
近期,英伟达披露H200规格来看,H200 基本上看起来像 GH200 的 Hopper 一半作为自己的加速器。当然,这里最大的区别是将 HBM3 换成 HBM3E,这使得 NVIDIA 能够提高内存带宽和容量——以及 NVIDIA 启用了第 6 个 HBM 内存堆栈,这在最初的 H100 中被禁用。这将使 H200 的内存容量从 80GB 增加到 141GB,内存带宽从 3.35TB/秒增加到 NVIDIA 初步预期的 4.8TB/秒——带宽增加约 43%。

根据总带宽和内存总线宽度,这表明 H200 的内存将以大约 6.5Gbps/引脚的速度运行,与原始 H100 的 5.3Gbps/引脚 HBM3 内存相比,频率提高了约 25%。H200 还将保留 GH200 不寻常的 141GB 内存容量。HBM3E 内存本身的物理容量为 144GB——以六个 24GB 堆栈的形式出现——但 NVIDIA 出于产量原因保留了部分容量。因此,客户无法访问板载的所有 144GB,但与 H100 相比,他们可以访问所有六个堆栈,并具有容量和内存带宽优势。
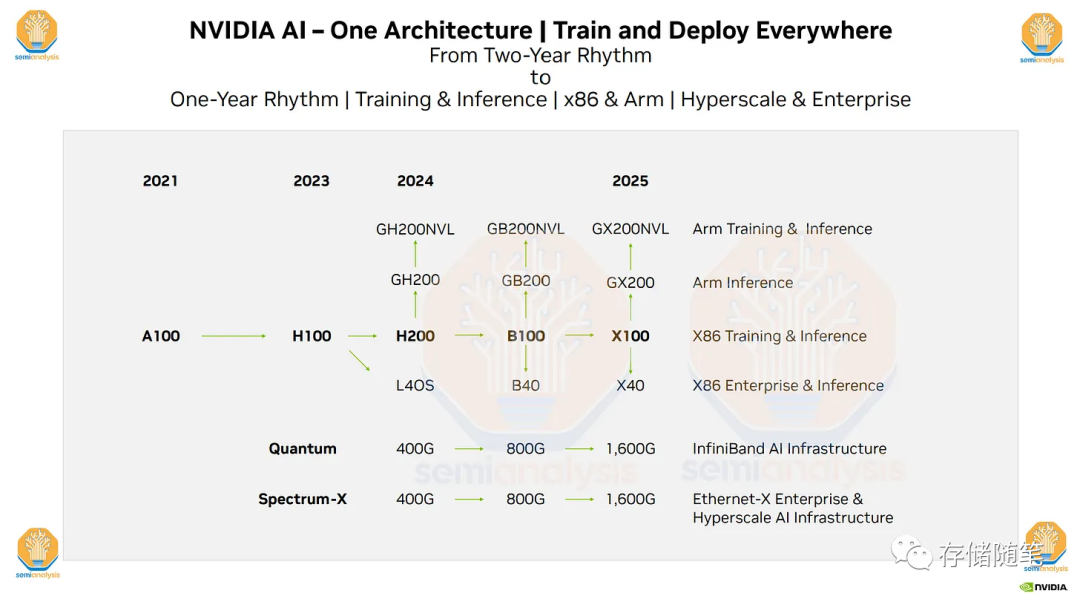
特别是他们未来几年的硬件路线图,包括即将推出的H200、B100和“X100”GPU。Nvidia每年更新AI GPU的举动非常重要,并带来了许多影响。Nvidia的过程技术计划、HBM3E速度/容量、PCIe 6.0、PCIe 7.0以及他们非常雄心勃勃的NVLink和1.6T 224G SerDes计划。如果这个计划成功,Nvidia将超越所有人。
高带宽存储器(High Bandwidth Memory,HBM)是一种基于3D堆栈工艺的高性能DRAM,由超微半导体和SK Hynix发起。这种存储器适用于高存储器带宽需求的应用场合,如图形处理器、网络交换及转发设备(如路由器、交换器)等。
HBM利用3D堆栈工艺,将多个存储芯片垂直堆叠在一起,以实现更高的存储容量和更快的存储带宽。这种设计使得HBM能够提供比传统DRAM更高的数据传输速率。
具体来说,HBM通过在垂直方向上堆叠多个DRAM芯片,将它们的接口和控制器结合在一起。这样,每个DRAM芯片都可以作为一个独立的存储单元,同时也可以与其他芯片共享数据。这种设计使得HBM能够实现更高的数据传输速率和更大的存储容量。
由于HBM具有高带宽、大容量和低延迟等优点,因此它被广泛应用于需要高存储器带宽的应用场合,如高性能计算、数据中心、网络交换及转发设备等。在这些应用场合中,HBM可以提供比传统DRAM更高的数据传输速率和更大的存储容量,从而提高了系统的整体性能。
此外,HBM也被用于图形处理器中,以提供更高的图像渲染速度和更好的游戏体验。在人工智能和机器学习领域,HBM也被广泛应用于各种算法和模型的训练中,以提供更快的计算速度和更好的训练效果。

据TrendForce集邦咨询最新HBM市场研究显示,为了更妥善且健全的供应链管理,NVIDIA也规划加入更多的HBM供应商,其中三星(Samsung)的HBM3(24GB)预期于今年12月在NVIDIA完成验证。而HBM3e进度依据时间轴排列如下表所示,美光(Micron)已于今年7月底提供8hi(24GB)NVIDIA样品、SK海力士(SK hynix)已于今年8月中提供8hi(24GB)样品、三星则于今年10月初提供8hi(24GB)样品。
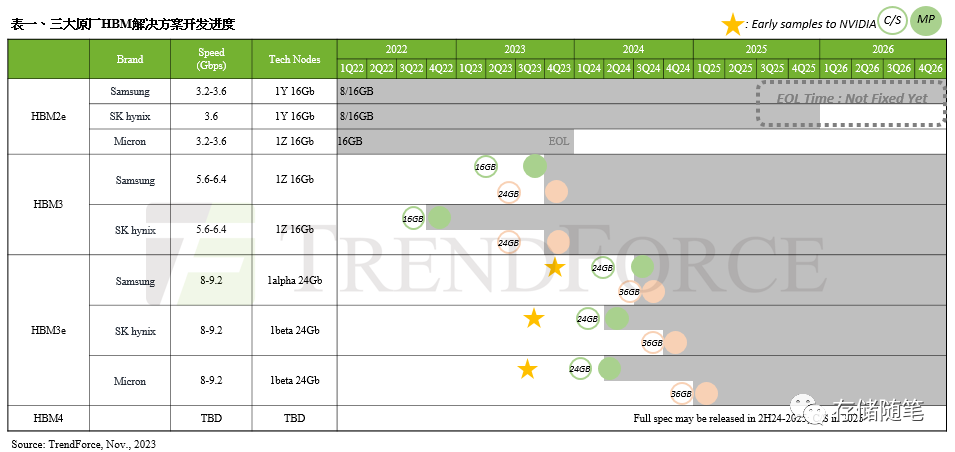
由于HBM验证过程繁琐,预计耗时两个季度,因此,TrendForce集邦咨询预期,最快在2023年底可望取得部分厂商的HBM3e验证结果,而三大原厂均预计于2024年第一季完成验证。值得注意的是,各原厂的HBM3e验证结果,也将决定最终NVIDIA 2024年在HBM供应商的采购权重分配,然目前验证皆尚未完成,因此2024年HBM整体采购量仍有待观察。