Docker安装
1、先卸载旧版(未安装可以忽略)
apt-get remove docker docker-engine docker.io containerd runc
2、安装依赖
apt update
apt-get install ca-certificates curl gnupg lsb-release
3、通过阿里的源安装证书
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
4、写入源信息。
add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
5、安装新版本
sudo apt-get install -y docker-ce
#或:apt-get install docker-ce docker-ce-cli containerd.io
6、启动docker
sudo systemctl start docker
7、运行hello word镜像查看docker是否安装成功
sudo docker run hello-world
搭建zookeeper集群
1、docker创建一个网络
docker network create kafka-net
2、拉取zookeeper镜像
docker pull zookeeper:3.5.9
3、使用dokcer compose 搭建zookeeper集群
mkdir -p /home/veteran/data/zookeeper
cd /home/veteran/data/zookeeper
touch zookeeper-compose.yml
sudo nano zookeeper-compose.yml # 插入下面的内容
version: '3'
services:
zoo1:
image: zookeeper:3.5.9
container_name: zoo1
restart: always
privileged: true
ports:
- 2182:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181zoo2:
image: zookeeper:3.5.9
container_name: zoo2
restart: always
privileged: true
ports:
- 2183:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181zoo3:
image: zookeeper:3.5.9
container_name: zoo3
restart: always
privileged: true
ports:
- 2184:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181networks:
default:
external: true
name: kafka-net
4、使用zookeeper-compose.yml文件
docker-compose -f zookeeper-compose.yml up -d
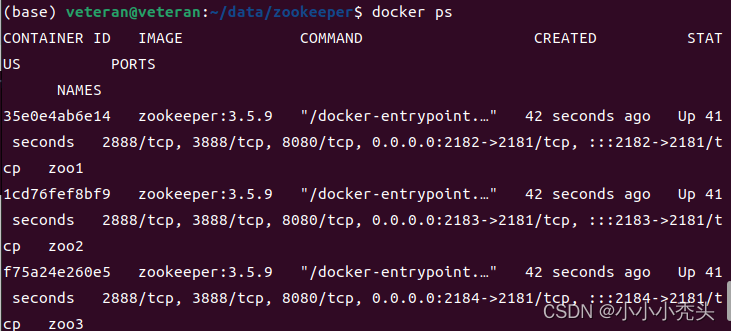
 使用docker ps查看启动的容器
使用docker ps查看启动的容器
搭建kafka集群
1、创建数据存储目录
cd /home/veteran/data/
mkdir -p kafka/node1/data
mkdir -p kafka/node2/datamkdir -p kafka/node3/data
2、创建kafka-compose.yml文件
touch kafka-compose.yml
sudo nano kafka-compose.yml
# 插入下面的内容
version: '3'
services:
broker1:
image: wurstmeister/kafka:latest
restart: always
container_name: broker1
privileged: true
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.43.207:9092 ## 宿主机IP
KAFKA_ADVERTISED_PORT: 9092
## zookeeper 集群,因为都在同一个内网,所以可以通过容器名称获取到容器的ip
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
volumes:
- "/home/veteran/data/kafka/node1/data/:/kafka"broker2:
image: wurstmeister/kafka:latest
restart: always
container_name: broker2
privileged: true
ports:
- "9093:9092"
environment:
KAFKA_BROKER_ID: 2
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.43.207:9093 ## 宿主机IP
KAFKA_ADVERTISED_PORT: 9093
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
volumes:
- "/home/veteran/data/kafka/node2/data/:/kafka"broker3:
image: wurstmeister/kafka:latest
restart: always
container_name: broker3
privileged: true
ports:
- "9094:9092"
environment:
KAFKA_BROKER_ID: 3
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.43.207:9094 ## 宿主机IP
KAFKA_ADVERTISED_PORT: 9094
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
volumes:
- "/home/veteran/data/kafka/node3/data/:/kafka"networks:
default:
external: true
name: kafka-net
3、执行kafka-compose.yml文件(自动拉取镜像)
docker-compose -f kafka-compose.yml up -d
4、 查看docker中运行的容器
docker ps

此时zookeeper集群与kafka集群已经搭建成功,我们开始创建生产者和消费者测试kafka集群。此次主要实现读取三个股票数据文件,分别记录不同股票的成交数量与交易量。
生产者
我们首先创建一个名为stock_1的topic,而后对生产者进行配置。为了读取csv文件,使用的哦阿了apache 的csv库函数,将stock_name作为key,trade_value作为alue作为消息进行发送。
public void producer() {
// 初始文件目录
List<String> filePaths = new ArrayList<>();
filePaths.add("/home/veteran/data/fileData/股票a.csv");
filePaths.add("/home/veteran/data/fileData/股票b.csv");
filePaths.add("/home/veteran/data/fileData/股票c.csv");
// 创建topic
String topic = "stock_1";
// 创建生产者
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.43.207:9092,192.168.43.207:9093,192.168.43.207:9094");
properties.put(ProducerConfig.LINGER_MS_CONFIG, 5);
// 把发送的key从字符串序列化为字节数组
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 把发送消息value从字符串序列化为字节数组
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> kProducer = new KafkaProducer<>(properties);
// 创建文件读取器
ReadFile readFile = new ReadFile();
// 循环处理三个文件
IntStream.range(0, filePaths.size()).forEach(index -> {
Iterable<CSVRecord> records = readFile.readCSV(filePaths.get(index));
// 提交topic
for (CSVRecord csvRecord : records) {
// 取出stock_name做为key
String key = csvRecord.get("stock_name");
// 取出trade_volume进行统计
String value = csvRecord.get("trade_volume");
ProducerRecord<String, String> kRecord = new ProducerRecord<>(topic, key, value);
// 使用kafka producer发送
kProducer.send(kRecord);
}
});
// 关闭生产者
kProducer.close();
}消费者
首先对kafka进行配置,关于kafka消费者与生产者的配置还有很多,目前就配置了每次最多能够读取的消息数量。创建两个map数据结构来记录不同stock_name的trade_volume和每个stock_name的成交数量。
public void consumer() {
// 初始化properties 类
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.43.207:9092,192.168.43.207:9093,192.168.43.207:9094");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "csv-consumer-group");
// 设置每次最多能够读取的消息数量
properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"1000");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 创建kafka消费者
KafkaConsumer<String, String> kConsumer = new KafkaConsumer<>(properties);
// 订阅消息
kConsumer.subscribe(Collections.singletonList("stock_1"));
// 通过map数据结构累积不同stock_name的trade_volume总量以及订单次数
Map<String, Long> accumulateData = new HashMap<>();
Map<String, Integer> stockCounts = new HashMap<>();
// 循环获取消息
while (true) {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建消费者记录器
ConsumerRecords<String, String> consumerRecords = kConsumer.poll(Duration.ofMillis(10000));
// 循环读取 并累积
for (ConsumerRecord<String, String> record : consumerRecords) {
String key = record.key();
String value = record.value();
long result = Long.parseLong(value);
// 对不同的key分别累积
if (accumulateData.containsKey(key)) {
accumulateData.put(key, accumulateData.get(key) + result);
stockCounts.put(key, stockCounts.get(key) + 1);
} else {
accumulateData.put(key, result);
stockCounts.put(key, 1);
}
// System.out.printf("接受到stock_1 %s 累积%d\n", key, result);
}
// 遍历accumulateData
for (Map.Entry<String, Long> entry : accumulateData.entrySet() ){
// 获取到stock_name
String stock_name = entry.getKey();
// 获取到 交易量
Long total_trade = entry.getValue();
// 获取到 订单数
int deal_counts = stockCounts.get(stock_name);
// 记录减一
System.out.printf("%s 共计交易 %d 成交 %d 单 \n", stock_name, total_trade, deal_counts);
}
System.out.println("--------------------------------------------------------------------");
long end = System.currentTimeMillis();
System.out.printf("花费时间为 %d", end - start);
}运行查看结果
