文章目录
- 1.提出问题
- 2.解决方法
-
- 01.添加额外的 uni-modal loss function:
- 02.Modality dropout
- 03.Adjust learning rate
- 04.Imbalanced multi-modal learning
- 05.条件利用(效)率
- 06.Pre-trained uni-modal encoder
- 07.One more step: fine-grained cases
- 08.balanced audiovisual dataset
- 09 PMR: Prototypical Modal Rebalance for Multimodal Learning, CVPR 2023.
- 10.Boosting Multi-modal Model Performance with Adaptive Gradient Modulation ,ICCV 2023
- 11.Cooperative Multi-modal Game
- 3.总结
- 4.未来发展:
1.提出问题
核心概念:
多模态学习是指利用多种不同类型的数据(如图像、文本、音频等)来进行学习和决策的机器学习方法。它旨在通过融合多个感知模态的信息,提供更全面、准确和丰富的数据表示,从而改善机器学习任务的性能。
在多模态学习中,每个感知模态都可以提供独特的信息,而这些信息在单一模态中可能无法获得。通过将不同模态的数据进行关联和整合,可以更好地理解和解释数据,提高模型的鲁棒性和泛化能力。
多模态学习可以应用于各种任务,如图像分类、目标检测、情感分析、语音识别等。例如,在图像分类任务中,可以同时利用图像的视觉特征和文本的语义信息来提高分类准确性。在情感分析中,可以结合文本和音频数据来更准确地识别情感表达。
大脑中的上丘脑接受各种感官刺激,能够提升感知效果。类似于神经网络的多模态输入与单一输出。

不同模态数据间的差异较大

paired 数据模态间的信息量不同,导致网络学习过程中出现衰退(难学习的模态,更容易欠优化):
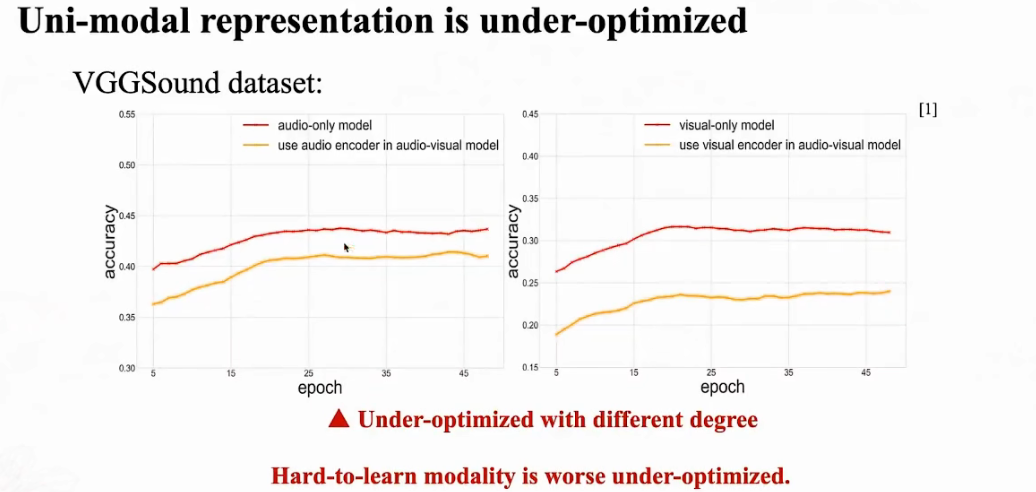
引入多模态,不一定能提升性能:
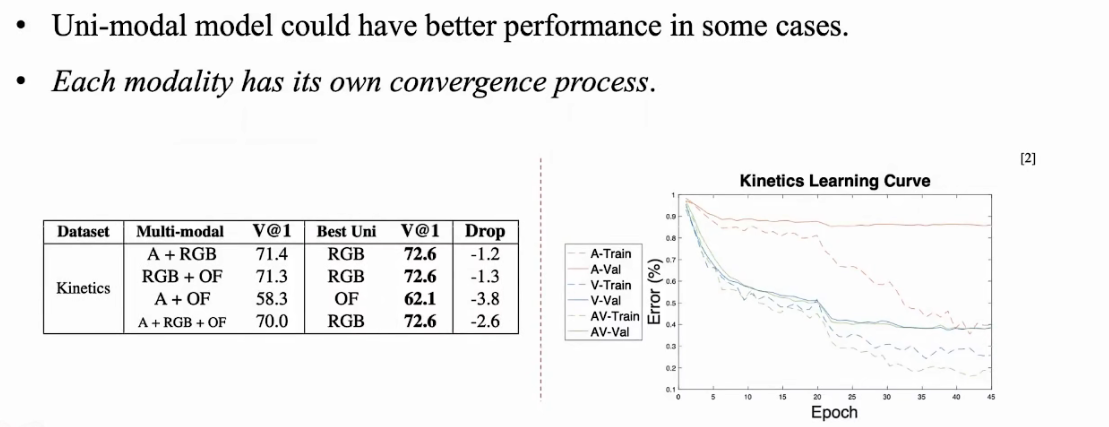
不同模态在学习过程中,learning pace不同。
2.解决方法
01.添加额外的 uni-modal loss function:
控制不同模态间,损失的权重(转化为多任务学习)
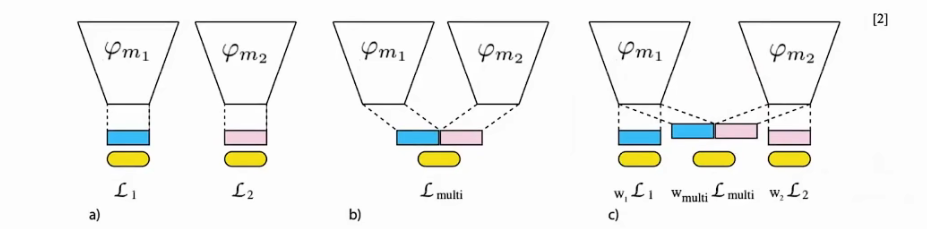
来自CVPR 2020《What makes training multi-modal classification networks hard?》
02.Modality dropout
某些模态置零,使得学习其他模态更充分(初步尝试:以固定速率drop)
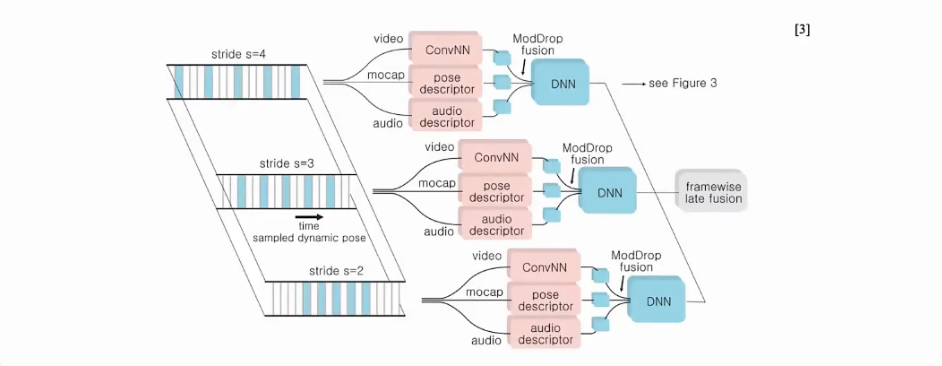
文章来自 TPAMI 2015 《Moddrop: adaptive multi-modal gesture recognition》
03.Adjust learning rate
不能兼顾每个模态的学习特点
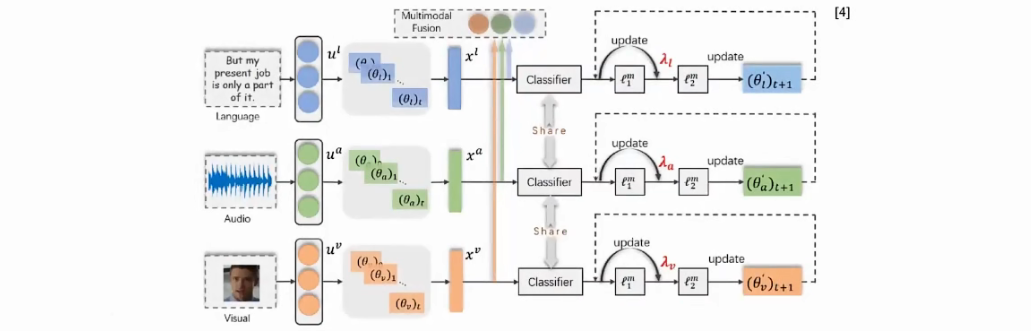
《Leaming to balance the learning rates between various modalities via adaptive tracking factor》 IEEE Signal Processing Leters, 2021
04.Imbalanced multi-modal learning
不同模态在联合学习的时候,表征质量是不同的:
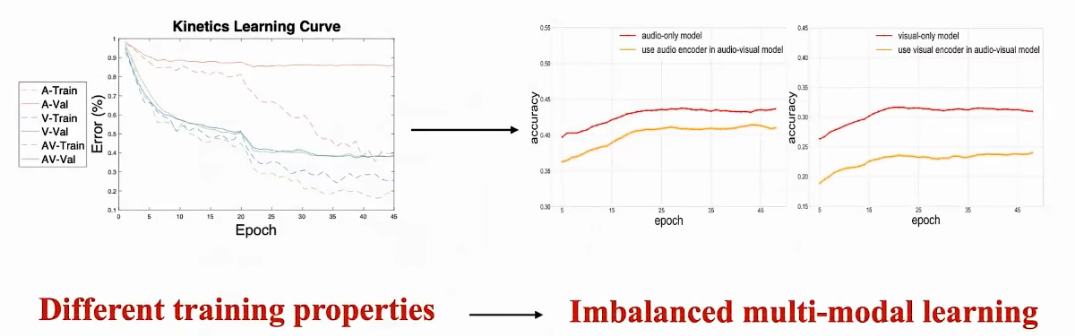
有更好表现的模态,主导训练过程:

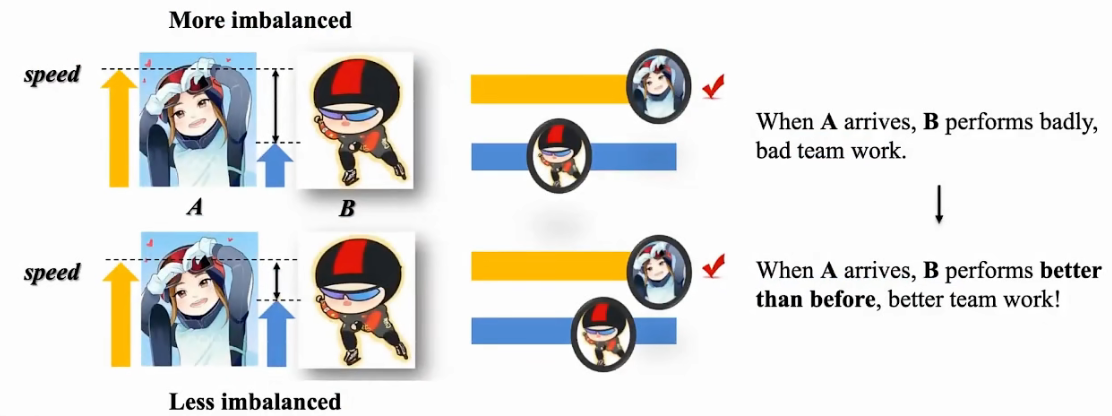
其中,a、v各代表一种模态。最后的softmax阶段,Wa*φa较大而另一模态 Wv*φv较小,也会使总和较大,导致最后的梯度较小。使得weak modality 不能被充分学习。
类似于滑雪比赛中,最后到的队员,代表了全队成绩;而不是第一名。
求 两个模态间学习性能的 Discrepancy Ratio ρ:

速度降低 --> 影响模型泛化性。通过引入协方差矩阵,提升噪声:
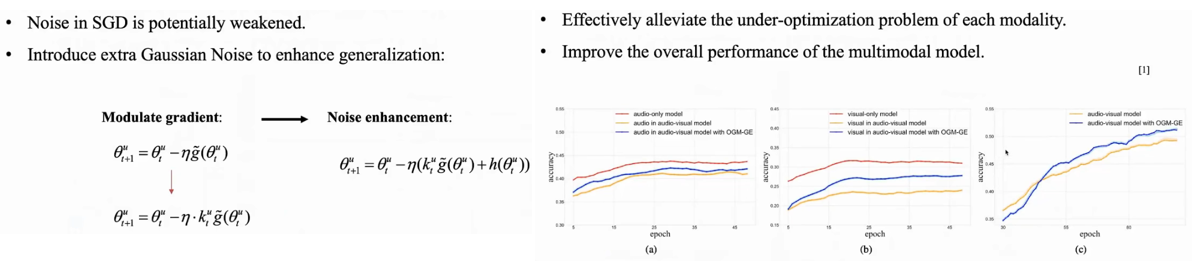
以下是结合不同backbone以及在多任务上性能测试(较好的表现):

来自文章 CVPR2022 ORAL 《Balanced multimodal learning via on-the-fly gradient modulation》
05.条件利用(效)率
测试一个模态,在给定另一个模态的条件下的学习效率(一个模态对另一模态的依赖程度)。

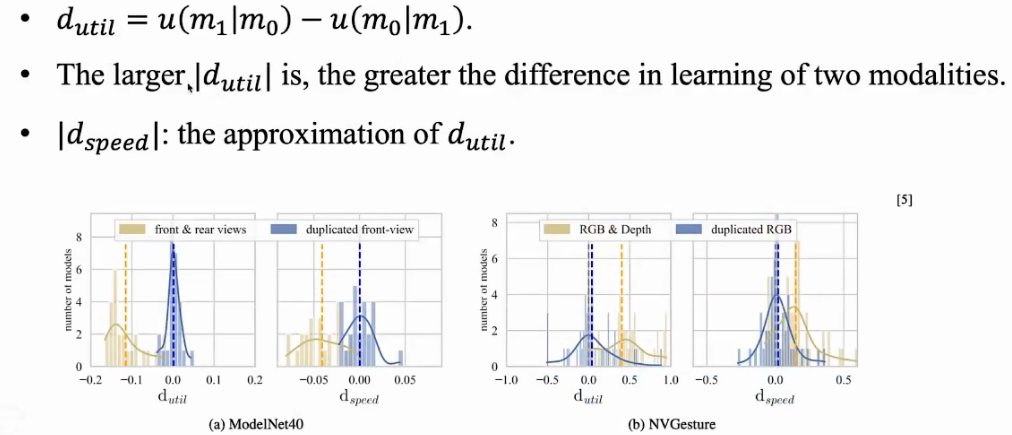
OGM是放慢学习快的模态(效果更好);这篇文章是加速学习慢的模态。

06.Pre-trained uni-modal encoder
利用 Pre-trained的单模态encoder,蒸馏出混合模型中某一模态的权重
](https://img-blog.csdnimg.cn/308d2896a8314d85956c4d32a2eb126a.png)
文章来自《On uni-modal feature learning in supervised multi-modal learning》ICML 2023
07.One more step: fine-grained cases
在细粒度任务上(比如以下:不同鸟的种类和叫声),多模态联合训练时,发现前面介绍的方法OGM-GE、G-blending效果反而不如 直接concat 多模态,见下图最后:
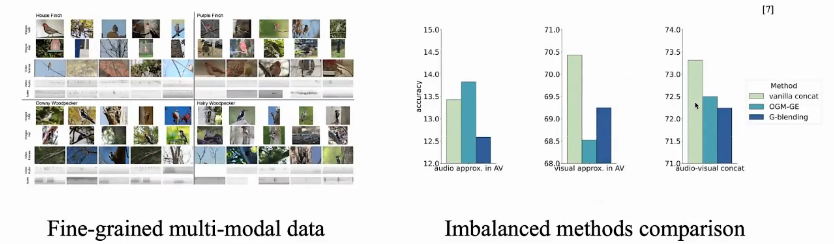
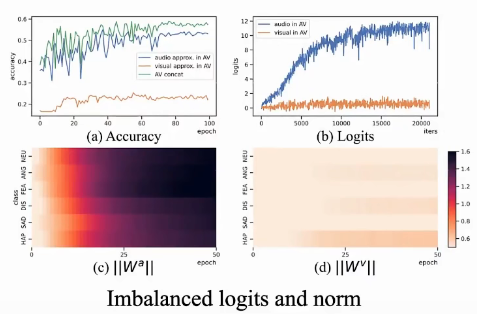
以下是训练数据,可以发现:无论accuracy 还是 logits,A和V差异都无比巨大(上一行中的蓝色线和红色线)。下面两张图是 normed weights,说明模型更偏向于Audio。
解决方法:消除w的norm的影响,更改度量方式:在余弦空间度量角相似度。
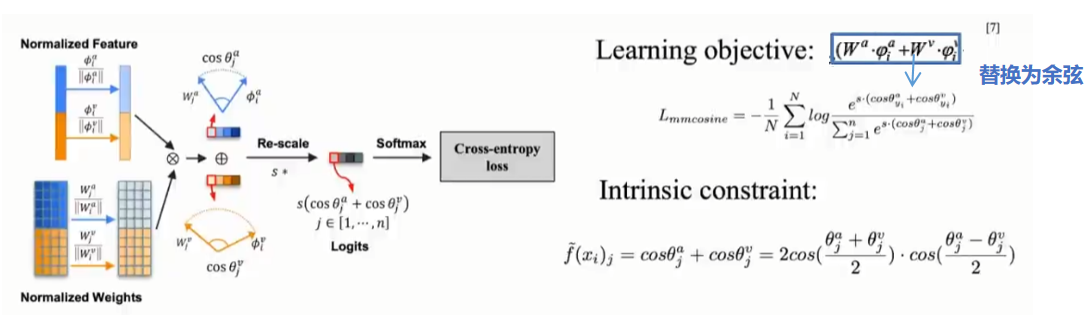
实验效果:涨点
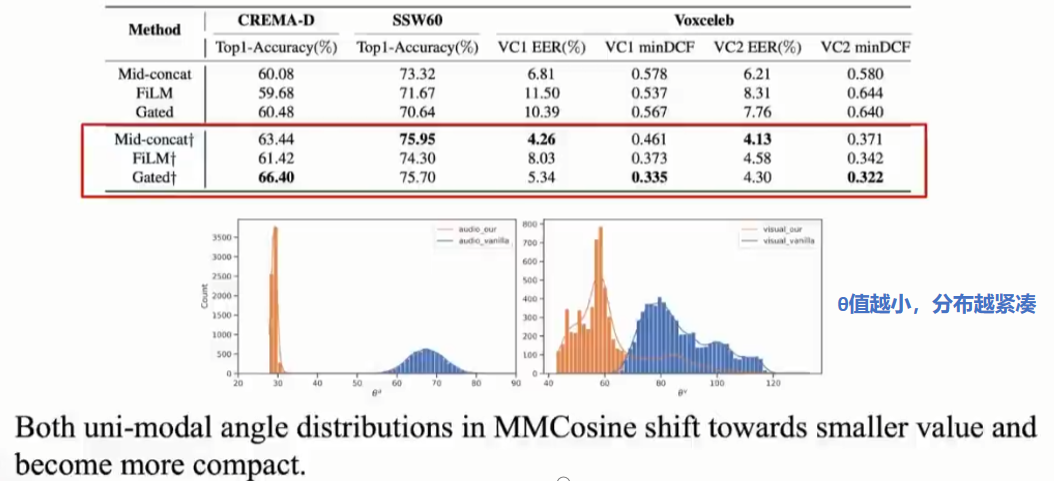
文章来自《Mmcosine: Multi-modal cosine loss towards balanced audio-visual fine-grained learning》ICASSP 2023:
08.balanced audiovisual dataset

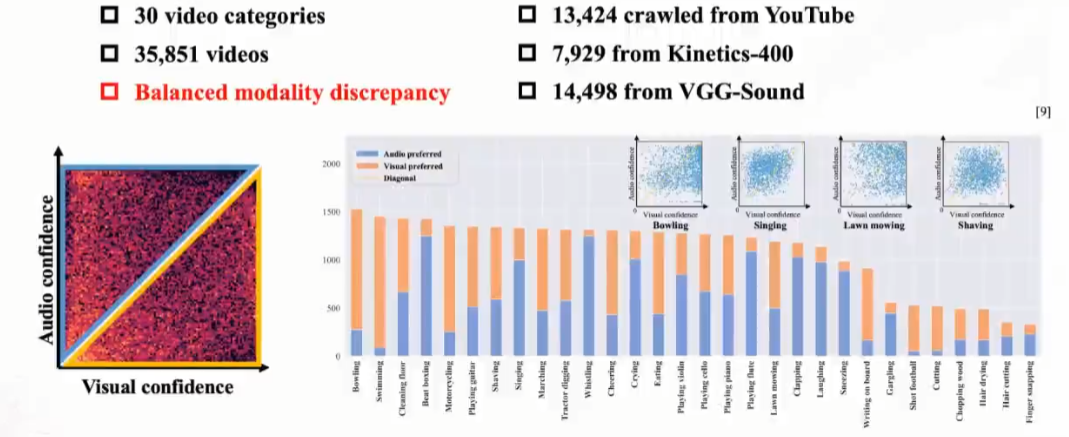
文章来自《Balanced audiovisual dataset for imbalance analysis》CVPR 2023
09 PMR: Prototypical Modal Rebalance for Multimodal Learning, CVPR 2023.
同时改变梯度大小和方向,改进弱势模态的学习速率
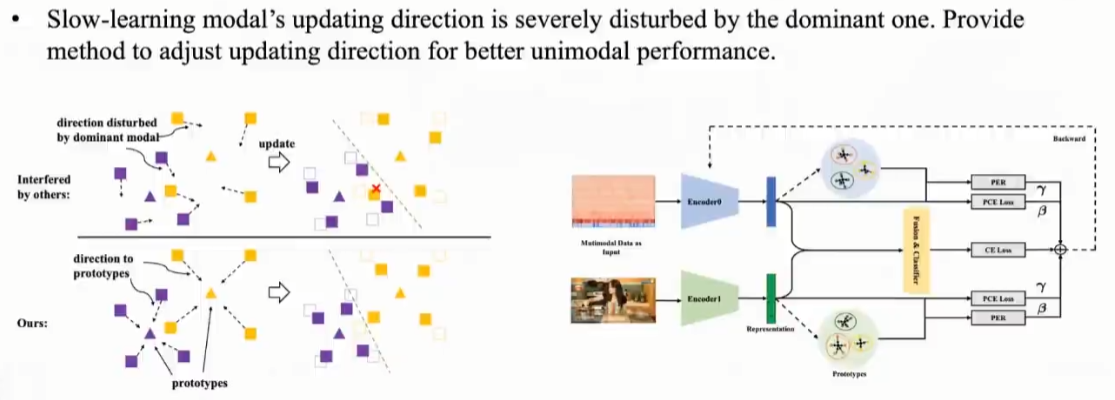
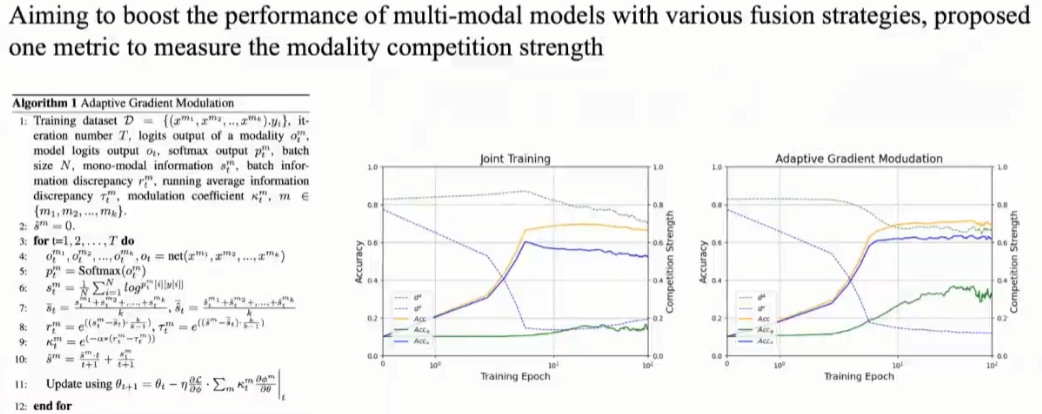
10.Boosting Multi-modal Model Performance with Adaptive Gradient Modulation ,ICCV 2023
原理也是度量模态间差异:
11.Cooperative Multi-modal Game
基本原理:将每个模态看作一个player,参与到联盟中,共同完成任务

根据每个modality贡献,多劳多得,少劳少得。评判标准:shapley值(度量modality 的实际贡献, 在博弈论、神经网络可解释性中常用)。


… … … low contributing mod导致模型退化, , ,, , , , , , , , 提升其判别能力,能够提升shapley值
实验效果:

本文采用sample-wise的方法,使得多模态之间合作紧密, , 提升视觉模态在整个联盟中的参与程度(容易分类与不容易分类的图片)
文章来源于《Enhancing Multi-modal Cooperation via Fine-grained Modality Valuation," in arXiv:2309.06255.2023》
3.总结

两大步骤:
- 识别不平衡。a.计算单模态的acc、logits b.计算一个模态对另一模态的依赖程度 c.信息论的角度。 模态好不好学习,与其携带的信息量多少无关。
- 解决不平衡
4.未来发展:
- 生成式任务:以上方法均用于解决判别式任务,而在生成式任务方面 work较少。以下是一些推荐论文,其中红框内是一篇生成式任务。

-
slam 也是一种多源信息融合过程
-
联邦学习:不同终端信息质量存在差异
资料来源于@中国人民大学胡迪老师,以及@高领人工智能学院。