对问题进行拆分,为拆出的每个二分类任务训练一个分类器
- 对于每个分类器的预测结果进行集成以获得最终的多分类结果
分解策略
一对一(One vs. One, OvO)
拆分阶段
N个类别两两配对- 得到
N(N-1)/2个二类任务
- 得到
- 各个二类任务学习分类器
- 得到
N(N-1)/2个二类分类器
- 得到
测试阶段
-
新样本提交给所有分类器预测
- 得到N(N-1)/2 个分类结果
-
投票产生最终分类结果
- 被预测最多的类别为最终类别
一对其余(One vs. Rest, OvR)
拆分阶段
-
某一类作为正例,其他反例
- N 个二类任务
-
各个二类任务学习分类器
- N 个二类分类器
测试阶段
-
新样本提交给所有分类器预测
- N 个分类结果
-
比较各分类器预测置信度
- 置信度最大类别作为最终类别
多对多(Many vs. Many, MvM)
-
若干类作为正类,若干类作为反类
-
纠错输出码(Error Correcting Output Code, ECOC)

