一、T检验
对连续变量使用的方法:T检验、方差检验
1.均值(Means)过程:
完成数据分组输出描述统计量
2.T检验:
用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著
前提:总体服从正态分布、样本量不超过30
3.单样本T检验:
推断该总体的均值是否与指定的检验值之间存在显著性差异。
假设-》t统计量-》统计量观测值和概率P-》比较P和显著性水平α(P<a:有差异)
α=0.05
实例:药物溶解
4.独立样本T检验:
利用来自两个总体的独立样本,推断两个总体的均值是否存在显著差异。
前提: 独立;正态;方差齐性
假设-》t统计量-》统计量观测值(F、t)和概率P-》比较P和显著性水平α(P(F)<a:方差不同;P(t)<a:有差异)
fa=0.05,ta=0.01
实例:两个老师的教学质量
5.配对样本T检验
利用来自两个不同总体的配对样本,推断两个总体的均值是否存在显著差异。
配对:1)两样本的观察值数目相等;2)两样本的观察值的顺序不能随意更改【例:干预前、干预后】
t-》P-》a(P<a:有差异)
a=0.01
实例:对贫血儿童进行干预后的血红蛋白数
二、非参数检验
在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态等进行推断的方法。
1.优缺点
优点:
1、对数据的要求不严格,对资料的分布类型要求较宽松;
2、检验方法灵活,使用用途广泛;
3、非参数检验的计算相对简单,易于理解和掌握
缺点:
1、当资料满足参数检验的条件时,非参数检验会降低检验的功效;
2、非参数检验主要使用了登记或符号秩,而不是使用原始数据,降低了检验的有效性。
2.卡方检验
通过分析实际的频数与理论的频数之间的差别或者吻合程度,
来推断总体是否服从某种理论分布,或者某种假设分布。

x²越小越接近期望
案例:小白鼠显形致死性实验
3.游程检验:
推断数据序列中两类事件的发生过程是否随机。
游程:分类变量中有相同取值的几个连续记录
问1:序列:110001101111有几个游程?答:5个
三、相关、回归
1.相关系数
0-》完全不相关,
绝对值为1-》完全相关,
大于0-》正相关,
小于0-》负相关,
取值范围[-1,1]
Ø最小二乘法
通过最小化误差的平方和寻找数据的最佳函数匹配,即各实测点到回归直线的纵向距离的平方和最小。通过最小二乘法,可以很好的使拟合曲线处于样本数据的中心位置。
Ø信息熵
度量样本纯度的指标
Ø信息增益
当选择某个特征对数据集进行分类时,分类后的数据集信息熵(不确定度)会比分类前的小,其差值表示为信息增益,用于衡量某个特征对分类结果的影响大小
相关的分类:
双变量相关:两个变量的三点呈直线的趋势
偏变量相关:两个变量的真实相关程度与方向(消除受其他变量的影响,与协方差分析类似)
距离相关:不同变量之间的相似性和差异性性分析
2.回归
利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
注意事项:
•欠拟合(underfitting):
拟合函数和训练集误差较大
•适度拟合(justright):
拟合函数和训练集误差较小
•过拟合(overfitting):
拟合函数完美匹配训练集数据
(过拟合可通过决策树:剪枝、神经网络:正则化)
回归的分类:线性回归、逻辑回归、多项式回归
(1)线性回归方程:
Y=a+bX
其中: a:回归直线在纵轴上的截距
b:回归系数,即直线的斜率
Ø似然函数
概率:
用于在已知一些参数的情况下,预测接下来的观测所得到的结果
似然性:
用于在已知某些观测所得到的结果下,对有关事务的性质的参数进行估计。

实例:黑球白球
模型本身不确定,有概率出现的:贝叶斯方法
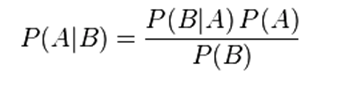


3.逻辑回归Logistic
将回归结果输出值映射为结果值(0,1)
分类:二项分类逻辑回归、有序逻辑回归、多项分类逻辑回归

4.回归和相关的区别
1.相关:2个变量-》正态分布;回归:应变量-》正态分布
2.相关:相互关系;回归:依存关系
3.相关:线性关系密切程度及相关方向;回归:应变量随自变量变化的关系
四、方差分析
检验两组以上总体均数是否相等(两组-》T检验)
通过比较不同变异来源的均方和误差均方,判断各样本所属总体方差是否相等
基本思想
通过分析研究不同来源的变异对总变异的贡献大小,从而确定可控因素对研究结果影响力的大小。
分类
单因素方差分析(水平>=3)【实例:3个不同电池生产企业】、
多因素方差分析、
协方差分析:对非研究影响因素的分析【与偏变量相关类似】、
多元方差分析、重复测量方差分析等
五、主成分分析
1.主成分分析
是利用降维的思想,
将多个互相关联的数值变量转化为少数几个综合指标的统计方法,
综合指标就是多个变量的主成分,是原始变量的线性组合。
主成分个数确定方法:
1、累计贡献率:70%以上;
2、特征根不小于1
2.因子分析
一种用来在众多变量中辨别、分析和归结出变量间的相互关系,并用简单的变量(因子)来描述这种关系的数据分析方法
多个观测变量--》少数几个不相关的综合指标
3.区别与联系
①都从原始变量中通过它们实际内部相关性来获取新变量;
②因子分析的公因子比主成分分析的主成分更有解释性
③实质:主成分:线性变换,无假设检验;因子:统计模型,可假设检验
④SPSS操作:主成分:不用旋转;因子:需要旋转
六、时间序列分析
系统中某一变量的观测值按时间顺序排列成一个数值序列,展示研究对象在一定时间内的变动过程。
特点:
趋势性、平稳性、季节性

指数平滑法:与前一期指数平滑值加权平均
ARIMA模型:允许变动
七、聚类与判别
1.区别
共同点:都是研究样品或者变量进行分类
聚类:
分析事先并不知道研究对象的类别,它根据研究对象本身提供的信息,通过统计手段做出分类决策,有一定的探索性
判别:
事先已知研究对象的类别,根据有关类别的信息建立判别函数,再利用判别函数判断位置类别个体属于何种类别
2.聚类算法
(1)K-Means(非监督学习)


计算距离(点到质心)的方法:
①欧几里得距离:

②余弦相似度:

(2)层次算法
将每条数据都当做是一个分类,每次迭代的时候合并距离最近的两个分类,直到剩下一个分类为止
Ø误差平方和SSE:
执行聚类分析后,对每个点都要计算一个误差值,即非质心点到最近的质心的距离。将这些距离值相加求和,作为SSE去评估一个聚类的质量
Ø离群值的影响:
要么单独一类,要么在分析前剔除掉
ØANOVA在聚类分析中的作用:
判断用于聚类的变量是否对于聚类结果有贡献,方差分析检验结果越显著的变量,说明对聚类结果越有影响。对于不显著的变量,可以考虑从模型中剔除。(与单因素方差联系,方差分析,剔除不显著变量)
3.判别

八、神经网络
模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
梯度下降法

α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离
感知机
感知机就是一个将两类物体分开的超平面。

反向传播算法--BP算法
一场以误差(Error)为主导的反向传播(Back Propagation)运动,旨在得到最优的全局参数矩阵,进而将多层神经网络应用到分类或者回归任务中去
(猜数字游戏)
流程:




九、基本数理知识
自由度:
计算某一统计量时,取值不受限制的变量个数
二项分布:
重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变。
秩:
基于样本值的大小在全体样本中所占的位次的统计量,如将样本混合排序后,就可以得到每个数据在这个数据的位置,若数据在总体数据上的位置相同,称之为结。
残差:
指实际观察值与估计值(拟合值)之间的差,回归残差是真实误差的估计;
众数:
出现次数最多的那个数,众数可能不止一个数
泊松分布:
适合于描述单位时间(或空间)内随机事件发生的次数
差分:
差分反映了离散量中的一种变化,比如一阶差分,就是指当自变量从x变到x+1时,函数y的改变量y(x+1)-y(x),称为函数在点x的一阶差分。
协方差
衡量两个变量在变化过程中是同向变化还是反向变化,以及变化程度如何
协方差为正:说明X,Y同向变化,协方差越大说明同向程度越高;
协方差为负:说明X,Y反向运动,协方差越小说明反向程度越高