育种值:生物的数字密码
嗨,大家好!今天分享的笔记是遗传育种领域中那神秘莫测的育种值。这个抽象的名词具体如何理解?为什么说育种值很重要?具体怎么计算?有什么用处?
别担心,我会用最幽默有趣的语言,辅以一些示例代码,让你快速了解育种值的定义、计算方法以及背后的算法原理,并给出Python和R两个版本的计算过程源码。
育种值是什么啊?
首先,我们得搞清楚育种值到底是啥。简单说,育种值是遗传育种领域里的一种评估指标,用来衡量个体在进化和繁殖中的“价值”。这个价值并不是指一个体有多么“强”,而是它在基因传递方面的出色表现。
定义
育种值是指种畜的种用价值。在数量遗传学中把决定数量性状的基因加性效应值定义为育种值(BV),个体育种值的估计值叫做估计育种值(EBV)。通俗的理解就是某个体所具有的遗传优势,即它高于或低于群体平均数的部分。
育种值的定义就像一把打开基因宝箱的钥匙,让我们能更好地了解基因世界中那些微小但却至关重要的差异。当我们在育种中选择父母个体时,育种值就是我们的指南针,指引我们朝着优化基因组的方向前进。
计算育种值的魔法
好了,现在让我们深入了解如何计算这个神秘的育种值。其实,计算育种值并不像看起来那么复杂,它的本质就是一些数学和统计的魔法。
算法一:选择差异法
在遗传学的大舞台上,一个广泛使用的育种值计算算法就是“选择差异法”(Selection Differential)。这个算法的核心思想是,我们通过比较选择群体和整体群体的基因型值来评估选择压力的强度。
下面是一个简单的示例代码:
import numpy as np
def calculate_selection_differential(selected_population, original_population):
selected_mean = np.mean(selected_population)
original_mean = np.mean(original_population)
selection_differential = selected_mean - original_mean
return selection_differential
# 示例数据
selected_population = np.random.normal(10, 2, 1000)
# 选择后的群体
original_population = np.random.normal(8, 2, 1000)
# 整体群体
# 计算选择差异
selection_differential = calculate_selection_differential(selected_population, original_population)
print(f"选择差异为: {selection_differential}")
这段代码模拟了一个选择后的群体和整体群体的基因型值分布,然后计算了选择差异。选择差异越大,说明选择压力越强,育种值就越高。
算法二:后代平均值法
另一个常用的育种值计算方法是后代平均值法(Progeny Mean Method)。这个方法通过比较后代群体的表现来评估父母个体的基因传递效果。代码如下:
def calculate_progeny_mean(selected_parents, offspring):
selected_mean = np.mean(selected_parents)
offspring_mean = np.mean(offspring)
progeny_mean = offspring_mean - selected_mean
return progeny_mean
# 示例数据
selected_parents = np.random.normal(12, 1, 500) # 选择的父母个体
offspring = np.random.normal(10, 1, 1000) # 后代群体
# 计算后代平均值
progeny_mean = calculate_progeny_mean(selected_parents, offspring)
print(f"后代平均值为: {progeny_mean}")
这段代码模拟了选择的父母个体和后代群体的表现,然后计算了后代平均值。越高的后代平均值表示父母个体的基因传递效果越好,育种值也就越高。
育种值有什么用处?
育种值在遗传育种领域中具有重要的应用价值,它为农业、畜牧业和其他生物学领域提供了有力的工具,以下是育种值在实际应用中的几个重要方面:
优化遗传进程:
育种值的计算有助于优化基因组的传递,提高所关注性状的遗传表现。通过选择具有较高育种值的个体作为父母,可以加速所需性状的进化,达到更好的遗传改良效果。
提高生产效率:
在农业和畜牧业中,育种值的应用可以带来更高的生产效率。通过选择具有优越基因的个体,农作物和动物的生长速度、产量、抗病能力等性状可以得到有效改良,从而提高农业和畜牧业的产量和质量。
适应环境变化:
随着气候和环境的变化,育种值的应用可以帮助培育更适应新环境的品种。通过选择具有适应性基因的个体,可以提高作物或动物对新环境条件的适应能力,增加其生存和生长的成功率。
节约资源:
通过精确计算育种值,可以更有效地选择父母个体,从而减少不必要的繁殖成本和资源浪费。这对于农业和畜牧业来说是非常重要的,因为资源的节约直接关系到生产的可持续性和经济效益。
R语言版计算方法
在R语言中,也可以使用lme4包快速的计算育种值,最佳线性无偏预测(Best Linear Unbiased Prediction,简称BLUP)。它可以对多环境数据进行整合,去除环境效应,得到个体稳定遗传的信息。
安装相关软件包
需要提前安装lme4包和tidyverse包
install.packages("lme4")
install.packages("tidyverse")
计算多环境无重复BLUP
输入数据格式要求
需要以下格式的数据,缺失值使用NA代替,注意环境和样品的数据类型应该为因子格式,表型为数值型。
# 样品 环境 表型值
line env y
L1 env1 66.72533
L2 env1 53.82899
L3 env1 58.04559
计算方法
首先,读入数据并整理:
library(lme4)
data=read.table("data.txt",header = T)
head(data)
data$lines=factor(data$lines)
data$env=factor(data$env)
然后,可以使用lmer进行分析,把env和lines当成随机效应。
blp=lmer(y~(1|env)+(1|lines),data=data)
# 输出摘要信息
summary(blp)
得到类似如下结果,其中展示了遗传方差(即lines的方差)和残差方差,
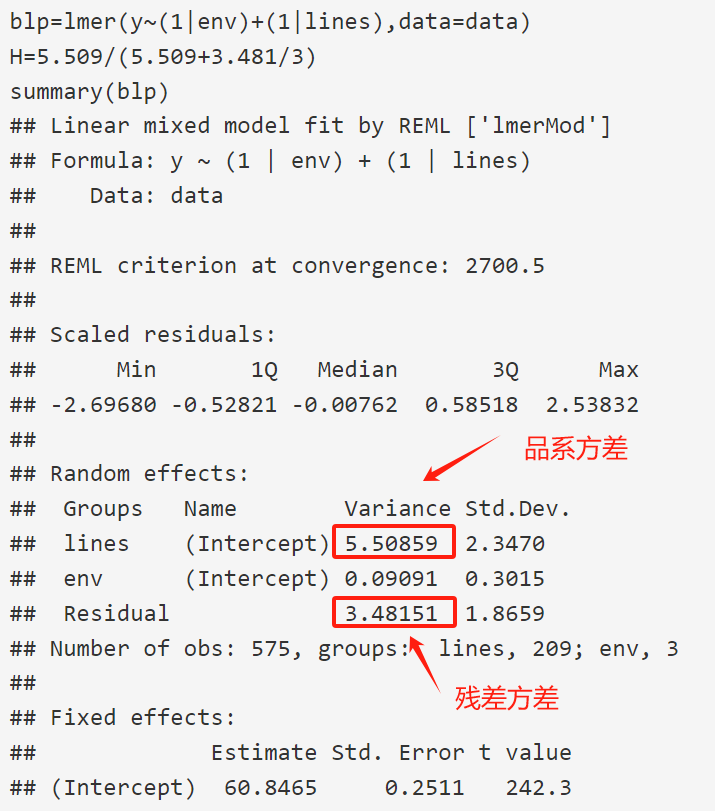 使用如下公式即可计算出遗传力h:
使用如下公式即可计算出遗传力h: 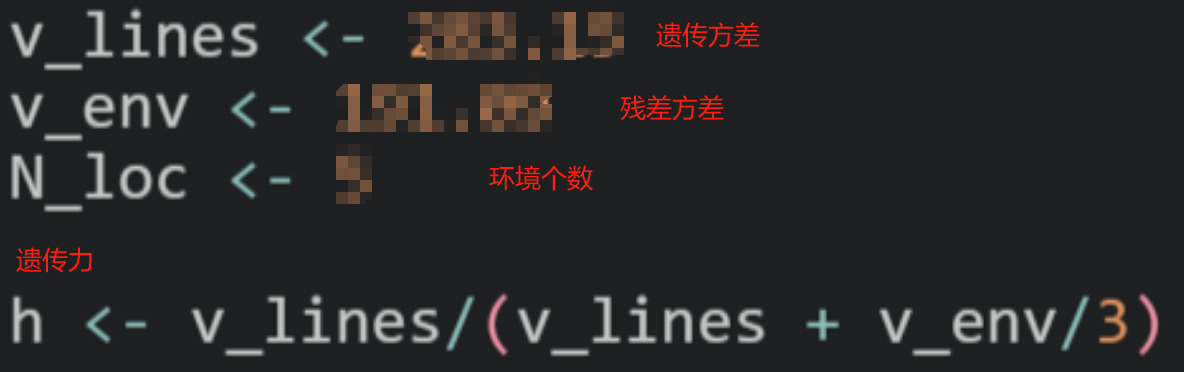
通过这篇文章,我们简要了解了育种值的定义和计算方法,以及背后的算法原理。在遗传育种的舞台上,育种值就像是一把魔法的秘钥,为我们解锁基因世界的奥秘。
如果你有任何疑问或想要深入探讨,欢迎后台私信交流,也欢迎将本文分享给其他朋友,我们一起在基因的海洋中探寻更多的奇迹!
本文由 mdnice 多平台发布