文章目录
- 一、先了解用户获取网络数据的方式
- 二、简单了解网页源代码的组成
-
- 1、web基本的编程语言
- 2、使用浏览器查看网页源代码
- 三、爬虫概述
-
- 1、认识爬虫
- 2、python爬虫
- 3、爬虫分类
- 4、爬虫应用
- 5、爬虫是一把双刃剑
- 6、python爬虫教程
- 7、编写爬虫的流程
- 四、python爬虫实践 - 获取博客浏览量
前言:python爬虫简单概括其实就是获取网页数据,然后按需提取!流程虽然简单,但实现起来需要结合多种技术,熟练掌握爬虫库才能编写出高效的爬虫代码
一、先了解用户获取网络数据的方式
1、用户使用浏览器:浏览器提交请求—>下载网页代码—>解析成页面
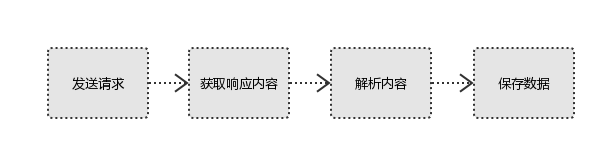
2、代码自动获取:模拟浏览器发送请求(获取网页代码html、css、javascript)->提取有用的数据->存放于数据库或文件中
python爬虫 便是使用代码自动获取,具体流程为:
二、简单了解网页源代码的组成
1、web基本的编程语言
简单了解可以上菜鸟教程
1)HTML、CSS、JavaScript 是 web 开发人员必须学习的 3 门语言,他们互相配合构成各类丰富的网站
(1)HTML 定义了网页的内容
(2)CSS 描述了网页的布局
(3)JavaScript 控制了网页的行为
2)html5简单例子

3)javaScript在html里

4)CSS在html里

2、使用浏览器查看网页源代码
1)网页右击查看源代码(也就是我们要获取的内容)

2)html代码,这里要求我们能稍微读懂其组成,然后根据内容来提取

三、爬虫概述
1、认识爬虫
我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做 Sogouspider。
2、python爬虫
百度搜索引擎,其实可以更形象地称之为百度蜘蛛(Baiduspider),它每天会在海量的互联网信息中爬取优质的信息,并进行收录。当用户通过百度检索关键词时,百度首先会对用户输入的关键词进行分析,然后从收录的网页中找出相关的网页,并按照排名规则对网页进行排序,最后将排序后的结果呈现给用户。在这个过程中百度蜘蛛起到了非常想关键的作用。
百度的工程师们为“百度蜘蛛”编写了相应的爬虫算法,通过应用这些算法使得“百度蜘蛛”可以实现相应搜索策略,比如筛除重复网页、筛选优质网页等等。应用不同的算法,爬虫的运行效率,以及爬取结果都会有所差异。
3、爬虫分类
爬虫可分为三大类:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫。
1)通用网络爬虫:是搜索引擎的重要组成部分,上面已经进行了介绍,这里就不再赘述。通用网络爬虫需要遵守 robots 协议,网站通过此协议告诉搜索引擎哪些页面可以抓取,哪些页面不允许抓取。
robots 协议:是一种“约定俗称”的协议,并不具备法律效力,它体现了互联网人的“契约精神”。行业从业者会自觉遵守该协议,因此它又被称为“君子协议”。
2)聚焦网络爬虫:是面向特定需求的一种网络爬虫程序。它与通用爬虫的区别在于,聚焦爬虫在实施网页抓取的时候会对网页内容进行筛选和处理,尽量保证只抓取与需求相关的网页信息。聚焦网络爬虫极大地节省了硬件和网络资源,由于保存的页面数量少所以更新速度很快,这也很好地满足一些特定人群对特定领域信息的需求。
3)增量式网络爬虫:是指对已下载网页采取增量式更新,它是一种只爬取新产生的或者已经发生变化网页的爬虫程序,能够在一定程度上保证所爬取的页面是最新的页面。
4、爬虫应用
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战,因此爬虫应运而生,它不仅能够被使用在搜索引擎领域,而且在大数据分析,以及商业领域都得到了大规模的应用。
1) 数据分析
在数据分析领域,网络爬虫通常是搜集海量数据的必备工具。对于数据分析师而言,要进行数据分析,首先要有数据源,而学习爬虫,就可以获取更多的数据源。在采集过程中,数据分析师可以按照自己目的去采集更有价值的数据,而过滤掉那些无效的数据。
2) 商业领域
对于企业而言,及时地获取市场动态、产品信息至关重要。企业可以通过第三方平台购买数据,比如贵阳大数据交易所、数据堂等,当然如果贵公司有一个爬虫工程师的话,就可通过爬虫的方式取得想要的信息。
5、爬虫是一把双刃剑
爬虫是一把双刃剑,它给我们带来便利的同时,也给网络安全带来了隐患。有些不法分子利用爬虫在网络上非法搜集网民信息,或者利用爬虫恶意攻击他人网站,从而导致网站瘫痪的严重后果。关于爬虫的如何合法使用,推荐阅读《中华人民共和国网络安全法》。
6、python爬虫教程
为了限制爬虫带来的危险,大多数网站都有良好的反爬措施,因此大家在使用爬虫的时候,要自觉遵守协议,不要非法获取他人信息,或者做一些危害他人网站的事情。
为什么用Python做爬虫
首先您应该明确,不止 Python 这一种语言可以做爬虫,诸如 PHP、Java、C/C++ 都可以用来写爬虫程序,但是相比较而言 Python 做爬虫是最简单的。下面对它们的优劣势做简单对比:
PHP:对多线程、异步支持不是很好,并发处理能力较弱;Java 也经常用来写爬虫程序,但是 Java 语言本身很笨重,代码量很大,因此它对于初学者而言,入门的门槛较高;C/C++ 运行效率虽然很高,但是学习和开发成本高。写一个小型的爬虫程序就可能花费很长的时间。
而 Python 语言,其语法优美、代码简洁、开发效率高、支持多个爬虫模块,比如 urllib、requests、Bs4 等。Python 的请求模块和解析模块丰富成熟,并且还提供了强大的 Scrapy 框架,让编写爬虫程序变得更为简单。因此使用 Python 编写爬虫程序是个非常不错的选择。
7、编写爬虫的流程
爬虫程序与其他程序不同,它的的思维逻辑一般都是相似的, 所以无需我们在逻辑方面花费大量的时间。下面对 Python 编写爬虫程序的流程做简单地说明:
先由 urllib 模块的 request 方法打开 URL 得到网页 HTML 对象。
使用浏览器打开网页源代码分析网页结构以及元素节点。
通过 Beautiful Soup 或则正则表达式提取数据。
存储数据到本地磁盘或数据库。
当然也不局限于上述一种流程。编写爬虫程序,需要您具备较好的 Python 编程功底,这样在编写的过程中您才会得心应手。爬虫程序需要尽量伪装成人访问网站的样子,而非机器访问,否则就会被网站的反爬策略限制,甚至直接封杀 IP。
四、python爬虫实践 - 获取博客浏览量
不废话,上代码
import re
import requests
from requests import RequestException
import urllib.request
url = "https://blog.csdn.net/STCNXPARM/article/details/122297801"
def get_page(url):
try:
#请求头部,如果不加头部,则会被反爬虫网站识别出是爬虫,会导致获取不到数据
headers = {
'Referer': 'https://blog.csdn.net', # 伪装成从CSDN博客搜索到的文章
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' # 伪装成浏览器
}
#获取网页源代码数据
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求出错')
return None
def parse_page(html):
try:
#使用正则匹配html代码中浏览量字段
read_num = int(re.compile('<span.*?read-count.*?(\d+).*?</span>').search(html).group(1))
#返回浏览量
return read_num
except Exception:
print('解析出错')
return None
def main():
try:
html = get_page(url)
if html:
read_num = parse_page(html)
if read_num:
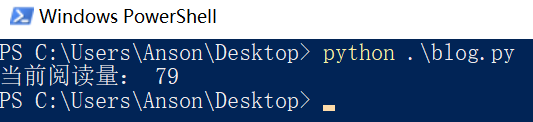
print('当前阅读量:', read_num)
except Exception:
print('出错啦!')
if __name__ == '__main__':
main()
运行结果:
如果是初学python爬虫,觉得自学比较难的,那么我接下来分享的这全套 Python 学习资料一定不要错过,希望能给那些想学习 Python 的小伙伴们带来帮助!
python学习路线

环境搭建
使用 Python 首先需要搭建 Python 环境,我们直接到 Python 官网 下载自己对应平台和版本的安装包进行安装即可
python开发工具
俗话说:工欲善其事,必先利其器,Python 的学习也是一样,新手建议首选 PyCharm,可以快速上手,减少配置时间。

学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。
全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、清华编程大佬出品《漫画看学Python》
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。

配套600集视频:

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接点击CSDN官方认证二维码免费领取【保证100%免费】。