自动驾驶汽车让我感到恐惧。这些巨大的金属块在没有人类干预的情况下四处飞驰,如果出现问题,没有人能够制止它们。为了降低这种风险,仅仅评估驱动这些汽车的模型是不够的。我们还需要了解它们是如何进行预测的。这是为了避免任何可能导致意外事故的边缘情况。
好吧,我们的应用程序并不那么重要。我们将调试用于驱动小型自动驾驶汽车的模型(你所能期望的最糟糕的情况可能只是扭伤了脚踝)。不过,IML方法可能会有所帮助。我们将看看它们如何甚至可以改善模型的性能。
具体来说,我们将:
使用PyTorch和图像数据以及连续目标变量对ResNet-18进行微调。
使用均方误差(MSE)和散点图来评估模型。
使用DeepSHAP解释模型。
通过更好的数据收集来校正模型。
探讨图像增强如何进一步改善模型。
在这个过程中,我们将讨论一些关键的Python代码片段。你还可以在GitHub上找到完整的项目。
如果你对SHAP不熟悉,那么请看下面的视频。如果你想了解更多,请参加我的SHAP课程。如果你订阅我的新闻通讯,你可以免费获得访问权限 :)
https://youtu.be/L8_sVRhBDLU
Python软件包
# Imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import glob
import random
from PIL import Image
import cv2
import torch
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
import shap
from sklearn.metrics import mean_squared_error数据集
我们从仅在一个房间内收集数据开始(这将会给我们带来麻烦)。如前所述,我们使用图像来驱动一辆自动驾驶汽车。你可以在Kaggle上找到这些图像的示例。这些图像都是224 x 224像素。
我们使用下面的代码显示其中一个图像。请注意图像的名称(第2行)。前两个数字是在224 x 224框架内的x和y坐标。在图1中,你可以看到我们使用绿色圆圈(第8行)显示了这些坐标。
#Load example image
name = "32_50_c78164b4-40d2-11ed-a47b-a46bb6070c92.jpg"
x = int(name.split("_")[0])
y = int(name.split("_")[1])
img = Image.open("../data/room_1/" + name)
img = np.array(img)
cv2.circle(img, (x, y), 8, (0, 255, 0), 3)
plt.imshow(img)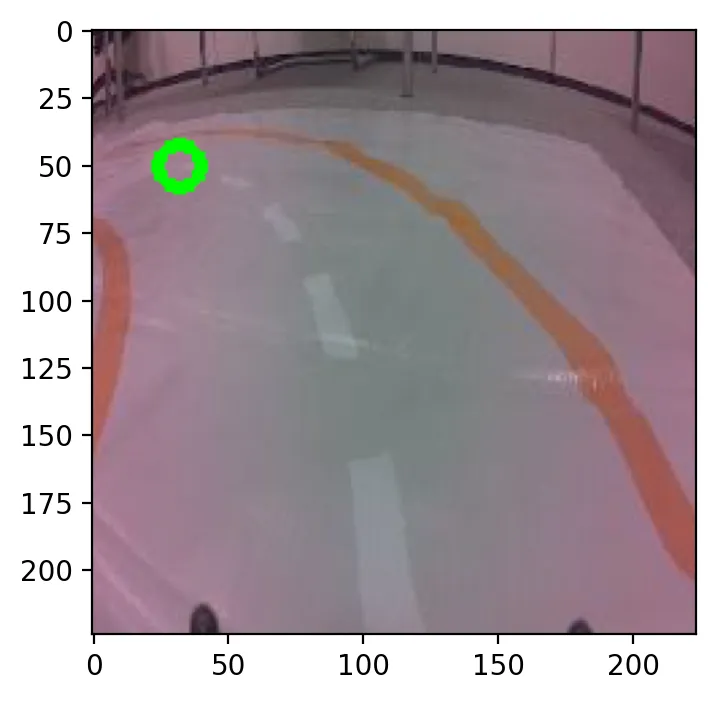
这些坐标是目标变量。模型使用图像作为输入来预测它们。然后,这个预测值用于控制汽车。在这种情况下,你可以看到汽车即将转向左边。理想的方向是朝着绿色圆圈给出的坐标前进。
训练PyTorch模型
我想重点介绍SHAP,所以我们不会深入研究建模代码。如果你有任何问题,请随时在评论中提问。
我们首先创建ImageDataset类。这个类用于加载我们的图像数据和目标变量。它使用图像的路径来完成这个任务。需要指出的一件事是目标变量是如何缩放的 —— x和y都将在-1到1之间。
class ImageDataset(torch.utils.data.Dataset):
def __init__(self, paths, transform):
self.transform = transform
self.paths = paths
def __getitem__(self, idx):
"""Get image and target (x, y) coordinates"""
# Read image
path = self.paths[idx]
image = cv2.imread(path, cv2.IMREAD_COLOR)
image = Image.fromarray(image)
# Transform image
image = self.transform(image)
# Get target
target = self.get_target(path)
target = torch.Tensor(target)
return image, target
def get_target(self,path):
"""Get the target (x, y) coordinates from path"""
name = os.path.basename(path)
items = name.split('_')
x = items[0]
y = items[1]
# Scale between -1 and 1
x = 2.0 * (int(x)/ 224 - 0.5) # -1 left, +1 right
y = 2.0 * (int(y) / 244 -0.5)# -1 top, +1 bottom
return [x, y]
def __len__(self):
return len(self.paths)实际上,在部署模型时,只使用x预测来引导汽车。由于缩放的原因,x预测的符号将决定汽车的方向。当x < 0时,汽车应该向左转。类似地,当x > 0时,汽车应该向右转。x值越大,转弯越急。
我们使用ImageDataset类创建训练和验证数据加载器。这是通过对来自room 1的所有图像路径进行随机的80/20分割来完成的。最终,我们在训练集和验证集中分别有1,217张和305张图像。
TRANSFORMS = transforms.Compose([
transforms.ColorJitter(0.2, 0.2, 0.2, 0.2),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
paths = glob.glob('../data/room_1/*')
# Shuffle the paths
random.shuffle(paths)
# Create a datasets for training and validation
split = int(0.8 * len(paths))
train_data = ImageDataset(paths[:split], TRANSFORMS)
valid_data = ImageDataset(paths[split:], TRANSFORMS)
# Prepare data for Pytorch model
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
valid_loader = DataLoader(valid_data, batch_size=valid_data.__len__())请注意valid_loader的batch_size。我们使用验证数据集的长度(即305)作为batch_size。这使我们能够在一次迭代中加载所有验证数据。如果你正在处理更大的数据集,可能需要使用较小的batch_size。
我们加载一个预训练的ResNet18模型(第5行)。通过设置model.fc,我们更新了最后一层(第6行)。这是一个从512个节点到我们的2个目标变量节点的全连接层。我们将使用Adam优化器来微调这个模型(第9行)。
output_dim = 2 # x, y
device = torch.device('mps') # or 'cuda' if you have a GPU
# RESNET 18
model = torchvision.models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(512, output_dim)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())我使用了GPU来训练模型(第2行)。你仍然可以在CPU上运行代码。微调不像从头开始训练那样计算密集!
最后,我们有模型训练代码。我们使用MSE作为损失函数进行10个epoch的训练。我们的最终模型是在验证集上具有最低MSE的模型。
name = "direction_model_1" # Change this to save a new model
# Train the model
min_loss = np.inf
for epoch in range(10):
model = model.train()
for images, target in iter(train_loader):
images = images.to(device)
target = target.to(device)
# Zero gradients of parameters
optimizer.zero_grad()
# Execute model to get outputs
output = model(images)
# Calculate loss
loss = torch.nn.functional.mse_loss(output, target)
# Run backpropogation to accumulate gradients
loss.backward()
# Update model parameters
optimizer.step()
# Calculate validation loss
model = model.eval()
images, target = next(iter(valid_loader))
images = images.to(device)
target = target.to(device)
output = model(images)
valid_loss = torch.nn.functional.mse_loss(output, target)
print("Epoch: {}, Validation Loss: {}".format(epoch, valid_loss.item()))
if valid_loss < min_loss:
print("Saving model")
torch.save(model, '../models/{}.pth'.format(name))
min_loss = valid_loss评估指标
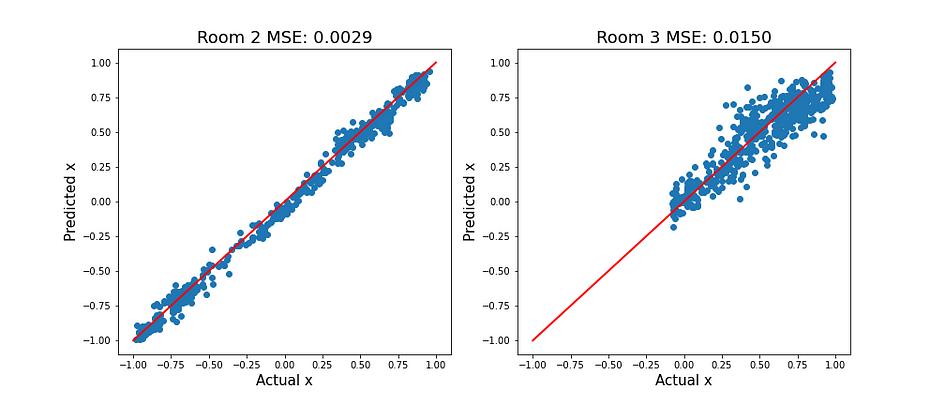
此时,我们希望了解我们的模型表现如何。我们查看均方误差(MSE)以及实际值与预测值x的散点图。暂时忽略y,因为它不影响汽车的方向。
训练集和验证集
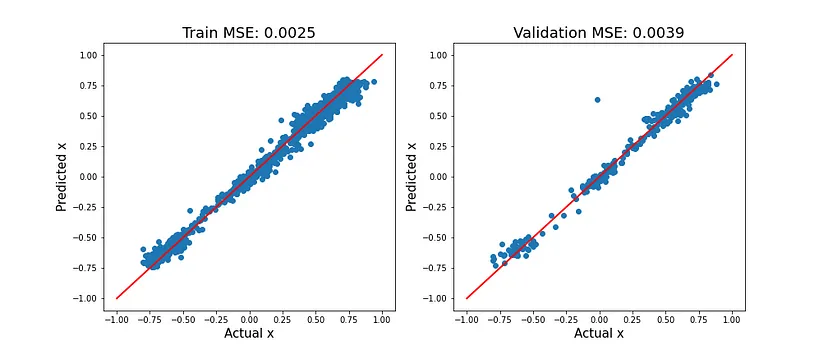
图2显示了训练集和验证集上的这些指标。对角线上的红线代表完美预测。对于x < 0和x > 0,该线周围存在类似的变化。换句话说,该模型能够以相似的准确度预测左转和右转。在训练集和验证集上表现相似还表明该模型没有过拟合。
要创建上述图,我们使用了model_evaluation函数。请注意,数据加载器应该被创建成这样,以便它们在第一次迭代中加载所有数据。
def model_evaluation(loaders,labels,save_path = None):
"""Evaluate direction models with mse and scatter plots
loaders: list of data loaders
labels: list of labels for plot title"""
n = len(loaders)
fig, axs = plt.subplots(1, n, figsize=(7*n, 6))
# Evalution metrics
for i, loader in enumerate(loaders):
# Load all data
images, target = next(iter(loader))
images = images.to(device)
target = target.to(device)
output=model(images)
# Get x predictions
x_pred=output.detach().cpu().numpy()[:,0]
x_target=target.cpu().numpy()[:,0]
# Calculate MSE
mse = mean_squared_error(x_target, x_pred)
# Plot predcitons
axs[i].scatter(x_target,x_pred)
axs[i].plot([-1, 1],
[-1, 1],
color='r',
linestyle='-',
linewidth=2)
axs[i].set_ylabel('Predicted x', size =15)
axs[i].set_xlabel('Actual x', size =15)
axs[i].set_title("{0} MSE: {1:.4f}".format(labels[i], mse),size = 18)
if save_path != None:
fig.savefig(save_path)我们创建了一个新的train_loader,将batch大小设置为训练数据集的长度。还重要的是加载已保存的模型(第2行)。否则,你将使用在最后一个epoch训练的模型。
# Load saved model
model = torch.load('../models/direction_model_1.pth')
model.eval()
model.to(device)
# Create new loader for all data
train_loader = DataLoader(train_data, batch_size=train_data.__len__())
# Evaluate model on training and validation set
loaders = [train_loader,valid_loader]
labels = ["Train","Validation"]
# Evaluate on training and validation set
model_evaluation(loaders,labels)移动到新位置
结果看起来不错!我们期望汽车表现良好,而它也确实如此。直到我们将它移到一个新的位置:

使用SHAP调试模型
我们寻求SHAP来寻找答案。它可以用于了解哪些像素对于给定的预测是重要的。我们首先加载我们保存的模型(第2行)。由于SHAP尚未针对GPU实现,因此我们将设备设置为CPU(第5–6行)。
# Load saved model
model = torch.load('../models/direction_model_1.pth')
# Use CPU
device = torch.device('cpu')
model = model.to(device)要计算SHAP值,我们需要获取一些背景图像。在计算值时,SHAP将对这些图像进行积分。我们使用了一个批次大小为100张图像。这应该给我们合理的近似值。增加图像的数量将改善近似值,但也会增加计算时间。
#Load 100 images for background
shap_loader = DataLoader(train_data, batch_size=100, shuffle=True)
background, _ = next(iter(shap_loader))
background = background.to(device)通过将模型和背景图像传递到DeepExplainer函数,我们创建了一个解释器对象。此函数有效地为神经网络近似SHAP值。作为替代方案,你可以将其替换为GradientExplainer函数。
#Create SHAP explainer
explainer = shap.DeepExplainer(model, background)我们加载了2个示例图像 —— 一个右转和一个左转(第2行),并对它们进行了转换(第6行)。这很重要,因为图像应该与训练模型时使用的格式相同。然后,我们计算使用这些图像进行的预测的SHAP值(第10行)。
# Load test images of right and left turn
paths = glob.glob('../data/room_1/*')
test_images = [Image.open(paths[0]), Image.open(paths[3])]
test_images = np.array(test_images)
test_input = [TRANSFORMS(img) for img in test_images]
test_input = torch.stack(test_input).to(device)
# Get SHAP values
shap_values = explainer.shap_values(test_input)最后,我们可以使用image_plot函数显示SHAP值。但首先,我们需要重新构造它们。SHAP值的维度如下所示:
(#目标, #图像, #通道, #宽度, #高度)
我们使用transpose函数,使其具有以下维度:
(#目标, #图像, #宽度, #高度, #通道)
请注意,我们还将原始图像传递给image_plot函数。由于变换,test_input图像会看起来很奇怪。
# Reshape shap values and images for plotting
shap_numpy = list(np.array(shap_values).transpose(0,1,3,4,2))
test_numpy = np.array([np.array(img) for img in test_images])
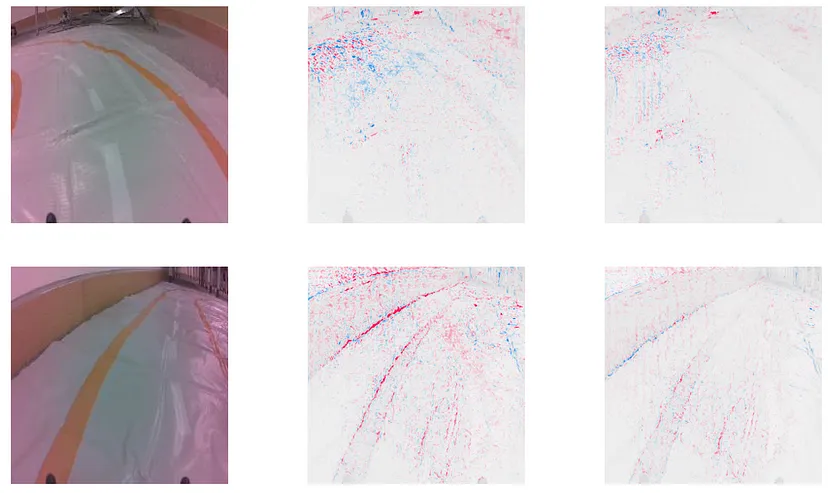
shap.image_plot(shap_numpy, test_numpy,show=False)你可以在图4中看到结果。第一列是原始图像。第二列和第三列分别是x和y预测的SHAP值。蓝色像素降低了预测值。相比之下,红色像素增加了预测值。换句话说,对于x预测,红色像素导致更锐利的右转。
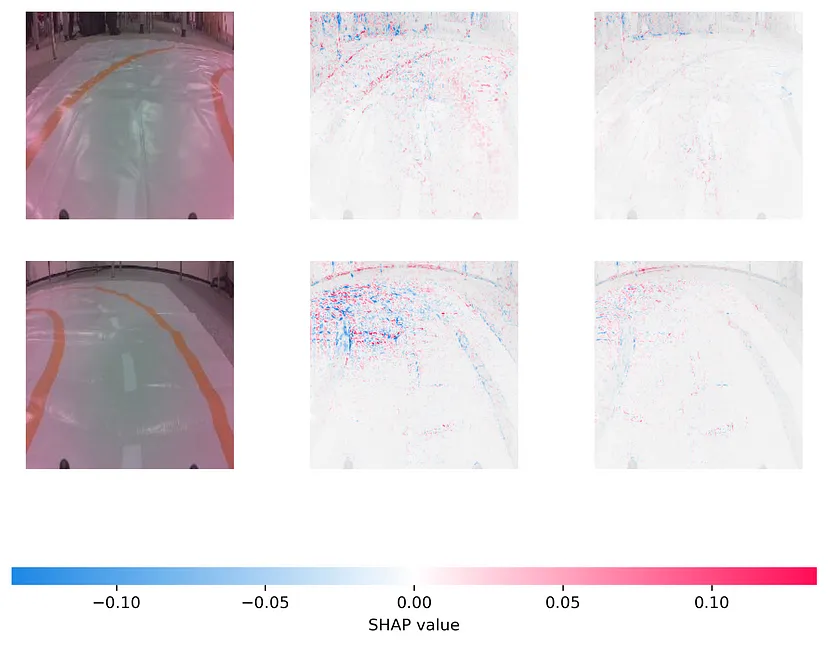
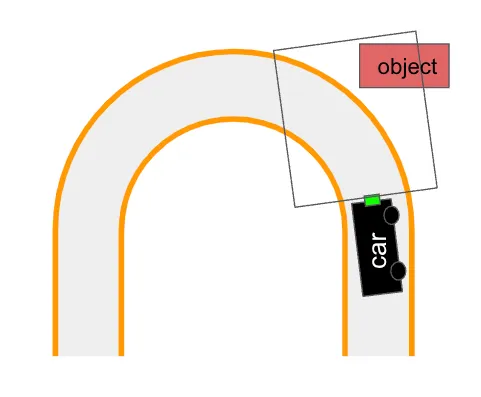
现在我们有了一些进展。重要的结果是模型使用了背景像素。你可以在图5中看到,我们放大了右转的x预测。换句话说,背景对于预测很重要。这解释了性能不佳的原因!当我们移到新房间时,背景发生变化,我们的预测变得不可靠。

模型对来自room 1的数据过拟合了。每个图像中都存在相同的对象和背景。因此,模型将这些与左转和右转关联起来。在我们的评估中,我们无法识别这一点,因为训练图像和验证图像中的背景是相同的。
改进模型
我们希望我们的模型在所有条件下表现良好。为了实现这一点,我们期望它只使用赛道上的像素。因此,让我们讨论一些使模型更加健壮的方法。
收集新数据
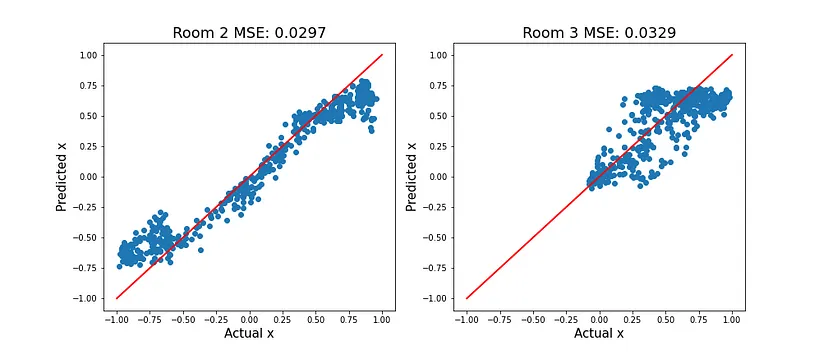
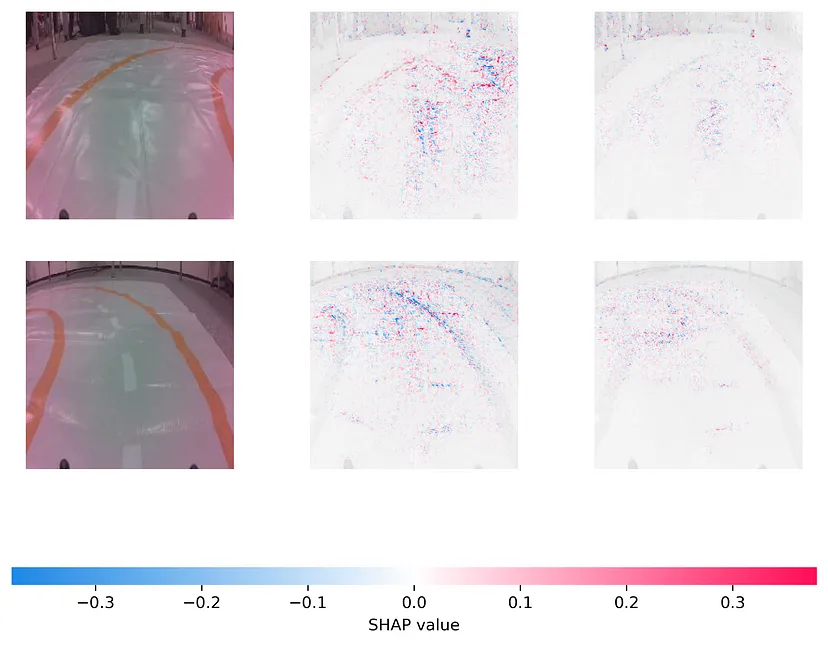
最好的解决方案是简单地收集更多数据。我们已经有一些来自room 2和room 3的数据。按照相同的流程,我们使用来自所有3个房间的数据训练一个新模型。从图7中可以看出,现在在来自新房间的图像上表现更好。
希望通过在多个房间的数据上进行训练,我们打破了转弯和背景之间的关联。不同的对象现在出现在左转和右转上,但赛道保持不变。模型应该学会赛道对于预测是重要的。
我们可以通过查看新模型的SHAP值来确认这一点。这些是与图4中看到的相同的转弯。现在背景像素的权重较小。好吧,它不是完美的,但我们已经取得了一些进展。
我们可以继续收集数据。我们收集的地点越多,模型就会变得越健壮。但是,数据收集可能是耗时的(而且无聊!)。相反,我们可以考虑数据增强。
数据增强
数据增强是指我们使用代码系统地或随机地改变图像的方法。这允许我们人为地引入噪音并增加数据集的大小。
例如,我们可以通过在垂直轴上翻转图像来将数据集的大小加倍。我们之所以能够这样做,是因为我们的赛道是对称的。如图9所示,删除也可能是一种有用的方法。这涉及到包括已删除对象或整个背景的图像。

在构建健壮的模型时,你还应该考虑光照条件和图像质量等因素。我们可以使用颜色抖动或添加噪音来模拟这些因素。如果你想了解所有这些方法,请查看下面的文章。
https://towardsdatascience.com/augmenting-images-for-deep-learning-3f1ea92a891c
在上述文章中,我们还讨论了为什么很难确定这些增强是否使模型更加健壮。我们可以在许多环境中部署模型,但这需要时间。幸运的是,SHAP可以作为一种替代方法。与数据收集类似,它可以让我们了解增强如何改变模型进行预测的方式。
希望你喜欢这篇文章!
参考资料
SHAP, PyTorch Deep Explainer MNIST example https://shap.readthedocs.io/en/latest/example_notebooks/image_examples/image_classification/PyTorch%20Deep%20Explainer%20MNIST%20example.html
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
