1--Model介绍
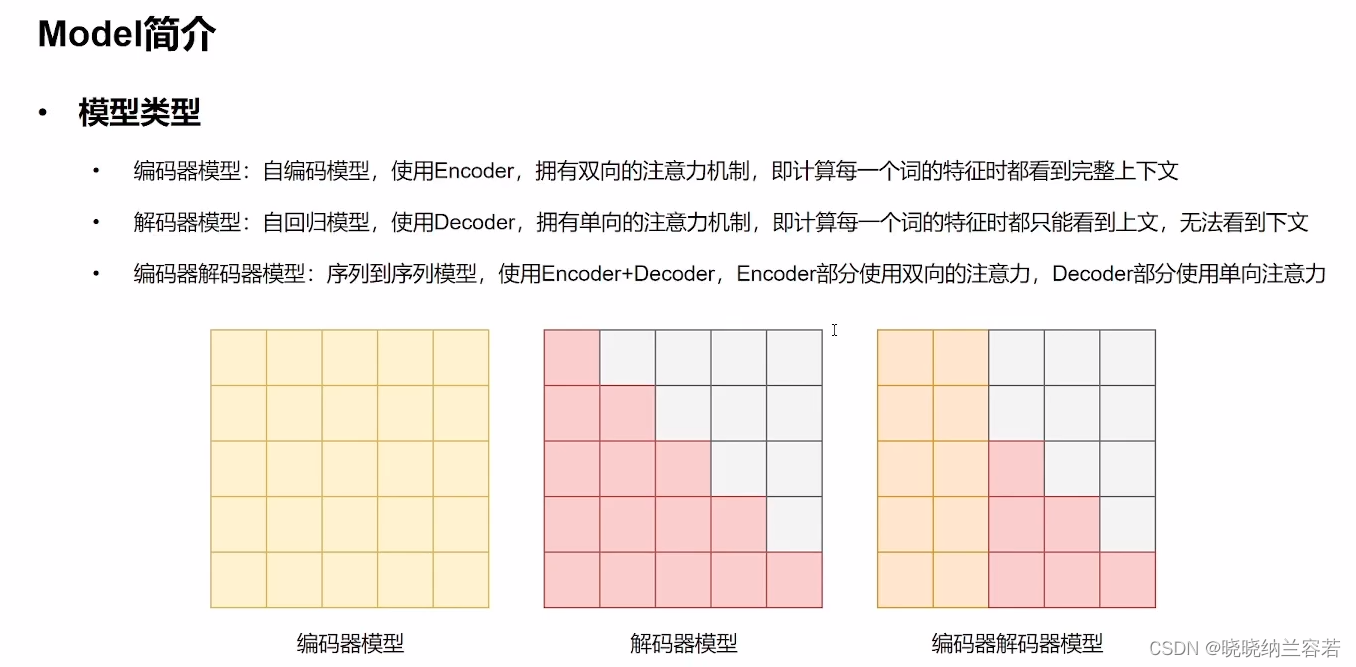
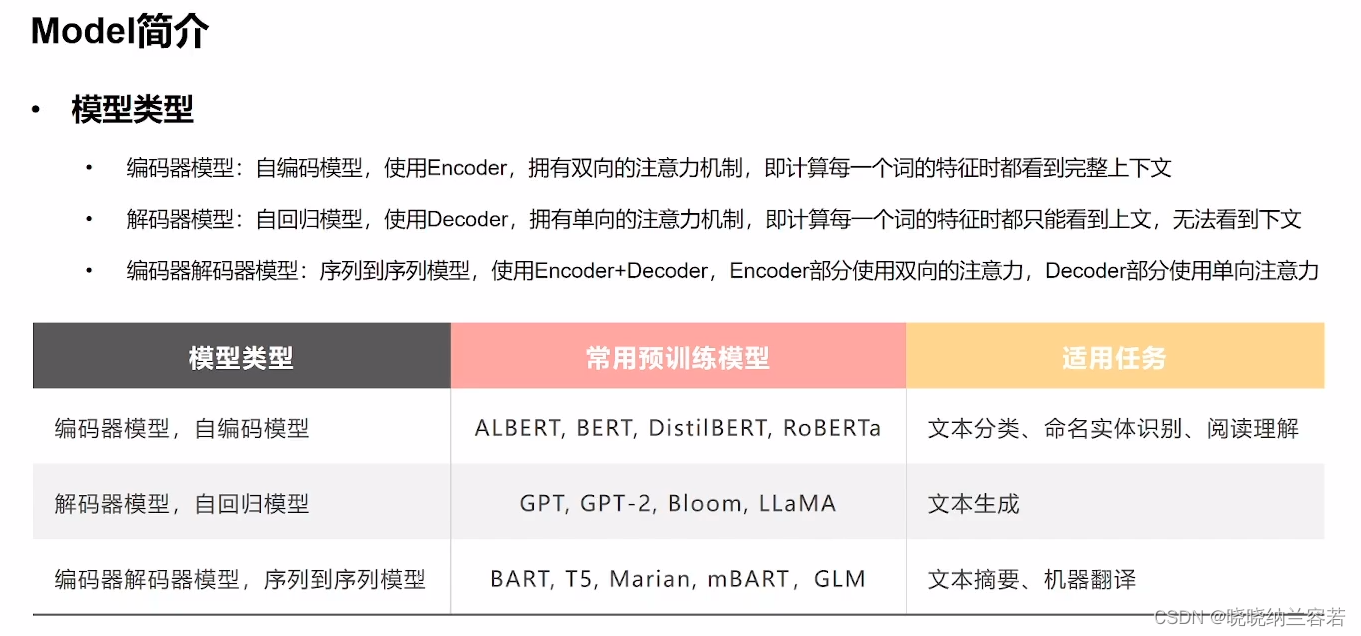
Transformer的 model 一般可以分为:编码器类型(自编码)、解码器类型(自回归)和编码器解码器类型(序列到序列);
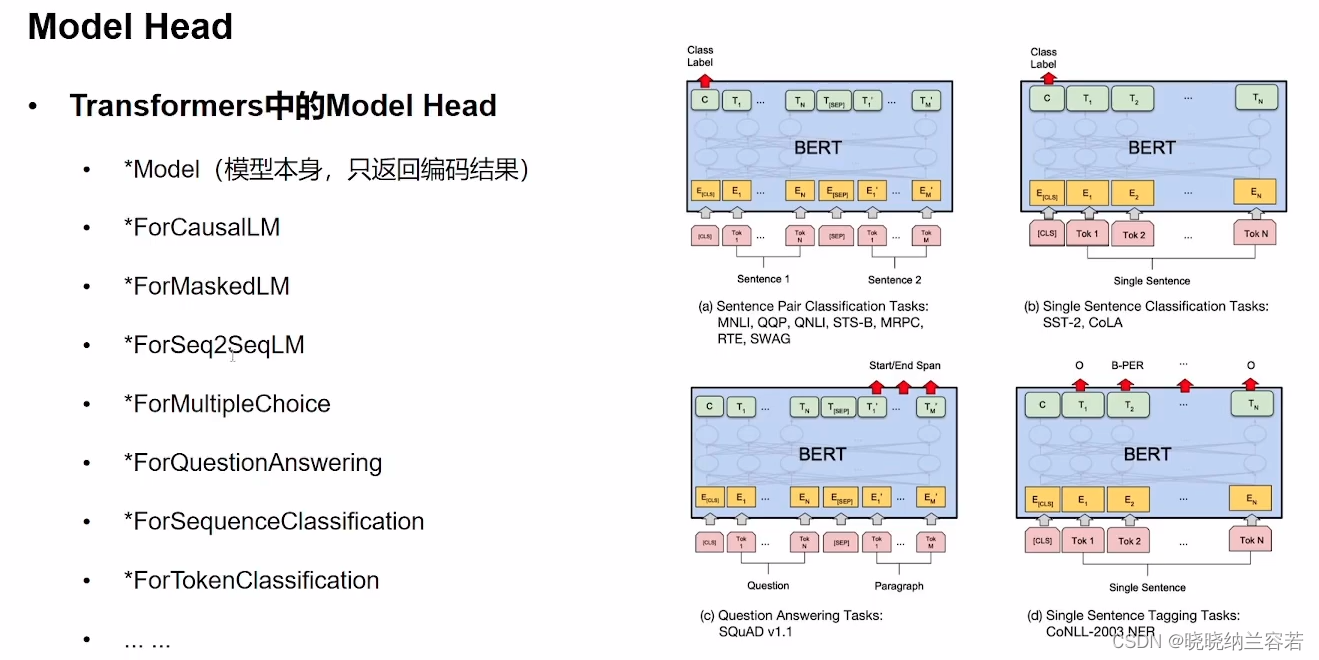
Model Head(任务头)是在base模型的基础上,根据不同任务而设置的模块;base模型只起到一个编码和建模特征的功能;

简单代码:
from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification
if __name__ == "__main__":
# 数据处理
sen = "弱小的我也有大梦想!"
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")
inputs = tokenizer(sen, return_tensors="pt")
# 不带model head的模型调用
model = AutoModel.from_pretrained("hfl/rbt3", output_attentions=True)
output1 = model(**inputs)
print(output1.last_hidden_state.size()) # [1, 12, 768]
# 带model head的模型调用
clz_model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3", num_labels=10)
output2 = clz_model(**inputs)
print(output2.logits.shape) # [1, 10]2--AutoModel的使用
AutoModel 用于加载模型;
2-1--简单Demo
测试代码:
from transformers import AutoTokenizer, AutoModel
if __name__ == "__main__":
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenlizer = AutoTokenizer.from_pretrained(checkpoint)
raw_input = ["I love kobe bryant.", "Me too."]
inputs = tokenlizer(raw_input, padding = "longest", truncation = True, max_length = 512, return_tensors = "pt")
# 加载指定的模型
model = AutoModel.from_pretrained(checkpoint)
print("model: \n", model)
outputs = model(**inputs)
print("last_hidden_state: \n", outputs.last_hidden_state.shape) # 打印最后一个隐层的输出维度
# [2 7 768] batch_size为2,7个token,每个token的维度为768
输出结果:
last_hidden_state:
torch.Size([2, 7, 768])
# 最后一个隐层的输出
# batchsize为2,表示两个句子
# 7表示token数,每一个句子有7个token
# 768表示特征大小,每一个token的维度为768测试代码:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
if __name__ == "__main__":
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenlizer = AutoTokenizer.from_pretrained(checkpoint)
raw_input = ["I love kobe bryant.", "Me too."]
inputs = tokenlizer(raw_input, padding = "longest", truncation = True, max_length = 512, return_tensors = "pt")
model2 = AutoModelForSequenceClassification.from_pretrained(checkpoint) # 二分类任务
print(model2)
outputs2 = model2(**inputs)
print(outputs2.logits.shape)运行结果:
torch.Size([2, 2])
# 两个句子,每个句子二分类的概率