CSAPP学习
前言
一门经典的计组课程,我却到了大四才学。
anyway,何时都不会晚。
博主参考的教程:本电子书信息 - 深入理解计算机系统(CSAPP) (gitbook.io),非常感谢作者的整理。
诚然去看英文版可以学到更多,不过一边翻译一边看的过程我觉得还是效率不高的,所以还是选择中文。
博主之前有一定的计算机基础,所以对一些简单概念可能跳得比较快,这里建议读者不懂的地方不要气馁“为什么这里三两句就讲掉了,但是我还没懂”。建议多多发掘自我检索能力,Search the Fxxking Web (STFW) 是计算机专业同学的一大重要能力。
Ch1. 计算机系统漫游
程序运行前4个阶段
相信尝试过一定编程学习的同学们都有过写、运行 helloworld 的经历。可能是用 Dev C++,VSCode,CLion 等 IDE,也可能是自己在命令行执行编译运行语句,本质都是一样的。
那么写了一个 helloworld.c,这个程序是怎么运行起来的呢?
首先计算机能直接运行的都是二进制文件,01010101110101……类似这样的文件。但是要是说让我们用这种语言(机器语言)编程,效率极低而且大概率会疯掉。
汇编语言是一种为了解决这个问题而诞生的低级语言,相对好理解一些,可以转换成机器语言。不过还是面向计算机的语言,编程习惯主要也是按照计算机的思维走,也比较难。
c语言是一种高级语言,是我们人类一定程度上能理解的编程语言,可以转换成汇编语言,再转成机器语言,供计算机运行。
gcc -o hello hello.c
这条命令行语句意思是用 gcc 翻译工具,把 hello.c 翻译成目标输出文件(output)hello,得到的可执行文件就是 hello。
翻译流程如下:

预处理:把文件中的注释信息去掉(注释信息是给人看的,对计算机运行没啥帮助),把头文件展开(其实头文件 #include #define 这些就是对一些格式内容的拷贝),得到 .i 文件。
编译:把高级语言翻译成汇编语言。相同的程序用不同高级语言写,经过编译器后,得到的汇编语言是相同的,也就是计算机最终执行的具体行为都是一样的。感兴趣同学可以了解一下编译和翻译两种高级语言转汇编语言的方式。
汇编:把 .s 汇编文件转为 .o 目标文件,目标文件也是二进制形式。但是缺少一些外部链接的库,暂时不能执行(比如 printf 函数是在 printf.o 文件中定义的,我们自己没定义,所以不能自己直接用,需要外链 printf.o 文件才能使用)。
链接:如上所述,最终生成一个可执行的目标程序。
好现在是可以理解高级语言的作用(让我们不用理解计算机具体运行方式,就能较为简单的编程,生成可执行文件)。但是我们还是需要学习一下底层的编译、汇编等原理的:
- 因为理解底层具体实现后,我们才知道怎样编写的程序运行更高效(同一个问题有许多解法,可以写许多种程序,比如 switch case 和 if else if,但是并不是能解决正确性的程序就是好程序了,我写一个跑一年才出结果的代码和跑1小时就出结果的代码价值也是完全不同的)。
- 对程序理解更深,出现问题时我们也知道如何排查,bug 不全是只有中英文字符那种程度的哦。
- 甚至有一些安全性问题是通过对底层原理进行攻击的。
CPU硬件运行方式
程序翻译成汇编语言类似这样:
main:
subq $8, %rsp ; 通过从栈指针(rsp)减去8字节,为栈分配空间。
movl $.LC0, %edi ; 将字符串".LC0"的地址加载到目标寄存器%edi中。
call puts ; 调用puts函数,该函数可能打印%edi寄存器指向的字符串。
movl $0, %eax ; 通过将0移动到%eax寄存器中,将返回值设置为0。
addq $8, %rsp ; 通过将8字节添加到栈指针(rsp),释放栈上的空间。
ret ; 从main函数返回。
不用看懂。可以看到按照计算机思维,这个程序被拆成了这么多条要执行的指令。CPU 执行程序的时候就是一条条指令执行的。
具体是怎样执行?下图是 计算机基本组成的结构图。计算机五大组成部分:CPU(运算器+控制器),内存,输入,输出。
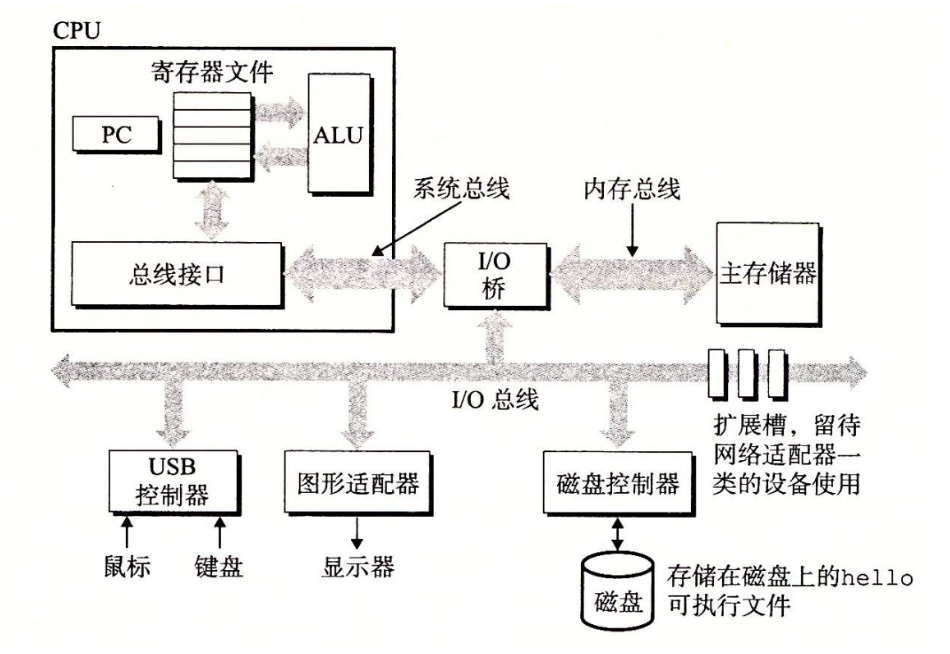
总线:在各个设备之间传输数据用。
输入设备:把信息输入给电脑的一些方式,比如键盘打字,鼠标点击,光盘U盘,我们写的程序存在磁盘上。
输出设备:电脑把信息输出给我们的方式,比如可以看到的显示器。输入输出设备统称 IO 设备。
主存:也叫内存,程序从磁盘里拿出来放到主存里运行。内存是衡量计算机运行快不快的一个重要指标因为内存小了每次能拿一小部分程序进来运行,再拿下一部分,效率比较低,内存大了磁盘和内存之间交互可能相对就快很多(磁盘里的内容往内存拿是比较占时间的)。
CPU:从主存里面拿一个个字节的数据进行处理。PC 是一个指针指向当前要拿的数据的位置;首先从 PC 所指向的主存地址中加载几个字节到 CPU 寄存器里,把寄存器中的内容复制到 ALU 中进行操作,比如取到了a和b的值算a+b;然后可能需要把一些数据存储写回到主存中,比如让 c=a+b,c的值变了,那么我们可能就需要把新值写回到主存中c的位置;最后 PC 跳转,指向下一部分要取的字节的位置。重复上述操作直到程序执行完。
比如想跑一个 helloworld 我们经历了这些步骤:
- 鼠标键盘输入,写了一个 helloworld 程序并点击运行或 shell 输入运行语句
./helloworld。我们输入的运行指令也是先被放到主存,然后被 CPU 寄存器文件读取,CPU 解析后明白我们是想执行 helloworld 文件,然后再下指令从磁盘中取 helloworld 程序到主存里运行。 - helloworld 程序被加载到主存中(虽然 CPU 是计算机的大脑,中控中心,但是这里磁盘数据不用经过 CPU 可以直接给主存是利用了 DMA 技术),CPU 再取主存中的数据进行指令解析,执行。
- CPU 解析指令直到我们是想在终端打印 helloworld,于是驱动显示器输出设备输出显示 helloworld。
Cache 缓存
CPU 去主存取指令,和去磁盘取指令,其实都有一定的时间开销(去磁盘开销更大)。我们可以在 CPU 内部临时存一些近期可能要访问到的内容,这样当访问到这部分内容的时候不需要每次都去主存去磁盘拿,在自己这里就找得到就快很多。比如c=a+b;c=a+b;c=a+b;c=a+b; 执行这个指令,如果第一次执行的时候 CPU 猜测,a和b的值后面会不会还要用到,我先在缓存里存一下以备不时之需。第二次执行的时候可以直接拿到本地缓存 cache 中存储的 ab 值进行运算,不用去磁盘里再取一次了,第三次第四次也是,这样就比较节约时间开销。
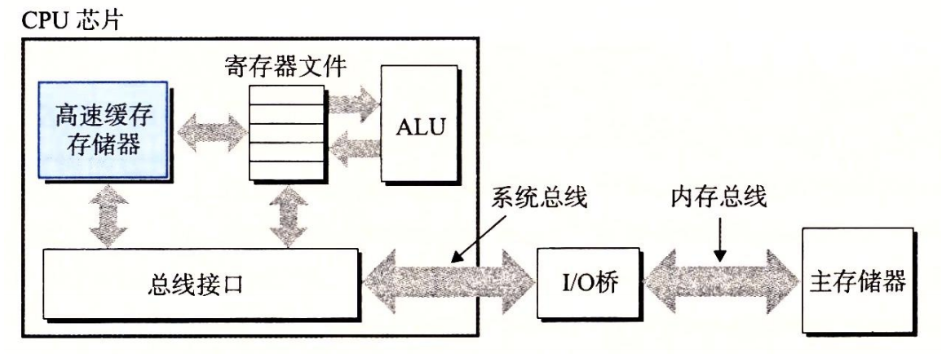
当然缓存大小有限,以此来保证 CPU 芯片大小不会太大和缓存中查找不会太慢。因此我们要设计一些缓存存储算法来决定哪些内容优先被存入缓存,这个后面再细讲。
缓存结构其实是这样的,著名的缓存金字塔:
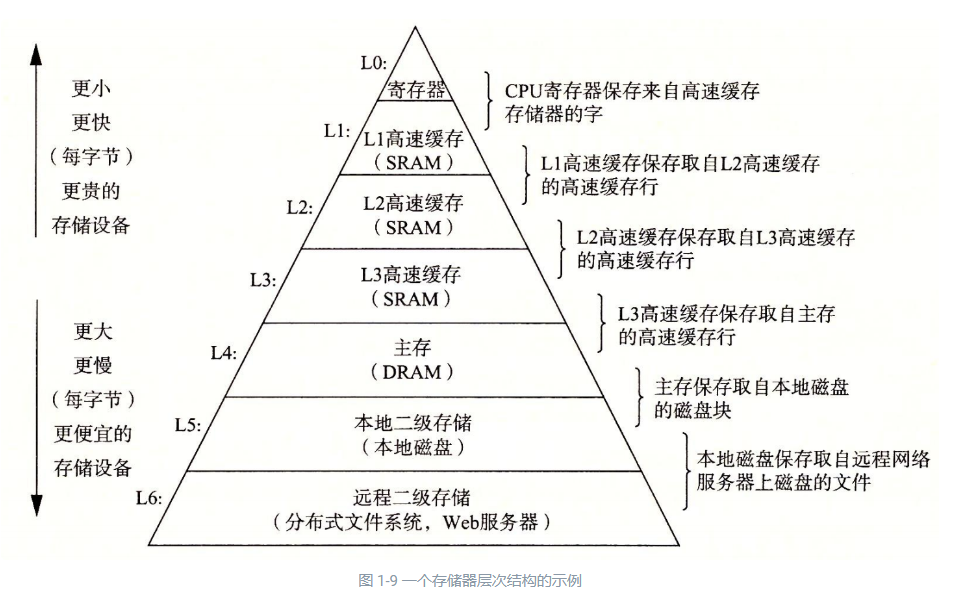
上面一层是下面一层的缓存。
操作系统
operating system,了解一些的同学可能知道,比如win系统,mac系统,linux系统,这玩意啥用处呢。主要是实现对资源的分配管理。

比如我qq应用程序,要调用键盘,调用摄像头,要调用键盘……首先应用程序直接去操作这些底层的 CPU,主存,IO 都比较麻烦,而且也不安全(比如qq崩溃异常状态下去调用这些设备)。操作系统负责中间管理,抽象出这些设备的接口供应用程序调用,也保护硬件不被失控应用程序滥用。
操作系统的抽象如下:
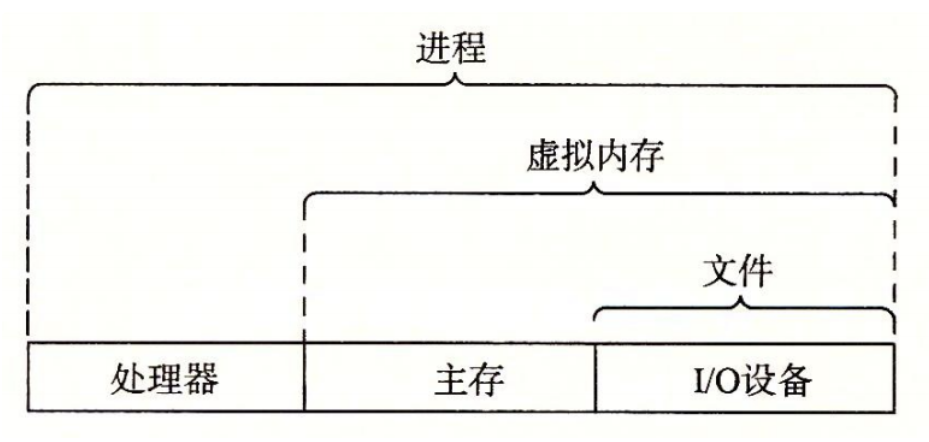
进程
一个正在运行的程序。操作系统会协调多个进程交错执行,比如我现在电脑上开着微信 浏览器 Typora,内核不停地切换这些进程的执行而我感觉不到。
进程切换需要保存当前进程状态,切换到下一个进程的状态继续运行,这个状态叫上下文 context。
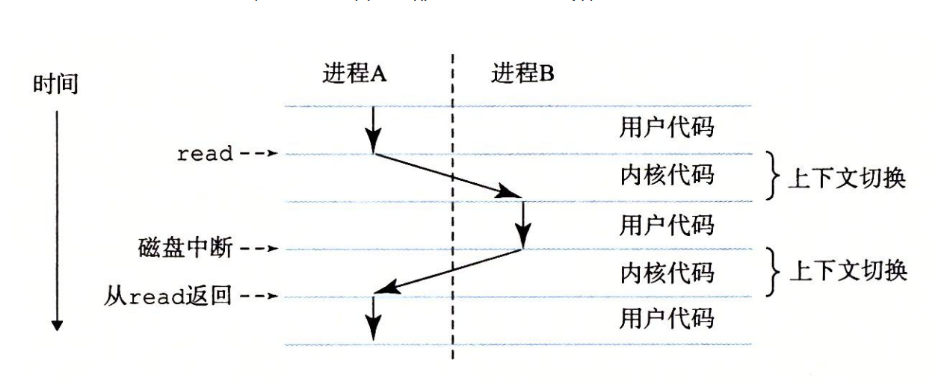
一个进程可能包含多个线程,他们共享这个进程的资源。
GPT:

虚拟内存
操作系统让多个进程互不干扰的使用主存,对每个进程来说他们只看得到自己的主存占用范围,感觉好像只有自己在占用主存,这就叫虚拟内存。
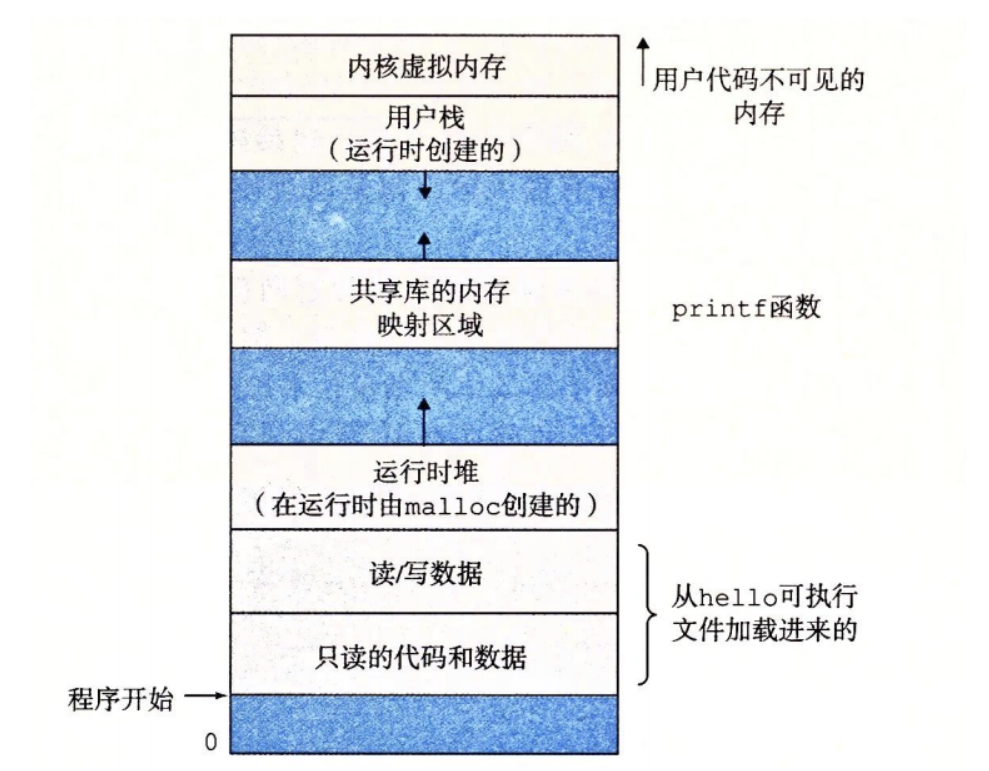
如图是主存中的组成,从下往上地址逐渐增大。
内核虚拟内存:给操作系统用的。
用户栈:比如程序里的函数,存到这里入栈。
共享库内存:比如 printf 这种共用库。
堆:比如 malloc 申请的空间,存在这里,也是多个程序共用。
数据:存放程序数据。
虚拟内存具体实现方法后面讲解。
文件
字节序列。所有 IO 设备都可以看做是文件,我们可以往文件里读写数据进行 IO 操作。这样我们对磁盘进行读写的时候其实我们并不关心具体读写 IO 行为,我们只需要往磁盘文件夹里读写文件即可。
网络通信
其实网络也类似一个 IO 设备,我们给网络适配器写入数据流,网络适配器发送给另一台主机。
比如下例,好处在于我们可以把程序存在服务器上,在服务器上跑,我们只需要发送简单指令。比如学习深度学习,不用自己非得买一个牛逼电脑,可以租牛逼服务器(服务器其实也算是一种电脑,和我们的客户端电脑没啥区别)。

重要概念
Amdahl 定律
计算提升系统某一部分性能对整个系统所带来的效果。
α是某一部分在整个系统中占的比重,k是这部分的性能加速了多少。S是最终对整个系统提升的加速效果。
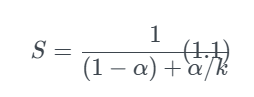
比如α=60%,k=3,这一部分提升了3倍速度,但是对整体速度的提升是1.67倍,可见想要提升系统整体速度,需要提升系统中大部分的速度。
并发 并行
并发:一个系统同时运行多个活动。
并行:利用并发来加速程序运行。
线程级并行
进程中多个任务的切换。
单处理器系统:模拟并发,即实际上是不断切换。
多处理器系统:确实可以并发运行,也可以加速用多线程方式写的单个程序。
超线程:也叫同时多线程,允许单核 CPU 执行多个控制流,多个控制流共享执行单元。比如单处理器切换线程,需要保存当前状态,切换 pc 指针,寄存器值……而超线程多个核对 pc,程序计数器等有拷贝,使得切换的时候不用那么麻烦,比如常规单处理器切换可能需要20000个周期,超线程一个周期就能切换。
指令级并行
有些系统硬件支持把一条指令拆成多个任务同时处理。
当指令周期小于1的时候(一个 CPU 时钟周期可以执行平均1条以上的指令)系统被称作超标量系统。