就是取前几个epoch的weight的平均值,可以缓解微调时的灾难性遗忘(因为新数据引导,模型权重逐渐,偏离训练时学到的数据分布,忘记之前学好的先验知识)
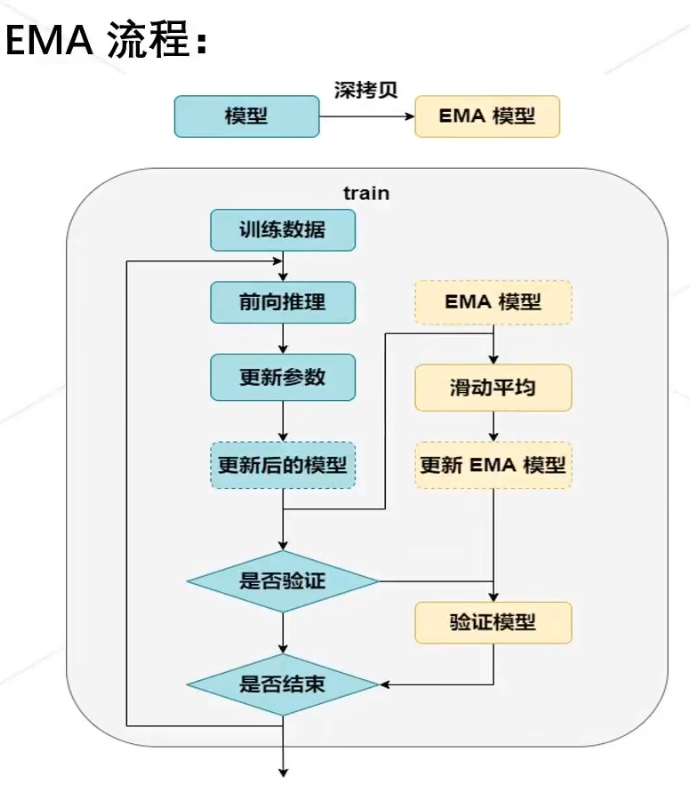
class EMA():
def __init__(self, model, decay):
self.model = model
self.decay = decay # decay rate
self.shadow = {
} # old weight
self.backup = {
} # new weight
def register(self): # deep copy weight for init
for name, param in self.model.named_parameters():
if param.requires_grad:
self.shadow[name] = param.data.clone()
def update(self): # ema:average weight for train
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
new_average = (1.0 - self.decay) * param.data + self.decay * self.shadow[name]
self.shadow[name] = new_average.clone()
def apply_shadow(self): # load old weight for eval begin
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
self.backup[name] = param.data
param.data = self.shadow[name]
def restore(self): # load new weight for eval end
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.backup
param.data = self.backup[name]
self.backup = {
}
# 初始化
ema = EMA(model, 0.999)
ema.register()
# 训练过程中,更新完参数后,同步update shadow weights
def train():
optimizer.step()
ema.update()
# eval前,apply shadow weights;eval之后,恢复原来模型的参数
def evaluate():
ema.apply_shadow()
# evaluate
ema.restore()