多模态深度学习是指将来自不同感知模态的信息(如图像、文本、语音等)融合到一个深度学习模型中,以实现更丰富的信息表达和更准确的预测。在多模态深度学习中,模型之间的融合通常有以下三种方法
总的来说,这三种方法都可以用于多模态深度学习中模型之间的融合,具体选择哪一种方法需要根据具体的任务和数据情况进行决策。
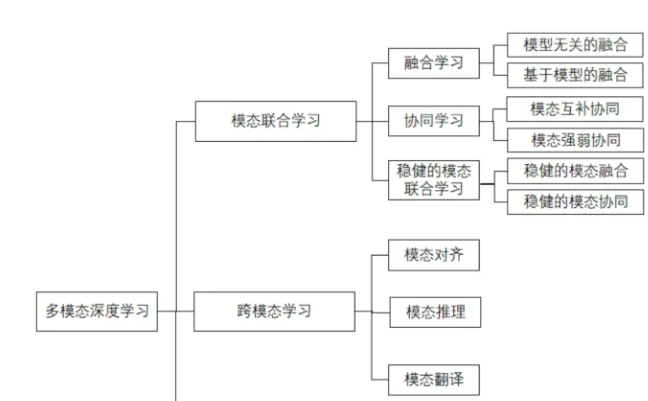
1. 模态联合学习 Multimodal Joint Learning
模态联合学习是一种联合训练的方法,将来自不同模态的数据输入到一个模型中,模型可以同时学习到多个模态的特征表示,并将这些特征表示融合在一起进行决策。
这种方法的优点是可以充分利用多个模态的信息,但是需要同时训练多个模型,计算复杂度较高。
1.1 定义
模态联合学习是一种将多个模态的信息融合在一个模型中进行联合训练的方法。
1.2 研究背景
这种方法的研究背景是,现实生活中的很多任务需要同时利用多个感知模态的信息,
例如语音识别、人脸识别、情感分析等。模态联合学习的目的是在一个统一的框架下,将来自不同模态的信息进行融合,提高任务的表现。
1.3 相关工作
一篇典型的使用模态联合学习方法的论文是2018年的“Multi-Modal Deep Learning for Robust RGB-D Object Recognition”,作者提出了一种基于深度学习的多模态目标识别方法。该方法使用了一个深度卷积神经网络(CNN)和一个多层感知器(MLP)组成的多模态模型来处理来自RGB-D传感器的数据。
具体地,CNN用于处理RGB图像,MLP用于处理深度图像,两个模型的输出在特征层级别进行融合。实验结果表明,该方法相对于单模态方法和其他多模态方法具有更好的识别性能。
2. 跨模态学习(Cross-Modal Learning)
跨模态学习是一种将一个模态的特征转换为另一个模态的特征表示的方法。
- 这种方法的目的是通过跨模态学习,学习到多个模态之间的映射关系,并将不同模态的信息融合在一起。
例如,可以使用图像的特征表示来预测文本的情感极性。这种方法可以减少训练时间和计算复杂度,但是需要预先确定好模态之间的映射关系。
2.1 定义
跨模态学习是一种将一个模态的特征转换为另一个模态的特征表示的方法。
2.2 研究场景
这种方法的研究背景是,现实生活中的不同感知模态之间存在着复杂的关联性和相互依赖性。
- 跨模态学习的目的是学习到不同模态之间的映射关系,实现跨模态信息的转换和融合。
2.3 相关工作
一篇典型的使用跨模态学习方法的论文是2018年的“Image Captioning with Semantic Attention”,作者提出了一种基于卷积神经网络(CNN)和长短时记忆网络(LSTM)的图像描述模型。
该模型首先使用CNN提取图像的特征表示,然后使用LSTM生成对图像的描述。在生成描述时,模型还使用了一个注意力机制,将图像中的重要区域与生成的文本序列进行对齐。实验结果表明,该方法相对于其他方法具有更好的描述性能,能够生成更准确和更生动的图像描述。
3. 多模态自监督学习(Multimodal Self-Supervised Learning)
多模态自监督学习是一种无需标注数据,通过模型自身学习来提取多个模态的特征表示的方法。这种方法的优点是可以利用大量未标注的数据进行训练,但是需要设计一些自监督任务来引导模型学习多模态的特征表示。例如,可以通过学习视觉音频同步、图像文本匹配等任务来进行多模态自监督学习。
3.1定义
多模态自监督学习是一种无需标注数据,通过模型自身学习来提取多个模态的特征的方法。
3.2研究场景
这种方法的研究背景是,现实生活中的很多任务需要大量标注数据才能进行训练,但标注数据的获取成本很高。
多模态自监督学习的目的是通过模型自身学习来利用未标注的数据,提高模型的泛化性能。
3.3 相关工作
一篇典型的使用多模态自监督学习方法的论文是2020年的“Unsupervised Learning of Multimodal Representations with Deep Boltzmann Machines”,作者提出了一种基于深度玻尔兹曼机(DBM)的无监督多模态特征学习方法。该方法使用了两个DBM分别处理来自图像和文本的数据,并在两个DBM之间添加了一个嵌入层,将图像和文本的特征进行融合。在训练过程中,模型使用了对比散度(CD)算法进行参数更新。实验结果表明,该方法相对于其他无监督方法和有监督方法具有更好的多模态特征表示能力。
4. 多模态实践
可以使用PaddlePaddle深度学习框架实现多模态深度学习的三种方法。下面是三种方法的简单实现说明。
3.1 模态联合学习
模态联合学习是将不同模态的特征提取网络联合在一起,以共同学习任务特征的方法。在PaddlePaddle中可以使用PaddleHub提供的预训练模型完成模态联合学习,例如使用PaddleHub提供的图像分类和文本分类模型,分别获得图像和文本的特征表示,然后将这些特征表示合并在一起,用于进行多模态任务的学习和预测。以下是基于PaddleHub实现的示例代码:
import paddlehub as hub
# 加载图像分类模型
image_classifier = hub.Module(name="resnet50_vd")
# 加载文本分类模型
text_classifier = hub.Module(name="ernie")
# 分别对图像和文本进行特征提取
image_feature = image_classifier.feature(input_images)
text_feature = text_classifier.feature(input_texts)
# 将图像和文本的特征表示合并在一起
multimodal_feature = paddle.concat([image_feature, text_feature], axis=-1)
# 使用多模态特征进行任务学习和预测
3.2跨模态学习
跨模态学习是将不同模态的数据映射到共同的空间中,以便可以使用相同的特征提取器和分类器进行训练和预测。在PaddlePaddle中可以使用自定义模型实现跨模态学习。以下是一个基于PaddlePaddle实现的跨模态学习的示例代码:
import paddle
# 定义图像模态的特征提取器
image_feature_extractor = paddle.nn.Sequential(
paddle.nn.Conv2D(...),
paddle.nn.BatchNorm2D(...),
paddle.nn.ReLU(),
...
)
# 定义文本模态的特征提取器
text_feature_extractor = paddle.nn.Sequential(
paddle.nn.Embedding(...),
paddle.nn.LSTM(...),
...
)
# 定义特征融合层
fusion_layer = paddle.nn.Sequential(
paddle.nn.Linear(...),
paddle.nn.ReLU(),
...
)
# 定义分类器
classifier = paddle.nn.Linear(...)
# 定义跨模态学习模型
class CrossModalModel(paddle.nn.Layer):
def __init__(self):
super().__init__()
self.image_feature_extractor = image_feature_extractor
self.text_feature_extractor = text_feature_extractor
self.fusion_layer = fusion_layer
self.classifier = classifier
def forward(self, image_data, text_data):
image_feature = self.image_feature_extractor(image_data)
text_feature = self.text_feature_extractor(text_data)
fused_feature = self.fusion_layer(paddle.concat([image_feature, text_feature], axis=-1))
output = self.classifier(fused_feature)
return output
# 使用跨模态学习模型进行任务学习和预测
3.3多模态自监督学习
多模态自监督学习是一种利用多模态数据自身特点设计的自监督学习方法,通常不需要标注数据。在PaddlePaddle中可以使用PaddleClas提供的模型进行多模态自监督学习,例如使用PaddleClas提供的SimCLR模型,该模型使用数据增强和对比学习方法进行多模态特征学习,以提高模型在多模态数据上的表现。以下是一个基于PaddleClas实现的多模态自监督学习的示例代码:
import paddle
import paddlehub as hub
from paddle.io import DataLoader
from paddle.vision.transforms import transforms
from paddle.vision.datasets import ImageNet, Cifar10
# 定义图像数据集的预处理器
image_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.Normalize(...),
...
])
# 加载图像数据集
image_dataset = ImageNet(..., transform=image_transforms)
# 加载文本数据集
text_dataset = ...
# 定义数据加载器
batch_size = 64
image_data_loader = DataLoader(image_dataset, batch_size=batch_size)
text_data_loader = DataLoader(text_dataset, batch_size=batch_size)
# 加载SimCLR模型
simclr = hub.Module(name="simclr")
# 使用多模态数据进行自监督学习
for image_data, text_data in zip(image_data_loader, text_data_loader):
# 将图像和文本数据进行拼接
multimodal_data = paddle.concat([image_data, text_data], axis=0)
# 进行数据增强
augmented_data = simclr.augment(multimodal_data)
# 获取特征表示
features = simclr(multimodal_data)
# 计算对比损失
loss = simclr.contrastive_loss(features, augmented_data)
# 反向传播更新模型参数
loss.backward()
reference
https://zhuanlan.zhihu.com/p/612953863