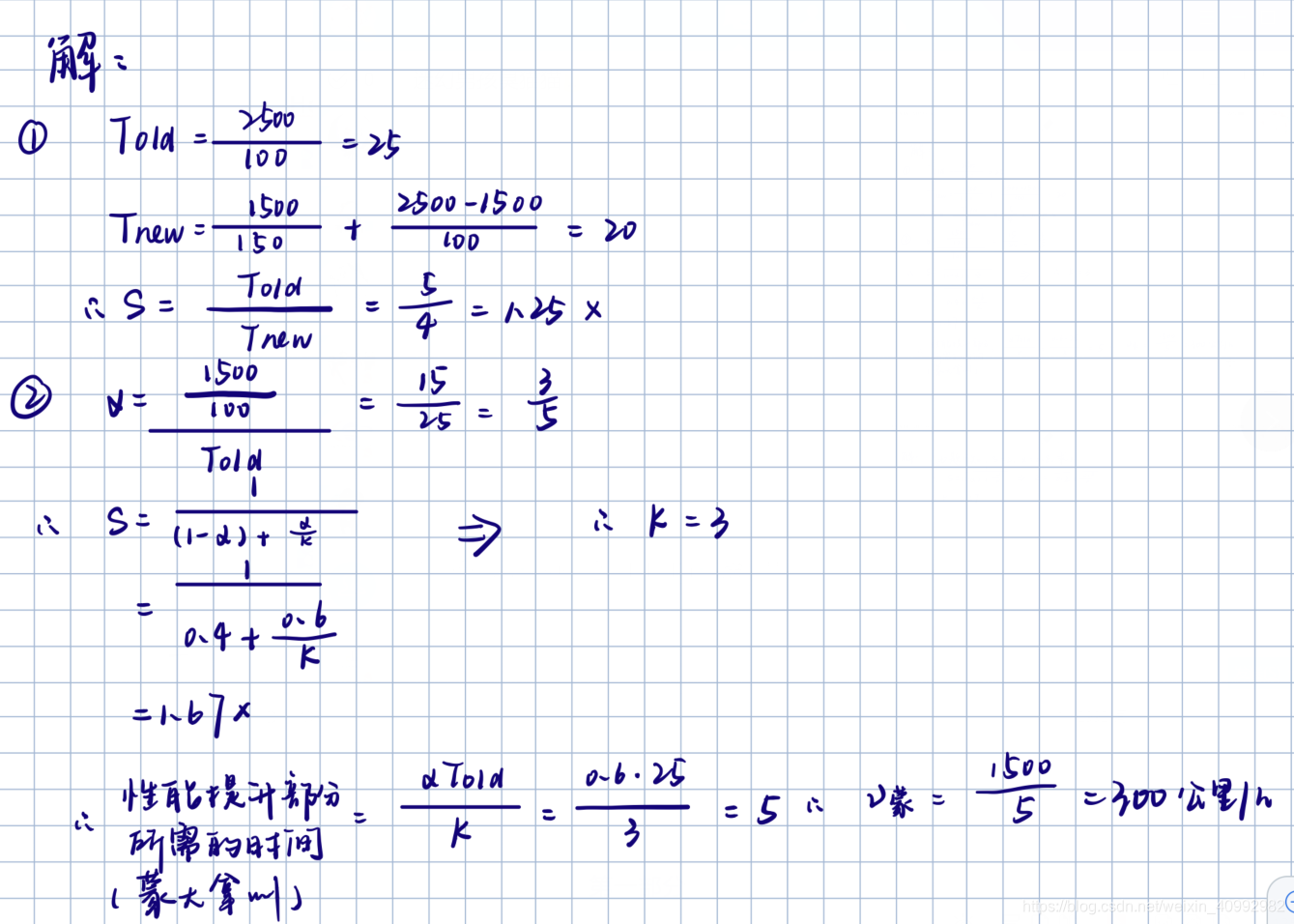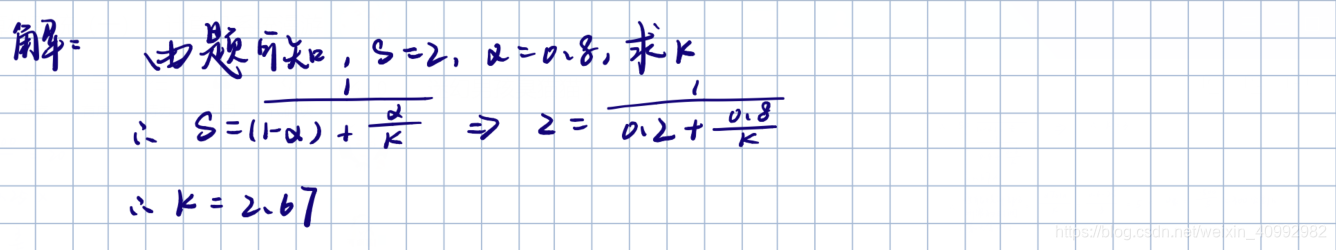深入理解计算机系统(一):计算机系统漫游
文章目录
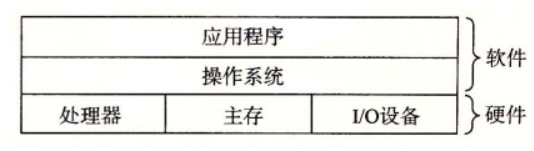
操作系统可以看成是应用程序和硬件之间插入的一层软件,所有应用程序对硬件的操作尝试都必须通过操作系统。操作系统的两个基本功能如下所示:
- 防止硬件被失控的应用程序滥用
- 向应用程序提供简单一致的机制来控制复杂而又通常大不相同的低级硬件设备。
这两个基本功能是通过进程、虚拟内存、文件这几个基本的抽象概念实现的。文件是对I/O设备的抽象表示,虚拟内存是对主存和磁盘I/O设备的抽象表示,进程则是对处理器、主存、I/O设备的抽象表示。
探秘hello world
下面这个经典的helloworld程序几乎是每个程序员入门必写的!那么,在系统上执行这个hello程序时,系统将会发生什么以及为什么会这样,你了解嘛?那么就从这里入手开始今天的博文吧!
#include<stdio.h>
int main(){
printf("hello,world"\n);
return 0;
}
我们通过编辑器创建并保存文本文件,命名为hello.c(源程序)。这个源程序实际上是由0和1组成的比特序列(位序列),8位为1字节,每个字节表示程序中的某些文本字符,这些文本字符是使用ASCⅡ码来表示的,ASCⅡ码实际上分别对应一个不同的整数值。
至此,我们知道hello.c是以字节序列的方式存储在文件中的,每个字节又对应一个整数值,从而对应某些字符。比如说,hello.c中第一个字节的整数值为35,对应的就是字符#,第二个字节的整数值为105,对应的字符是i。
PS:只由ASCⅡ字符构成的文件叫做文本文件,其他的文件是二进制文件,显然hello.c是个文本文件。
写好了基本程序,接下来要将这个源程序翻译一下,还记得我们常用的指令吗?
linux>gcc -o hello hello.c
为了在系统上运行hello.c,每一条C语句都必须被其它程序转化为一系列的机器语言指令(比C语言低级),然后这些指令按照一种成为可执行目标程序的格式打包,并以二进制磁盘文件的形式存放起来。
这个指令的意思就是GCC编译器驱动程序读取源程序文件hello.c,并把它翻译成一个可执行的目标文件hello。这个翻译过程分为4个阶段。预处理器、编译器、汇编器、链接器一起构成了编译系统。

接下来,对每个阶段进行一下简短的介绍:
-
预处理阶段:预处理器(cpp)根据以字符
#开头的命令,修改原始的C程序。比如第一行#include<stdio.h>命令告诉cpp读取系统头文件stdio.h的内容,并把它直接插入程序文本中,这样就得到了另一个C程序,通常是以.i作为文件扩展名。 -
编译阶段:编译器(ccl)将文本文件hello.i翻译成文本文件hello.s(包含一个汇编语言程序)。
main: subq $8,%rsp movl $.LC0,%edi call puts movl $0,%eax addq $8,%rsp ret -
汇编阶段:汇编器将hello.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的歌实,并将结果保存在目标文件hello.o中,hello.o是一个二进制文件。
-
链接阶段:回忆一下,我们的hello程序中调用了printf函数,这个函数是每个C编译器都提供的标准C库中的一个函数,它存在于一个名为printf.o的单独的预编译好了的目标文件中,而这个文件必须以某种方式合并到我们的hello.o程序中。链接器(ld)就负责合并,结果就是得到hello文件,这是个可执行文件,它可以被加载到内存里,然后由系统执行。
OK,经过上面一通翻译,终于得到了可执行的文件hello,那么想要运行这个文件,还需要输入下列命令:
linux>./hello
hello,world
linux>
当我们在键盘上输入字符串./hello,敲回车的时候,shell程序知道我们结束了命令的输入,然后shell执行一系列指令来加载可执行的hello文件,这些指令将hello目标文件中的代码和数据从磁盘复制到主存。数据包括最终会被输出的字符串hello,world\n。
至此,一个源程序的诞生到如何显示就已经全部说完了~
系统的硬件组成
为了更好的理解运行hello程序时发生了什么,我们接下来简单了解系统的硬件组成,然后从这个角度再来看看hello程序的执行。
1.总线
贯穿整个系统的一组电子管道。总线携带信息字节并负责在各个部件间传递。
2.I/O设备
I/O设备是系统和外部世界的联系通道。常用的4个I/O设备:作为用户输入的键鼠,作为用户输出的显示器,以及长期存储数据和程序的磁盘。当完成“翻译”任务后,hello程序就存放在磁盘上。每个I/O设备都通过一个控制器/适配器和I/O总线相连。
3.主存
主存是个临时存储设备,在处理器执行程序的时候,用来存放程序和程序处理的数据。主存是一组DRAM组成的。
4.处理器
就是我们常说的CPU了,是解释存储在主存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(或寄存器),称为程序计数器(PC),在任何时候,PC都指向主存中的某条机器语言指令。
处理器从PC指向的内存处读取指令,解释指令中的位,执行该执行令指示的简单操作,然后更新PC,使其指向下一条指令,而这条指令并不一定和在内存中刚刚执行的指令相邻。
说说简单操作的例子:
- 加载:从主存复制一个字节或者一个字到寄存器,以覆盖寄存器原来的内容
- 存储:从寄存器复制一个字节或者一个字到主存的某个位置,以覆盖这个位置上原来的内容
- 操作:把两个寄存器的内容复制到ALU,ALU对这两个字做算术运算,并把结果存放到一个寄存器中,以覆盖该寄存器中原来的内容。
- 跳转:从指令本身中取一个字,并将这个字复制到PC中,以覆盖PC中原来的值。
再来看看hello程序吧~
当我们在键盘上输入./hello后,shell程序会将字符逐个读进寄存器中,然后再把它放入内存中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SSlFhIcp-1586767083410)(C:\Users\NayelyA\AppData\Roaming\Typora\typora-user-images\image-20200413153902880.png)]](https://img-blog.csdnimg.cn/20200413164044580.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk5Mjk4Mg==,size_16,color_FFFFFF,t_70)
敲回车的时候,shell程序知道我们结束了命令的输入,然后shell执行一系列指令来加载可执行的hello文件,这些指令将hello目标文件中的代码和数据从磁盘复制到主存。数据包括最终会被输出的字符串hello,world\n。利用DMA技术,数据可以不通过处理器而直接从磁盘到达主存。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FosUIabI-1586767083411)(C:\Users\NayelyA\AppData\Roaming\Typora\typora-user-images\image-20200413154052937.png)]](https://img-blog.csdnimg.cn/2020041316410724.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk5Mjk4Mg==,size_16,color_FFFFFF,t_70)
一旦目标文件hello中的代码和数据被加载到主存,处理器就开始执行hello程序的main程序中的机器语言指令,这些指令将hello,world\n字符串中的字节从主存复制到寄存器文件,再从寄存器文件中复制到显示设备,最终显示再屏幕上。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D3gA29Lr-1586767083413)(C:\Users\NayelyA\AppData\Roaming\Typora\typora-user-images\image-20200413154235338.png)]](https://img-blog.csdnimg.cn/20200413164122477.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk5Mjk4Mg==,size_16,color_FFFFFF,t_70)
高速缓存与存储器层次结构
通过以上的介绍,程序一共被复制了几次,从哪里复制到哪里呢?一开始程序的机器指令放在磁盘上,程序加载时,被复制到主存,处理器运行程序的时候,指令从主存复制到处理器。这些复制工作会减慢程序真正的工作,你可以理解为这些复制会带来一定的开销。
根据机械原理,较大的存储设备要比较小的存储设备运行的慢,而快速设备的造价远高于同类的低速设备。针对处理器和主存间的差异,设计出了高速缓存存储器,存放处理器近期可能会需要的信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gpfhXsk0-1586767083414)(C:\Users\NayelyA\AppData\Roaming\Typora\typora-user-images\image-20200413154646140.png)]](https://img-blog.csdnimg.cn/20200413164144362.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk5Mjk4Mg==,size_16,color_FFFFFF,t_70)
每个计算机系统的存储设备都被组织成了一个存储器层次结果,想必课堂上已经见过这幅图片了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Km3m5EUJ-1586767083414)(C:\Users\NayelyA\AppData\Roaming\Typora\typora-user-images\image-20200413154808443.png)]](https://img-blog.csdnimg.cn/20200413164202269.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk5Mjk4Mg==,size_16,color_FFFFFF,t_70)
存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存。
并发和并行
1.线程级并发
当构建一个由单操作系统内核控制的多处理器组成的系统时,我们就得到了一个多处理器系统。随着多核处理器和超线程的出现,多处理器系统变得常见。
多核处理器就是把多个CPU集成到一个集成电路芯片上。下面给出一个典型多核处理器的组织架构,其中有4个CPU核,每个核都有自己的L1和L2高速缓存,这些核共享更高层次的高速缓存以及到主存的接口。
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mckLkfr1-1586767083415)(C:\Users\NayelyA\AppData\Roaming\Typora\typora-user-images\image-20200413161327569.png)]](https://img-blog.csdnimg.cn/20200413164236998.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk5Mjk4Mg==,size_16,color_FFFFFF,t_70)
超线程这个概念在很多面经中也出现过,来重点mark下!超线程有时候也叫做同时多线程,是一项允许一个CPU执行多个控制流的技术。超线程技术把多线程处理器内部的两个逻辑内核模拟成两个物理芯片,可以让单个处理器使用线程级的并行计算,利用空闲CPU资源,在相同时间内完成更多工作。
2.指令集并行
现代处理器可以同时执行多条指令的属性叫做指令级并行。如果处理器可以达到比一个周期一条指令更快的执行速率,就称之为超标量处理器,大多数现代处理器都支持超标量操作。
3.单指令、多数据并行
有的处理器的硬件运行一条指令产生多个可以并行执行的操作,这种方式叫做单指令、多数据。
Amdahl定律
Amdahl定律:要想显著加速整个系统,必须提升全系统中相当大的部分的速度。

HomeWork