Huggingface的介绍,使用(CSDN最强Huggingface入门手册)
1.Huggingface的简介
Huggingface即是网站名也是其公司名,随着transformer浪潮,Huggingface逐步收纳了众多最前沿的模型和数据集等有趣的工作,与transformers库结合,可以快速使用学习这些模型。目前提到NLP必然绕不开Huggingface。
2.Huggingface的具体介绍
进入Huggingface网站,如下图所示。

其主要包含:
- Models(模型),包括各种处理CV和NLP等任务的模型,上面模型都是可以免费获得
- Datasets(数据集),包括很多数据集
- Spaces(分享空间),包括社区空间下最新的一些有意思的分享,可以理解为huggingface朋友圈
- Docs(文档,各种模型算法文档),包括各种模型算法等说明使用文档
- Solutions(解决方案,体验等),包括others
- Pricing(dddd) ,懂的都懂
3.Huggingface的Models
点开Models。可以看到下图的任务,再点开+23 Tasks。

可以看到下图所有的任务。
其中,主要包括计算机视觉、自然语言处理、语音处理、多模态、表格处理、强化学习。


展开介绍:
Computer Vision(计算机视觉任务):包括lmage Classification(图像分类),lmage Segmentation(图像分割)、zero-Shot lmage Classification(零样本图像分类)、lmage-to-Image(图像到图像的任务)、Unconditional lmage Generation(无条件图像生成)、Object Detection(目标检测)、Video Classification(视频分类)、Depth Estimation(深度估计,估计拍摄者距离图像各处的距离)
Natural Language Processing(自然语言处理):包括Translation(机器翻译)、Fill-Mask(填充掩码,预测句子中被遮掩的词)、Token Classification(词分类)、Sentence Similarity(句子相似度)、Question Answering(问答系统),Summarization(总结,缩句)、Zero-Shot Classification (零样本分类)、Text Classification(文本分类)、Text2Text(文本到文本的生成)、Text Generation(文本生成)、Conversational(聊天)、Table Question Answer(表问答,1.预测表格中被遮掩单词2.数字推理,判断句子是否被表格数据支持)
Audio(语音):Automatic Speech Recognition(语音识别)、Audio Classification(语音分类)、Text-to-Speech(文本到语音的生成)、Audio-to-Audio(语音到语音的生成)、Voice Activity Detection(声音检测、检测识别出需要的声音部分)
Multimodal(多模态):Feature Extraction(特征提取)、Text-to-Image(文本到图像)、Visual Question Answering(视觉问答)、Image2Text(图像到文本)、Document Question Answering(文档问答)
Tabular(表格):Tabular Classification(表分类)、Tabular Regression(表回归)
Reinforcement Learning(强化学习):Reinforcement Learning(强化学习)、Robotics(机器人)
API地址(可以自己对着学,博客这里就只是给出些简单介绍)
模型的使用
一般来说,页面上会给出模型的介绍。例如,我们打开其中一个fill-mask任务下下载最多的模型bert-base-uncased。

可以看到模型描述:

使用方法
需要提前安装transformers库,可以直接pip install transformers安装。还有Pytorch或TensorFlow库,读者自行下载。
下载完后可以使用pipeline直接简单的使用这些模型。第一次执行时pipeline会加载模型,模型会自动下载到本地,可以直接用。第一个参数是任务类型,第二个是具体模型名字。
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Hello I'm a [MASK] model.")
模型下载在本地的地址:
C:\Users\【自己的用户名】\.cache\huggingface\hub
当然,不同模型使用方法略有区别,直接通过页面学习或文档学习最好。

可以自定义加载输入分词器:使用AutoTokenizer
from transformers import AutoTokenizer
#下面这种方式可以自动加载bert-base-uncased中使用的分词器
tokenizer=AutoTokenizer.from_pretrained("bert-base-uncased")
可以自定义加载模型结构:使用AutoModel
不包括输入分词器和输出部分!!!
from transformers import AutoModel
#下面这种方式可以自动加载bert-base-uncased中使用的模型,没有最后的全连接输出层和softmax
model=AutoModel.from_pretrained("bert-base-uncased")
可以自定义加载模型和输出部分:使用AutoModelForSequenceClassification等
from transformers import AutoModelForSequenceClassification
#下面这种方式可以自动加载bert-base-uncased中使用的模型(包括了输出部分),有最后的全连接输出层
model=AutoModel.AutoModelForSequenceClassification("bert-base-uncased")
模型保存
model.save_pretrained("./")#保持到当前目录
1个简单流程例子
input=['The first sentence!','The second sentence!']
from transformers import AutoTokenizer
tokenizer=AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")#https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english
input=tokenizer(input, padding=True, truncation=True, return_tensors='pt')#padding='max_length'
from transformers import AutoModelForSequenceClassification
model=AutoModel.AutoModelForSequenceClassification("distilbert-base-uncased-finetuned-sst-2-english")
print(model)
output=model(**input)
print(output.logits.shape)
import torch
predictions=torch.nn.functional.softmax(output.logits, dim=1)
print(predictions)
print(model.config.id2label)
4.Huggingface的dataset
可以看到有如下任务的数据集。读者可自行打开学习

例如,我们打开Text Classification 任务的glue数据集
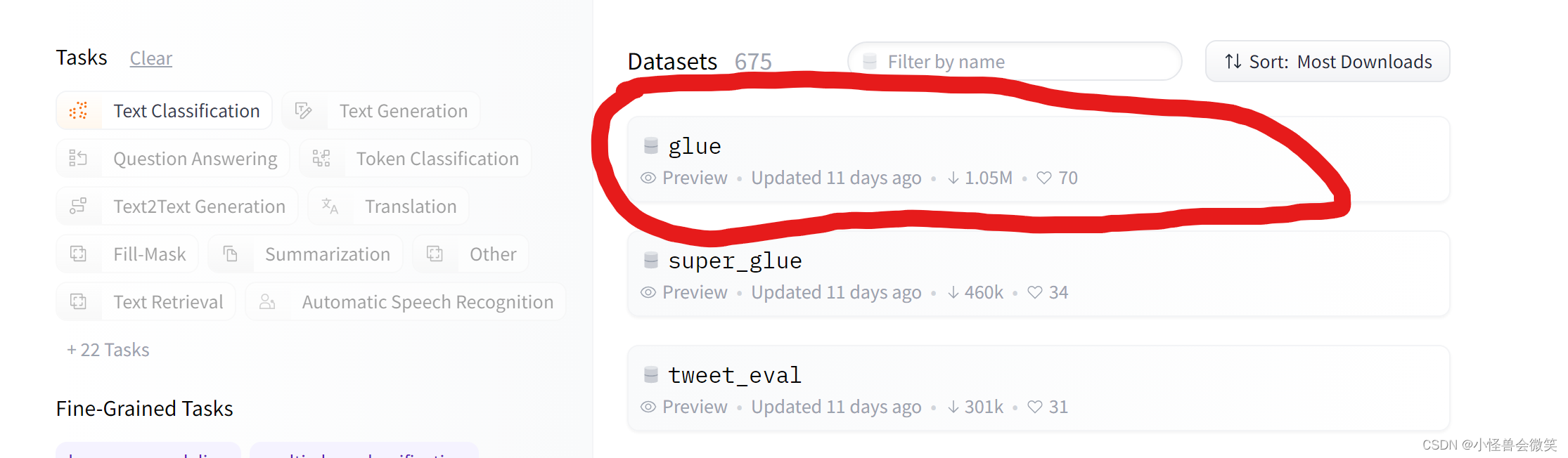
可以看到下图,里面会有数据集的介绍、相关信息和下载方式,读者自行查看。

加粗样式
导入数据集方法(提前pip install datasets)
from datasets import load_dataset
datasets=load_dataset("glue","mrpc")#glue下还有其他数据集
print(datasets)
train_data=datasets['train']
print(train_data[0])
有了数据后训练模型方法
#下面给出bert-base-uncased的例子,实现对两个句子的相似度计算
#导入tokenizer
from transformers import AutoTokenizer
tokenizer=AutoTokenizer.from_pretrained("bert-base-uncased")#https://huggingface.co/bert-base-uncased
#input=tokenizer('The first sentence!','The second sentence!')#测试
#print(tokenizer.convert_ids_to_tokens(input["input_id"]))
#实际使用tokenizer的方法,得到tokenizer_data
def tokenize_function(example):
return tokenizer(example["sentence1"],example["sentence2"],truncation=True)
from datasets import load_dataset
datasets=load_dataset("glue","mrpc")
tokenizer_data=datasets.map(tokenize_function,batched=True)
print(tokenizer_data)
#训练参数
from transformers import TrainingArguments
training_arg=TrainingArguments("test-trainer")#训练参数,可以自己去改,参数意思参考https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments
print(training_arg)#看下默认值
#导入模型
from transformers import AutoModelForSequenceClassification
model=AutoModelForSequenceClassification.from_pre_trained("bert-base-uncased",num_labels=2)#num_labels自己定义了,所以不会导入输出层
#导入数据处理的一个东西DataCollatorWithPadding,变成一个一个batch
from transformers import DataCollatorWithPadding
data_collator=DataCollatorWithPadding(tokenizer=tokenizer)
#导入训练器,进行训练,API : https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Trainer
from transformers import Trainer
trainer=Trainer(model,training_arg,train_dataset=tokenizer_data["train"],eval_dataset=tokenizer_data["validation"],data_collator=data_collator,tokenizer=tokenizer)
trainer.train()
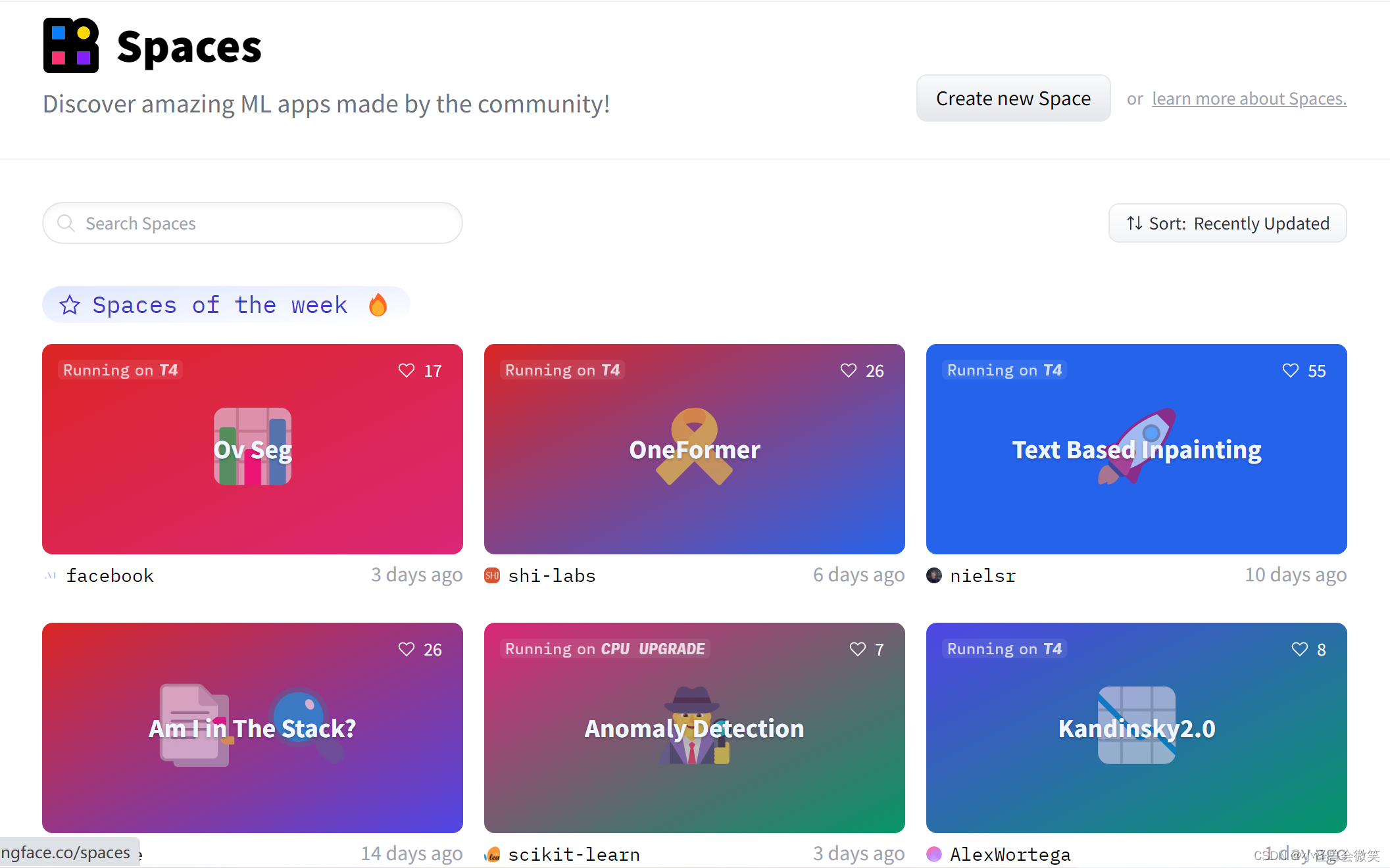
5.Huggingface的spaces
点开如下图所示。里面有些近些天有趣的东西火热的apps。
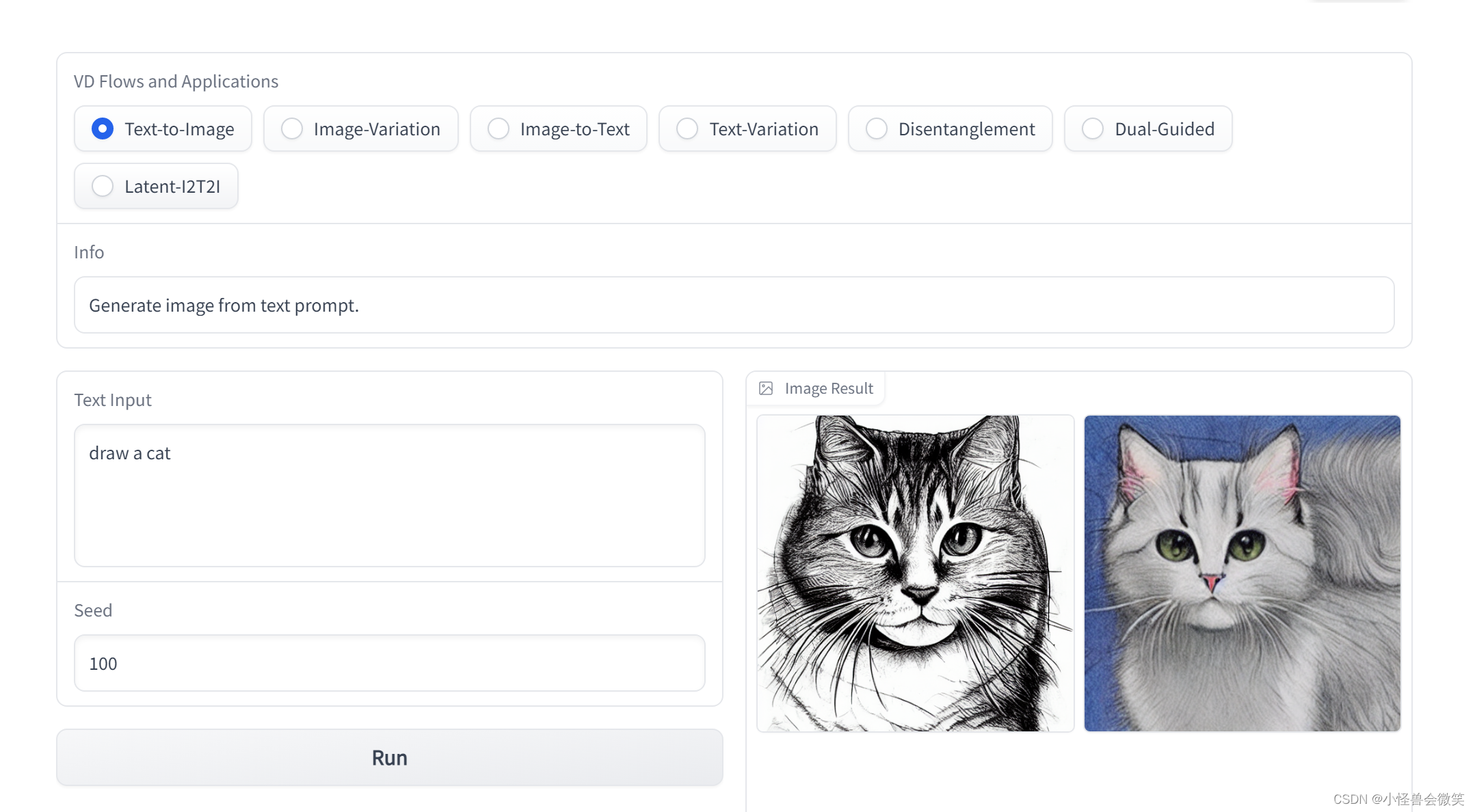
比如,我看到一个有趣的扩散模型的app。。打开后发现其可以实现许多多模态之间的转换。
6.总结
类似Github,Huggingface里面有好多好东西。一起来玩下下!