学习目标
-
能够知道Web开发流程
-
能够掌握FastAPI实现访问多个指定网页
-
知道通过requests模块爬取图片
-
知道通过requests模块爬取GDP数据
-
能够用pyecharts实现饼图
-
能够知道logging日志的使用
一、基于FastAPI之Web站点开发
FastAPI是一个高性能、易于使用、快速编写API的现代Web框架。它基于Python3.6+的新特性(如类型标注、异步支持、协程等),对性能和开发速度进行了优化,支持异步编程,可以轻松地创建具有高性能的API服务。
FastAPI的主要特点包括:
1. 快速:FastAPI的请求响应速度非常快,相比其他框架甚至能快几倍。
2. 易于使用:FastAPI的API设计类似于Flask,提供了简单易用的路由和参数解析。同时,它的类型标注功能使开发更加可靠,易于维护。
3. 异步支持:FastAPI完全支持异步编程模式,利用Python 3.6以上版本的async/await关键字,使得复杂的I/O操作变得非常简单。
4. 自动生成API文档:FastAPI基于OpenAPI标准,自动生成并提供了优美的API文档,无需手动编写文档。
5. 安全性:FastAPI完全支持OpenID Connect 和OAuth2规范,提供安全的认证方式,同时支持JWT和Bearer Token。
1、基于FastAPI搭建Web服务器
搭建基于FastAPI的Web服务器的具体步骤如下:
-
安装FastAPI和uvicorn:
pip install fastapi
pip install uvicorn
-
创建一个Python文件,例如main.py,并导入必要的模块:
from fastapi import FastAPI
-
创建一个FastAPI应用实例:
app = FastAPI()
-
定义一个路由处理函数,用于处理HTTP请求:
@app.get("/")
def read_root():
return {"Hello": "World"}
-
启动Web服务器:
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
-
在命令行中运行Python文件,启动Web服务器:
python main.py
-
访问http://localhost:8000/,应该能够看到返回的JSON数据{"Hello": "World"}。
以上就是使用FastAPI搭建Web服务器的基本步骤。你可以根据需要添加更多的路由处理函数和业务逻辑。 接下来我们来看一个具体的例子:
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index.html")
def main():
with open("source/html/index.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
2、Web服务器和浏览器的通讯流程
实际上Web服务器和浏览器的通讯流程过程并不是一次性完成的, 这里html代码中也会有访问服务器的代码,比如请求图片资源。 Web服务器和浏览器的通讯流程一般如下:
-
浏览器向Web服务器发送HTTP请求。
-
Web服务器接收到请求后,根据请求的内容生成相应的HTTP响应。
-
Web服务器将HTTP响应返回给浏览器。
-
浏览器接收到HTTP响应后,解析响应内容并渲染页面。
-
如果页面中包含其他资源(如图片、CSS、JavaScript等),浏览器会再次向Web服务器发送请求获取这些资源,并重复上述流程。
在这个过程中,HTTP协议是Web服务器和浏览器通信的基础。 我们来看一个具体的例子:

那像0.jpg、1.jpg、2.jpg、3.jpg、4.jpg、5.jpg、6.jpg这些访问来自哪里呢 ?
答:它们来自index.html
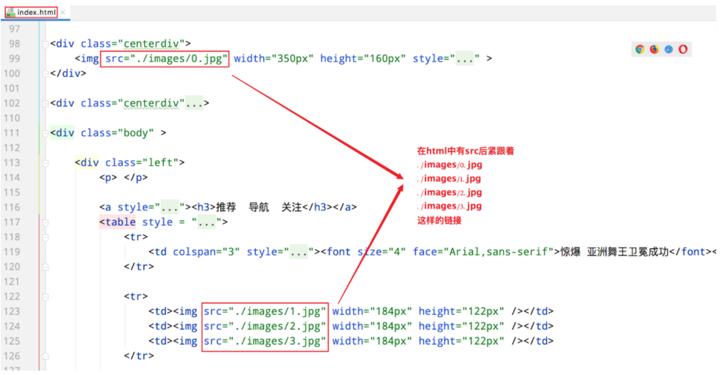
3、浏览器访问Web服务器的通讯流程

浏览器访问Web服务器的通讯流程:
-
浏览器 (127.0.0.1/index.html) ==> 向Web服务器请求index.html
-
Web服务器 (返回index.html) ==> 浏览器
-
浏览器解析index.html发现需要0.jpg ==>发送请求给 Web服务器请求0.jpg
-
Web服务器 收到请求返回0.jpg ==> 浏览器 接受0.jpg
通讯过程能够成功的前提: 浏览器发送的0.jpg请求, Web服务器可以做出响应, 也就是代码如下
# 当浏览器发出对图片 0.jpg 的请求时, 函数返回相应资源
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
print(data)
return Response(content=data, media_type="jpg")
4、加载图片资源代码
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
print(data)
return Response(content=data, media_type="jpg")
@app.get("/images/1.jpg")
def func_02():
with open("source/images/1.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/2.jpg")
def func_03():
with open("source/images/2.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/3.jpg")
def func_04():
with open("source/images/3.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/4.jpg")
def func_05():
with open("source/images/4.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/5.jpg")
def func_06():
with open("source/images/5.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/6.jpg")
def func_07():
with open("source/images/6.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/gdp.html")
def func_08():
with open("source/html/gdp.html") as f:
data = f.read()
return Response(content=data, media_type="text/source")
@app.get("/index.html")
def main():
with open("source/html/index.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/source"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
这段代码是一个使用FastAPI框架创建的简单Web服务器。下面是代码的解释:
-
首先,导入所需的模块:
-
FastAPI模块用于创建Web应用程序。
-
Response模块用于构建HTTP响应。
-
uvicorn模块用于运行服务器。
-
创建FastAPI的实例对象 app。
-
定义了多个路由处理函数,每个函数对应一个URL路径。每一个函数中,它们会打开并读取指定的图片文件或HTML文件。
-
当访问 /images/0.jpg 路径时,执行 func_01() 函数。该函数打开名为 0.jpg 的图片文件,读取文件的内容,并返回一个含有图片内容的HTTP响应。
-
同样的方式定义了 /images/1.jpg 至 /images/6.jpg 路径对应的函数。
-
当访问 /gdp.html 路径时,执行 func_08() 函数。该函数打开名为 gdp.html 的HTML文件,读取文件的内容,并返回一个含有HTML内容的HTTP响应。
-
当访问 /index.html 路径时,执行 main() 函数。该函数打开名为 index.html 的HTML文件,读取文件的内容,并返回一个含有HTML内容的HTTP响应。
-
最后,使用 uvicorn.run() 方法运行服务器,监听IP地址 127.0.0.1 上的端口号 8000。
5、小结
-
浏览器访问Web服务器的通讯流程:
-
浏览器 (127.0.0.1/index.html) ==> 向Web服务器请求index.html
-
Web服务器 (返回index.html) ==> 浏览器
-
浏览器解析index.html发现需要0.jpg ==>发送请求给 Web服务器请求0.jpg
-
Web服务器 收到请求返回0.jpg ==> 浏览器 接受0.jpg
二、基于Web请求的FastAPI通用配置
1、目前Web服务器存在问题
# 返回0.jpg
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
print(data)
return Response(content=data, media_type="jpg")
# 返回1.jpg
@app.get("/images/1.jpg")
def func_02():
with open("source/images/1.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
# 返回2.jpg
@app.get("/images/2.jpg")
def func_03():
with open("source/images/2.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
这段代码是一个使用Python的FastAPI框架编写的Web应用程序。它创建了三个路由(或称为端点),分别用于返回不同的图片文件。 通过@app.get装饰器,每个函数定义了一个路由,指定了路由的URL路径,以及当请求该路径时执行的函数。
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
这个函数定义了一个路由/images/0.jpg,当访问此路径时会执行func_01函数。该函数打开并读取名为source/images/0.jpg的文件,并将读取的数据赋值给变量data。然后,函数返回一个Response对象,其中包含data作为内容,并指定媒体类型为jpg。
类似地,func_02函数定义了另一个路由/images/1.jpg,用于返回名为source/images/1.jpg的文件。 最后,func_03函数定义了一个路由/images/2.jpg,用于返回名为source/images/2.jpg的文件。 这些函数使用了with open语句来打开文件并读取其内容。打开文件时使用了"rb"模式(以二进制模式打开文件),表示这是一个二进制文件(比如图片),而不是文本文件。
这些函数返回的Response对象指定了响应的内容和媒体类型,以便客户端能够正确解析和处理返回的图像数据。
对以上代码观察,会发现每一张图片0.jpg、1.jpg、2.jpg就需要一个函数对应, 如果我们需要1000张图片那就需要1000个函数对应, 显然这样做代码的重复太多了.
2、基于Web请求的FastAPI通用配置
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):
# 这里open()的路径就是 ==> f"source/images/0.jpg"
with open(f"source/images/{path}", "rb") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="jpg")
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="jpg")
完整代码:
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):
# 这里open()的路径就是 ==> f"source/images/0.jpg"
with open(f"source/images/{path}", "rb") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="jpg")
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="jpg")
@app.get("/{path}")
def get_html(path: str):
with open(f"source/html/{path}", 'rb') as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/source"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
这段代码使用了Python的FastAPI框架来创建一个简单的Web服务器。以下是代码的解释:
-
导入必要的模块:代码首先导入了FastAPI框架模块,用于创建Web应用程序。然后导入了Response模块,用于返回HTTP响应报文。最后导入了uvicorn模块,用于运行Web服务器。
-
创建FastAPI应用程序对象:使用app = FastAPI()创建了FastAPI框架的应用程序对象。
-
定义路由和处理函数:
-
/images/{path}路由匹配请求路径为/images/0.jpg。path参数表示请求中的文件路径。
-
get_pic函数是处理/images/{path}路由的处理函数。它从指定路径读取图片文件的内容,并将其作为二进制数据返回给客户端。使用Response(content=data, media_type="jpg")创建了一个Response对象,将图片数据作为响应数据返回给客户端。
-
/{path}路由匹配其他所有请求路径。path参数表示请求中的文件路径。
-
get_html函数是处理/{path}路由的处理函数。它从指定路径读取HTML文件的内容,并将其作为二进制数据返回给客户端。使用Response(content=data, media_type="text/html")创建了一个Response对象,将HTML数据作为响应数据返回给客户端。
4.运行Web服务器:使用uvicorn.run(app, host="127.0.0.1", port=8000)运行Web服务器,监听127.0.0.1:8000地址。这将启动一个HTTP服务器,接受客户端请求,并根据定义的路由和处理函数进行响应。
运行结果:

3、小结
通用配置代码:
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):
# 这里open()的路径就是 ==> f"source/images/0.jpg"
with open(f"source/images/{path}", "rb") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="jpg")
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="jpg")
这段代码是一个基于FastAPI框架的HTTP服务端代码。该代码中定义了一个GET请求处理函数get_pic,用于处理请求路径为/images/{path}的请求。
当接收到一个请求时,FastAPI会将请求路径中的{path}部分作为参数传递给get_pic函数。在函数内部,该参数被声明为path: str,表示path是一个字符串类型的数据。
函数内部使用open()函数打开了一个文件,文件路径为source/images/{path},其中{path}是请求路径中的具体值。然后使用rb模式读取文件内容,并将内容赋值给变量data。
最后,使用Response类创建一个响应对象,并将文件内容作为响应数据,数据格式为jpg。最终返回该响应对象作为HTTP响应。
三、Python爬虫介绍
1、什么是爬虫

网络爬虫:
又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取网络信息的程序或者脚本,另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
通俗理解:
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来. 就像一只虫子在一幢楼里不知疲倦地爬来爬去.
你可以简单地想象:
每个爬虫都是你的「分身」。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样

百度:其实就是利用了这种爬虫技术, 每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。 有了这样的特性, 对于一些自己公司数据量不足的小公司, 这个时候还想做数据分析就可以通过爬虫获取同行业的数据然后进行分析, 进而指导公司的策略指定。
2、爬虫的基本步骤
基本步骤:
-
起始URL地址
-
发出请求获取响应数据
-
对响应数据解析
-
数据入库
3、安装requests模块
-
requests : 可以模拟浏览器的请求
-
官方文档 :http://cn.python-requests.org/zh_CN/latest/
-
安装 :pip install requests
快速入门(requests三步走):
# 导入模块
import requests
# 通过requests.get()发送请求
# data保存返回的响应数据(这里的响应数据不是单纯的html,需要通过content获取html代码)
data = requests.get("http://www.baidu.com")
# 通过data.content获取html代码
data = data.content.decode("utf-8")
4、小结
requests三步走:
# 导入模块
import requests
# 通过requests.get()发送请求
# data保存返回的响应数据(这里的响应数据不是单纯的html,需要通过content获取html代码)
data = requests.get("http://www.baidu.com")
# 通过data.content获取html代码
data = data.content.decode("utf-8")
5、爬取照片
☆ 查看index.html
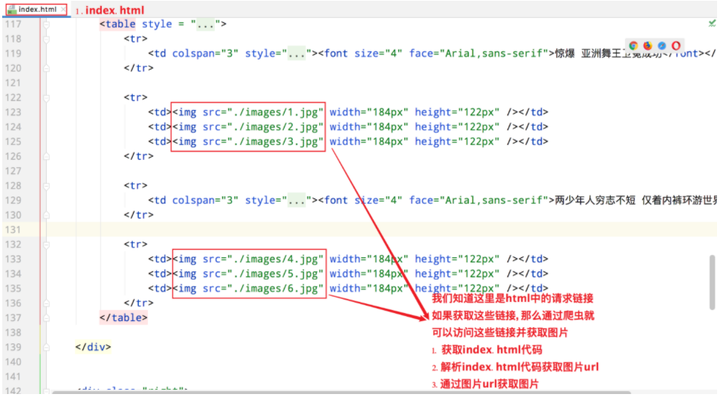
☆ 爬取照片的步骤
-
获取index.html代码
-
解析index.html代码获取图片url
-
通过图片url获取图片
☆ 获取index.html代码
# 通过爬虫向index.html发送请求
# requests.get(网址): 向一个网址发送请求,和在浏览器中输入网址是一样的
data = requests.get("http://127.0.0.1:8000/index.html")
# content可以把requests.get()获取的返回值中的html内容获取到
data = data.content.decode("utf-8")
☆ 解析index.html代码获取图片url
# 获取图片的请求url
def get_pic_url():
# 通过爬虫向index.html发送请求
# requests.get(网址): 向一个网址发送请求,和在浏览器中输入网址是一样的
data = requests.get("http://127.0.0.1:8000/index.html")
# content可以把requests.get()获取的返回值中的html内容获取到
data = data.content.decode("utf-8")
# html每一行都有"\n", 对html进行分割获得一个列表
data = data.split("\n")
# 创建一个列表存储所有图片的url地址(也就是图片网址)
url_list = []
for url in data:
# 通过正则解析出所有的图片url
result = re.match('.*src="(.*)" width.*', url)
if result is not None:
# 把解析出来的图片url添加到url_list中
url_list.append(result.group(1))
return url_list
这段代码是一个函数,用于获取图片的请求URL。具体的流程如下:
1. 使用爬虫向"http://127.0.0.1:8000/index.html"发送请求,获取网页内容。
2. 将获取到的网页内容进行解码,使用utf-8编码格式。
3. 将解码后的内容按行分割,得到一个列表,每个元素是网页的一行内容。 4. 创建一个空列表url_list,用于存储所有图片的URL地址。
5. 遍历每一行的内容,使用正则表达式解析出所有的图片URL。
6. 如果解析结果不为空,将解析出来的图片URL添加到url_list中。
7. 最后返回url_list,即所有图片的URL地址。
☆ 通过图片url获取图片
# 把爬取到的图片保存到本地
def save_pic(url_list):
# 通过num给照片起名字 例如:0.jpg 1.jpg 2.jpg
num = 0
for url in url_list:
# 通过requests.get()获取每一张图片
pic = requests.get(f"http://127.0.0.1:8000{url[1:]}")
# 保存每一张图片
with open(f"./source/spyder/{num}.jpg", "wb") as f:
f.write(pic.content)
num += 1
这段代码是一个函数,用于将爬取到的图片保存到本地。
首先,函数接受一个参数url_list,该参数是一个包含图片url的列表。
然后,通过一个循环遍历url_list中的每一个url。 在循环内部,使用requests.get()方法获取每一张图片。这个方法发送一个HTTP GET请求到指定的url,并返回一个Response对象。
接下来,使用open()函数打开一个文件,文件路径为"./source/spyder/{num}.jpg",其中num是一个递增的数字,用于给每张图片起一个唯一的名字。
然后,使用文件对象的write()方法将图片内容写入到文件中。pic.content是获取到的图片内容。
最后,关闭文件,num递增,继续处理下一张图片,直到遍历完所有的url_list中的url。 完整代码:
import requests
import re
# 获取图片的请求url
def get_pic_url():
# 通过爬虫向index.html发送请求
# requests.get(网址): 向一个网址发送请求,和在浏览器中输入网址是一样的
data = requests.get("http://127.0.0.1:8000/index.html")
# content可以把requests.get()获取的返回值中的html内容获取到
data = data.content.decode("utf8")
# html每一行都有"\n", 对html进行分割获得一个列表
data = data.split("\n")
# 创建一个列表存储所有图片的url地址(也就是图片网址)
url_list = []
for url in data:
# 通过正则解析出所有的图片url
result = re.match('.*src="(.*)" width.*', url)
if result is not None:
# 把解析出来的图片url添加到url_list中
url_list.append(result.group(1))
return url_list
# 把爬取到的图片保存到本地
def save_pic(url_list):
# 通过num给照片起名字 例如:0.jpg 1.jpg 2.jpg
num = 0
for url in url_list:
# 通过requests.get()获取每一张图片
pic = requests.get(f"http://127.0.0.1:8000{url[1:]}")
# 保存每一张图片
with open(f"./source/spyder/{num}.jpg", "wb") as f:
f.write(pic.content)
num += 1
if __name__ == '__main__':
url_list = get_pic_url()
save_pic(url_list)
详细解释一下代码,这段代码实现了以下功能:
-
导入了requests和re模块。
-
定义了一个函数get_pic_url(),用于获取图片的请求url。
-
首先,通过使用requests.get()方法向"http://127.0.0.1:8000/index.html"发送请求,获取网页的内容。
-
然后,使用content.decode("utf8")将获取到的内容解码为字符串。
-
接着,使用split("\n")将字符串按行分割成一个列表。
-
创建一个空列表url_list,用于存储图片的url地址。
-
遍历列表data中的每个元素,使用正则表达式匹配出所有的图片url,并将其添加到url_list中。
-
返回url_list。
-
定义了一个函数save_pic(url_list),用于将爬取到的图片保存到本地。
-
初始化一个变量num为0,用于给照片起名字。
-
遍历url_list中的每个url。
-
使用requests.get()方法获取每张图片的内容。
-
使用open()方法打开一个文件,将图片内容写入文件中,文件名为"./source/spyder/{num}.jpg",并递增num。
-
在主程序中,首先调用get_pic_url()函数获取图片的url列表,然后调用save_pic(url_list)函数将图片保存到本地。
☆ 小结
-
爬取照片的步骤
-
获取index.html代码
-
解析index.html代码获取图片url
-
通过图片url获取图片
四、使用Python爬取GDP数据
1、gdp.html

通过访问 http://127.0.0.1:8080/gdp.html 可以获取2020年世界GDP排名. 在这里我们通过和爬取照片一样的流程步骤获取GDP数据。
2、zip函数的使用
zip() 函数: 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表. zip()函数是Python内置的一个函数,用于将多个可迭代对象打包成一个元组的列表。 zip()函数的语法如下:
zip(*iterables)
其中,iterables是一个或多个可迭代对象,可以是列表、元组、字符串或其他可迭代对象。 zip()函数的工作原理是,它会从每个可迭代对象中依次取出一个元素,然后将这些元素打包成一个元组,再将这个元组添加到结果列表中。当其中任何一个可迭代对象取尽元素时,zip()函数就会停止打包。 下面是一个简单的示例,展示了zip()函数的使用:
numbers = [1, 2, 3]
letters = ['a', 'b', 'c']
zipped = zip(numbers, letters)
# 打印结果
for item in zipped:
print(item)
输出结果:
(1, 'a')
(2, 'b')
(3, 'c')
在这个示例中,zip()函数将numbers和letters两个可迭代对象打包成了一个元组的列表。每个元组由numbers和letters中对应位置的元素组成。 需要注意的是,如果传入的可迭代对象的长度不一致,zip()函数会以最短的可迭代对象为准进行打包。如果需要以最长的可迭代对象为准进行打包,可以使用itertools.zip_longest()函数。 zip()函数在实际应用中常用于同时迭代多个可迭代对象,特别是在需要将它们的对应位置的元素进行处理或组合时非常有用。 下面是另外一个例子:
a = [1, 2, 3]
b = [4, 5, 6]
c = [4, 5, 6, 7, 8]
# 打包为元组的列表
zipped = zip(a, b)
# 注意使用的时候需要list转化
print(list(zipped))
>>> [(1, 4), (2, 5), (3, 6)]
# 元素个数与最短的列表一致
zipped = zip(a, c)
# 注意使用的时候需要list转化
print(list(zipped))
>>> [(1, 4), (2, 5), (3, 6)]
3、爬取GDP数据
import requests
import re
# 存储爬取到的国家的名字
country_list = []
# 存储爬取到的国家gdp的数据
gdp_list = []
# 获取gdp数据
def get_gdp_data():
global country_list
global gdp_list
# 获取gdp的html数据
data = requests.get("http://localhost:8000/gdp.html")
# 对获取数据进行解码
data = data.content.decode("utf8")
# 对gdp的html数据进行按行分割
data_list = data.split("\n")
for i in data_list:
# 对html进行解析获取<国家名字>
country_result = re.match('.*<a href=""><font>(.*)</font></a>', i)
# 匹配成功就存放到列表中
if country_result is not None:
country_list.append(country_result.group(1))
# 对html进行解析获取<gdp数据>
gdp_result = re.match(".*¥(.*)亿元", i)
# 匹配成功就存储到列表中
if gdp_result is not None:
gdp_list.append(gdp_result.group(1))
# 把两个列表融合成一个列表
gdp_data = list(zip(country_list, gdp_list))
print(gdp_data)
if __name__ == '__main__':
get_gdp_data()
这段代码的功能是爬取一个网页上的国家名字和GDP数据。具体的实现过程如下:
-
导入requests和re模块。
-
创建两个空列表country_list和gdp_list,用于存储爬取到的国家名字和GDP数据。
-
定义一个函数get_gdp_data(),用于获取GDP数据。
-
在函数中,首先使用requests.get()函数获取网页的HTML数据,并将其解码为utf8格式。
-
将获取到的HTML数据按行分割,得到一个列表data_list。
-
遍历data_list列表,对每一行的HTML数据进行解析。
-
使用re.match()函数对每一行的HTML数据进行匹配,以获取国家名字和GDP数据。
-
如果匹配成功,将国家名字存放到country_list列表中,将GDP数据存放到gdp_list列表中。
-
将country_list和gdp_list两个列表融合成一个列表gdp_data。
-
最后,打印出gdp_data列表。
-
在主程序中,调用get_gdp_data()函数来执行爬取操作。
4、小结
-
爬取gdp的步骤
-
获取gdp.html代码
-
解析gdp.html代码获取gdp数据