黑箱模型的解释-SHAP
1.SHAP值
SHAP值基于Shapley值,Shapley值是博弈论中的一个概念。SHAP所做的是量化每个特征对模型所做预测的贡献。

对于所有的特征上图(Age、Gender、Job)可以自由组合共有2^3=8种可能(数学中称为power set即幂集)。SHAP需要为幂集中的每个不同的组合训练一个不同的预测模型,这意味着有8个模型。当然,这些模型在涉及到它们的超参数和训练数据时是完全等价的。唯一改变的是模型中包含的一组特征。
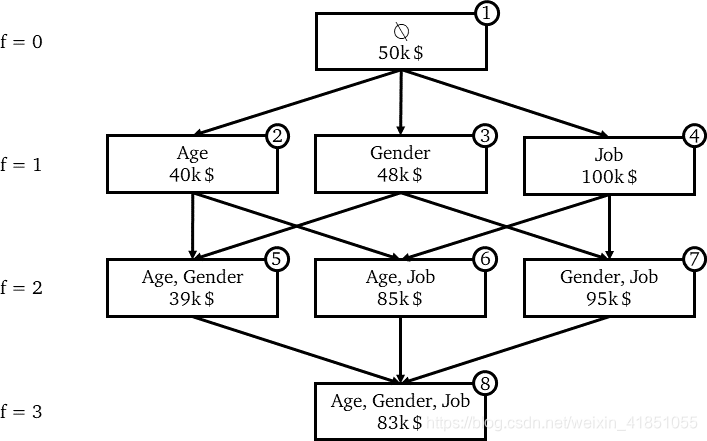
假设上图是已经用相同训练样本训练了8个线性回归的模型。我们可以用这8个模型分别对一个测试样本做预测(x1),最后得出8个预测结果如上图。因为SHAP值所做的是量化每个特征对模型所做预测的贡献,因此需要计算出每个特征的SHAP值。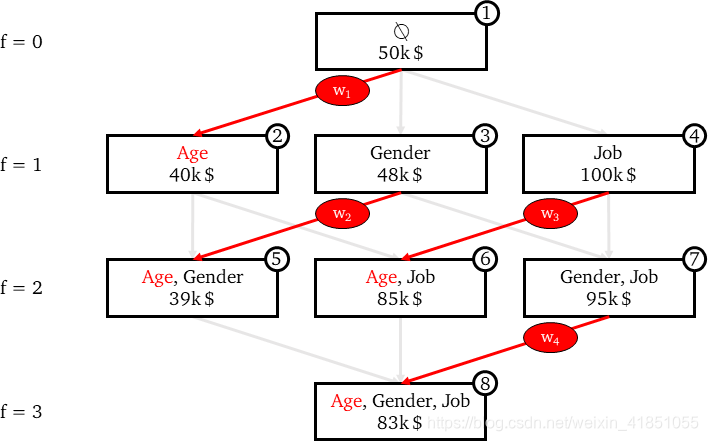
对于模型2中Age可以算出年龄作为特征的模型的边际贡献是:
要获得年龄对最终模型效果的影响需要将所以涉及到Age的模型的边际贡献汇总。上图展示了所有涉及年龄的模型(1、2、5、6、8),可以得到年龄的贡献值(SHAP值)如下:
如何确定边际贡献的权重:
- 所有边际贡献对具有1个特征的模型的权重之和应等于所有边际贡献对具有2个特征的模型的权重之和,以此类推……,换句话说,同一“行”上所有权值的和应该等于任意其他“行”上所有权值的和。在我们的例子中,这意味着:w₁= w₂+ w₃= w₄
- 对每个f,f个特征的模型的所有的边际贡献的权重应该是相等的。换句话说,同一“行”上的所有边应该相等。在我们的例子中,这意味着:w₂ = w₃
结合数据可以计算出x1的Age的SHAP值:
应用到我们的例子中,得到: -
把它们加起来就是+33k,这正好是完整模型的输出(83k )和没有任何特征的虚拟模型的输出(50k)之间的差值。
2.SHAP值应用于黑箱模型的解释
2.1 数据

2.2 SHAP值的解释(反映出了相互作用)
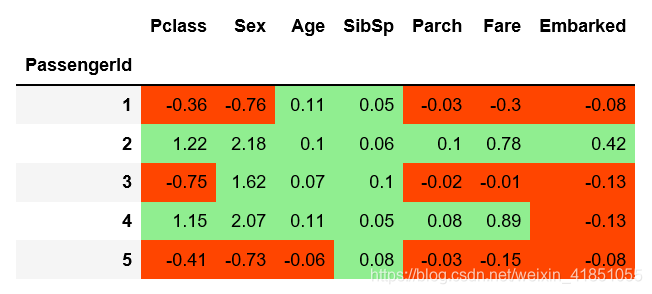
上图为前5个样本的数据(Pclass:客舱等级;Sex:乘客性别;Age:乘客年龄;SibSp:泰坦尼克号上的兄弟姐妹/配偶人数;Parch:泰坦尼克上的家长/儿童人数;Fare:乘客票价;Embarked:登船口岸)
上图横向为变量,纵向为样本的每个样本变量的SHAP值(以Catboost模型为例)。SHAP值越高,生还概率越高,反之亦然。此外,大于0的SHAP值会导致概率的增加,小于0的值会导致概率的减少。
假设对于第一个个体,我们知道除了年龄以外的所有变量。它的SHAP和是-0.36 -0.76 +0.05 -0.03 -0.3 -0.08 = -1,48。一旦我们知道了个体的年龄(也考虑了年龄和其他变量之间的相互作用),我们就可以更新总和:-1.48 +0.11 =-1.37。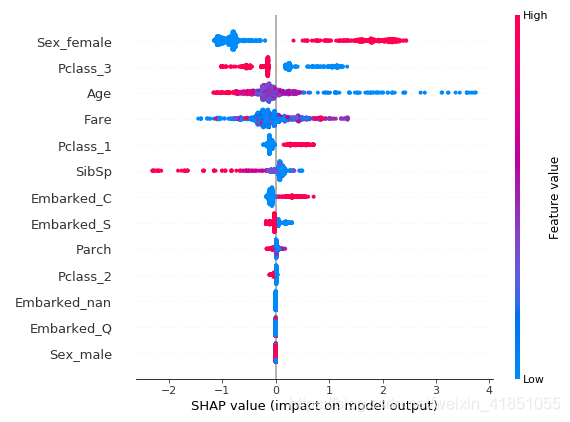
上图基于Python的SHAP库来进行画出(SHAP值对于人类来说是不可理解的(即使对于数据科学家来说也是如此))
2.3 SHAP值转化到概率(用概率的方式解释,更加容易理解)
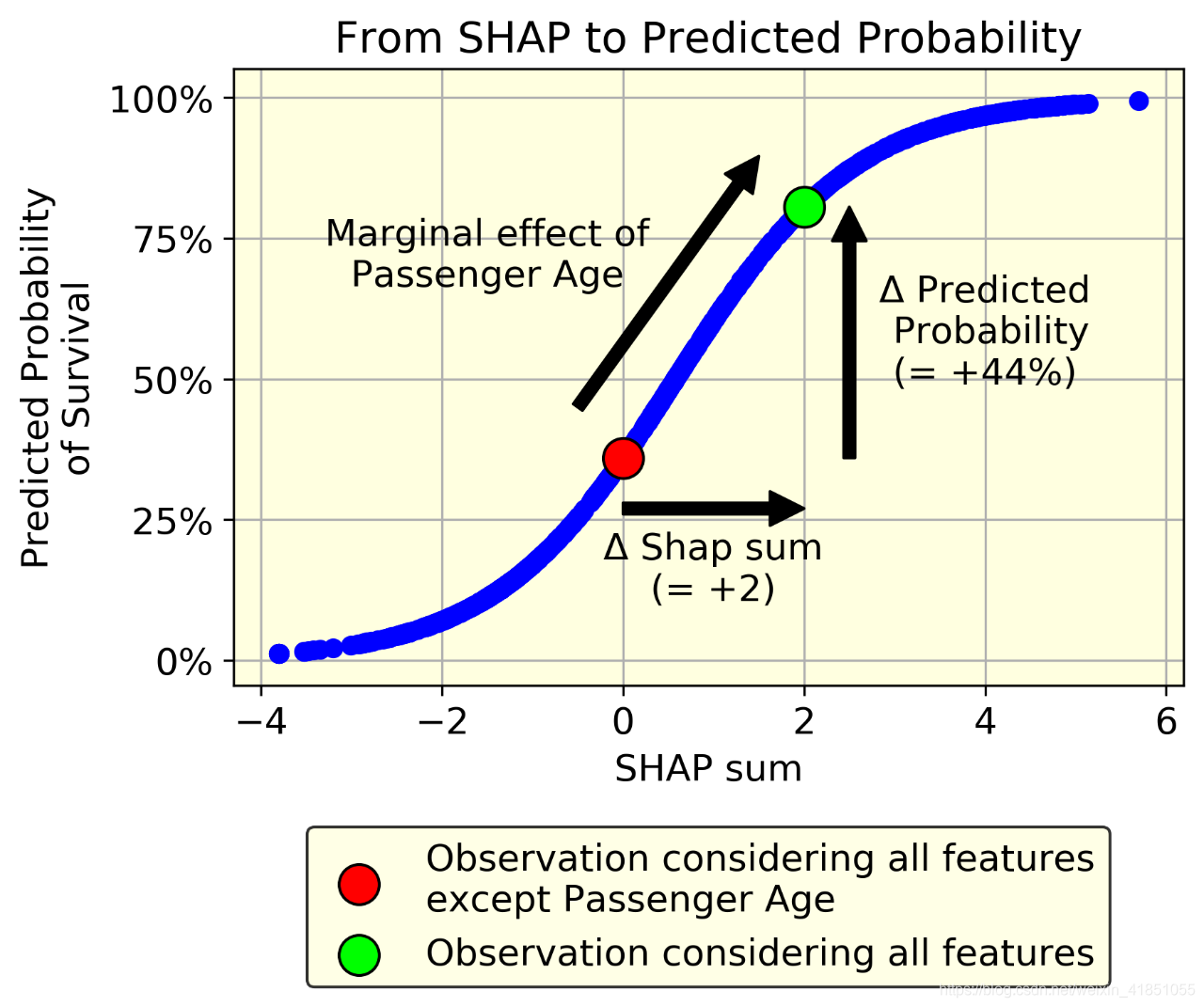
SHAP值是一个任意实数,而概率是在[0,1]范围内。因此需要一个函数f(.)将SHAP转化为概率(f(.)可以是满足条件的任何函数,并不是确定的)。即:
假设已知除年龄外的所有变量,其SHAP和为0。现在假设年龄的SHAP值是2。f()函数就可以量化年龄对预测的生存概率的影响:它就是f(2)-f(0)。在我们的例子中,f(2)-f(0) = 80%-36% = 44%。按照这种思路可以算出每个格子中的影响(impact),可以应用以下公式:
得到如下的格子影响: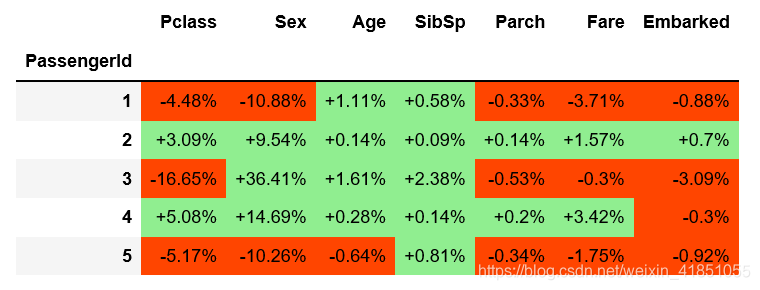
拥有一张三等舱的票会降低第一个乘客的生存概率-4.48%(相当于-0.36 SHAP)。请注意,3号乘客和5号乘客也在三等舱。由于与其他特征的相互作用,它们对概率的影响(分别为-16.65%和-5.17%)是不同的。
2.4 SHAP值转化到概率的进一步解释
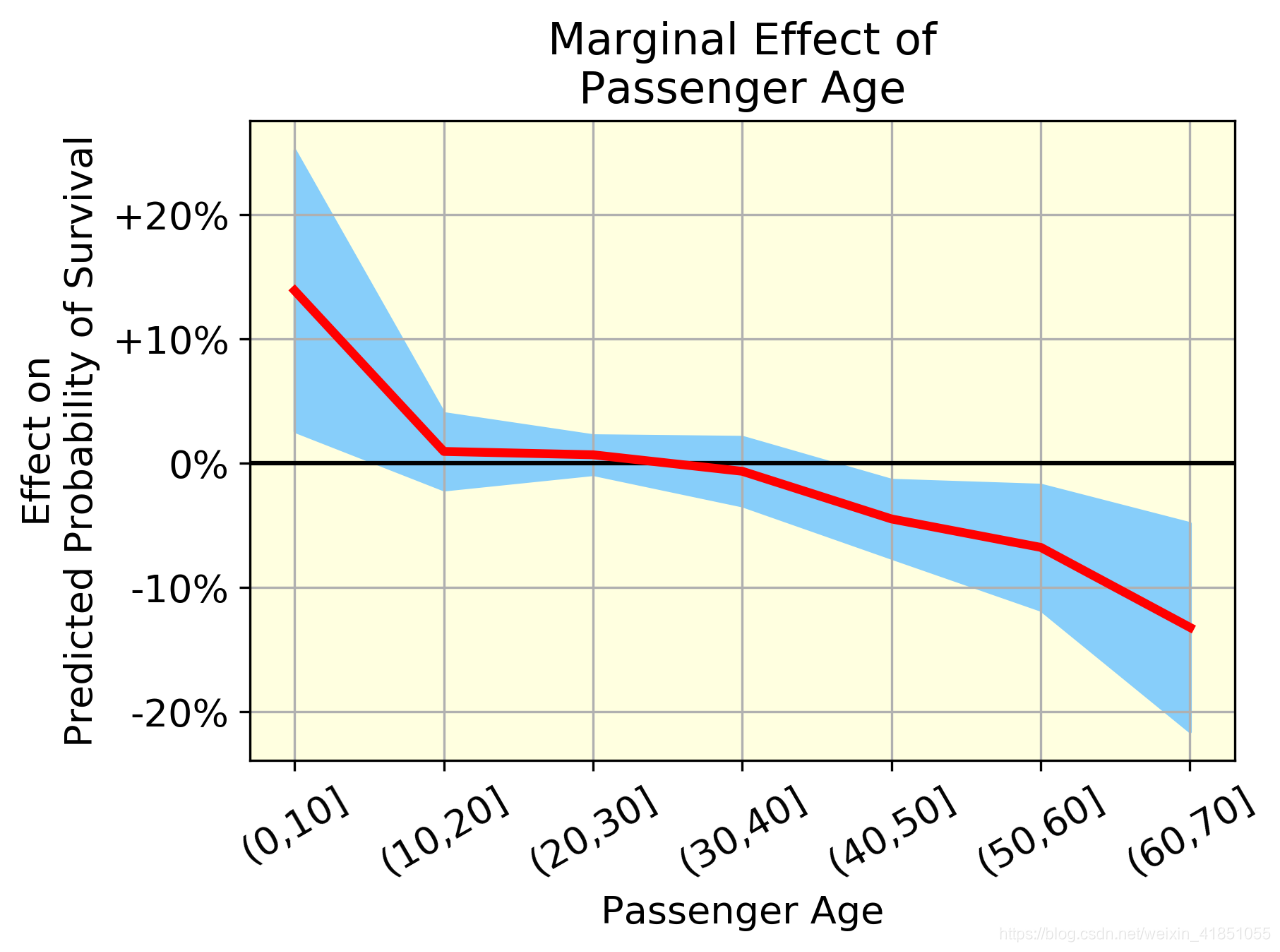
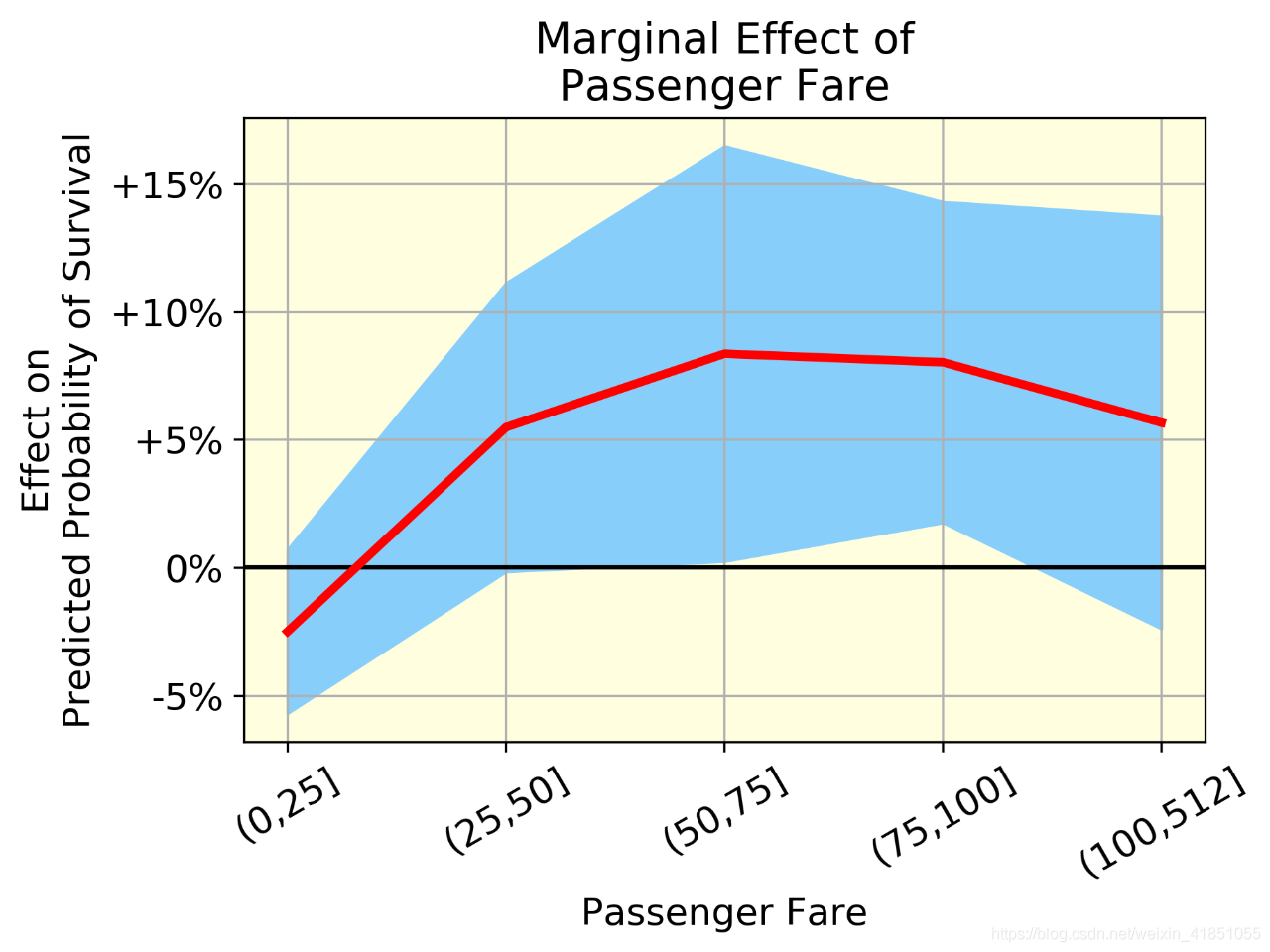
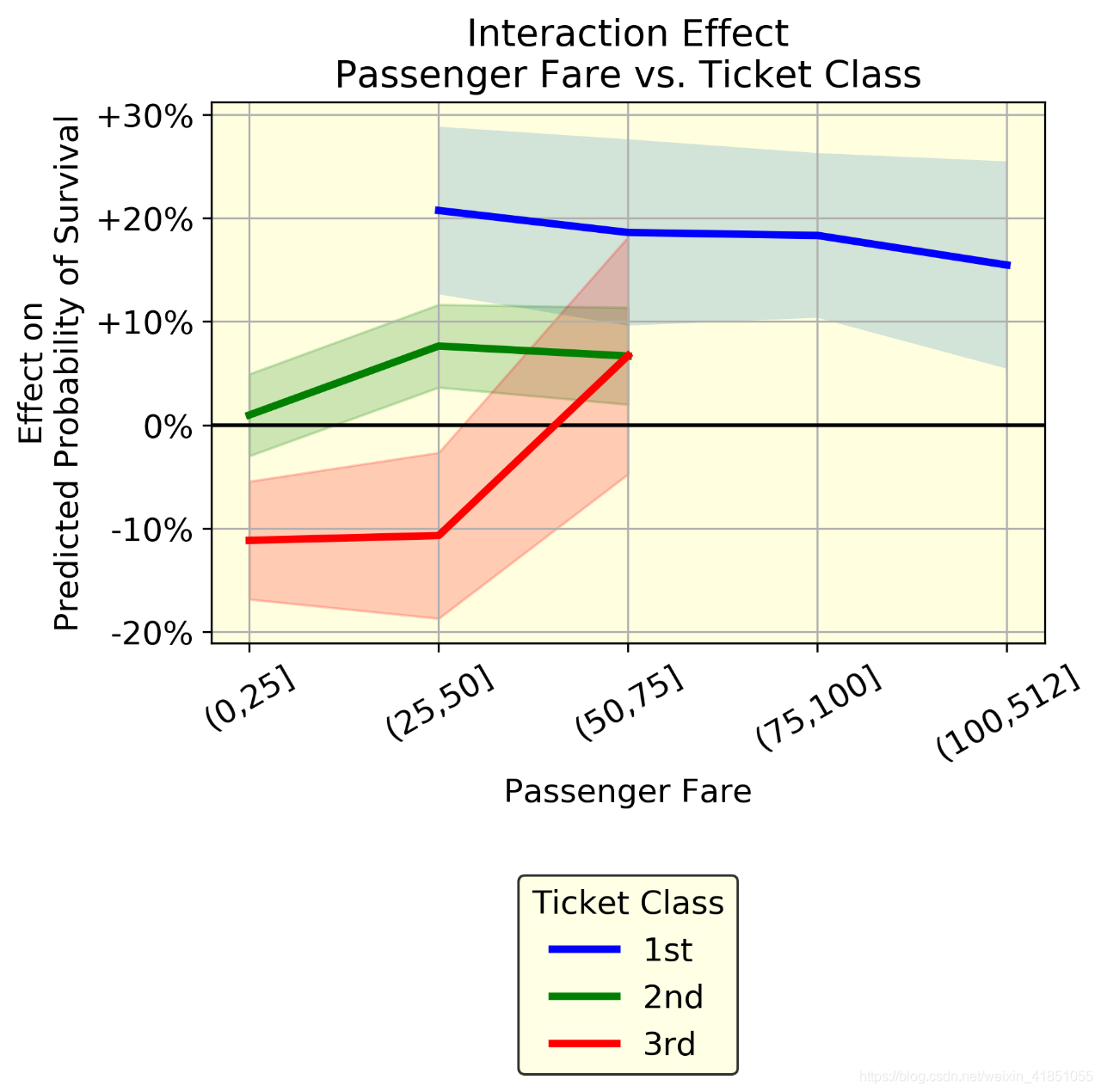
图一是乘客年龄的边际效应,图二是乘客票价的边际效应,图三是交互作用:乘客票价 vs. 客舱等级。红线表示平均效应(一组中所有个体的年龄效应的均值),蓝带(均值±标准差)表示同一组中个体年龄效应的变异性。变异是由于年龄和其他变量之间的相互作用。以上3个图可提供的价值有:
- 我们可以用概率来量化效果,而不是用SHAP值。例如,我们可以说,平均来说,60-70岁的人比0-10岁的人(从+14%到-13%)的存活率下降了27%
- 我们可以可视化非线性效应。例如,看看乘客票价,生存的可能性上升到一个点,然后略有下降
- 我们可以表示相互作用。例如,乘客票价与客舱等级。如果这两个变量之间没有相互作用,这三条线就是平行的。相反,他们表现出不同的行为。蓝线(头等舱乘客)的票价稍低。特别有趣的是红线(三等舱乘客)的趋势:在两个相同的人乘坐三等舱时,支付50 - 75英镑的人比支付50英镑的人更有可能生存下来(从-10%到+5%)。
3.总结
- 像逻辑回归这样的简单模型做了大量的简化。黑盒模型更灵活,因此更适合复杂(但非常直观)的现实世界行为,如非线性关系和变量之间的交互。
- 可解释性是指基于人类对现实的感知(包括复杂的行为),以一种人类可理解的方式表达模型的选择。
- 我们展示了一种将SHAP值转换为概率的方法。这使我们有可能对一个黑匣子进行可视化,并确保它与我们对世界的认识是一致的(在质量和数量上):一个比简单模型所描述的世界更丰富的世界。
4.代码实现(待更…)
5.参考
1.https://www.6aiq.com/article/1588001724187
2.https://towardsdatascience.com/black-box-models-are-actually-more-explainable-than-a-logistic-regression-f263c22795d